[13일 복습 문제]
- 객체의 형태를 그대로 유지하면서 파일을 저장하고 불러 올 수있는 모듈은?
:pickle
- time 에서 포맷코드 : %x 뭐가 출력되는가?
:로케일의 적절한 날짜표현
- 오늘 날짜를 time으로 표현 하시오.
:import time
time.localtime()
time.strftime("%x", time.localtime()) -> 09/14/22
- list(zip([1,2,3],[4,5,6])) 하면 결과값이 어떻게 나오는가.
: [(1, 4), (2, 5), (3, 6)]
- '0xf1f7 10진수로 바꾸기
: int('0xf1f7', base =16) -> 61943
- a = ['3', '5', '18', '11'] ,숫자 뒤에 개를 붙이 시오.
:
(1) list(map(lambda x: x + '개', a))
(2) list(map(lambda x:x+'개',['3', '5', '18', '11']))
(3)
def f(str):
return str + '개'
list(map(f, a)) (4)
a = ['3','5','18','11']
def str_(a):
return a+'개'
list(map(str_, a))- 1부터 55까지의 수 중에서 random으로 10개의 수를 뽑아 리스트를 만들어라. 단, 리스트 내 수들은 중복되지 않아야 한다.
#(1)
import random
li = []
for _ in range(10):
a = random.randint(1, 55)
if a in li:
continue
li.append(a)
li #(2)
import random
li = []
while len(li) < 10:
i = random.randint(1,55)
if i in li: continue
else:
li.append(i)
print(li) #(3)
import random
lst = []
while True:
lst.append(random.randint(1,55))
lst = set(lst)
lst = list(lst)
if len(lst) == 10:
break
sorted(lst) - 렘덤 함수를 사용하여 [1,2,3,4,5]를 아무렇게나 썩어주라.
data=[1,2,3,4,5]
random.shuffle(data)
data- 현재 월 일 년과 시간을 출력하게 하여라.
:(1)
time.strftime('%x ,%X', time.localtime()) -> 09/14/22 ,00:41:29
(2)
time.strftime('%m/%d/%y %H:%M:%S', time.localtime())
- name = ['Lee', 'Park', 'Jeon', 'Choi']
age = [19, 22, 16, 31]
job = ['student', 'teacher', 'student', 'artist']
- name = ['Lee', 'Park', 'Jeon', 'Choi']
#(1)
a=[]
for i,j,k, in zip(name,age,job):
a.append([i,j,k])
a
->[['Lee', 19, 'student'],
['Park', 22, 'teacher'],
['Jeon', 16, 'student'],
['Choi', 31, 'artist']]
#(2)
list(zip(name, age, job))- 파일 읽은 후 5000원 이상의 메뉴를 출력하고, 김밥종류의 가격 평균을 출력해 보세요.
import pandas as pd
df = pd.read_csv("김밥천국메뉴.csv")
df
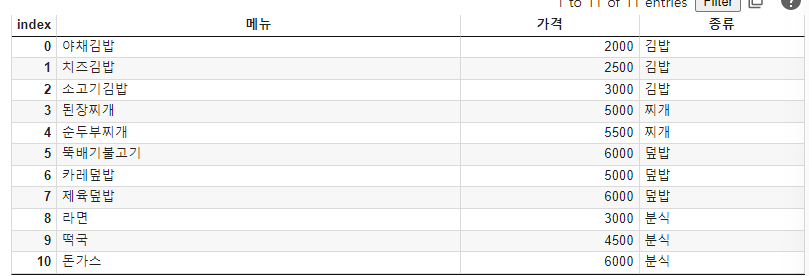
(1)
가격 5000이상. 출력하기.
df[df['가격']>=5000]['메뉴']
1)df.가격>=5000 : T/F로 나옴
2)df[df.가격>=5000 ] : 5000원 이상 전체 나옴
3)df[df.가격>=5000 ].메뉴 : 메뉴만 나옴
(2)
김밥의 가격 평균을 구하시오.
df[df.종류 == "김밥"]
import numpy as np
np.mean(df[df.종류 == "김밥"].가격)
(3)
sum = 0
count = 0
for menu, price, kind in zip(df.메뉴, df.가격, df.종류):
if price >= 5000:
print(menu)
if kind == "김밥":
sum += price
count += 1
print(f'김밥가격 평균은 {sum/count}원 입니다.') 
[오전 수업 시작 p282]
http://localhost:8888/lab/tree/9.14(7).ipynb
탭을 4개의 공백으로 바꾸기
하위 디렉터리 검색하기
(1)
import os
os.listdir()
#(2)
dirname = "Downloads"
filenames = os.listdir(dirname)
#(3)
import os
def search(dirname):
try:
filename = os.listdir (dirname)
for filename in filenames:
full_filename = os.path.join(dirname, filename)
if os.path.isdir(full_filename):
search(full_filename)
else:
ext= full_filename[-3: ]
if ext == '.py':
print(full_filename)
except PermissionError:
pass(4)
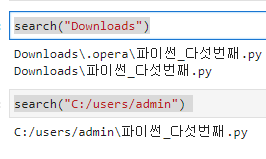
search("Downloads")
search("C:/users/admin")
[ 정규표현식 p290 ]
:복잡한 문자열을 처리할 때 사용하는 기법으로, 파이썬만의 고유 문법이 아니라 문자열을 처리하는 모든 곳에서 사용한다.
메타문자
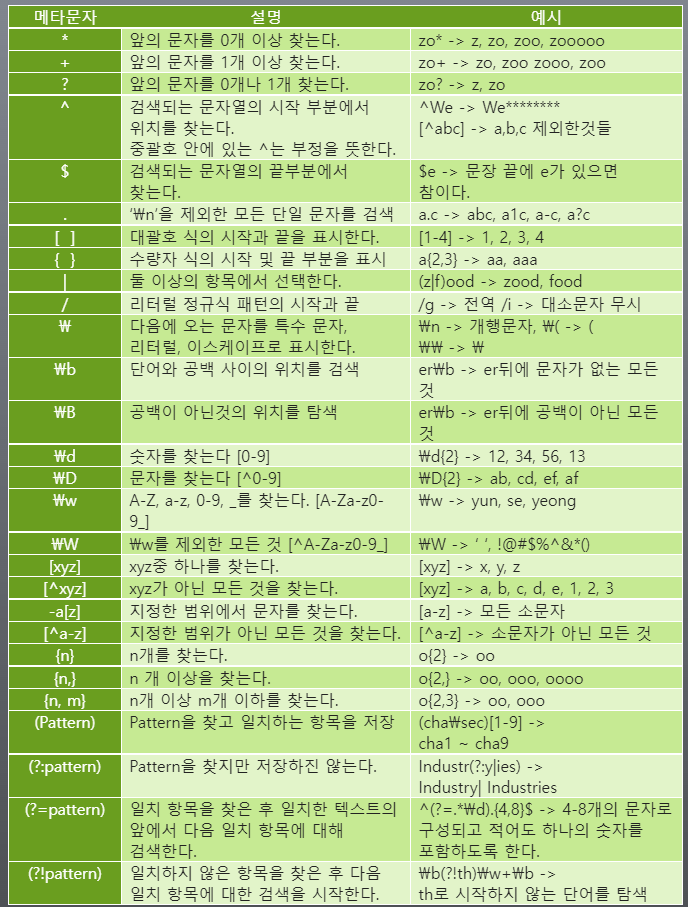
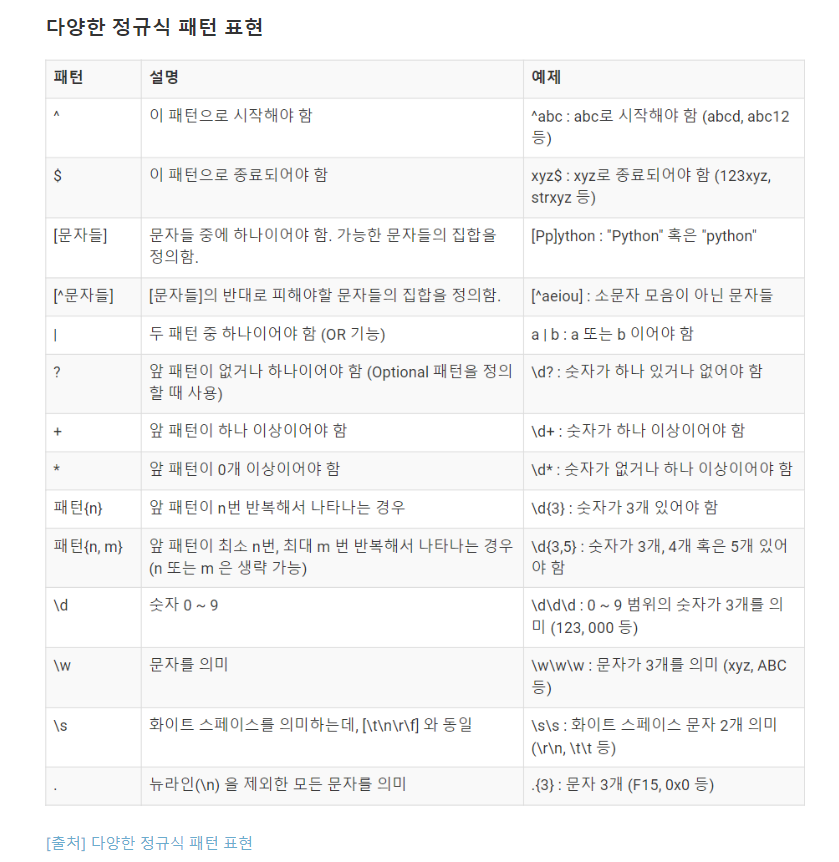
\d{6} :"숫자6개 반복 [-] \d{7}: 숫자 7개 반복"

메타문자 [] : 문자클래스, 사이의 문자들과 매치
- [a,b,c]: a또는 b또는 c
- [a-z] : a부터 z까지
- [a-z A-Z] : 모든 문자
- [0-9] : 모든 숫자
메타문자 ^
- [^ ]: not 의미, 대괄호 안에 있어야한다.
- 예) [^0-9]라는 정규 표현식은 숫자가 아닌 문자만 매치된다.
[ 오후 수업 시작 ]
메타문자 Dot(.)
: 줄바꿈 문자인 \n을 제외한 모든 문자와 매치됨을 의미한다.
- 예) a.b -> "a + 모든문자 + b"
- 예) a[.]b -> "a + Dot(.)문자 + b",
"a.b" 문자열과 매치되고, "a0b" 문자열과는 매치되지 않는다.
메타문자 반복 (*)
- 예) cat -> '' 바로 앞에 있는 문자 'a'가
0부터 무한대로반복될 수 있다는 의미
메타문자 반복 (+)
:"c + a(1번 이상 반복) + t"
- 예) ca+t -> '+'는 최소
1번 이상 반복될 때 사용한다.
메타문자 ?
: 반복은 아니지만 이와 비슷한 개념으로 ? 이 있다.
-> ? 메타문자가 의미하는 것은 {0, 1} 이다
- 예) ab?c -> "a + b(있어도 되고 없어도 된다) + c"
, +, ? 메타 문자는 모두 {m, n} 형태로 고쳐 쓰는 것이 가능하지만 가급적 이해하기 쉽고 표현도 간결한 , +, ? 메타 문자를 사용하는 것이 좋다.
메타문자 반복 고정하기 {m}
- 예) ca{2}t -> "c + a(반드시 2번 반복) + t"
메타문자 반복 고정하기{m, n}
- 예) ca{2,5}t -> "c + a(2~5회 반복) + t"
[ 파이썬에서 정규 표현식을 지원하는 re 모듈 p298 ]
: 파이썬은 정규 표현식을 지원하기 위해 re(regular expression의 약어) 모듈을 제공한다.
import re
p = re.compile('ab*')re.compile을 사용하여 정규 표현식(위 예에서는 ab*)을 컴파일한다. re.compile의 결과로 돌려주는 객체 p(컴파일된 패턴 객체)를 사용하여 그 이후의 작업을 수행할 것이다.
http://localhost:8888/lab/workspaces/auto-E/tree/9.14(7).ipynb
출처:
