제로베이스 데이터 취업스쿨_ EDA/웹 크롤링/파이썬 프로그래밍_이론_서울시 CCTV 현황 분석 프로젝트 소개 및 데이터 출처
제로베이스 데이터 취업스쿨_ EDA/웹 크롤링
서울시 CCTV 분석
분석 및 시각화
겁나게 초급용임....
난데 없이 왜 서울시 CCTV를 분석하는가?
python, pandas, matplotlib을 써보기 좋은 데이터 셋임.
오늘의 목표 : 인구수 대비 cctv 설치율 보기
1. 서울시 구별 cctv 현황 데이터 확보 (python, pandas)
2. 인구 현황 데이터 확보 (python, pandas)
3. cctv 데이터와 인구현황 데이터 합치기 (python, pandas)
4. 데이터를 정리하고 정렬하기 (python, pandas)
5. 그래프를 그릴 수 있는 능력(matplotlib)
6. 전제적인 경향을 파악할 수 있는 능력 (regression using Numpy)
7. 그 경향에서 벗어난 데이터를 강조하는 능력 (Insight and Visualization)
seoul CCTV 설치 현황과
seoul population 현황 데이터 받음
pandas로 CSV, 엑셀 파일 읽기
- python에서 R 만큼 강력한 데이터 핸들링 성능 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용가능한 엑셀로 받아들여도 됨
import pandas as pd #usually
import numpy as nd #usually
data = pd.Series([1,3,5, np.nan, 6,8])
# pandas dataset is series
# np.nan은 결측값
# 3번째 인덱스에 해당하는 값은 np.nan으로 결측값
dates = pd.date_range('20130101', periods = 6)
#날짜(시간)을 이용할 수 있다
# periods = 생성할 날짜의 개수
# datetime64[ns] = 날짜 형식
# 주기(freq)는 일별('D')
# 다르게 입력하려면
# dates = pd.date_range('20130101', periods=6, freq='M')
df.head() #df.head()와 df.info()는 판다스에서 제공하는 메서드(Method). 메서드는 함수(function)와 마찬가지로 호출될 때 ()를 사용하여 실행.
df.index # 데이터프레임의 속성(Attribute). 속성은 데이터프레임의 특징이나 속성 값을 반환하며, ()를 사용하여 호출하지 않음.
df.column
df.value
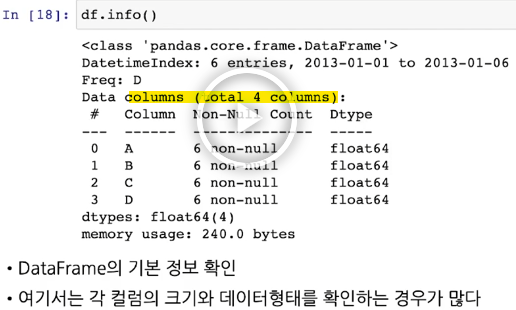
df.info() # dataframe의 기본 정보 확인. 각 열의 크기와 데이터 형태 확인하는 경우가 많음
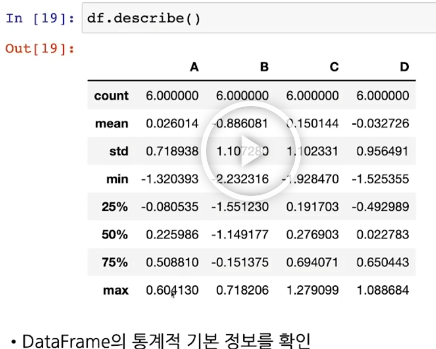
df.describe() # dataframe의 통계적 기본 정보 확인
df.sort_values(by ='B', ascending=False) #ascending=False : 내림차순
df['A']#열 인덱스의 값
df[0:3]#행 번호
df["20130101":"20130102"] #행 인덱스
df.loc["20130101":"20130102",['A','B']] #어디서부터 어디 행의 어떤어떤 열 값
df.loc["20130101",['A','B']] #하나의 행 에 있는 열 값
df.iloc[3] #행 번호
df.iloc[[1,2,4],[0,2]] #행번호, 열번호
df.iloc[:, 1:3]#모든열의 1,2번 행
#loc는 문자로 찾는거고, iloc는 행 값으로 찾는거
df[df['A']>0] #df를 표현하는데, df a 열에서 0보다 큰걸 보여라
df[df['A']>0] #df를 표현하는데, df a 열에서 0보다 큰걸 보여라
df[df>0]#df를 표현하는데, df에서 0보다 큰걸 보여라(0보다 작은거느 Nan처리)
df['E'] = ['one','one','two','thre','four','three',] #dataframe명[새로추가할 열 이름] = [데이터 내용]
df['E'].isin(['two','four']) #df e열에 저 값이 있는지 확인해봐라
df[df['E'].isin(['two','four'])] #df에서 df e열에 저 값이 있는지 확인해보고 그거만 뽑아줘라
del df['E'] #특정 열 제거
df.apply(np.cumsum) # 각 열의 누적 합 표형태로

'D': 일별
'B': 주중(평일)만 포함한 일별
'W': 주간(매주 일요일)으로
'M': 월말로
'Q': 분기말로
'A' 또는 'Y': 연말로

다른 예
pd.Series([1,2,3], dtype=float)
pd.Series([1,2,3,4,], dtype=np.float64) # float16: 16비트 부동소수점형 데이터 타입입니다. 약 3~4자리의 유효 숫자를 표현할 수 있습니다. float32: 32비트 부동소수점형 데이터 타입입니다. 약 7자리의 유효 숫자를 표현할 수 있습니다. float64: 64비트 부동소수점형 데이터 타입입니다. 약 15자리의 유효 숫자를 표현할 수 있습니다. float128: 128비트 부동소수점형 데이터 타입입니다. 약 18자리의 유효 숫자를 표현할 수 있습니다.
pd.Series(np.array([1,2,3])) #pd.Series(np.array([1,2,3]))는 NumPy 배열을 사용하여 Series를 생성하는 것입니다. NumPy 배열은 고성능의 다차원 배열을 제공하는 패키지로, 데이터를 효율적으로 저장하고 처리할 수 있습니다. 따라서 NumPy 배열을 사용하면 데이터 처리 속도가 향상될 수 있습니다.
#pd.Series([1,2,3], dtype=str)는 데이터를 리스트로 직접 전달하며, dtype=str 매개변수를 사용하여 Series의 데이터 타입을 문자열로 설정하는 것입니다. 이 경우에는 Series의 모든 요소가 문자열로 변환됩니다. 데이터 타입을 명시적으로 지정할 수 있으므로, 데이터를 원하는 형식으로 강제로 변환할 수 있습니다.
#즉, 첫 번째 방식은 NumPy 배열을 사용하여 Series를 생성하고, 두 번째 방식은 리스트를 사용하여 Series를 생성하면서 데이터 타입을 명시적으로 설정하는 차이가 있습니다. NumPy 배열은 특히 대량의 숫자 데이터 처리나 과학적인 계산 작업에서 유용하게 사용될 수 있습니다.행, 열 지우는법
df.drop(['e'], axis=1) #axis=0 가로, axis=1 세로
df.drop(['2013-01-02'], axis=0) #axis=0 가로, axis=1 세로열의 합계, 최소, 최대, 평균 구하는법
df['A'].apply('sum')
df['A'].apply('min')
df['A'].apply('max')
df['A'].apply('average')
df[['A', 'D']].apply(np.sum)
#np로 사용하는것도 가능!주피터,vs 함수
def plusminus(num):
return 'plus' if num >0 else 'minus'
df['A'].apply(plusminus)
df['A'].apply(lambda x:'plus') #lambda x: 'plus'는 입력값 x를 받아서 항상 'plus'라는 문자열을 반환하는 함수
df['A'].apply(lambda num: 'plus'if num >0 else 'minus')CCTV데이터와 인구현황 데이터 훑어보기
CCTV_Seoul['13년 이후 증가율'] = (
(CCTV_Seoul['2022년']+CCTV_Seoul['2021년']+CCTV_Seoul['2020년']+CCTV_Seoul['2019년']+CCTV_Seoul['2018년']
+CCTV_Seoul['2017년']+CCTV_Seoul['2016년']+CCTV_Seoul['2015년']+CCTV_Seoul['2014년']+CCTV_Seoul['2013년']
) / len(CCTV_Seoul.columns)
*100
)
CCTV_Seoul.sort_values(by='13년 이후 증가율', ascending=True).head(5)여기서 파일 자체에서 value들이 숫자가 아니라서... 개고생함
pop_Seoul.drop([0], inplace=True) #합계 열 지움
pop_Seoul.head()
pop_Seoul['자치구'].unique()#자치구에 어떤 index들이 있는지 확인
pop_Seoul['한국인비율'] = pop_Seoul['한국인'] / pop_Seoul['인구수'] * 100
pop_Seoul['외국인비율'] = pop_Seoul['외국인'] / pop_Seoul['인구수'] * 100
pop_Seoul['고령자비율'] = pop_Seoul['고령자'] / pop_Seoul['인구수'] * 100하.. 이것도 파일 자체에서 value가 숫자가 아니라서 개고생했고...
하 진짜 개힘들었다.
pop_Seoul 확인하는데 또 합계 열이 있는겨
그래서 각 해마다 위에있는 합계열을 지우려고 쌩쑈를함
방법은
pop_Seoul = pop_Seoul.drop(pop_Seoul[pop_Seoul['자치구'] == '합계'].index)
pop_Seoul을 재정의할건데
pop_Seoul에서 이런걸 지워라
pop_Seoul안에서 이 인덱스를 지우는데
어떤 인덱스냐하면pop_Seoul의 '자치구'열에 '합계가 있는 열의 인덱스를.
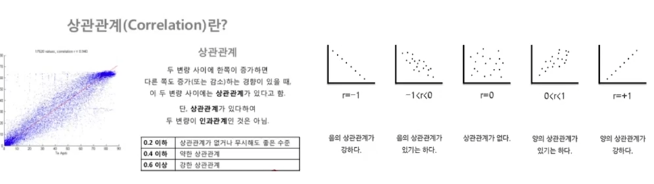
*중요한건, 상관관계가 있다고 해서 인과관계가 있는건 아니다.
pd.merge(left, right, how='left', on='key') #key 열을 기준으로 공통으로 가지고 있는 열들만 병합
#how는 기준이 되는 데이터셋. 만약 how데이터셋에만 있는거라도 가지고 오게 되며, 나머지딸려오는 데이터셋에 그 데이터가 없으면 nan표시, 딸려오는 데이터셋에만 있는건 또 안옴
#만약 다 살린다? 하면 how = 'outer'하면 됨data_result = pd.merge(CCTV_Seoul, pop_Seoul, on = '자치구')
data_result.head()
data_result.set_index('자치구', inplace=True) # 기존에는 index 숫자였는데 이제 자치구 따라서 index 설정!
data_result.head()
data_result.corr() #상관관계 보는법
# 데이터의 관계를 찾을 때, 최소한의 근거가 있어야 해당 데이터를 비교하는 의미가 존재함.
# 상관계수를 조사해서 절대값 0.2 이상의 데이터를 비교하는 것이 의미가 있다.
총계 2014년 2015년 2016년 2017년 2018년 2019년 2020년 2021년 2022년 13년 이후 증가율 인구수 한국인 외국인 고령자
총계 1.000000 0.600059 0.738385 0.691330 0.678957 0.695110 0.496219 0.437304 0.559023 0.165895 0.994851 0.390291 0.379328 0.105692 0.128124
2014년 0.600059 1.000000 0.499137 0.533287 0.293208 0.458973 0.187133 0.309275 0.074742 -0.019444 0.606659 0.305743 0.295872 0.104650 0.123546
2015년 0.738385 0.499137 1.000000 0.670131 0.561094 0.515924 0.174702 0.273157 0.242700 0.010339 0.757830 0.401815 0.394444 0.042059 0.114815
2016년 0.691330 0.533287 0.670131 1.000000 0.660402 0.423000 0.150797 0.128985 0.157973 0.007654 0.719211 0.286061 0.282330 0.004110 0.117997
2017년 0.678957 0.293208 0.561094 0.660402 1.000000 0.431984 0.038134 0.051713 0.374117 0.076692 0.678955 0.156122 0.148938 0.089969 0.020881
2018년 0.695110 0.458973 0.515924 0.423000 0.431984 1.000000 0.308508 0.227964 0.221367 -0.019917 0.685777 0.347326 0.332419 0.181833 0.108874
2019년 0.496219 0.187133 0.174702 0.150797 0.038134 0.308508 1.000000 0.031107 0.356496 0.017990 0.485375 0.417816 0.418968 -0.106515 0.179749
2020년 0.437304 0.309275 0.273157 0.128985 0.051713 0.227964 0.031107 1.000000 0.119583 0.039479 0.447827 -0.017393 -0.034949 0.302804 -0.025917
2021년 0.559023 0.074742 0.242700 0.157973 0.374117 0.221367 0.356496 0.119583 1.000000 0.222868 0.530330 0.164724 0.158943 0.064260 0.041304
2022년 0.165895 -0.019444 0.010339 0.007654 0.076692 -0.019917 0.017990 0.039479 0.222868 1.000000 0.186364 -0.009164 0.003899 -0.220709 0.023679
13년 이후
증가율 0.994851 0.606659 0.757830 0.719211 0.678955 0.685777 0.485375 0.447827 0.530330 0.186364 1.000000 0.385166 0.374453 0.102487 0.128840
인구수 0.390291 0.305743 0.401815 0.286061 0.156122 0.347326 0.417816 -0.017393 0.164724 -0.009164 0.385166 1.000000 0.998333 -0.179505 0.264857
한국인 0.379328 0.295872 0.394444 0.282330 0.148938 0.332419 0.418968 -0.034949 0.158943 0.003899 0.374453 0.998333 1.000000 -0.235992 0.241496
외국인 0.105692 0.104650 0.042059 0.004110 0.089969 0.181833 -0.106515 0.302804 0.064260 -0.220709 0.102487 -0.179505 -0.235992 1.000000 0.343041
고령자 0.128124 0.123546 0.114815 0.117997 0.020881 0.108874 0.179749 -0.025917 0.041304 0.023679 0.128840 0.264857 0.241496 0.343041 1.000000-> cctv개수 대비 인구수의 상관관계는 0.390291.
엄청 높은 편이 아님
따라서 구 별 인구 대비 cctv개수를 분석해서
상대적으로 cctv가 적거나 많은 구를 찾는것이 의미를 가짐
data_result['cctv 비율'] = data_result['총계'] / data_result['인구수'] * 100
data_result.sort_values(by='cctv 비율', ascending=True).head(5)