
AI를 공부하면서 직접 데이터를 다뤄 실습하면서 연습해보고자 Dacon에서 제공하는 <따릉이 개수 예측하기> 주제에 참여해보았다.
몇 년 전에 전공 수업에서 ML을 다룬 이후로 오랜만에 다시 실습을 하게 되어 기초부터 차근차근 진행해보았다. 해당 대회의 문제 및 데이터 링크는 포스트 하단에 첨부하였다.
💁🏻♀️ 문제 소개
해당 문제는 train dataset에 제공되는 따릉이 id 별 대여 시점의 시간, 기온, 풍속 등의 데이터를 활용해 대여될 따릉이의 개수를 예측하는 문제이다.
0. 라이브러리, 데이터 불러오기
pandas, matplotlib 라이브러리와 DecisionTreeRegressor, RandomForestRegressor 등을 import 한다.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
# 데이터 불러오기
train = pd.read_csv('/경로/train.csv') # 모델 학습 파일
test = pd.read_csv('/경로/test.csv') # 모델 시험지 파일
submission = pd.read_csv('/경로/submission.csv') # 답안지 파일
1. EDA (Exploratory Data Analysis, 탐색적 자료 분석)
탐색적 자료 분석(EDA) 은 데이터를 다양한 각도에서 관찰하고 이해하는 과정으로, 데이터를 분석하기 전 그래프나 통계적인 방법으로 자료를 직관적으로 바라보는 과정이다.
데이터에 대해 이해하기 위해 train.csv와 test.csv 파일에 저장된 값을 출력하였다.
Train 데이터 셋은 아래와 같이 구성되며, Test 데이터는 Train 데이터에서 가장 오른쪽에 위치한 count 열을 제외한 모습이다.
Train dataset
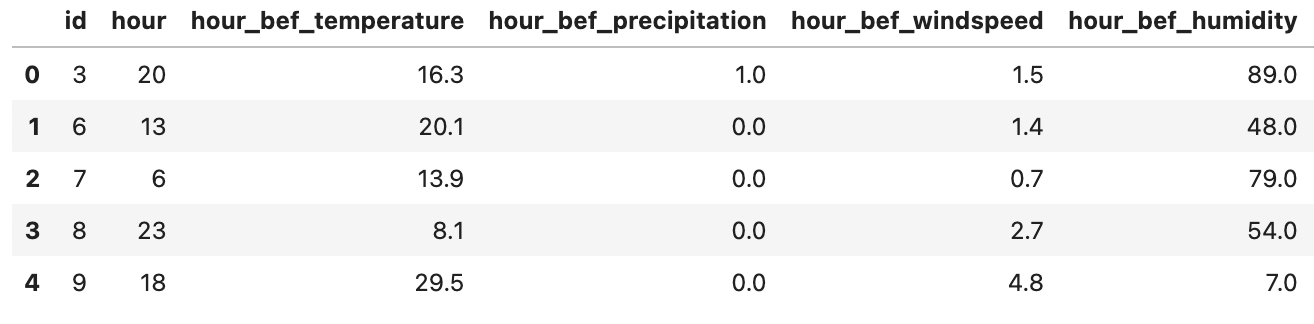
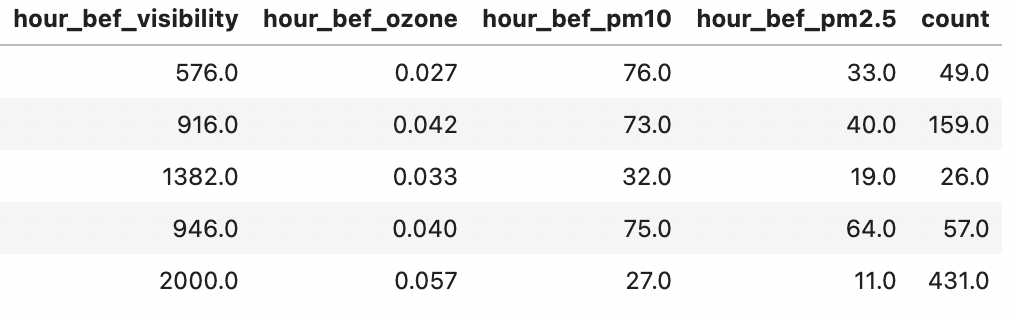
변수 소개 (attribute)

EDA에 활용한 코드는 다음과 같다.
train.head()
train.tail()
print(train.shape)
print(test.shape)
print(submission.shape)train.info() # train dataset에 대한 정보 출력
train.describe() # train dataset의 기술 통계량
test.info() # test dataset에 대한 정보 출력
test.describe() # test dataset의 기술 통계량데이터의 기술 통계량 값은 전처리 과정에서 NaN(결측치)를 보정할 때 사용한다.
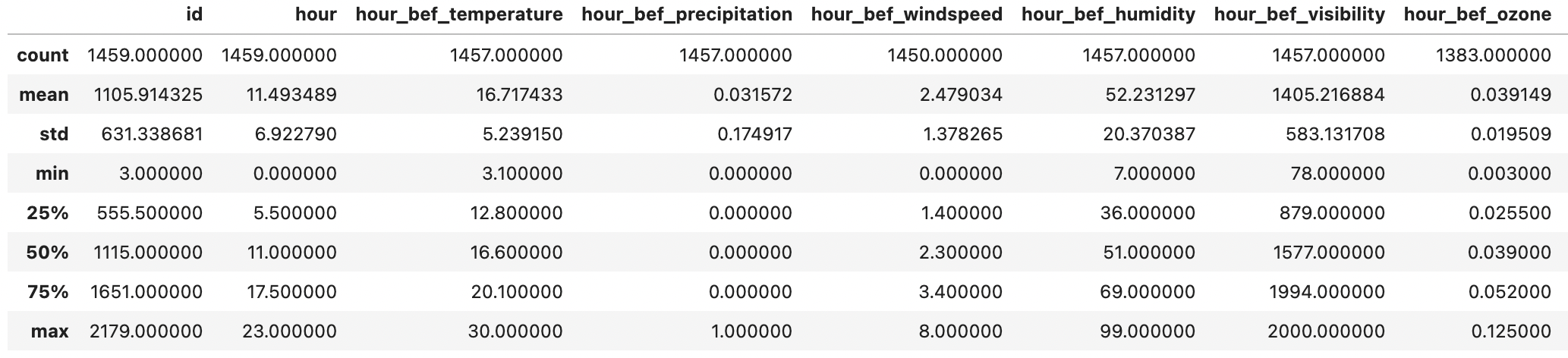
train.groupby('hour').mean() # 시간 별 각 항목에 대한 평균 값 구하기
train.groupby('hour').mean()['count'] # 시간 별 대여량의 평균
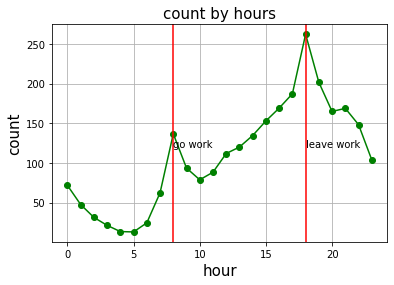
# 시간대 별 따릉이 대여량 시각화
plt.plot(train.groupby('hour').mean()['count'], 'go-')
plt.grid() # 보조선
plt.title('count by hours', fontsize=15)
plt.xlabel('hour', fontsize=15)
plt.ylabel('count', fontsize=15)
plt.axvline(8, color='r')
plt.axvline(18, color='r')
plt.text(8, 120, 'go work', fontsize=10) # 출근 시간 텍스트 입력
plt.text(18, 120, 'leave work', fontsize=10) # 퇴근 시간 텍스트 입력
# plt.savefig('picture.png) 그래프를 이미지로 저장시간대 별 따릉이 대여량을 그래프로 시각화한 결과, 오전 8시와 오후 6시에 대여량이 크게 증가한 것을 볼 수 있다. 이를 바탕으로 출퇴근, 등하교 시간에 따릉이 대여량이 크게 늘어나는 경향이 있음을 예측할 수 있다.
상관 계수
상관 계수 란 두 개의 변수가 같이 일어나는 강도를 나타내는 수치이다. -1과 1 사이 값을 가지며, 절댓 값이 0.4 이상인 경우 두 변수 간에 상관성이 있다고 해석한다.
import seaborn as sns
plt.figure(figsize=(10, 10)) # 상관관계 분석 이미지 크기 늘리기
sns.heatmap(train.corr(), annot=True)변수 간의 상관도를 분석하여 heatmap을 출력해보았을 때, 결과는 다음과 같다.
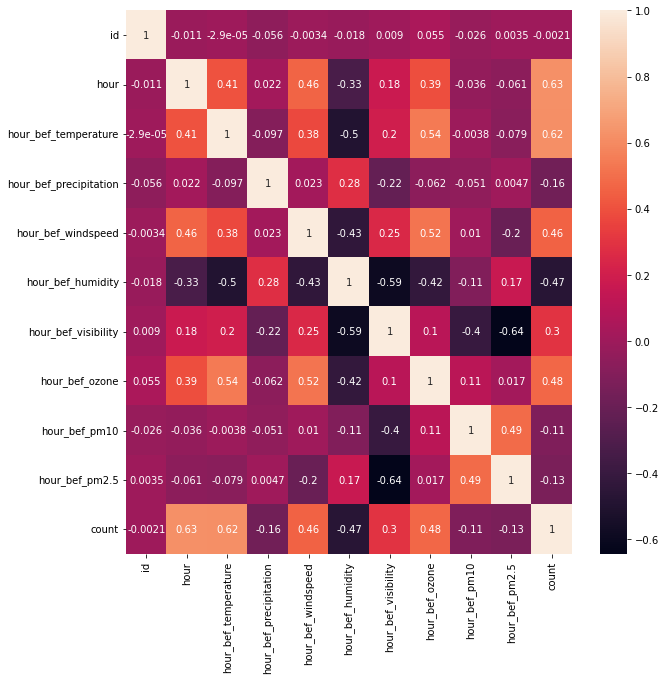
위 이미지의 count 열을 보았을 때 상관계수가 높은 변수들을 채택해 모델 생성하고자 한다. 선택한 변수는 hour, hour_bef_temperature, hour_bef_windspeed 변수이다.
2. 전처리
- Train, Test 데이터의 결측치를 확인한다. 사용할 변수에 결측치가 존재하는 경우 보정이 필요하다. 본 데이터는 hour_bef_temperature, hour_bef_windspeed에 결측치가 존재한다.
- 기온과 풍속의 경우 전체 시간의 평균 값으로 보정할 경우, 시간대 별 특징을 반영하지 못한다는 한계가 존재한다. 따라서 시간대 별 기온 및 풍속의 평균을 내어 해당 시간대에 맞는 수치로 값을 보정하였다.
train.isna().sum() # isna() 와 isnull()과 같음
train[train['hour_bef_temperature'].isna()] # 결측치인 행만 출력
# 자정, 오후 6시에 hour_bef_temperature의 값이 비어있음
# 온도의 경우, 평균 값으로 넣으면 해당 시간의 특성을 반영하지 못함
train.groupby('hour').mean()['hour_bef_temperature'].plot() # 시간 별 온도 평균 출력
plt.axhline(train.groupby('hour').mean()['hour_bef_temperature'].mean()) # 전체 시간에 대한 평균 온도 출력 (일직선)시간대 별 평균 기온 vs 하루의 평균 기온
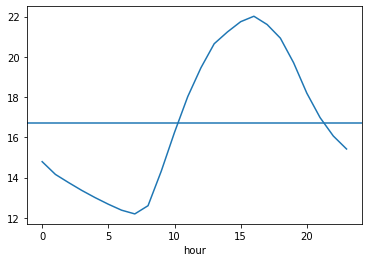
train.csv 데이터에서는 0시와 18시의 기온 데이터가 결측치 값이었는데, 만약 평균 기온을 대체했다면 해당 시간대의 기온과 큰 오차가 있어 예측 결과의 정확도가 떨어졌을 것이다.
train['hour_bef_temperature'].fillna({934: 14.788136, 1035: 20.926667}, inplace=True)
# 각 시간 별 평균 기온을 출력해서 해당 값으로 NaN 값이 있는 정오, 18시 행의 hour_bef_temperature 값을 넣어줌
# 934번째 행, 1035번째 행
# inplace=True 옵션을 사용해야 값이 저장됨위 같은 방법으로 train, test 데이터에 대한 결측치 값을 모두 보정해준다.
3. 모델링
변수 선택 및 모델 구축
개수 변수와 상관도가 높았던 시간, 기온, 풍속 변수를 feature로 선택하였다.
features = ['hour', 'hour_bef_temperature', 'hour_bef_windspeed']
X_train = train[features]
Y_train = train['count']
X_test = test[features]
print(X_train.shape)
print(Y_train.shape)
print(X_test.shape)
# hyperparameter
# n_estimators : 트리 개수
# n_jobs : 사용할 cpu 개수 (-1로 설정하면 가장 많은 cpu 사용 가능)
# max_depth: 모델의 과대 적합 방지를 위한 깊이 설정 변수
# random_state : random 성질을 고정시킴
# 해당 데이터에 가장 적합한 hyparameter 옵션을 찾는 과정 => tuning
model100 = RandomForestRegressor(n_estimators=100, random_state=0) # Decision Tree 모델을 여러 개 모아서 만든 것 = Random Forest
model100_5 = RandomForestRegressor(n_estimators=100, max_depth = 5, random_state=0)
model200 = RandomForestRegressor(n_estimators=200)
# DecisionTreeClassifier 모델 활용
import sklearn
from sklearn.tree import DecisionTreeClassifier
model_dtc = DecisionTreeClassifier(random_state=0)
model_dtr = DecisionTreeRegressor()모델 학습
RandomForestRegressor, DecisionTreeRegressor, DecisionTreeClassifier의 hyparameter를 일부 조절하며 5개의 모델을 생성해 학습하였다.
model100.fit(X_train, Y_train)
model100_5.fit(X_train, Y_train)
model200.fit(X_train, Y_train)
model_dtc.fit(X_train, Y_train)
model_dtr.fit(X_train, Y_train)모델 예측
ypred1 = model100.predict(X_test)
ypred2 = model100_5.predict(X_test)
ypred3 = model200.predict(X_test)
ypred4 = model_dtc.predict(X_test)
ypred5 = model_dtr.predict(X_test)4. 결과 제출
데이콘의 경우, 문제에서 제공하는 submission.csv 파일에 정답을 저장하여 최종 제출해야 한다. 답을 제출하면 자체적으로 보유한 정답 데이터와 유사도를 비교해 점수를 측정해준다.
submission['count'] = ypred1
submission.to_csv('model100.csv', index=False)
submission['count'] = ypred2
submission.to_csv('model100_5.csv', index=False)
submission['count'] = ypred3
submission.to_csv('model200.csv', index=False)
submission['count'] = ypred4
submission.to_csv('model_dtc.csv', index=False)
submission['count'] = ypred5
submission.to_csv('model_dtr.csv', index=False)📝 제출 결과
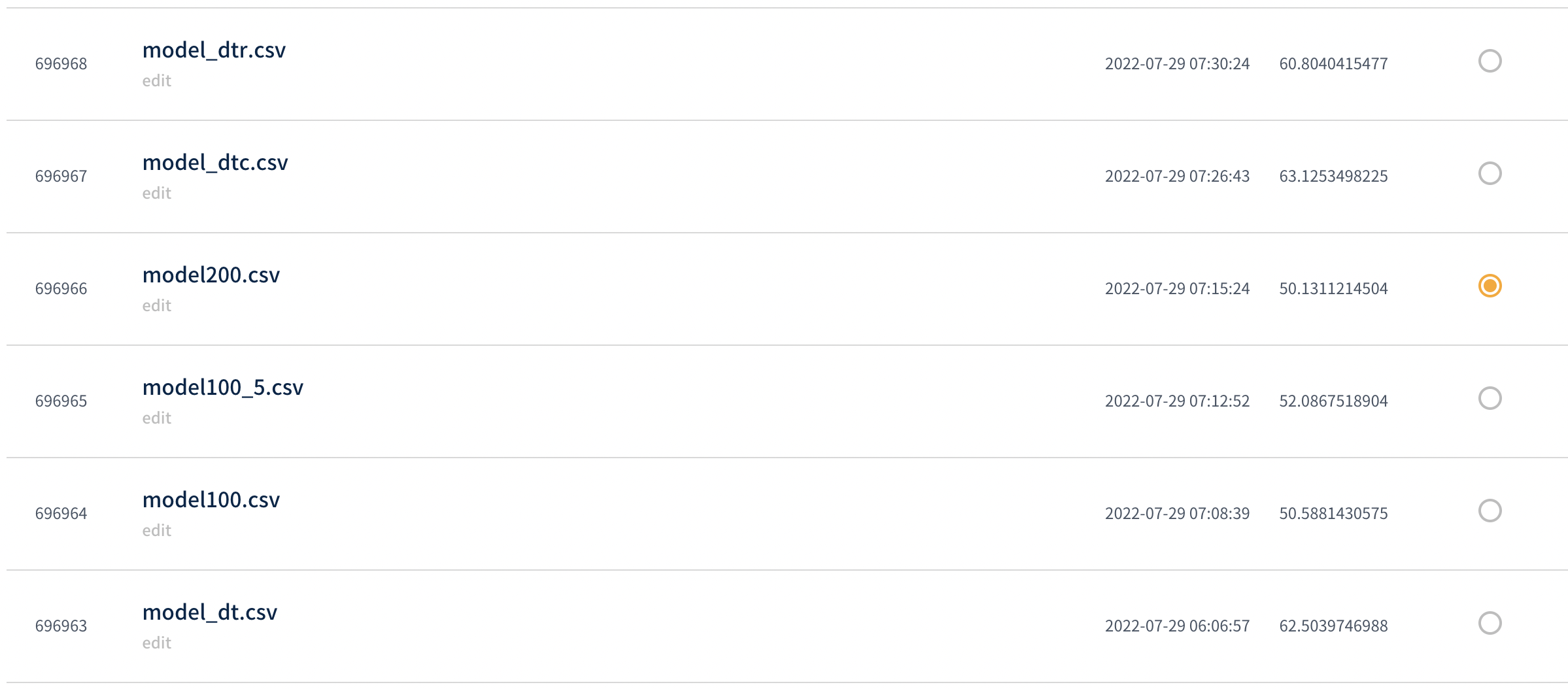
아직 기초적인 부분만 공부하여 코드를 작성해 점수가 높지는 않다. 모델을 더욱 발전시켜 성능을 향상시킬 것이다 😊
(점수는 데이콘이 보유한 실제 데이터와의 오차를 의미하며, 낮은 값일수록 오차가 적음을 나타낸다. 즉, 점수가 낮을 수록 좋은 성능의 모델인 것이다.)
👩🏻💻 소스 코드
보다 자세한 설명은 깃허브에 정리하여 업로드해 놓았다. <코드 보기>를 통해 확인 가능하다.
👏 마무리
hyperparameter의 값을 조절할 때마다 모델의 테스트 결과에 대한 정확도가 달라진다.
다음 번에는 이번에 사용한 Random Forest Regressor, Decision Tree Regressor, Decision Tree Classifier에 대한 hyparameter에 대해 공부하고, 이를 조절해가면서 해당 데이터 셋에 대한 가장 최적화된 hyparameter 값을 찾아볼 것이다.
Reference
🚲 Dacon 서울시 따릉이 대여량 예측 경진대회
https://dacon.io/competitions/open/235576/overview/description
🚲 Dacon 따릉이 데이터를 활용한 데이터 분석 강의 영상
https://www.youtube.com/watch?v=WreGAJxukpA
https://www.youtube.com/watch?v=7IbTi1QicHU
https://www.youtube.com/watch?v=FrzmkRKDyjA
