1. SQL 처리 과정과 I/O
1.1 SQL 파싱과 최적화
SQL의 특성
SQL은 Structured Query Language의 약자로, '구조적' 질의 언어로서, 원하는 결과집합을 구조적(structured), 집합적(set-based), 선언적(declarative)인 방법으로 얻어내는 질의 언어지만, 결과집합을 만들어 내는 과정은 절차적으로 진행되는 언어임
따라서 SQL로 선언된 Structured Language를 Procedural하게 변형하기 위해서는, DBMS 내부에 Procedure가 존재할 것이 가정되며, 이것이 바로 SQL Optimizer임
또한, DMBS 내부에서 Procedure를 작성하고 Compile하여 Excutable하게 만드는 전 과정을 'SQL 최적화' 라고 한다.
< SQL 최적화 >
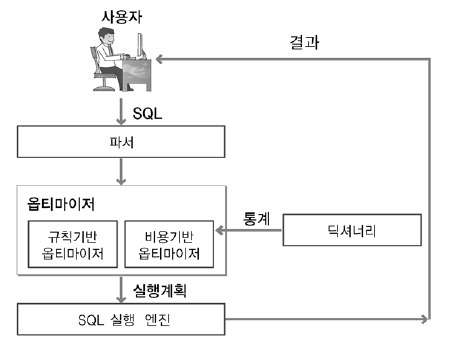
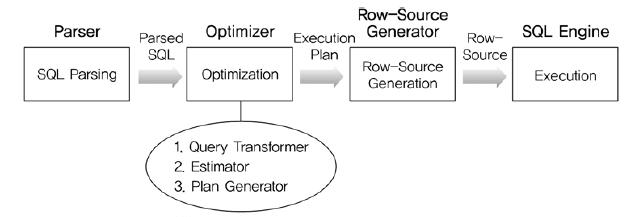
SQL 최적화 순서
- SQL Parsing
- Generate Parsing Tree : SQL문을 이루는 개별 구성요소를 분석해 Parsing Tree 생성
- Syntax Check : Check Unusable/Missing Keyword 등 문법적(Syntac) 요소 체크
- Semantic Check : Unexist Table/Column, Authorization 등 논리적 요소 체크
- SQL 최적화
- Optimizer의 실행경로 생성 : System 및 Object 통계정보 등 활용하여 가장 효율적인 경로 선택
- Row-Source 생성
- Row-Source Generator(이하 RSG)가 담당하며, 2.에서 선택된 실행경로를 Executable Code/Procedure 형태로 Formatting함
< SQL Optimizer >
SQL Optimizer는 Parser나 RSG와 마찬가지로, DBMS Server Process의 Function중 하나이며, 최적의 DATA ACCESS ROUTE를 선택하는 DBMS의 핵심 엔진임
Optimizer 최적화 프로세스 (비용기반 Optimizer의 경우)
- 분석된 쿼리 수행을 위한 후보군 탐색
- Data Dictionary에 미리 수집해 둔 Object statistics 및 Systam statistics등을 이용해 예상비용 산정
- 최저 비용을 나타내는 실행계획 선택
비용(cost)이란?
옵티마이저가 쿼리를 수행하는 동안 발생할 것으로 예상하는 I/O 횟수 또는 예상 소요시간을 표현한 값 (정확하지 않은 예상치)
Optimizer가 최저 비용을 나타내는 실행계획을 선택하는 과정을 알아보기 위하여, 다음과 같은 실험을 진행하였다.
(DBeaver 24.2.3, MySQL9.1.0 on Docker27.3.1. Using MySQL Sakila Sample Data)
가설 : Optimizer는 현재 존재하는 인덱스 중 가장 최저 비용의 인덱스를 선택하여, 해당 경로를 테이블 스캔에 이용한다.
실험 대상
rental 테이블 ( COUNT(*) 16,044 )
DESCRIBE rental ;

실험 준비
1. 일반 인덱스 하나와, 비효율적일 것으로 생각되는 인덱스를 생성한다 ( 각 인덱스별 비용 차이를 확인하기 위함 )
CREATE INDEX r_x01
ON rental (rental_id, inventory_id);
CREATE INDEX r_x02
ON rental (rental_id, rental_date, inventory_id, customer_id, return_date, staff_id, last_update);- 테이블 최적화, 테이블 캐시 제거 등 실험 오차를 줄이기 위한 전처리 작업을 진행한다.
OPTIMIZE TABLE rental;
ANALYZE TABLE rental;
SET GLOBAL innodb_buffer_pool_size = 0;
FLUSH TABLES WITH READ LOCK;
UNLOCK TABLES;(OPTIMIZE 정상 진행되지 않아 ANALYZE 한 번 더 실행해 주었음 :Table does not support optimize, doing recreate + analyze instead)
이와 같이 준비작업을 거치면, 다음과 같이 인덱스가 준비된다(기본 생성되어 있는 인덱스 포함)
SHOW INDEX FROM rental ;
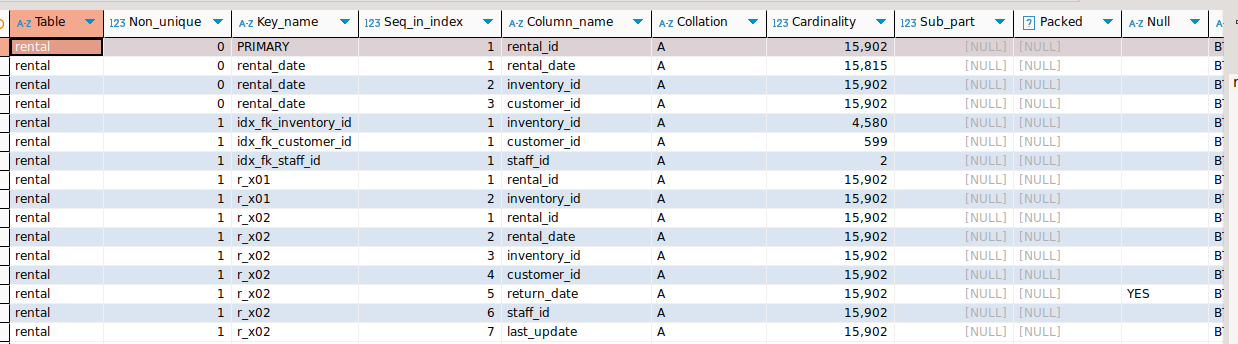
이제부터 해당 테이블에 대해 다음과 같은 SELECT 구문을 실행함으로서, 각 경로별 비용의 차이와 Optimizer의 경로 선택을 추적해본다.
SELECT * FROM rental r
WHERE customer_id = 1
AND staff_id = 2;위의 구문을 각 Index에 대해 FORCE INDEX 구문으로 Explain Execution Plan한 결과는 다음과 같다.
예시 코드
SELECT *
FROM rental r FORCE INDEX ( PRIMARY )
WHERE customer_id = 1 AND staff_id = 2;

| Selected index | Select cost | nodeName | table cost | Rows |
|---|---|---|---|---|
| Optimizer Auto | 21.5 | r(index_merg) | 20 | 15 |
| PRIMARY | 17680.2 | r(ALL) | 17678.86 | 16072 |
| rental_date | 17680.2 | r(ALL) | 17678.86 | 16072 |
| idx_fk_inventory_id | 17680.2 | r(ALL) | 17678.86 | 16072 |
| idx_fk_customer_id | 28.6 | r(ref) | 26 | 26 |
| idx_fk_staff_id | 1094.6 | r(ALL) | 291 | 8036 |
| r_x01 | 17680.2 | r(ALL) | 17678.86 | 16072 |
| r_x02 | 17680.2 | r(ALL) | 17678.86 | 16072 |
결과 및 해석
우선 Optimizer가 자동으로 선택한 경로를 제외한 기타 결과값들에 대해서만 확인해보자.
PRIMARY, rental_date, idk_fk_inventory_id, r_x01, r_x02에 대해서는 r(ALL)의 결과로 FULL SCAN이 진행되었다.
그 이유에 대해서 알아보기 위해서는, 실험을 진행한 QUERY의 구조를 다시 한 번 확인해 볼 필요가 있다.
SELECT * FROM rental r
WHERE customer_id = 1
AND staff_id = 2;위 쿼리에서는 customer_id와 staff_id를 query의 조건으로 이용하고 있는데, r_x02를 제외하면 모든 index는 해당 값을 참조하지 않고 있다.
따라서 FULL SCAN이 진행된 것이다.
r_x02의 경우customer_id와 staff_id를 가지고 있으나 FULL SCAN이 진행되었다. 그 이유는 해당 Index가 복합 인덱스이기 때문이다.
복합 인덱스는 첫 번째 열부터 시작하여 조건이 일치할 때만 최적화(Leftmost Prefix Rule)되는데, r_x02의 경우 쿼리에서 사용된 컬럼이 중간에 포함되어 있으므로 제대로 활용되지 않은 것이다.
만일, customer_id와 staff_id가 포함된, 즉 인덱스에 필요한 모든 컬럼이 포함된 경우 테이블을 직접 조회하지 않고 인덱스만으로 처리(ex, 커버링 인덱스)가 가능하여 비용이 크게 낮아진다.
idx_fk_customer_id의 경우, 쿼리에서 사용되는 customer_id가 포함되어 있기 때문에, r(ref) 로 실행 계획이 수립되었고, 이에 따라 table cost가 26으로 현저히 낮아진 것을 보인다.
그렇다면, Optimizer Auto로 시행하였을 때, 28.6보다 낮은 값을 가지는 21.5라는 경로는 어떻게 선택되게 된 것일까?
이 경우, 기록된 표에서 nodeName을 보면 알 수 있다.
Optimizer Auto의 결과로 r(index_merg)가 실행되었는데, 이는 Optimizer가 단일 인덱스를 사용하는 것보다는 인덱스를 병합하여 사용하는 것이 더 효율적이라고 스스로 판단한 결과임을 나타낸다.
쿼리문에서 사용된 조건이 idx_fx_customer_id와 idx_fk_staff_id인덱스였으므로, 이를 교집합(intersect)하여 병합된 인덱스를 사용한 것이기 때문이다.
실제로 Optimizer Auto 쿼리에 대하여 Explain을 실행해 보면 다음과 같은 값을 확인할 수 있다.

이를 유도하기 위하여 다음과 같은 구문을 사용할 경우, 예상과 같은 결과가 출력된다.
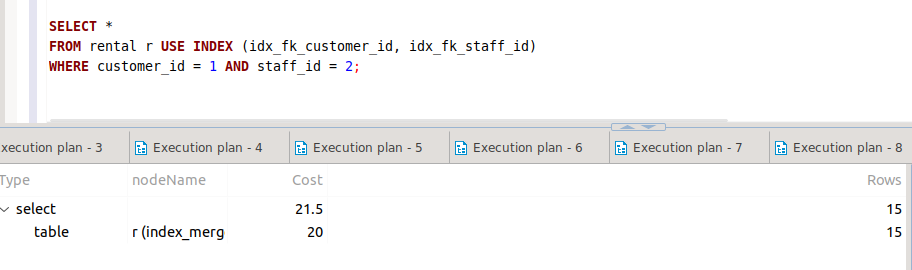
옵티마이저 힌트
: 옵티마이저가 선택한 경로 또한 예상치이므로, 일반적으로는 좋은 결과를 가져오나, 항상 최선이라고 보장할 수는 없다.
이 경우, 옵티마이저가 경로를 선택함에 있어 인간이 개입하여 방향성을 조정할 수 있는데, 이를 일부만 조정하거나, 전부를 강제할 수도 있다.
이렇게 옵티마이저 힌트를 사용하면, 쿼리의 실행 계획을 더욱 정밀하게 제어할 수 있고, 이는 쿼리가 예상과 다르게 실행되거나 최적화가 필요할 때 유용하게 쓸 수 있다.
MySQL에서 자주 사용하는 힌트들은 다음과 같다.
1. 인덱스 관련 힌트(Index Hints)
- USE INDEX : 특정 인덱스를 우선적으로 사용하도록 권장합니다.
SELECT *
FROM rental USE INDEX (idx_fk_customer_id)
WHERE customer_id = 1;- FORCE INDEX : 해당 인덱스를 강제 사용하며, 테이블 풀 스캔이 최후의 수단이 되도록 만듭니다.
SELECT *
FROM rental FORCE INDEX (idx_fk_customer_id)
WHERE customer_id = 1;- IGNORE INDEX : 지정된 인덱스의 사용을 막고, 다른 인덱스나 테이블 스캔을 유도합니다.
SELECT *
FROM rental IGNORE INDEX (idx_fk_staff_id)
WHERE customer_id = 1 AND staff_id = 2;2. 조인 순서 제어 힌트 (Join Order Hints)
: 이하의 힌트들은 주석 내에 /+ ... / 형태로 힌트를 추가하면, MySQL은 해당 힌트를 참고해 실행 계획을 수립합니다.
- JOIN_FIXED_ORDER : 테이블이
FROM절에 나열된 순서대로 조인되도록 강제합니다.
SELECT /*+ JOIN_FIXED_ORDER */ *
FROM t1 JOIN t2 ON t1.id = t2.id;- JOIN_ORDER, JOIN_PREFIX, JOIN_SUFFIX : 특정 테이블 조인 순서의 일부만 지정합니다. 나머지는 옵티마이저가 결정합니다.
3. 조인 알고리즘 제어 힌트(Join Algorighm Hints)
- BKA (Batched Key Access) / NO_BKA : 배치 키 접근(BKA)알고리즘의 사용을 제어합니다.
- BNL (Block Nested-Loop) / No_BNL : 블록 네스티드 루프 조인의 사용을 제어합니다.
4. 뷰와 서브쿼리 처리 힌트(Materialization and Merge Hints)
- MERGE / NO_MERGE : 뷰나 서브쿼리를 메인 쿼리에 병합할지, 또는 임시 테이블로 물리화할지 제어합니다.
5. 조건 푸시다운 힌트(Condition Pushdown Hints)
- DERIVED_CONDITION_PUSHDOWN / NO_DERIVED_CONDITION_PUSHDOWN : 파생 테이블(derived table)이나 뷰의 조건을 푸시다운(pushdown)할지를 결정합니다.
결론
MySQL의 옵티마이저 힌트는 쿼리 최적화를 세밀하게 제어할 수 있는 강력한 도구입니다. 그러나 모든 경우에 힌트가 성능을 개선하는 것은 아니므로, 실제 실행 계획(EXPLAIN)과 실행 시간 분석을 통해 최적의 설정을 찾는 것이 중요합니다.
더 자세한 내용은 MySQL 공식 문서에서 확인할 수 있습니다.
