[논문리뷰] PAESE, MixMatch, AMIGOS
논문리뷰
PARSE-Pairwise Alignment of Representations in Semi-Supervised EEG Learning for Emotion Recognition (Guangyi Zhang et al., 2022)
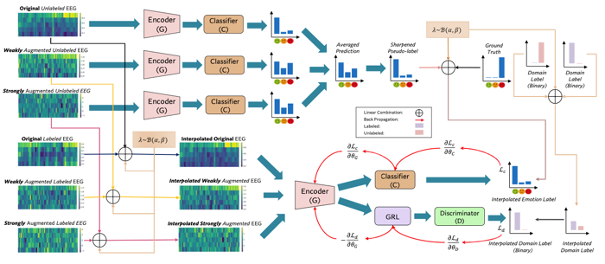
감정 인식을 위한 신뢰할 수 있는 뇌파 표현을 학습하기 위한 새로운 반지도형 아키텍처인 PARSE를 제안한다.
1) 대량의 레이블이 지정되지 않은 데이터와 제한된 수의 레이블이 지정된 데이터 사이의 잠재적인 분포 불일치를 줄이기 위해 PARSE는 쌍별 표현 정렬을 사용한다.
2) 모델을 엄격하게 테스트하기 위해 PARSE를 여러 최신 반지도 접근 방식과 비교하고, 이를 EEG 학습에 맞게 구현 및 조정한다.
3) 클래스당 하나의 샘플만 레이블이 지정된 경우, 레이블이 지정되지 않은 데이터와 레이블이 지정된 데이터 간의 분포 정렬을 수행함으로써 쌍별 표현 정렬이 성능을 크게 향상시키는 것을 알 수 있다.
→ label이 있는 데이터와 label이 없는 데이터를 한 쌍으로 MixUp한다.
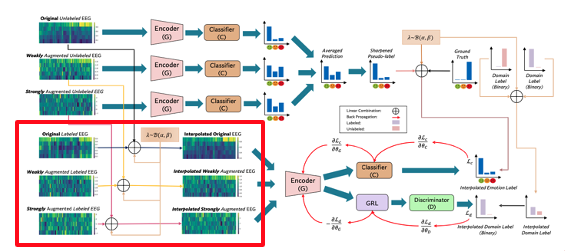
→ Label이 지정되지 않은 데이터와 label이 지정된 데이터 사이의 불일치를 줄이기 위해 Pairwise representation alignment를 적용한다.
→ GRL과 Domain Discriminator을 사용한 적대적 학습을 통한 분류 성능 향상한다.
[ PARSE의 방식 ]
→ 레이블이 지정되지 않은 대량의 데이터와 제한된 수의 레이블이 지정된 데이터 간의 잠재적인 분포 불일치를 줄이는 것
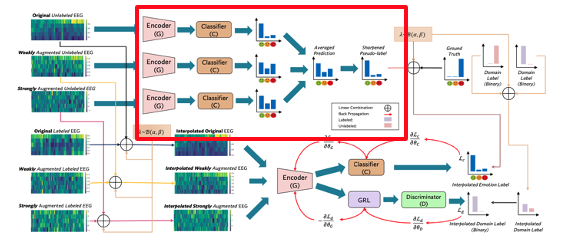
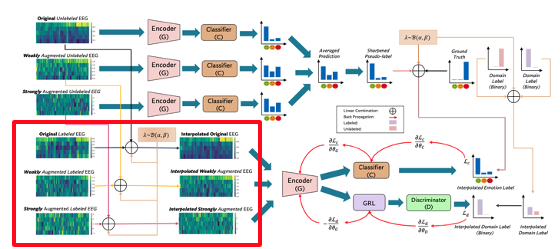
- Data Augmentation: 라벨이 지정된 데이터와 라벨이 지정되지 않은 데이터 모두에 대해 데이터 증강을 수행하여 사용 가능한 데이터의 양을 늘린다.
- Label-Guessing: 레이블이 지정되지 않은 원본 데이터와 증강된 데이터에 대해 레이블 추측을 수행하여 유사 레이블을 생성한다. 추측한 라벨을 선명하게 하여 품질을 개선한다.
- MixUp: 라벨이 지정된 데이터와 라벨이 지정되지 않은 데이터의 볼록 조합을 계산하여 모델의 성능을 개선한다.
- Pairwise Representation Alignment: 쌍별 표현 정렬을 수행하여 라벨이 지정된 데이터와 라벨이 지정되지 않은 데이터 간의 분포 불일치를 줄인다.
- Total Loss Function: 많은 SSL 모델에서 사용되는 supervised loss을 사용한다.
[ 데이터 셋 별 분석 결과 ]
→ 사용된 모델: Π-model, Temporal Ensembling, Mean Teacher, Pseudo-Labeling, Convolutional autoencoder, MixMatch, FixMatch, AdaMatch
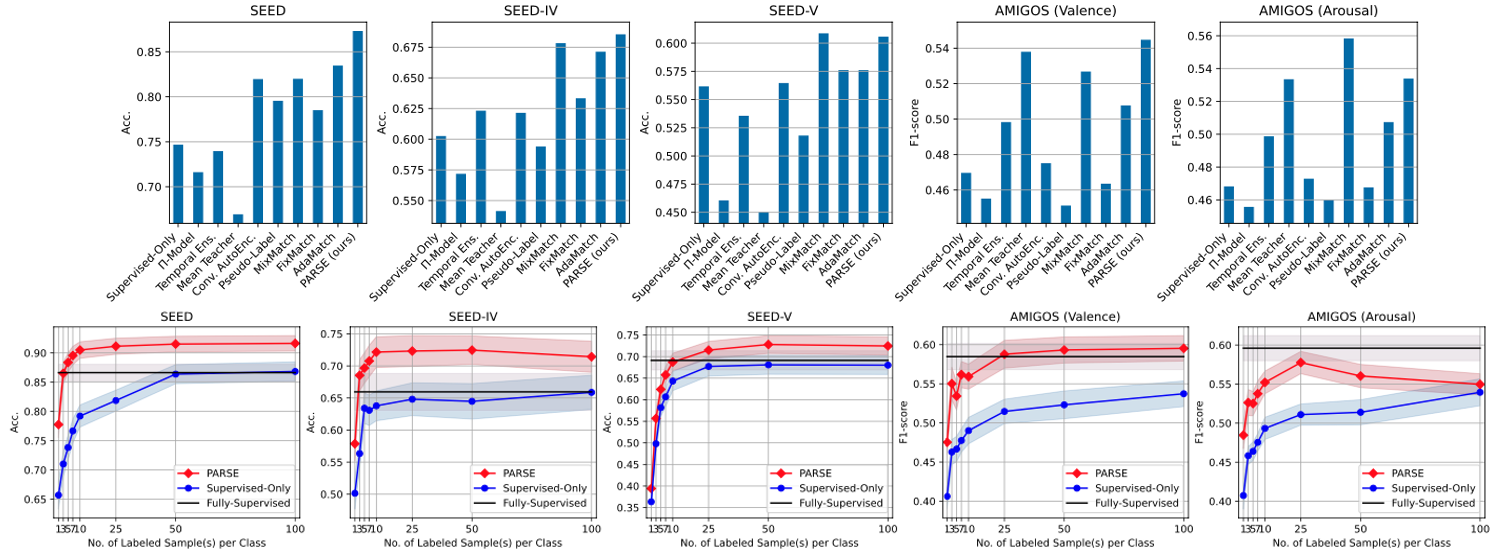
-
SEED: 15명의 참가자가 수행한 실험에서 세 가지 감정을 자극으로 사용한 15개의 필름 클립으로 구성된 데이터 셋 → EEG 신호는 1초 세그먼트로 분리
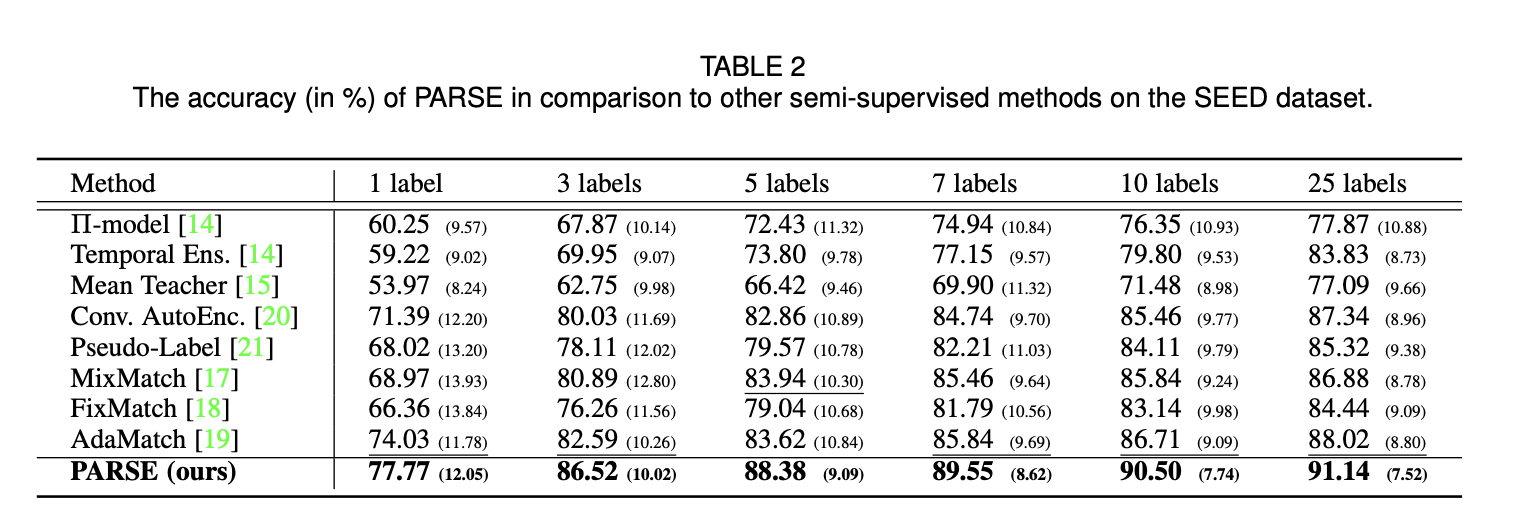
다양한 양의 제한된 라벨 표본을 사용하여 전반적으로 최상의 결과를 달성
-
SEED-IV: 15명의 피험자가 각각 60초 동안 지속되는 40개의 비디오 클립을 시청하면서 얻은 EEG 기록으로 구성된 데이터 셋 → EEG 신호는 4초 세그먼트로 분리
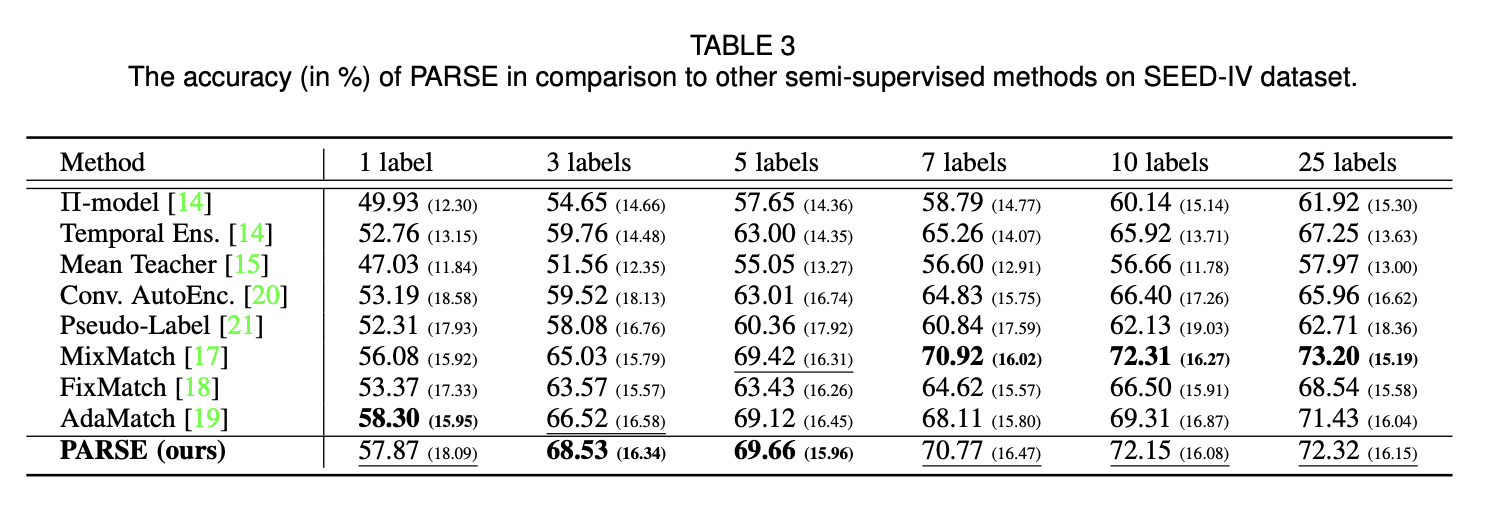
제한된 양의 라벨이 부착된 샘플을 다양하게 사용하여 전반적으로 최상의 결과를 달성
-
SEED-V: 15명의 피험자가 각각 120초 동안 15개의 비디오 클립을 시청하면서 얻은 EEG 기록으로 구성된 데이터 셋 → EEG 신호는 4초 세그먼트로 분리
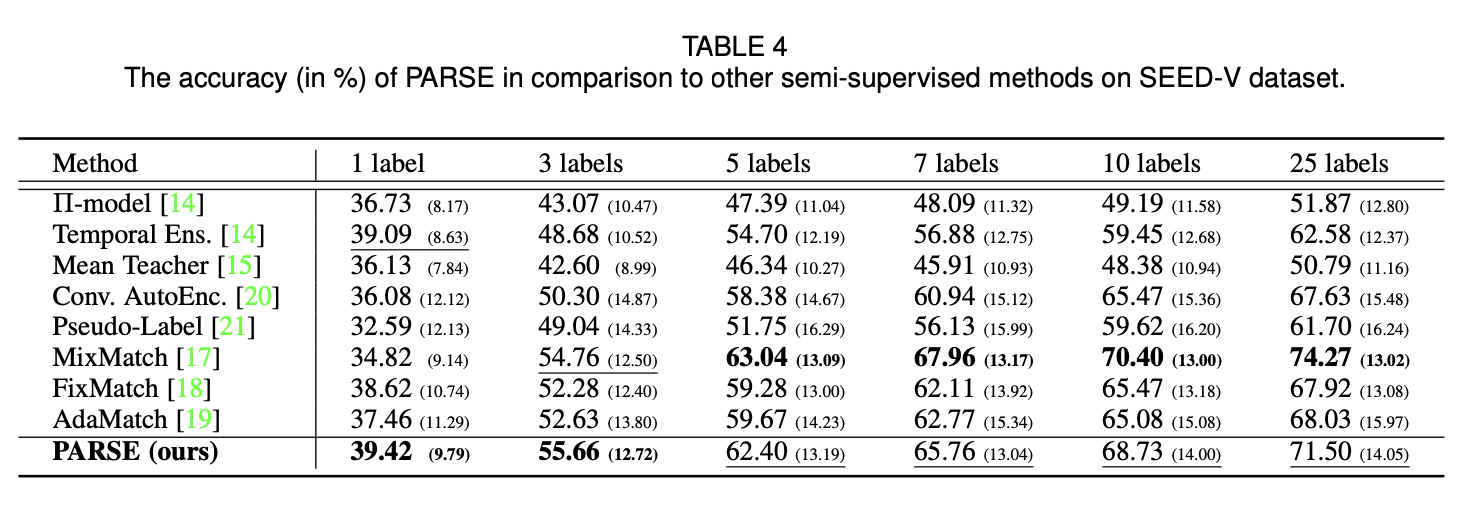
제한된 양의 라벨이 부착된 샘플을 다양하게 사용하여 두 번째로 좋은 결과에 도달에 도달
-
AMIGOS: 40명의 피험자가 각각 5분 동안 40개의 비디오 클립을 시청하면서 얻은 EEG 기록으로 구성된 데이터 셋 → EEG 신호는 20초 세그먼트로 분리
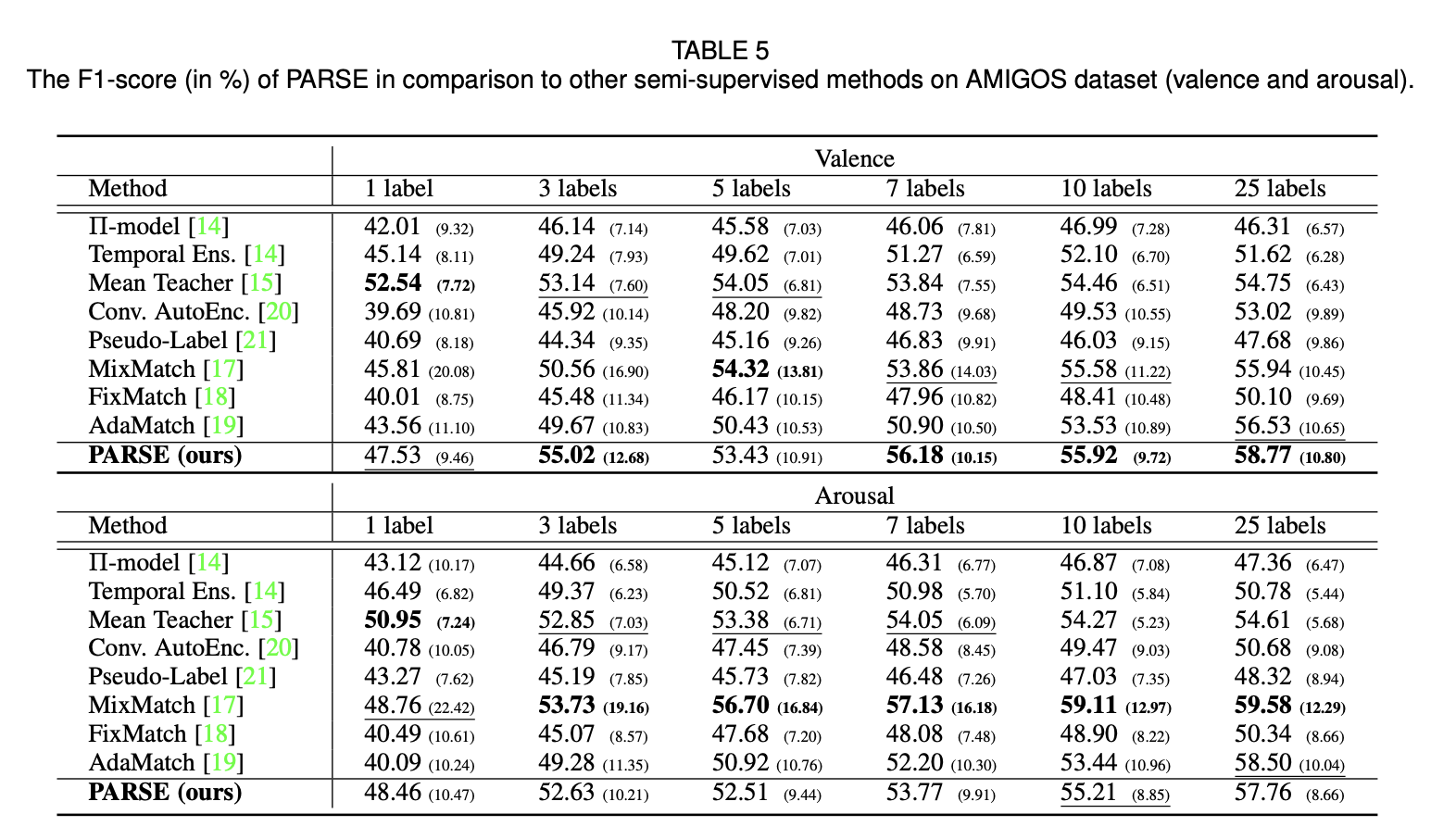
[ Valence ]
다양한 양의 제한된 라벨 표본을 사용하여 전반적으로 최상의 결과를 달성
[ Arousal ]
제한된 양의 라벨이 부착된 샘플을 다양하게 사용하여 두 번째로 좋은 결과에 도달에 도달
[ 결론 ]
이 연구에서는 뇌파 기반 감정 인식을 위한 새로운 준지도 방식을 제안한다. 제안한 프레임워크는 SEED, SEED-IV, AMIGOS(원자가)에서 라벨링된 6개의 모든 시나리오에서 평균 최고 결과를 달성했으며, SEED-V에서는 0.3%의 차이로 최고 결과에 근접한 것으로 나타났다.
모든 데이터 세트에 걸쳐 라벨링된 샘플의 수를 변화시키면서 제안한 방법에 대한 쌍별 표현 정렬의 영향을 보여준다. 준지도학습에서 쌍별 표현 정렬이 레이블이 지정된 표현과 레이블이 지정되지 않은 표현 사이의 거리를 상당히 줄여준다는 것을 보여주는 추가 분석을 수행한다. 라벨이 지정되지 않은 뇌파 데이터에서 강화학습보다 일관되게 우수한 성능을 보여준다.
→ Augmentation된 Dataset이 실제로 classification에서 유효하게 같은 class로 묶일 수 있는지에 대해 검증이 되지 않았음
MixMatch (David Berthelot et al., 2019)
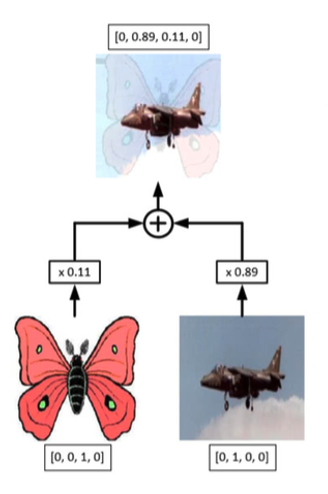

자기주도학습은 라벨이 지정되지 않은 데이터를 활용하여 라벨이 지정된 대규모 데이터 세트에 대한 의존도를 완화하기 위한 좋은 방법이다. 이 논문에서는 자기주도학습을 발전시켜 더 좋은 결과를 낼 수 있는 방법을 소개한다.
목표: 자기주도학습의 새로운 알고리즘인 MixMatch 생성 및 평가
자기주도학습을 사용하는 이유?
→ 라벨이 있는 데이터를 수집하는데 비용과 시간이 많이 들기 때문
[ 자기주도학습의 기존 방법 ]
- Consistency Regularization
→ 라벨이 지정되지 않는 예에 대해 분류기가 증강된 후에도 동일한 클래스 분포를 출력해야하는 아이디어 활용하여 데이터 증강 적용
장점) 안정적인 대상 제공, 경험적으로 결과를 크게 개선
단점) 도메인 별 데이터 확대 전략을 사용 - Entropy Minimization
→ 라벨이 지정되지 않는 데이터에 대해 낮은 엔트로피 예측
1) VAT와 결합하고 2) 1-hot 라벨 구성하고 cross-entropy loss의 훈련 대상으로 사용 3) 선명화 로 엔트로피를 최소화 한다. - Traditional Regularization
→ 모델에 제약을 가하는 일반적인 접근 방식 / MixUp 사용
[ MixMatch ]

U: 라벨이 없는 데이터 / X: 라벨이 있는 데이터
- Data Augmentation: U와 X에대해 각각 개별 증강 후 이후 과정을 통해 추측된 라벨 생성
- Label Guessing: U의 라벨이 지정되지 않는 예제에 대해 MixMatch 모델의 예측을 사용하여 추측을 생성
→ 추측은 나중에 unsupervised loss term로 사용, 모델의 예측된 클래스 분포의 평균을 계산하여 추측
+ 선명화 기능 적용 - MixUp: 라벨이 지정된 예제와 안된 예제를 혼합하여 해당 라벨의 확률을 계산
→ X를 데이터 증강 및 MixUp을 통해 라벨이 지정된 X’로 변환 - Loss Function: X의 라벨과 모델 예측 간의 일반적인 cross-entropy loss을 U의 예측 및 추측 레이블에 대한 L2dml 제곱과 더해 계산한다.
→ 경계가 있고 잘못된 예측에 덜 민감하기 때문에 사용 - Hyperparameter: 다양한 하이퍼파라미터가 있지만 하이퍼파라미터가 많이지면 자기주도학습은 작은 검증 세트로 교차 검증이 어렵기때문에 문제가 될 수 있음
→ MixMatch에서는 대부분의 하이퍼파라미터를 고정하여 실험 혹은 데이터 세트별로 조정할 필요 없음
→ α = 0.75, λu = 100일 때가 좋은 출발점임 (λu는 실험에 따라 선형적으로 증가시킨다.)
[ 결론 ]
MixMatch가 연구한 모든 설정에서 다른 방법에 비해 오류율이 2배 이상 감소하여 현저하게 향상된 성능을 나타냄
AMIGOS- A Dataset for Affect, Personality and Mood Research on Individuals and Groups (Juan Abdon Miranda-Correa et al., 2018)
기존의 affective computing을 위한 데이터베이스는 1) 얼굴 표정 분석에 중점을 두거나 2) 생리학적 신호에 기반하거나 3) 비디오 양식을 사용하였음. 이 데이터베이스는 기존과는 다른 개인 및 그룹에 대한 정서, 성격 특성 및 기분에 대한 멀티모달 연구를 위한 데이터 세트인 AMIGOS를 제시하였음.
이 논문 저자들의 목표: 개인의 성격과 기분, 사회적 맥락 및 비디오 길이와 관련해서 개인의 신경 생리학적 신호를 통해 정서적 반응에 대한 멀티모달 연구를 가능케 함
[ 수집 방법 ]
- 40명의 참가자가 16개의 짧은 비디오(< 250 ) 시청
- 개인 및 그룹 참가자가 4개의 긴(> 14분) 비디오 시청
→ EEG, ECG, GSR 등의 생체 신호를 웨어러블 센서를 사용하여 기록하고 참가자의 정면 비디오와 깊이 전신 비디오도 녹화함
[ 특징 ]
- 참가자들이 자체적으로 평가한 내부 주석과 다른 인원이 평가한 외부 주석이 있음
→ 내, 외부 영향 주석 사이에 중요한 상관 관계가 있음 - 다양한 차원의 상관 관계 분석을 제시함
[ 결론 ]
AMIGOS 데이터 세트가 개인 및 집단에 대한 감정, 성격 특성 및 기분에 대한 복합 연구에 사용될 수 있으며 EEG가 원자가 및 각성 예측에 가장 적합한 생리학적 양식인 것을 확인함
