SQL 파싱 과정과 소프트/하드 파싱의 정의
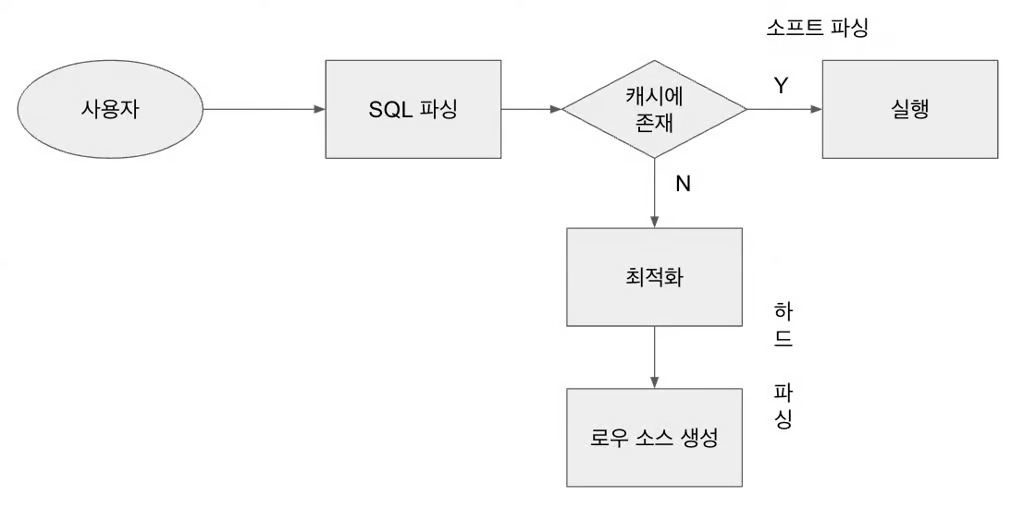
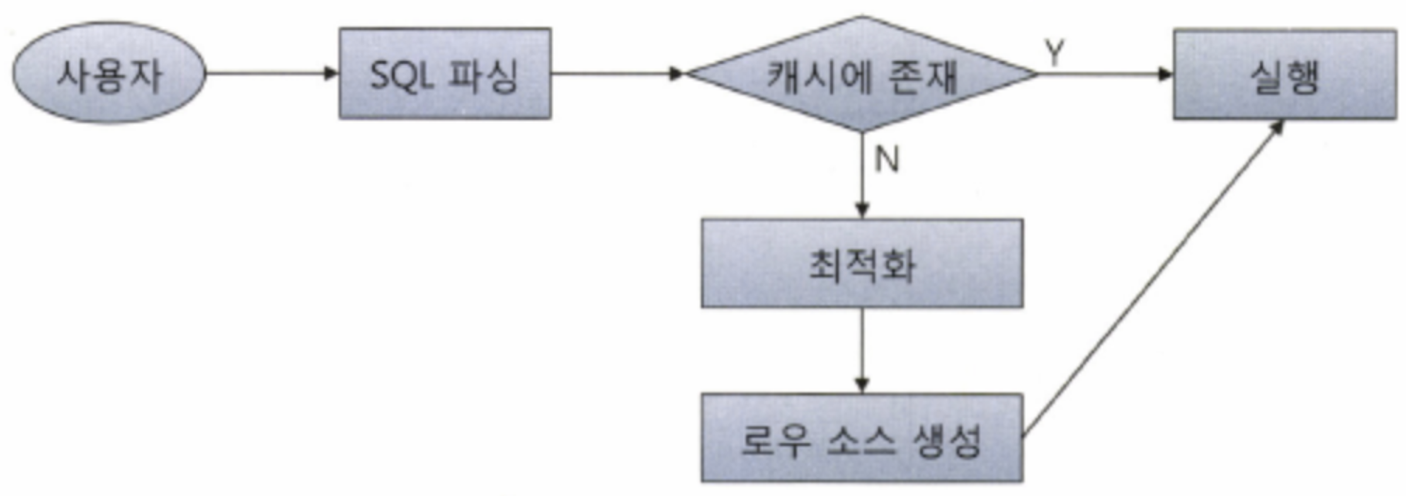
사용자가 전달한 쿼리문을 이용하여 SQL 파싱이 진행될 때는, 위의 도식과 같은 과정을 거친다.
- 사용자로부터 SQL을 전달받음
- SQL을 파싱한 후, 해당 SQL이 라이브러리 캐시에 존재하는지 확인함
2-1. 해당 SQL문이 캐시에 존재하는 경우 해당 문을 바로 실행 :소프트 파싱(Soft Parsing)
2-2. 해당 SQL문이 캐시에 존재하지 않는 경우, 해당 구문을 최적화 한 뒤 로우 소스를 생성한 뒤 실행 :하드 파싱(Hard Parsing)
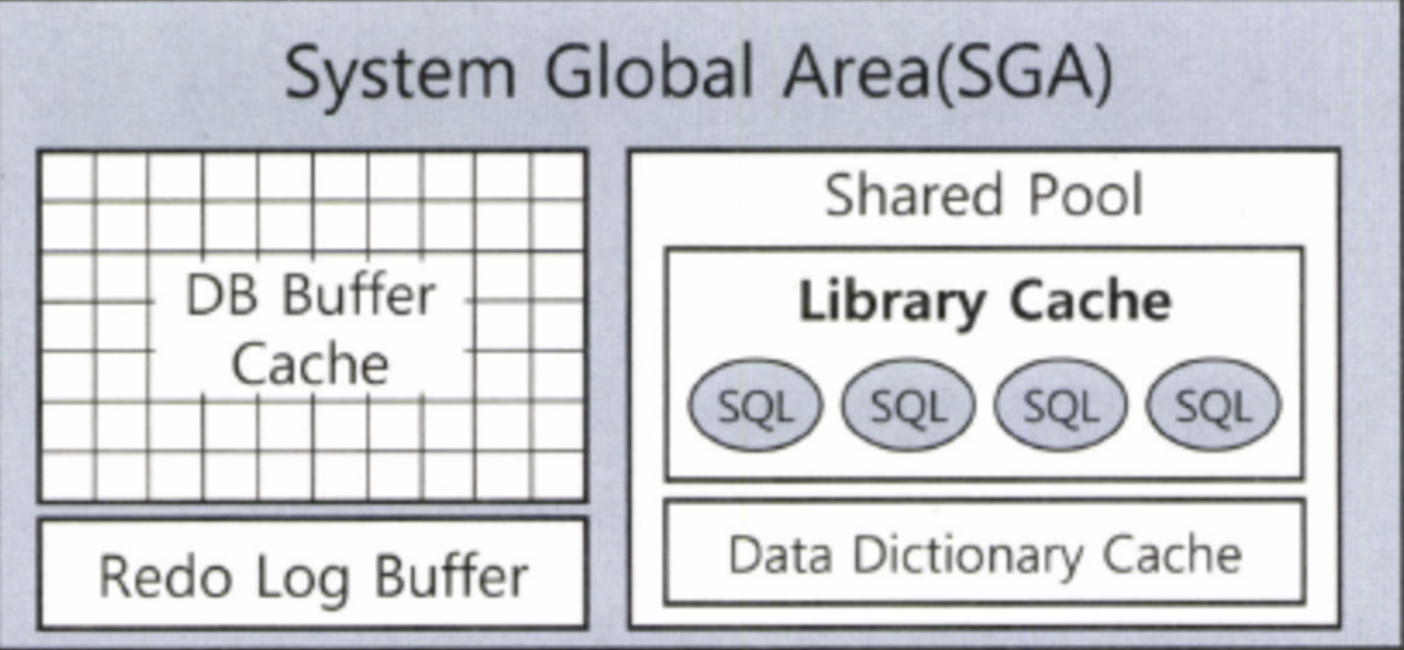
위에서 언급한 라이브러리 캐시는 SGA(System Global Area)라는 공간 내부에 존재하는데, 이는 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 데이터와 제어 구조를 캐싱하는 메모리 공간이며, 라이브러리 캐시에는 이미 생성된 내부 프로시저 등이 저장되어 재사용이 가능케 된다.
하드 파싱의 부하
하드 파싱 과정은 부하가 꽤나 심한 과정이다. 조인 순서만 고려해도 5!(120)가지가 되며, 여기에 NL Join, Sort Merge Join등 조인 방식을 고려하고, 테이블 스캔 방식(r(ALL), Index 스캔)이나, 인덱스를 이용한다면 어떤 인덱스를 어떤 방식으로 조인할지 등 고려해야 할 사항만 수십 수만가지이다.
이 과정에서 옵티마이저가 사용하는 정보를 간단히 정리하면 다음과 같다.
- 테이블, 컬럼, 인덱스 구조에 관한 기본 정보
- 오브젝트 통계: 테이블 통계, 인덱스 통계, (히스토그램을 포함한 컬럼 통계
- 시스템 통계 : CPU 속도, Single Block I/O 속도, Multiblock I/O 속도 등
- 옵티마이저 관련 파라미터
이 과정은 대부분 I/O보다 CPU 로드율이 훨씬 높은 몇 안 되는 작업 중 하나이며, 그렇기에 최적화 된 경로를 캐시에 저장하여 최대한 많이 이용하려고 하는 것이다.
바인드 변수의 중요성
이름 없는 SQL 문제
사용자 정의 함수/프로시저, 트리거, 패키지 등은 이름을 가지므로, 컴파일한 채로 딕셔너리에 저장하여 영구 보관되므로, 보관 및 호출을 통한 재사용이 용이하다. 반면, SQL의 경우 이름이 따로 없으므로 이를 관리하기가 쉽지만은 않다.
IBM DB2같은 DMBS의 경우 SQL에도 함수/프로시저처럼 영구 저장하기도 하나, 오라클,SQL Server와 같은 대다수의 DBMS는 SQL을 저장하여 관리하려 하지 않는다
그 이유는 생각보다 간단한데, 이는 DMBS에서 수행되는 SQL이 모두 완성된 SQL은 아니며, 일회성 (ad hoc) SQL도 많기 때문이다. 당장 개발 과정에서 쿼리문을 작성하고 로드율을 테스트하던 수많은 상황들만 떠올려 봐도 명백하다. 이런 SQL들까지 모두 저장하는 것은 비효율적이므로, 대부분의 SQL들을 저장하지 않는 쪽으로 결정하게 된 것.
엄밀히 이야기하면 저장 자체는 시도하긴 한다. 다만 SQL문은 이름이 없고, 그 SQL 전체 문장이 곧 이름이 되므로, 변수 하나만 달라지더라도 다른 이름의 별개의 문장으로 취급되므로, 실행할 때 마다 각각 최적화를 진행하고, 별도의 라이브러리 캐시 공간을 이용하는 것
공유 가능 SQL(바인드 변수)
만일, 어떤 SQL 로직을 반복적으로 이용하는 상황이 필요하다고 해보자. 이 서비스 로직은 로그인이나 상품 주문 등 특정 동작을 할 때마다 아주 약간의 차이만 가진 채로, 의미적으로 동일한, 사실상 같은 로직을 실행하게 된다.
DMBS에서 발생하는 부하는 대부분 I/O 로드이지 CPU 로드가 아니다. 그러나 이 로직이 공유되지 않고 반복적으로 집중 이용 되게 된다면
-즉, 이름 없는 SQL을 반복 실행한다면-매 실행마다 각각 최적화를 진행하고, 별도의 캐시 공간을 이용하게 되므로, I/O 로드율이 저조함에도 불구하고 높은 CPU 로드율로 인해 DBMS의 효율적인 동작을 보장할 수 없게 된다.
이런 경우, 해당 반복 사용 로직을 파라미터로 받는 프로시저 하나를 공유하면서 재사용한다면, 라이브러리 캐시에 수백 수천개의 동일한 로직의 SQL문이 아닌, 하나의 최적화된 프로시저만 존재하게 되며, 이 로직을 소프트 파싱 과정을 통해 반복 사용함으로서, DMBS의 효율성이 높아지게 되는 것이다.
이렇게 파라미터가 라이브러리 캐시에 저장되게 하려면, 이 경우 바인드 변수를 사용하여 Parameter-Driven방식으로 SQL을 작성할 수 있다.
바인드 변수가 사용되지 않은 구문을 작성한 경우
SELECT * FROM customer WHERE login_id = '" + login_id + "'";위 구문이 여러번 호출되는 경우, 라이브러리 캐시는 아래와 같을 것이다.
SELECT * FROM customer WHERE login_id = 'hello'
SELECT * FROM customer WHERE login_id = 'world'
SELECT * FROM customer WHERE login_id = 'this'
SELECT * FROM customer WHERE login_id = 'is'
SELECT * FROM customer WHERE login_id = 'library'
SELECT * FROM customer WHERE login_id = 'cache'
...
...
...바인드 변수가 사용된 구문 예시
SELECT * FROM customer WHERE login_id = ?위 구문은 반복 호출되더라도, 아래와 같은 라이브러리 캐시의 형태를 가지게 된다.
SELECT * FROM customer WHERE login_id = :1