[10.20] 내일배움캠프 3일차(웹개발종합)
👉 Python, 웹 크롤링, mongoDB 다루기
1. Python 기본 다지기
🚨Python은 들여쓰기가 매우 중요!🚨
- 변수 선언(정수,문자열)
👉 a = 3 , b = 2
👉 print(a + b) - > 5
👉 c = 'sanghoon' , d = 'good'
👉 print(c + d) -> 'sanghoongood'- 변수 선언(List, Dict)
👉 a_list = ['사과', '배', '감']
👉 a_list.append('수박') -> 데이터 추가
👉 b_dict ={'name' : 'bob' , 'age' : 26}
👉 b_dict[ 'name' ] , b_dict[ 'age' ] 접근
- 함수 선언
👉 def sum(a,b):
return a+b
👉 result = sum(2,3) -> 5 담김
- 조건문
👉 def is_adult(age):
if age > 20: print('성인 입니다!')
else : print('청소년 입니다!')
👉 is_adult(19) -> 청소년 입니다!
- 반복문(List)
👉 fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
👉 for fruit in fruits :
print(fruit) -> 리스트 형식의 데이터 끝까지 출력.
- 반복문(Dict)
👉 people = [ {'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27} ]
👉 for person in people :
if person[ 'age' ] > 20 :
print(person[ 'name' ]) -> 20살보다 높은 나이 사람 출력.
2. Python 웹 크롤링
- 패키지 : 라이브러리 담아두는 공간이라고 생각.
- 웹 크롤링 시 JS의 Ajax와 같이 url로 Data를 요청할 때 유용한 패키지 설치
👉 setting -> python 인터프리터 -> + -> requests검색 후 설치 -> Ajax와 비슷
- Request 패키지 사용 예제 1( Json데이터 API 가져오기!! )
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for row in rows :
gu_name = row['MSRSTE_NM']
gu_mise = row['IDEX_MVL']
if gu_mise < 60 :
print(gu_name)
👉 request.get('url')로 data 가져온 뒤 .json메서드로 타입 변환
- Request 패키지 사용 예제 2( 운영 중인 웹 사이트 정보 가져오기!!)
👉 브라우저 웹 크롤링 시 테그 접근하기 유용한 패키지 beautifulsoup
- //웹 브라우저에서 요청하는 것 같이 하기 위한 헤더
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
- //헤더를 포함한 url요청 후 반환 값 저장
data=requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
👉 가져오고 싶은 data들의 공통되는 해당 테그를 살펴보고 접근 하도록 한다!!
👉 본 예제는 '#old_content > table > tbody > tr' 까지의 공통 범위 테그를 갖고 있기 때문에 soup.select()의 범위가 결정.
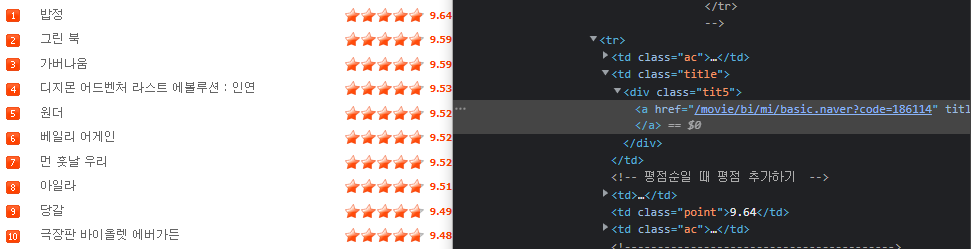

movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None :
title = a.text
star = movie.select_one('td.point').text
rank = movie.select_one('td:nth-child(1) > img')['alt']👉 각각 제목, 별점, 순위를 찾아 출력하는 코드 부분.
- Request 패키지 사용 예제 3( 운영 중인 웹 사이트 정보 가져오기!!)
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701', headers=headers)
# body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number // 순위
# body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis // 곡명
# body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis // 아티스트
soup = BeautifulSoup(data.text, 'html.parser')
genie_chart = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for genie in genie_chart:
a = genie.select_one('td.info > a.title.ellipsis')
if a is not None:
rank = genie.select_one('td.number').text[0:2].strip()
title = a.text.strip()
artist = genie.select_one('td.info > a.artist.ellipsis').text
print(rank, title,artist)👉 지니 웹 사이트에서 순위 곡 이름 아티스트를 크롤링 해보자.
👉 공통 테크 접근 #body-content > div.newest-list > div > table > tbody > tr
👉 순위, 곡 이름 ,아티스트를 크롤링 하면서 다른 문자열의 제거와
공백열 제거를 위해 text[ 0 : 2 ] , 와 strip( )을 사용
3. MongoDB
- MongoDB연결에 필요한 패키지 mongopy , dnspython
👉 test : idfrom pymongo import MongoClient client = MongoClient('mongodb+srv://test:sparta@cluster0.cygiufq.mongodb.net/Cluster0?retryWrites=true&w=majority') db = client.dbsparta
👉 sparta : pw
👉 Cluster0 :
- MongoDB 기본 사용
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:sparta@cluster0.cygiufq.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})👉 MongoDB 저장시 Dict 형태 {' name ' : ' bob '} 로 저장
4. MongoDB와 웹크롤링 사용
👉 네이버 영화 랭킹, 이름 , 평점 가져와서 저장하기 - 예제 1
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:sparta@cluster0.cygiufq.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta
# 코드에서 요청하는 것을 브라우저에서 요청하는 것 처럼 해주는 것
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
#old_content > table > tbody > tr:nth-child(8) > td.title > div > a
#old_content > table > tbody > tr:nth-child(4) > td.point // 평점
#old_content > table > tbody > tr:nth-child(2) > td:nth-child(1) > img // 순위
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None :
title = a.text
star = movie.select_one('td.point').text
rank = movie.select_one('td:nth-child(1) > img')['alt']
# print(rank,title.text,star)
doc = {'title':title,
'rank':rank,
'star':star}
db.movies.insert_one(doc) 
👉 epl 공식 순위 가져와서 저장하기[ Remake ] - 예제 2
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=epl%EB%93%9D%EC%A0%90%EC%88%9C%EC%9C%84', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:sparta@cluster0.cygiufq.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta
#teamRankTabPanel_0 > div > div.scroll > table > tbody > tr:nth-child(1) > th // 순위
#teamRankTabPanel_0 > div > div.scroll > table > tbody > tr:nth-child(1) > td.team.tp.wdt > p > span > a //팀이름
#teamRankTabPanel_0 > div > div.scroll > table > tbody > tr:nth-child(2) > td.team.wdt > p > span > a
#teamRankTabPanel_0 > div > div.scroll > table > tbody > tr:nth-child(1) > td:nth-child(5) // 승
#teamRankTabPanel_0 > div > div.scroll > table > tbody > tr:nth-child(1) > td:nth-child(6) // 무
#teamRankTabPanel_0 > div > div.scroll > table > tbody > tr:nth-child(1) > td:nth-child(7) // 패
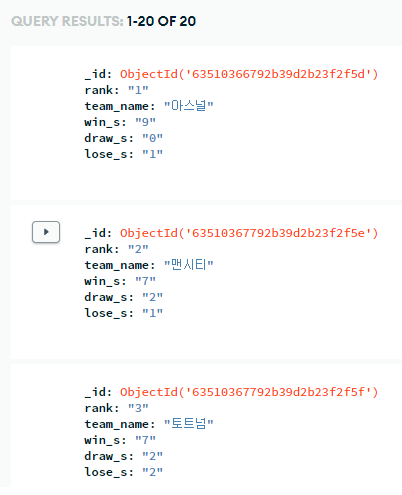
soccers = soup.select('#teamRankTabPanel_0 > div > div.scroll > table > tbody > tr')
for soccer in soccers:
a = soccer.select_one('td > p > span > a')
if a is not None:
rank = soccer.select_one('th').text
team_name = a.text
win_s = soccer.select_one('td:nth-child(5)').text
draw_s = soccer.select_one('td:nth-child(6)').text
lose_s = soccer.select_one('td:nth-child(7)').text
dict = {'rank': rank,
'team_name':team_name,
'win_s':win_s,
'draw_s':draw_s,
'lose_s':lose_s}
db.epl.insert_one(dict)
# print(rank,team_name,win_s,draw_s,lose_s)
5. 느낀점⭐
- Python의 문법은 간단하다. ( 줄 맞추는게 중요하다. )
- API 데이터를 request패키지로 크롤링 하는 것과 웹 사이트 자체의 데이터를 크롤링 하는 것을 헷갈리지 말자!!

기록하는 습관