PPT 순서
- AIOps란? =>
- AIOps 필요한 이유 =>
- 장.단점 =>
- 도입 효과 =>
- AIOps 기능 (이상징후 탐지, 적정자원 관리) 메트릭,로그,트레이싱 =>
- 시계열 데이터, 종류 =>
- 근본원인 분석 =>
- 경쟁사 DataDog 성장 배경, 이유, 최신 발표 =>
- 심포니AI 아키텍처 =>
- ElasticSearch, 흐름 설명 =>
- 개선점
Aiops 란 (Artificial intelligence for IT Operations)는 IT 운영을 향상시키기 위한 인공지능(AI)애플리케이션임
AIOps는 빅데이터,분석 및 머신 러닝 기능을 사용한다.
빅데이터 분석, 머신러닝(ML)등 인공지능(AI) 기술을 활용해 공통 정보기술(IT) 이슈의 파악과 해결을 자동화하는 총칭이다.
대기업의 시스템, 서비스 및 애플리케이션은 방대한 양의 로그 및 성능 데이터를 생산한다.
AIOps는 이 데이터를 사용하여 자산을 모니터링하고 IT 시스템 외부와 무관하게 종속성에 대한 가시성을 확보한다.
AI옵스는 IT 운영 관리에 인공지능을 적용한 것이다. 인프라, 네트워크, 애플리케이션을 지능적으로 관리할 수 있다. AI옵스는 문제 발생 시 실행되는 경보 시스템과 수동으로 처리하는 기존 방식을 AI와 ML 시스템으로 전환한다. 이를 통해 IT 운영 관리를 좀 더 효율화하는 것은 물론 부정적인 영향을 미칠 수 있는 사건·사고를 미연에 예측할 수 있게 해준다.
AIOps 플랫폼은 다음 세가지 기능을 기업에 제공해야 함
1. 일상적인 실천을 자동화한다.
2. 인간보다 더 빠르고 정확하게 심각한 문제를 인식한다.
3. 데이터 센터 그룹과 팀 간의 상호 작용을 강조한다.




AI기술을 IT운영에 접목한 것으로, "IT운영을 위한 인공지능"을 뜻 함
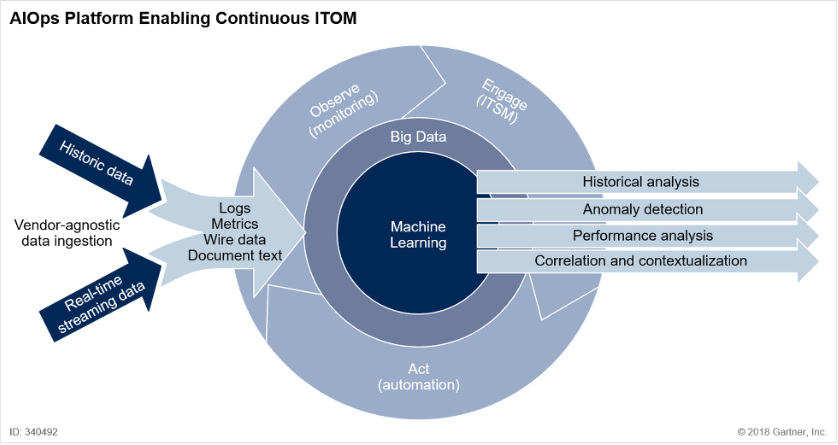
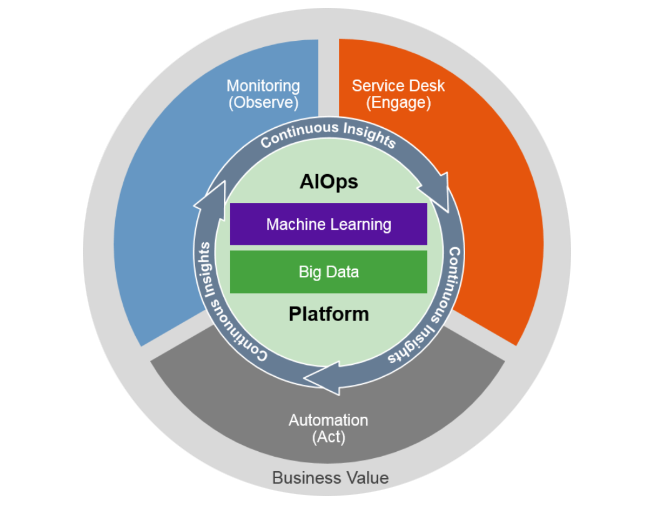
가트너는 위 그림과 같이 AIOps가 IT운영 전반에 걸쳐 지속적인 통찰을 가능하게 한다고 설명함
AIOps에서 Logs, Text, Wire, Metrics, API등응 데이터 우형들을 처리하여 다음과 같이 활용할 수 있습니다.
Causal Analysis(인과관계 분석)
Anomaly detection(이상 탐지)
Performance analysis(성과 분석)
Prediction(예측)
Correlation and contextualization(상관관계와 맥락화)
Intelligent Remediation(지능적 개선)
도입 효과
1. 업무의 효율성 증가
일상적이고 반복적인 업무를 자동화하여 업무의 효율성을 증가시킴
운영을 효율화 할 수 있는 업무에 집중 가능
2. 운영 비용 감소 & 안정적이고 예측 가능한 인프라 제공
분석과 예측을 통해 최적화된 자원을 사용함으로써 운영 비용을 최소화, 안정적이고 예측 가능한 운영 가능
3. 기타 부서와의 협업 최대화
각 팀에게 관련 데이터를 제공, 데이터 기반으로 한 의사결정이 가능
이상징후 탐지 Anomaly Detection
이상징후 탐지는 어떤 데이터 안에서 다른 관측값들과 다른 방법에 의해 성성되었다고 의심되는 이상치를 탐지 하는 데이터 분석 기법이다.
지도학습·준지도학습·비지도학습 방식으로 이상 현상을 탐지합니다.
이상징후 탐지는 웹 애플리케이션 환경 내에서 비정상적이거나 예상치 못한 이벤트 및 측정을 식별하는 효과적인 수단이다.
적정자원 관리 - Right Sizing
적절한 양의 리소스를 요청하여 사용하지 않는 리소스에 대해 초과 비용을 지불하지 않고 가변 로드를 처리하기에 충분한지 확인해야함
컴퓨팅 리소스는 비용이 많이 들기 때문에 가능한 한 인프라 관련 지출을 최소화하기를 원함
그러나 리소스 절약으로 인해 성능 문제가 발생하거나 심지어 가동 중지 시간이 발생하면 비즈니스는 이익을 놓치게 된다.
지출 최적화와 성능을 수용 가능한 수준으로 유지하는 것 사이에서 조정하는 것이 올바른 크기 조정 프로세스가 해결하려는 문제이다.
정리하자면,
- 과잉 할당은 클라우드 인프라의 비효율적인 활용과 실제로 사용되지 않는 리소스에 대한 초과 지불로 이어진다
- 과소 할당은 성능 문제 또는 호스팅된 프로젝트의 다운타임을 유발하는 리소스 부족을 초래하여 최종 사용자 경험 저하, 고객 누락 및 수익 손실로 이어진다.
Datadog

데이터독Datadog은 서버, 데이터베이스, 클라우드 서비스 등에 대한 다양한 모니터링 서비스를 제공하는 클라우드 모니터링 애플리케이션을 대표하는 서비스 중 하나입니다
데이터독은 서버 상태를 모니터링하는 기능을 시작으로, 아마존 웹 서비스, 마이크로소프트 애저, 구글 클라우드 서비스들의 서비스와 통합 기능을 제공하고, 에이전트의 확장 기능을 통해 데이터베이스, 캐시 스토어 등 다양한 애플리케이션에 대한 추가적인 메트릭 수집과 모니터링을 지원함
알람, 대시보드, 로그 수집, APM, 네트워크 트래픽 모니터링, 앤드포인트 모니터링 등을 지원하는 종합 모니터링 서비스로 확장해나가고 있음
datadog-agent
데이터독에서는 서버와 추가적인 모니터링을 수행하는 데이터독 에이전트를 개발하고 있음.
데이터독 에이전트는 모니터링하고자 하는 서버에 설치해서 해당 서버의 정보를 수집하는 역할을 함
인프라스트럭처 모니터링
기본 기능
특정 호스트에 데이터독 에이전트를 설치하면 자동적으로 해당 서버의 시스템 정보를 수집
APM(Application Performance Management)
애플리케이션을 내부에 심어, 애플리케이션의 성능을 분석하는 서비스
로그 수집 및 관리
실시간 로그 수집 및 모니터링을 구축할 수 있음
데이터독 에이전트에서 로그 수집을 활성화하면 로그를 전송할 수 있음.
신테틱스(Synthetics)
데이터독의 외부 헬스 체크 서비스
API 테스트와 블라우저 테스트를 제공하며, 업타임을 확인하고, 특정 리전에서의 접속 문제나 퍼포먼스 이슈를 지속적으로 파악할 수 있음
네트워크
네트워크 모니터링 기능을 사용할 수 있음
네트워크 모니터링 기능을 통해서 트래픽의 흐름을 추적하거나 정상적이지 않은 네트워크 현황을 파악하는 것이 가능함
메트릭(Metrics) / 대시보드(Dashiboard) / 모니터(Monitor)
다양한 인터그레이션을 통해 수집되는 메트릭들을 검색하고 확인하는 것이 가능하며 이 메트릭을 기반으로 대시보드를 구성하거나 모니터(알람)을 만들 수 있음
대시보드는 그래프를 포함한 다양한 형식의 위젯들로 구성하게 됨
대시보드는 크게 타임보드와 스크린보드 두 가지 형식으로 나뉨
타임보드 형식의 대시보드에서는 모든 위젯이 같은 시간 범위를 공유함
스크린보드 형식의 대시보드에서는 개별 위젯이 고유의 시간 범위를 가질 수 있으며 위젯의 위치도 자유롭게 배치 할 수 있음.
데이터 독 이상 탐지
이상 감지는 추세, 계절별 요일 및 시간 패턴을 고려하여 메트릭이 과거와 다르게 동작하는 시기를 식별하는 알고리즘 기능
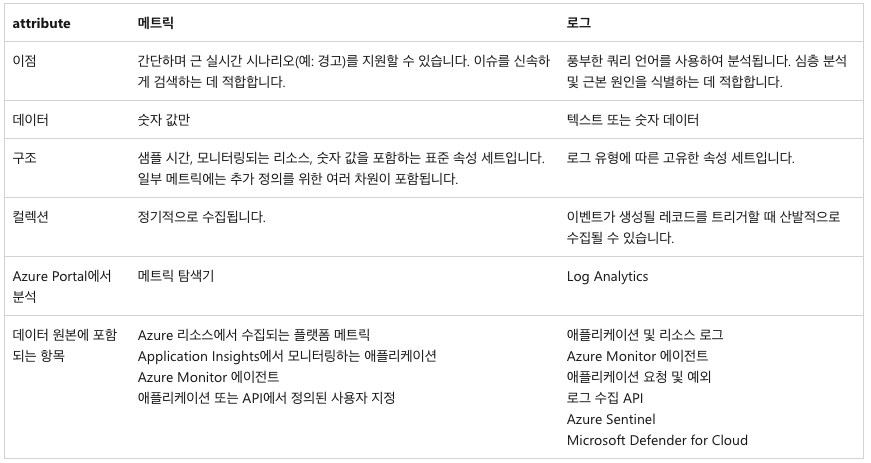
메트릭과 로그의 차이
메트릭은 특정 기준에 대한 수치를 나타냄
로그: 오류 보고 및 관련 데이터를 중앙 집중식으로 추적하는 것, 어떤 오류인지 파악하기 위해 사용하는 데이터를 의미함
메트릭 : 시간상 특정 지점에서 시스템의 일부 측면을 설명하는 숫자 값임, 이러한 데이터는 일정한 간격으로 수집되며 타임스탬프, 이름, 값 및 하나 이상의 정의 레이블로 식별됨.
Monitoring 은 Application에서 일정 항목에 대해서 수치를 측정하고 집계 및 분석 하여 시스템이 작동합니다.
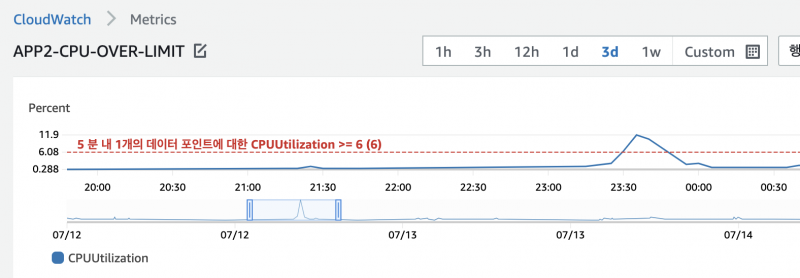
이런식으로 CPU Utilization 의 5 Minute Average 가 6이 넘는경우, 서버를 자동 증설함
Metric 측정 -> Monitoring -> Response, Reaction, Notification 방식으로 처리됩니다.
이 방식의 주요 사용처는 Auto Scaling 입니다.
로그 : 시스템 내에서 발생한 이벤트임. 다른 종류의 데이터를 포함할 수 있으며 타임스탬프를 사용하는 구조적 또는 자유 형식 텍스트일 수 있음.
환경의 이벤트가 로그 항목을 생성할 때 산발적으로 만들어질 수 있음
로깅의 목적은 오류 보고 및 관련 데이터를 중앙 집중식으로 추적하는 것입니다.
관련이 없거나 주의를 산만하게 하는 정보를 포함해서는 안 됩니다.
- 누가 로그 파일을 사용하는지 (주로 시스템관리자가 분석 및 모니터링하는 용도로 사용함)
- 로그 파일을 사용해서 문제 발생을 예방하고, 문제 발생시 추적할 수 있는지 (쓸모가 있어야함)
- 로그의 중요성에 따라 구분해야 하는지? (general_log, audit_log 등. 중요한 이벤트는 따로 로깅하자.)
- 새로운 이벤트가 즉시 기록될 필요는 없음. (일반적으로 수초 ~ 수분의 딜레이가 있음)
Tracing
애플리케이션에 대한 훨씬 더 넓고 지속적인 보기를 포함함
추적의 목표는 프로그램의 흐름과 데이터 진행을 따르는 것, 따라서 더 많은 정보가 있음
Tracing은 프로세스의 최적화에 중점을 둠. 스택을 추적하여 개발자는 병목 현상을 식별하고 성능 개선에 집중할 수 있음

- 함수 이름
- 함수의 실행시간
- 전달된 파라미터
- 호출 경로 (call stack)
의 정보를 가지고 있음
이상적으로는 모든 서비스 동작에 대해 Tracing을 하는것이 좋습니다. (tracing 부하가 생각보다 많이 걸리지는 않음)
Tracing 을 도입하기 어려운 경우
- 복잡한 레이어 (사용자 여정 기록이 쉽지 않음)
- 소프트웨어 엔진마다 구현해야함
- (코드/ 프로젝트의) 디자인 모델, 푸쉬 모델 (특히, 비동기 방식의 Domain Driven이나, Event Driven 방식) (데이터 처리되는 방식이 추적이 어려움)
요약
Logging 은 Event 에 대한 단순기록. human readable 할 수도 있고, json 형태의 기록일 수도 있음.
Tracing 은 특정 사용자의 하나의 관통화된 이벤트들의 기록.
Monitoring 은 Metric 을 측정하고, 계산식에 따라서 진단 하는것.
https://blog.lael.be/post/11224 로그, 트레이싱, 메트릭 차이
이러한 작업들의 목적
Investigate(Diagnostics) 가 목적입니다. 조사할 수 있고, 진단할 수 있는 것이 목적입니다. Investigate 후 장애상황 발생시, Alarm과 연동하면 MTTD를 줄일 수 있습니다. (Tracing 사용시 MTTR도 줄일 수 있음)
시계열 데이터?
엘라스틱 서치?
시계열 데이터란? & 시계열의 종류
시계열 데이터란 일정한 시간동안 수집 된 일련의 순차적으로 정해진 데이터 셋의 집합임
시계열 데이터의 특징: 시간에 관해 순서가 매겨져 있음, 연속한 관측치는 서로 상관관계를 갖고 있음
시계열 데이터의 분석 목적
시계열이 갖고 있는 법칙성을 발견해 이를 모형화하고, 또 추정된 모형을 통하여 미래의 값을 forecasting 하는 것
시계열 자료의 종류
- POS(Point of sales)구매 자료(불규칙적인 시차)
- 일일 코스피 주식가격
- 월별/분기별/연도별 특정 사건의 수치(규칙적인 시차)
이런식으로 시계열 자료를 볼 때 y축을 확인하여 노이즈 값에 영향을 많이 받는가를 확인해야 함
시계열의 종류
- 추세 변동
- 계절 변동
- 순환 변동
- 불규칙 변동
- 추세변동
- 시계열의 장기간에 걸친 점진적이고 지속적인 변화 상태를 나타낸 것을 의미함
- 시간의 흐름에 따른 시계열자료들의 상승경향이나 하강경향의 상태를 의미
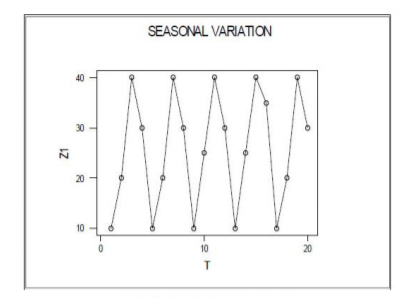
- 계절변동
- 관측된 시계열 자료들을 일 년 단위 혹은 더 짧은 기간의 주기로 기록했을 때 기후 등과 같은 자연의 조건, 사회적 관습, 혹은 제도 등의 영향을 받아서 계절적인 차이를 나타내는 것
- 시계열 자료에서 주기적인 패턴을 갖고 반복적으로 나타나는 주기변동
- 보통 분기별, 월별 자료에서 나타
- 순환변동
- 경기변동이라고도 함
- 수년간의 간격을 두고 상승과 하락이 주기적으로 나타나는 변동으로 의미
- 기후조건, 사회적 관습 등과 같은 계절 변동으로 설명되지 않는 장기적인 주기변동
- 순환변동을 계절변동과 혼동할 수 있겠지만, 계절변동으로 설명되지 않는 장기적인 변동을 주기변동을 뜻함

- 불규칙변동
- 사전적으로 예상할 수 없는 특수한 사건에 의해 야기 되는 변동(지진, 전쟁, 홍수, 파업)
- 명확히 설명될 수 없는 요인에 의해 발생되는 우연변동(시계열 데이터 랜덤한 것인지를 확인할 필요가 있음)
근본원인 분석
근본 원인 분석(Root Cause Analysis, RCA)란 적절한 해결책을 찾기 위해 문제의 근본 원인을 밝혀내는 프로세스임.
RCA는 표면적인 원인과 결과를 넘어, 프로세스 또는 시스템이 어디서 실패했는지 또는 애초에 어디서 문제가 일어났는지를 보여줄 수 있음
목표 및 이점
- 문제나 사건의 근본 원인을 발견하는 것
- 근본 원인 내에서 모든 근원적인 문제를 해결 및 보완하는 방법을 이해하거나, 거기서 새로운 지식을 얻는것
- 이 분석을 통해 알게 된 내용을 적용하여 항후 문제를 체계적으로 방지하거나 계속해서 성공적인 결과를 얻는 것
이는 최신 엔터프라이즈 애플리케이션의 다양한 시스템에 문제가 어떻게 파급될 수 있는지 추적하는 플로우차트를 생성한다. 과부하에 걸린 데이터베이스가 API 게이트웨이 속도를 늦추고 웹 서비스를 마비시켰다고 가정해보자. 여기서 자동화된 워크플로우 카탈로그는 문제 발생 과정을 추적하고 문서화해 팀이 실제 문제를 신속하게 파악할 수 있도록 지원한다.
앱다이나믹스(AppDynamics)
시스코 산하 사업부인 ‘앱다이나믹스’는 성능 모니터링을 전문으로 한다(시스코가 이 회사를 지난 2017년 미화 37억 달러에 인수했다). 앱다이나믹스는 플랫폼에 머신러닝을 추가해 과거 기준에서 벗어나는 지표를 감시한다.
해당 시스템은 플로우 차트를 생성하고 이벤트가 어떻게 시스템 장애까지 이어졌는지 학습해 근본 원인을 파악하는 데 도움을 준다. 또한 일반적인 장애 해결을 자동화할 수 있는 링크를 제공하며, 이러한 지표를 비즈니스 결과(예: 매출 등)와 상호 연계할 수 있도록 지원한다.
데이터독(DataDog)
최근 ‘데이터독’은 성능 관리 도구에 워치독(Watchdog) 모듈을 추가했다. 이를 통해 데브옵스 팀은 성능 장애가 발생하기 시작하면 자동으로 경고를 받을 수 있다.
이 도구는 계절 및 시간에 따라 조정된 과거 기록을 기반으로 성능 예측을 한다. 레이턴시, RAM 소비량, 네트워크 대역폭 등의 지표가 변경되고 기준에서 벗어나면 경고가 발동될 수 있다. 이는 데이터독의 보안 탐지 시스템과 통합돼 있으며, 가상머신(VM), 클라우드 인스턴스 및 서버리스 기능과 연동할 수도 있다.
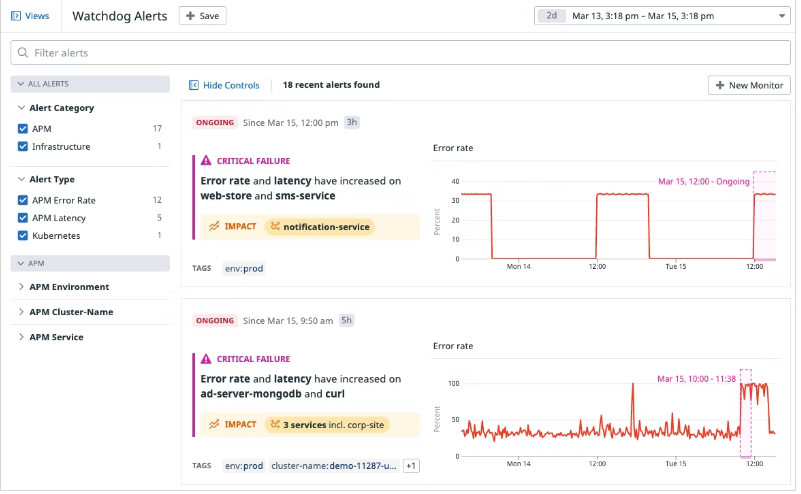
이 서비스는 파악할 수 한 성능 데이터를 관찰하고 그 정상치를 학습하고, 뭔가 이상이 발생하면 경보를 발하고, 가능한 한 무엇이 일어 났는지 통찰력을 부여 .

뉴 렐릭 원(New Relic One)
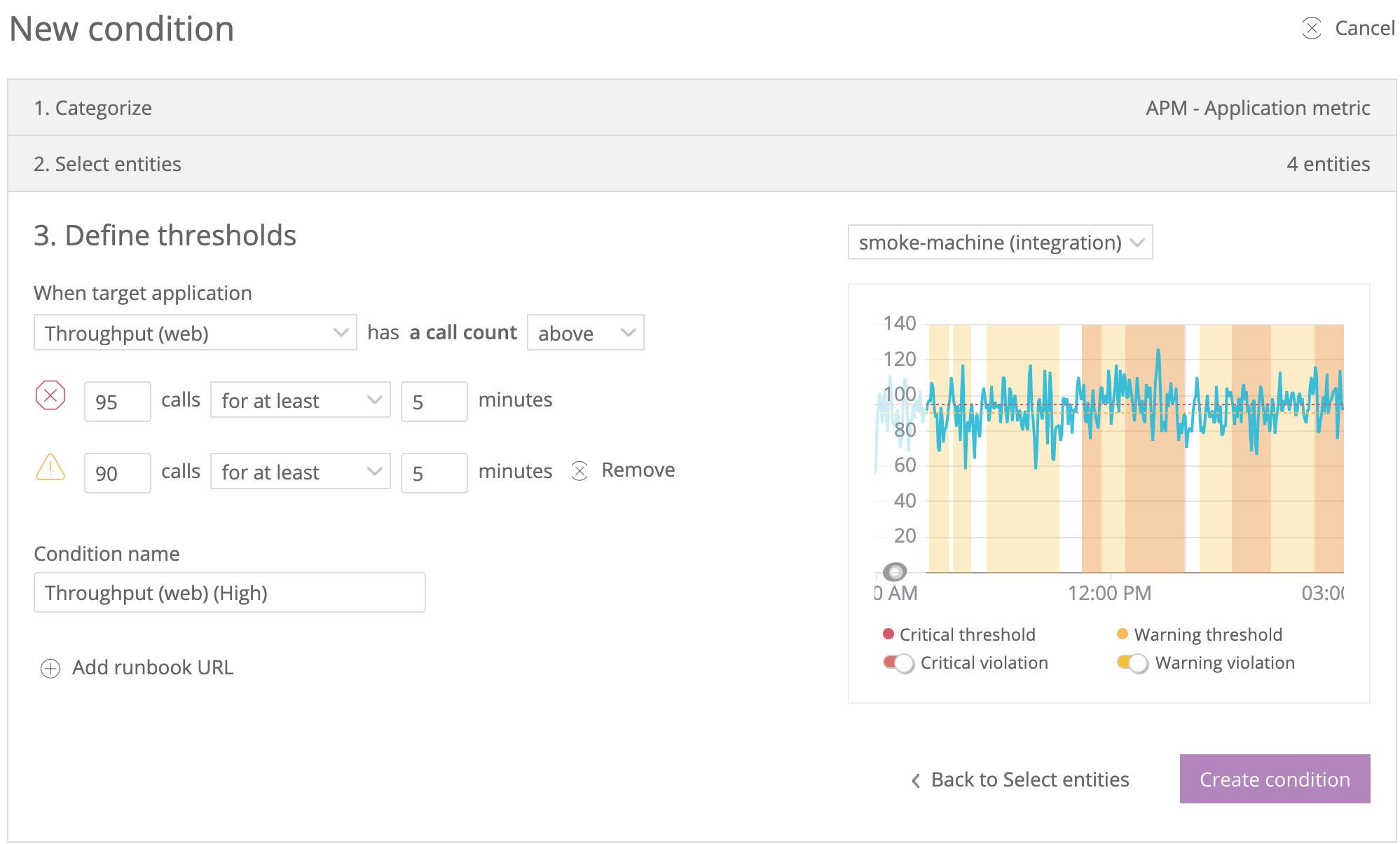
‘뉴 렐릭’은 성능 모니터링 도구인 ‘원’에 AI 엔진을 추가했고, 스플렁크, 그래파나, AWS 클라우드워치 등 다른 도구에서 유입되는 모든 이벤트를 추적한다. 이 도구는 잠재적 심각도를 가진 여러 이벤트를 유연한 수준의 민감도로 구성할 수 있다.
예를 들면 우선순위가 낮은 오류가 15분 동안 여러 차례 발생한 경우에 경고를 생성하도록 설정할 수 있다. 또 서버 충돌과 같은 우선순위가 높은 이벤트는 즉시 호출 경고를 생성하도록 할 수 있다. 문제 로그는 모든 이벤트를 추적하고 AI가 경고를 생성하기 전까지 취한 논리적 단계를 제시하는 상관관계 보고서(Correlation Decision report)도 제공한다.
위 원문보기:
https://www.ciokorea.com/news/202264#csidx6d781f7e75f5d9b8d68029c1636e052
ElasticSearch 엘라스틱서치
Apache Lucene 기반의 Java 오픈소스 분산 검색 엔진
방대한 양의 데이터를 신속하게, 거의 실시간(NRT, Near Real Time)으로 저장, 검색, 분석 할 수 있음
elasticsearch는 검색을 위해 단독으로 사용되기도 하고, ELK(Elasticsearch / Logstatsh / Kibana)스택으로 사용되기도 함
ELK 스택

- Logstash
다양한 소스(DB, csv파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달 - Elasticsearch
Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득 - Kibana
Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터
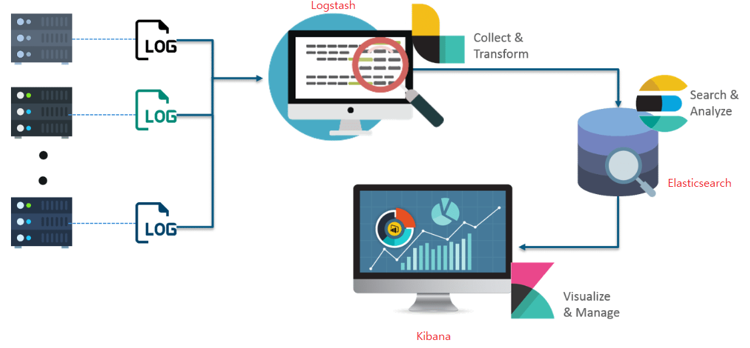
-
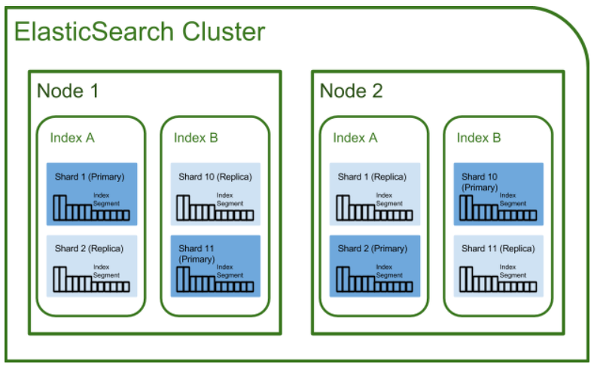
클러스터
elasticsearch에서 가장 큰 시스템 단위를 의미함 최소 하나 이상의 노드로 이루어진 노드들의 집합
서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할수도 있음 -
노드
클러스터에 포함된 단일 서버로 데이터를 저장하고 클러스터의 색인화 및 검색 기능에 참여 -
인덱스
비슷한 특성을 가진 문서의 모음(고객 데이터에 대한 인덱스, 제품 카탈로그에 대한 인덱스, 주문 데이터에 대한 인덱스) -
타입
하나의 색인에서 하나 이상의 유형을 정의할 수 있음. 유형은 색인을 논리적으로 구분한 것 의미 체계는 사용자가 결정 -
도큐먼트
도큐먼트는 인덱스화 할 수 있는 기본 정보 단위이다.
이 문서는 JSON(JavaScript Object Notation)형식이다 -
샤드 & 리플리카
인덱스를 샤드라는 조각으로 분할하는 기능
리플리카는 오류를 방지해 복사본을 생성할 수 있는데 이를 리플리카라고 함
● Elasticsearch를 사용하는 이유는 무엇인가요?
- Elasticsearch는 빠릅니다.
Elasticsearch는 Lucene을 기반으로 구축되기 때문에, 전체 텍스트 검색에 뛰어납니다.
Elasticsearch는 또한 거의 실시간 검색 플랫폼입니다.
Elasticsearch는 보안 분석, 인프라 모니터링 같은 시간이 중요한 사용 사례에 이상적입니다. - Elasticsearch는 본질상 분산적입니다.
Elasticsearch에 저장된 문서는 샤드라고 하는 여러 다른 컨테이너에 걸쳐 분산되며, 이 샤드는 복제되어 하드웨어 장애 시에 중복되는 데이터 사본을 제공합니다. - Elasticsearch는 광범위한 기능 세트와 함께 제공됩니다.
속도, 확장성, 복원력뿐 아니라, Elasticsearch에는 데이터 롤업, 인덱스 수명 주기 관리 등과 같이 데이터를 훨씬 더 효율적으로 저장하고 검색할 수 있게 해주는 강력한 기본 기능이 다수 탑재되어 있습니다. - Elastic Stack은 데이터 수집, 시각화, 보고를 간소화합니다.
Beats와 Logstash의 통합은 Elasticsearch로 색인하기 전에 데이터를 훨씬 더 쉽게 처리할 수 있게 해줍니다. Kibana는 Elasticsearch 데이터의 실시간 시각화를 제공하며, UI를 통해 애플리케이션 성능 모니터링(APM), 로그, 인프라 메트릭 데이터에 신속하게 접근할 수 있습니다.
출처: https://choseongho93.tistory.com/231 [TROLL:티스토리]
Beats 주요유형
-
#FileBeat : 로그파일, 대용량 CSV 파일 등 파일 위주의 대량 데이터 수집
(AI 학습활용, 초기 저장된 데이터 읽는 시간 용량에 따라 필요) -
#MetricBeat : 시스템 실행중인 프로세스 정보, 프로세스의한 자원 소모 및 유휴자원 등의 정보를 실시간 수집
-
WinLogBeat : Window OS 용 window 이벤트 관련 로그정보 및 기타 윈도우용 로그데이터 수집
-
HeartBeat : 다른 프로세스의 가동 시간 모니터링, 다양한 시스템을 동시에 모니터링 할 때 유용
-
PacketBeat : 네트워크에 대한 Depth 있는 데이터 수집
-
AuditBeat : 리눅스 시스템의 사용자 접속과 실행 이벤트 로그 정보(감사) 데이터 정보 수집, 보안 분석 활용
참고
https://blog.ex-em.com/1209
엑셈
https://hoya012.github.io/blog/anomaly-detection-overview-1/
이상 탐지
Datadog이 어떻게 큰 성장을 했는가?
https://blog.imqa.io/datadog_become_number_one/
Datadog 최신 발표
https://www.datadoghq.com/ko/blog/dash-2021-new-feature-roundup/
preprocessing: 전처리
Feature Engineering: 머신러닝 알고리즘 작동하게끔
HDFS: 하둡 파일 관리 시스템
sparkcluster:
데이터독
데이터독은 클라우드 모니터링 서비스를 제공하는 스타트업으로 설립
2019년 9월 상장 당시 약 9조원의 기업가치를 인정받음
현재 시가총액은 약 30조원
우리나라의 대표기업 상성그룹을 비롯해 워싱턴포스트, 로열더치셀, 21세기폭스등 여러 대기업을 고객사로 두고 있음
2012년 인프라 모니터링, 2017년 어플리케이션 성능 모니터링, 2018년 시스템 로그 관리, 2019년 사용자 경험 모니터링 기능을 추가하여 종합 클라우드 모니터링 플랫폼이 됨
데이터독 최신 발표
사일로 파괴
Cloud Cost Management를 통해 이해 관계자는 인프라 및 애플리케이션 원격 측정과 함께 비용 데이터를 분석할 수 있고, 각 팀, 서비스 및 애플리케이션이 전체 클라우드 지출에 어떻게 기여하는지 보여줌
엔지니어링 팀은 자신의 작업이 클라우드 비용에 어떤 영향을 미치는지 빠르게 확인할 수 있으므로 서비스 비용 효율성을 최적화하고 비용 인식 문화를 도입할 수 있음
조직이 클라우드 지출에 대해 높은 수준의 명확성을 얻기가 어려움
클라우드 비용을 명확하게 이해할 수 있도록 돕기 위해 cloud cost management를 도입
조직 전체의 팀에 클라우드 비용에 대한 전체적인 보기를 제공 해당 비용에 대한 협력적인 이해를 촉진하고 효과적인 의사 결정을 내리는 데 도움을 줌
클라우드 비용 관리자는 할인 프로그램의 전략적 선택을 통해 현재 비용을 설명하고 미래 비용을 줄이기 위해 클라우드 청구서의 변경 사항을 보고 분석할 수 있음.
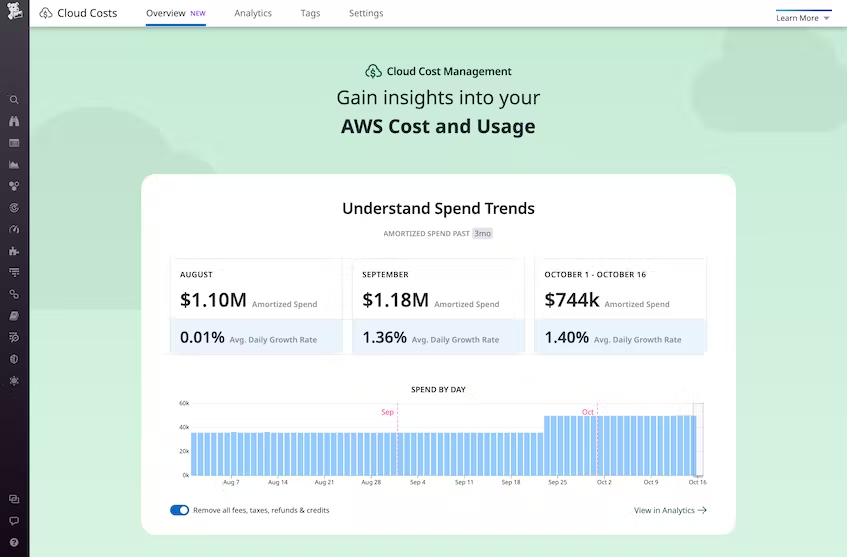
클라우드 비용 가시성 향상
blended
unblended
net unblended
amortized
net amortized
on-demand
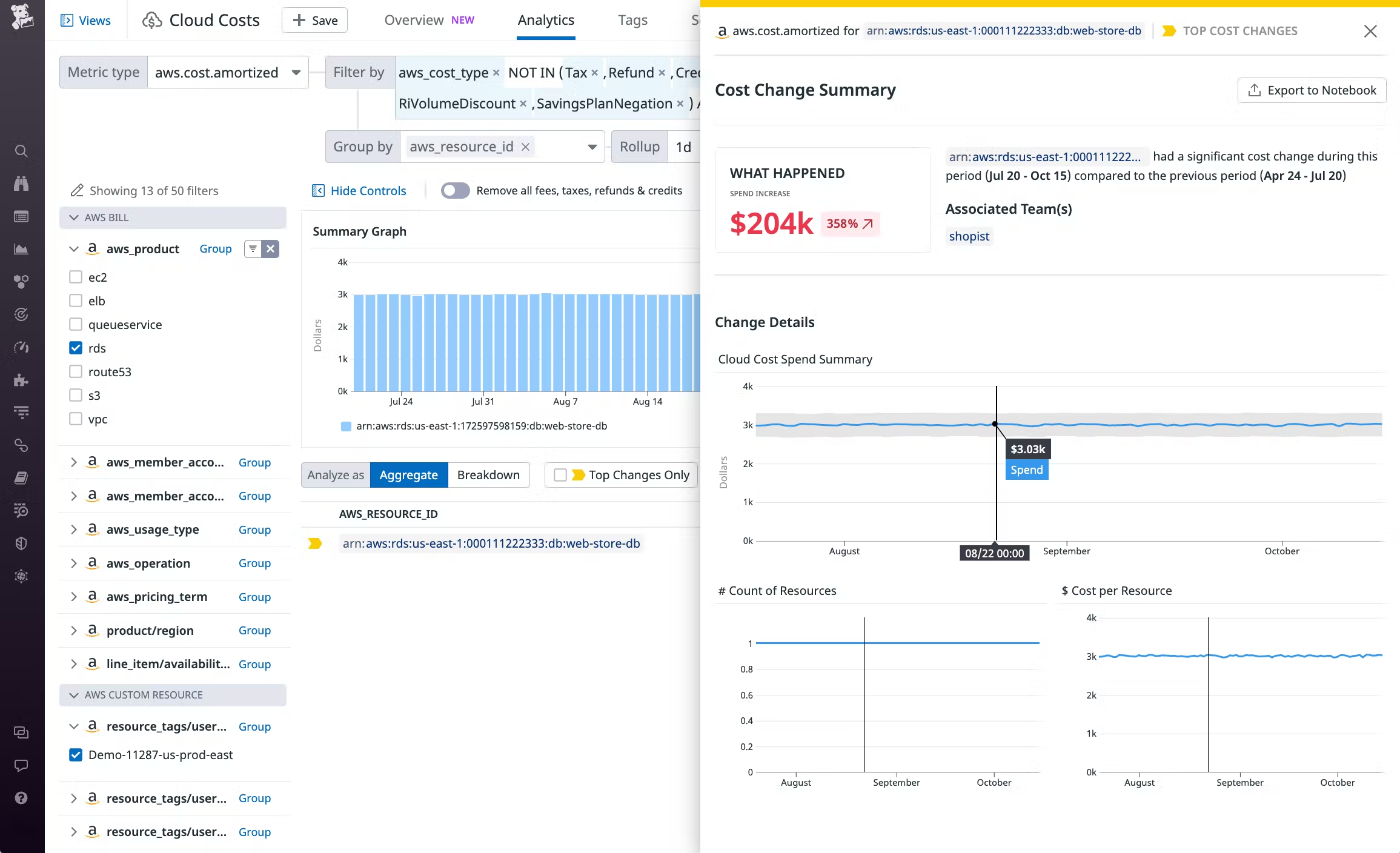
현재 기간에 이 RDS 리소스에 대한 비용이 이전 3개월 기간에 비해 204,000달러(358%) 증가했음을 알 수 있습니다.
관리자와 엔지니어 모두에게 추가적인 이점을 제공
코스크린
엔지니어링 및 운영 팀이 더 분산되어 있기 때문에 조직에서는 효율적이고 의미 있는 공동 작업을 실시간으로 촉진하는 협업 도구를 채택하는 것이 중요하다.
Datadog Coscreen 출시, 음성 및 영상 채팅과 대화형 화면 공유를 사용하는 가상 화의를 만들어 사용자가 작업 환경을 원할하게 병합할 수 있도록 하는 원격 공동 작업 도구임.
엔지니어링 팀과 DevOps팀이 서로의 창을 동시에 공유하고 상호 작용할 수 있음
