오늘은 인공지능 프로그래밍 시간에 배웠던 딥러닝 모델 성능 검증에 대해 알아보자.
1. Train set과 Test set
정의
Train set은 우리말로 학습셋이고 모델이 학습을 하는 데이터를 말한다.
Test set은 우리말로 테스트셋이고 학습한 후에 테스트를 하는 데이터를 말한다.
왜 둘을 구분할까?
학습셋 만으로 머신러닝을 진행하면 과적합이 발생할 수 있다. 머신 러닝의 최종 목적은 과거의 데이터를 토대로 새로운 데이터를 예측하는 것이다. 즉, 새로운 데이터에 사용할 모델을 만드는 것이 최종 목적이므로 테스트셋을 만들어 정확한 평가를 병행하는 것이 매우 중요하다.
어떻게 할 수 있을까?
학습셋과 테스트셋을 사용하여 학습하는 방법을 코드를 통해 알아보자.
from sklearn.model_selection import train_test_split
# 학습셋과 테스트셋을 구분합니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)
score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])scikit-learn을 활용해서 위와 같이 학습셋과 테스트셋을 구분하고 테스트 예측률을 확인할 수 있다.
2. Train 예측률과 Test 예측률
어떤 것이 더 중요할까?
앞에서도 설명했듯이, 딥러닝, 머신 러닝의 목표는 학습셋에서만 잘 작동하는 모델을 만드는 것이 아니다. 새로운 데이터에 대해 높은 정확도를 안정되게 보여 주는 모델을 만드는 것이 목표이다. 즉, 당연히 Train 예측률 보다 Test 예측률이 더 중요하다.
은닉층에 따라 어떻게 변화할까?
은닉층이란 입력층과 출력층 사이의 계층을 말한다.
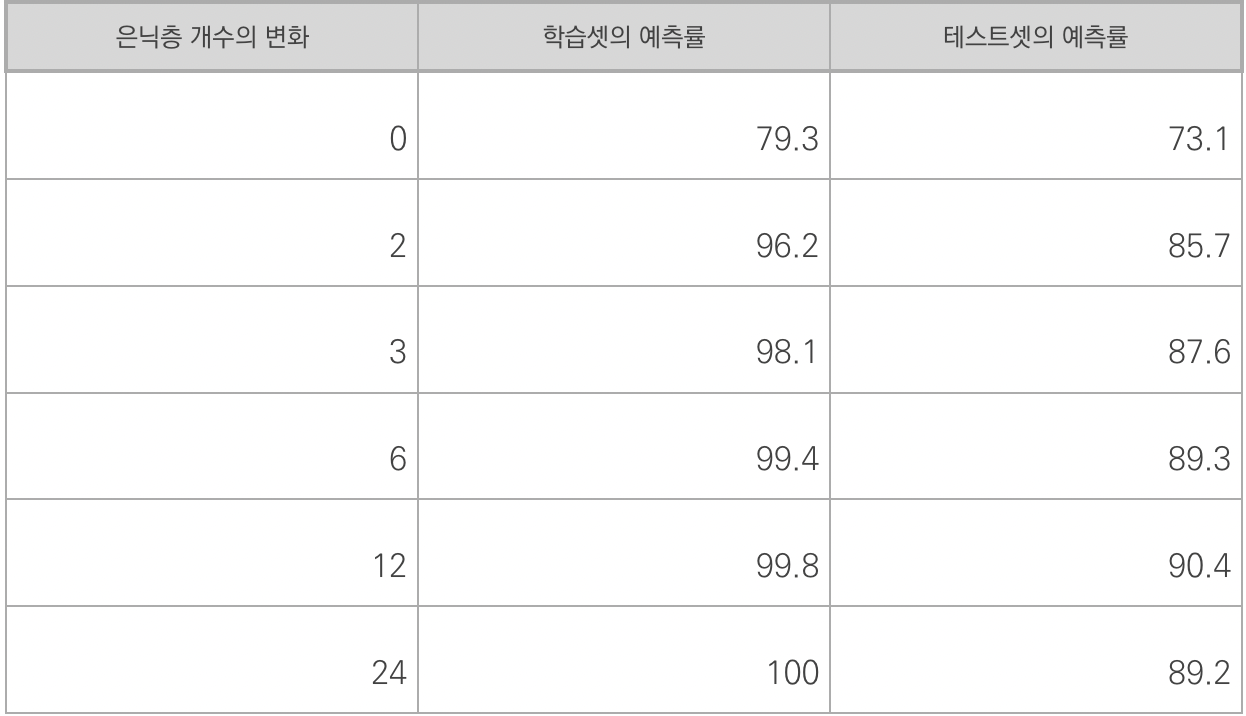
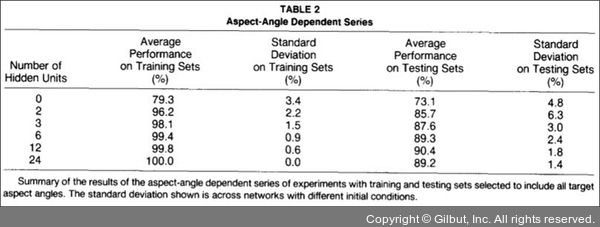
위 표에서 보이듯이, 은닉층이 늘어날수록 학습셋의 예측률이 점점 올라가다가 결국 24개의 층에 이르면 100% 예측률을 보인다. 테스트셋 예측률은 은닉층의 개수가 12개일 때 90.4%로 최고를 이루다 24개째에서는 다시 89.2%로 떨어지고 만다. 즉, 식이 복잡해지고 학습량이 늘어날수록 학습 데이터를 통한 예측률은 계속해서 올라가지만, 적절하게 조절하지 않을 경우 테스트셋을 이용한 예측률은 오히려 떨어지는 것을 확인할 수 있습니다.
