Apache Kafka는 대용량의 실시간 데이터 스트림 처리를 위한 분산 메시징 시스템입니다.
Kafka를 통해 서버 간 비동기 통신을 구현하고, 대량의 데이터를 빠르고 안정적으로 처리할 수 있습니다.
Kafka 메시지 처리의 기본 흐름
- 메시지 생성 및 전송
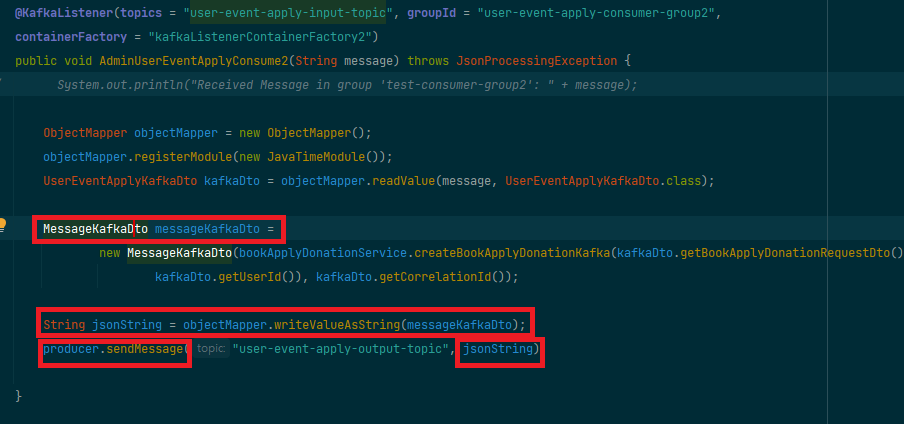
프로듀서는 메시지를 생성하고 이를 Kafka 토픽의 특정 파티션에 전송합니다.
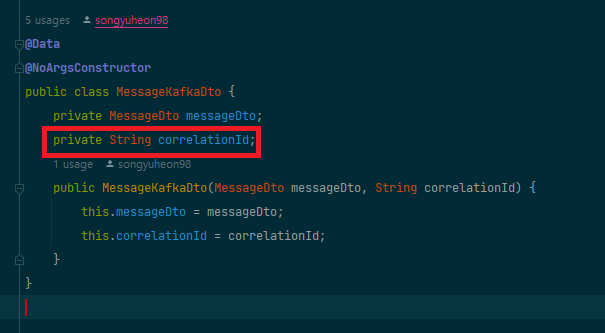
메시지는correlationId같은 식별 정보를 포함하고 있어, 나중에 처리 결과를 정확히 매칭할 수 있습니다.
- 메시지 저장

Kafka 서버는 받은 메시지를 파티션에 저장합니다.
- 메시지 소비
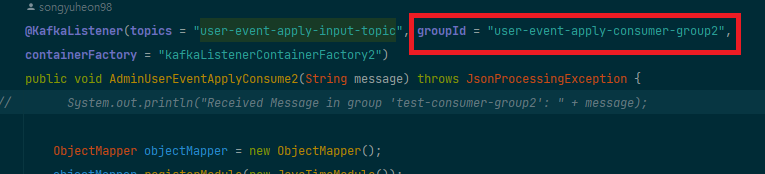
컨슈머는 컨슈머 그룹 ID를 설정하여 Kafka 서버에 연결하고 메시지를 소비합니다.
Kafka는 이 ID를 기반으로 각 컨슈머에게 파티션을 할당합니다.
- 비즈니스 로직 처리
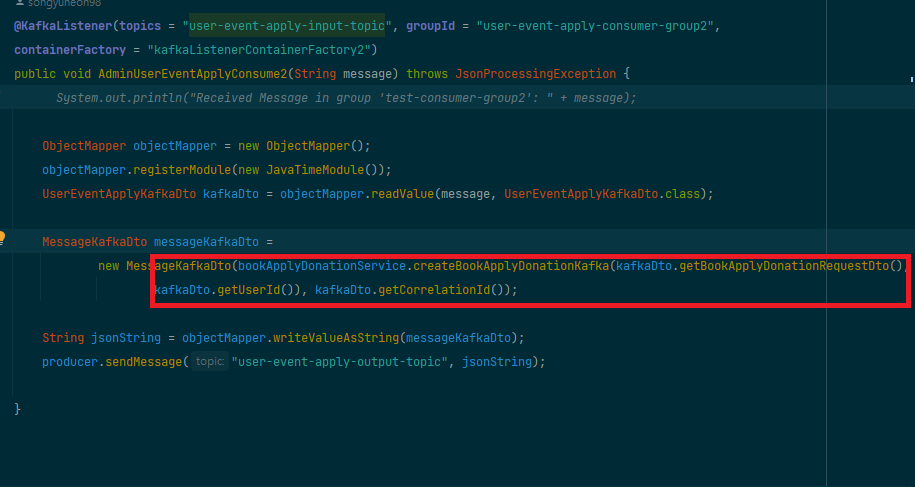
컨슈머는 받은 메시지를 바탕으로 필요한 비즈니스 로직을 처리합니다.
- 결과 전송
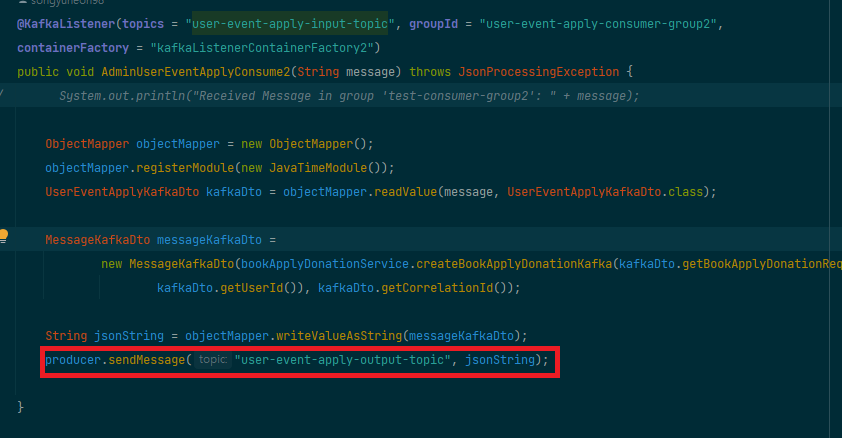
처리 결과는 새로운 메시지로 생성되어 결과 토픽에 전송됩니다.
이 메시지에는 원래 메시지와 동일한correlationId가 포함됩니다.
- 결과 소비 및 처리
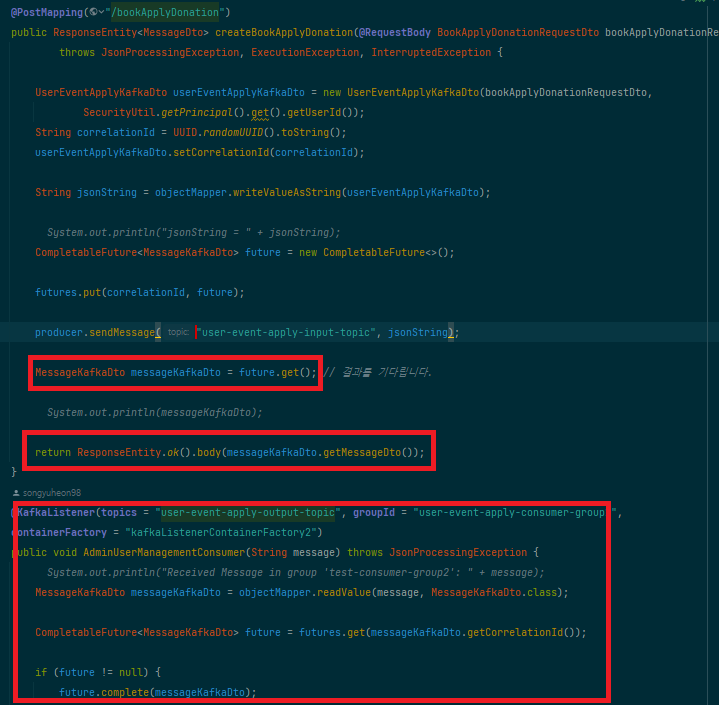
결과를 처리하는 컨슈머는 결과 토픽에서 메시지를 소비하고,correlationId를 확인하여 관련된 결과만을 처리합니다.
- 클라이언트로 응답
마지막으로, 처리된 결과를 바탕으로 클라이언트에게 응답을 보냅니다.
서버 조합별 컨슈머 그룹 ID 설정의 중요성
메인 서버와 트래픽 서버를 각각 여러 대 사용할 때, 각 서버 조합별로 별도의 컨슈머 그룹 ID를 설정하는 것이 중요합니다.
이렇게 설정함으로써 메시지는 정확한 대상에 의해 처리되고, 메인 서버에서는 올바른 처리 결과를 받아 클라이언트에게 전달할 수 있습니다.
컨슈머 그룹 ID를 통한 메시지 처리 최적화
컨슈머 그룹 ID를 설정하면, Kafka는 여러 가지 최적화를 수행할 수 있습니다.
-
파티션 할당
컨슈머 그룹 내에서 각 컨슈머는 유일한 파티션을 할당받아 메시지를 처리합니다. -
오프셋 관리
컨슈머들은 처리한 메시지의 오프셋을 저장하여, 장애 발생 시 중단된 위치부터 처리를 재개할 수 있습니다. -
라운드 로빈 파티션 할당
컨슈머 수가 파티션 수보다 적을 때, 각 컨슈머는 여러 개의 파티션을 할당받을 수 있습니다. -
재조정
컨슈머 그룹 내의 컨슈머 수에 변화가 있을 때, Kafka는 파티션 할당을자동으로 조정합니다. -
동일한 메시지를 한 번만 처리
컨슈머 그룹을 통해 메시지가중복 처리되는 것을 방지합니다.
정리
Kafka에서 컨슈머 그룹 ID를 적절히 활용하면, 메시지 처리의 효율성과 정확성을 높일 수 있습니다.
특히 대규모 분산 환경에서는 이러한 최적화가 더욱 중요해진다고 생각합니다.

backend_Devloper