0. 서론
들어가기에 앞서 AI 대회는 처음이어서 일단 어떤 방식으로 사람들이 모델링을 하는지 찾아볼 필요가 있었다. 내가 찾아본 모델링의 프로세스는 다음과 같았다.
- 연구 주제의 설정
- 데이터의 탐구 및 전처리 계획
- 모델 학습을 위한 준비 및 모델 학습
- 모델의 성능 평가 및 결과
전에 혼자 공부하는 머신러닝에서 배운 내용과 크게 다르지는 않았다. 이번에도 train과 test로 분류해서 데이터가 주어졌기 때문에 공부하던 내용으로 진행하면 됐다.
1. 연구 주제의 설정
일단 우리가 목표로 하는 것은 와인 품질을 분류하는 것이다. 인터넷에서 관련 글을 조금 찾아보니 "종속변수가 2가지 경우의 수인 Binary Classification 연구이므로, ML Model 중 Classification Model에 대해 학습을 시킨다"로 정리할 수 있다고 했다.
-
Binary Classification(이진 분류): 종속변수의 경우의 수가 2가지인 경우 -> 연구 주제가 "좋은지 나쁜지" 두 가지 경우의 수밖에 존재하지 않는다. -> 분류(Classification) 사용
-
ML(Machine Learning, 기계학습)에서 분류(Classification)
-> 베이지안, 로지스틱 회귀, KNN, Decision Tree 등 다양함
2. 데이터의 탐구 및 전처리 계획
먼저 데이터를 불러와서 한번 확인해 보았다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
train = pd.read_csv('/content/drive/MyDrive/dacon/wine/train.csv')
test = pd.read_csv('/content/drive/MyDrive/dacon/wine/test.csv')
train.describe(include='all')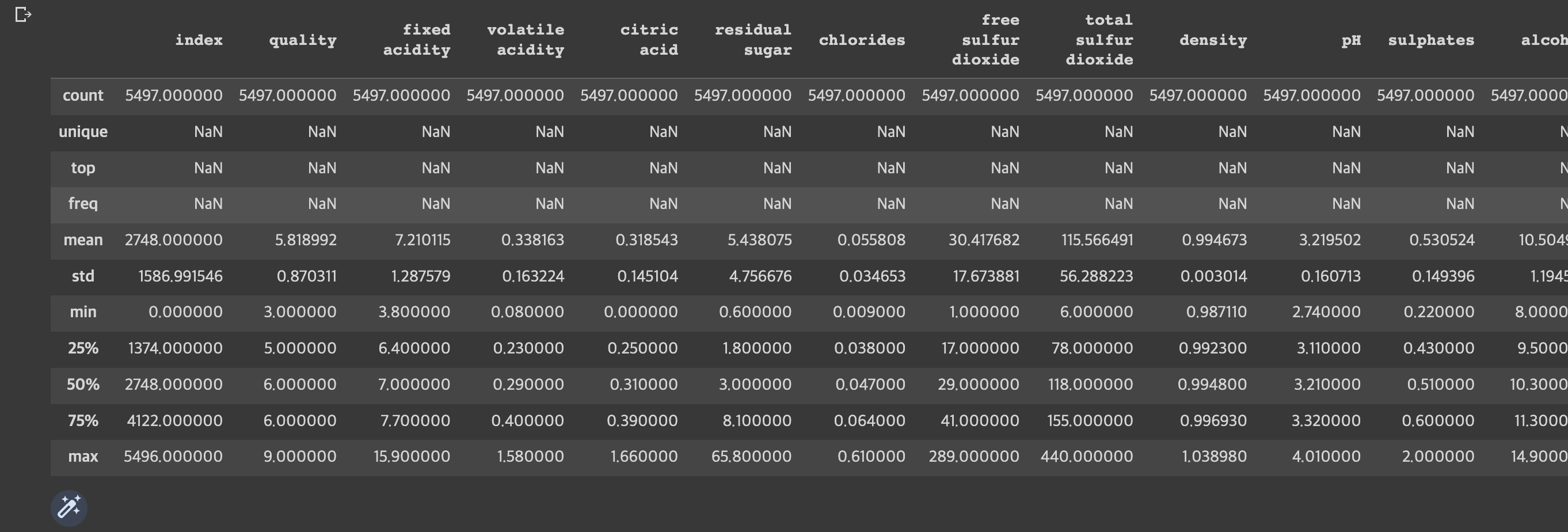
이런식으로 변수들의 scale값이 달라서 표준화가 필요하다는 점을 알 수 있었다. 또한 와인의 품질과 관련해서는, 이번 분류는 이진분류이기 때문에 scale을 이진분류로 바꿔줘야겠다.
3. 모델 학습을 위한 준비 및 모델 학습
사실 이 부분에서 내 머리를 강하게 때린 부분은 내가 아직 공부를 덜해서 어떤 모델을 적용시켜야 할 지 모르겠다는 점이었다. 혼공머신을 혼자 독학 했던 것도 거의 1년 전의 일이라 기억이 잘 나질 않았다.
일단 이번주의 미션은 해결을 하고 다음주부터는 강의를 듣고 dacon에 test guide가 있는 문제들을 주마다 하나씩 풀어봐야겠다는 플랜이 세워졌다.
다시 본론으로 돌아와서,
이번 와인품질분류기는 많은 분들이 랜덤포레스트를 사용해서 모델링을 한 것 같았다. 나는 아직 이부분을 공부해본 경험이 없어서.. 이번에는 EDA만 조금 더 해보기로 했다. 일단 주어진 자료들을 좀 더 시각화를 해보자.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,12))
sns.heatmap(data = train.corr(), annot=True, fmt = '.2f', linewidths=.5, cmap='Blues')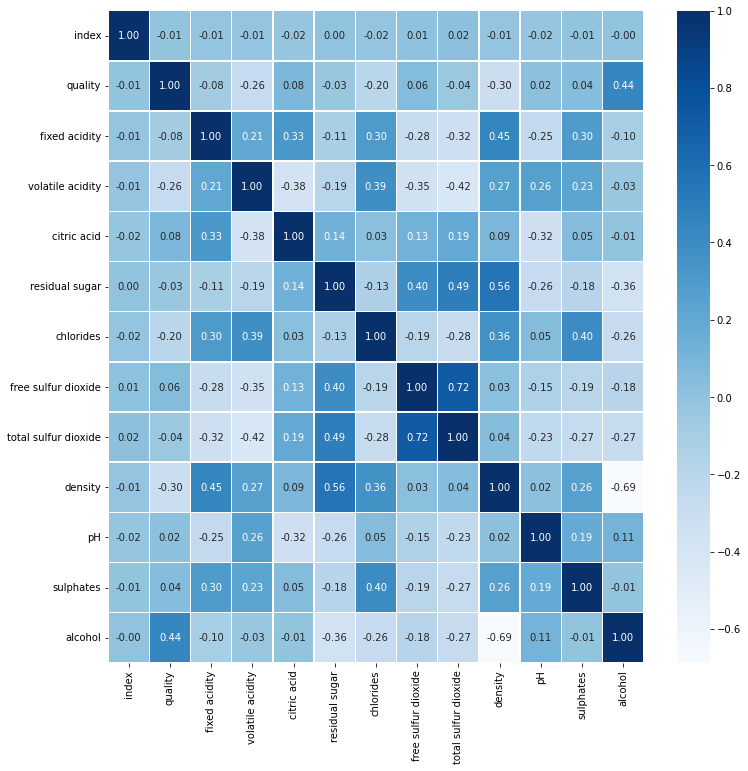
train 변수들 간의 상관관계를 시각화 한 것이다. 마찬가지로 test 변수들 간의 상관관계를 나타낼 수도 있다.
plt.figure(figsize=(12,12))
for i in range(1,13):
plt.subplot(3,4,i)
sns.distplot(train.iloc[:,i])
plt.tight_layout()
plt.show()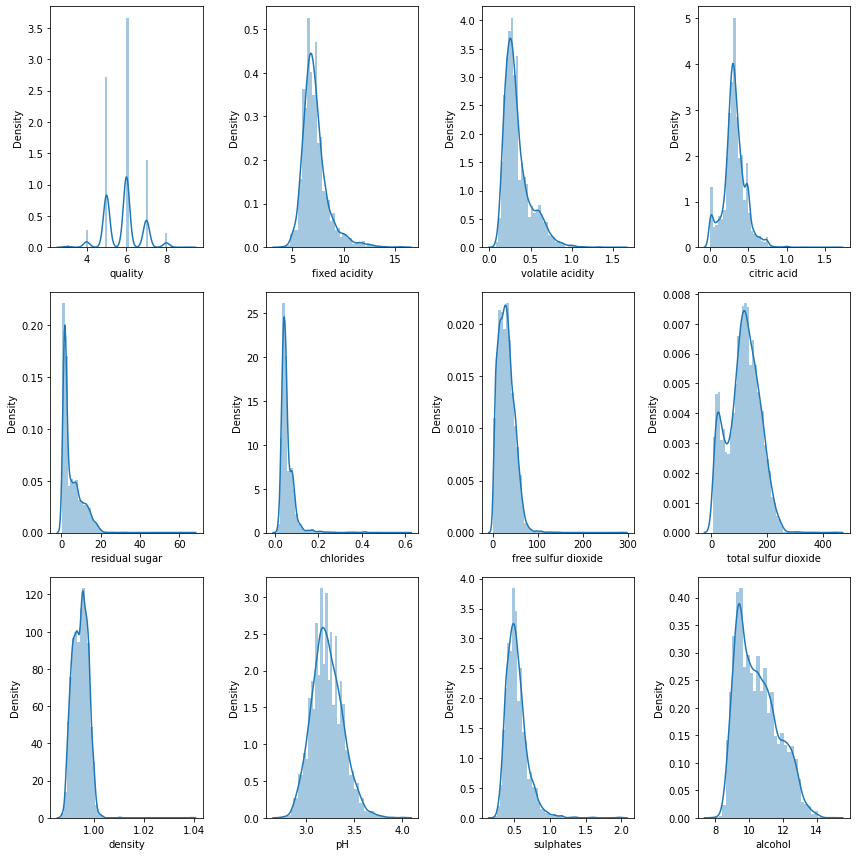
train의 각 변수별 분포도 살펴보고
for i in range(11):
fig = plt.figure(figsize = (12,6))
sns.barplot(x = 'quality', y = train.columns[i+2], data = train)
train에서 각 변수와 quality 변수 사이 분포를 확인할 수도 있다. (위 사진은 나온 결과값 중 하나이다.)
4. 모델의 성능 평가 및 결과
보통 accuracy로 많이 평가하는 걸로 알고 있으나, precision, recall, f1 score 등으로 평가하기도 한다. 나는 학교에서 들은 데이터마이닝 수업에서 주로 accuracy를 이용했다. 이번에는 모델학습을 하지 못해서 따로 확인해보지는 못했다.
5. 결론
일단 내가 공부를 한게 없어서 이번에는 데이터 탐구 밖에는 하지 못했다. 다음 번에 공부를 좀 더 한 다음에 다시 한번 더 풀어보는 것이 좋을 거 같다.
1년간 학교에서 일하느라 공부못했다는 핑계아닌 핑계로 위안을 삼아보지만 내 자신한테 굉장히 실망스럽다.. 방학에 공부 좀 해야겠다..ㅜ
