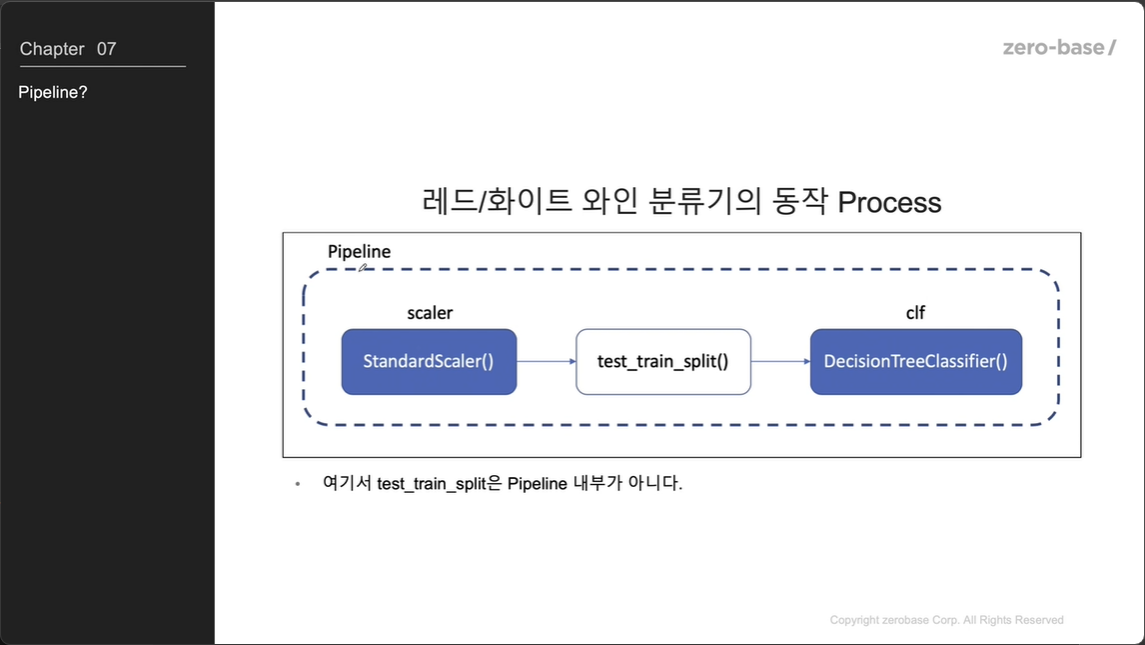
Pipeline

동작 프로세스

pipeline.steps

set_params

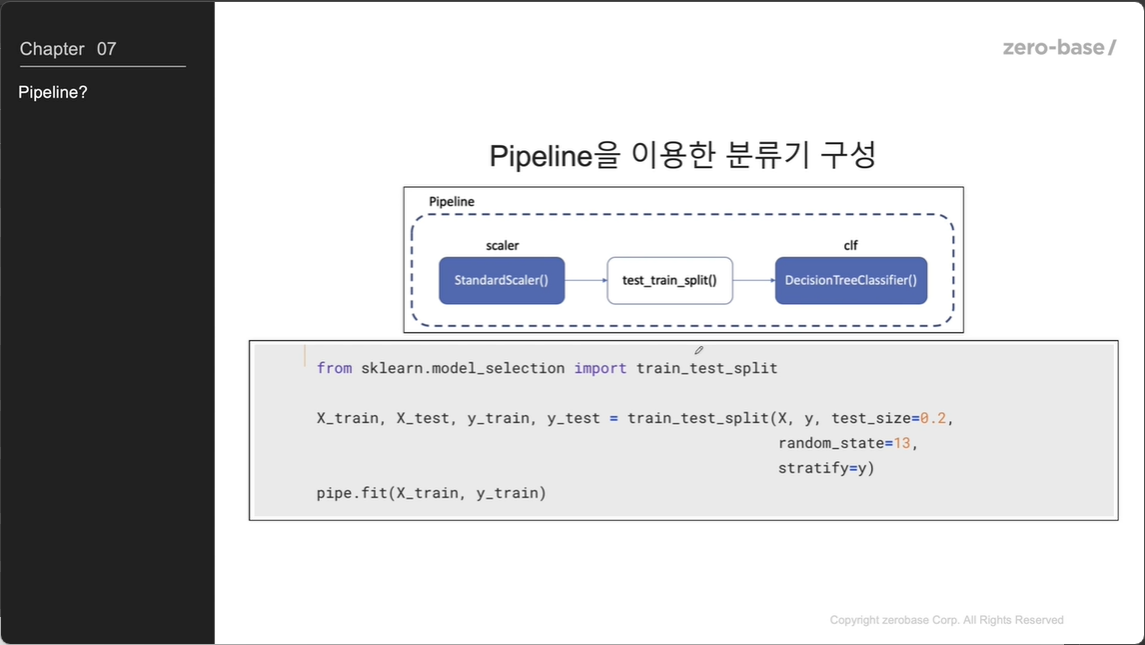
분류기 구성
결과

하이퍼파라미터 튜닝
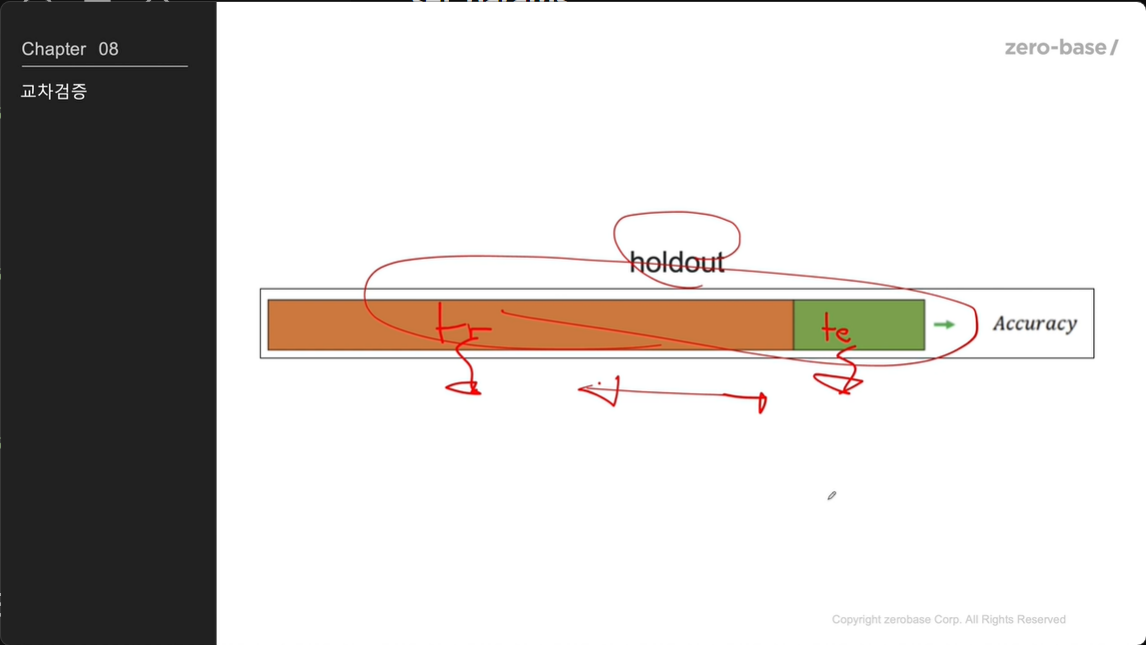
교차검증

hold out
k-fold cross validation
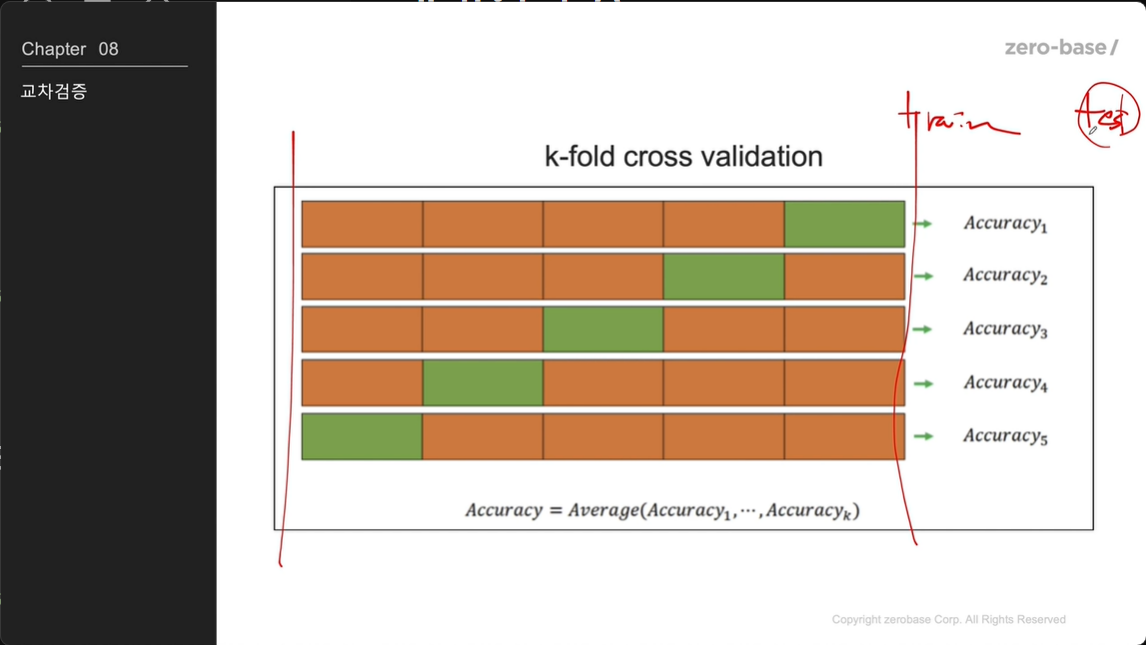
- K-Fold 교차 검증은 데이터를 K개의 부분집합으로 나누고, K번의 실험을 수행하여 모델의 성능을 평가하는 방법
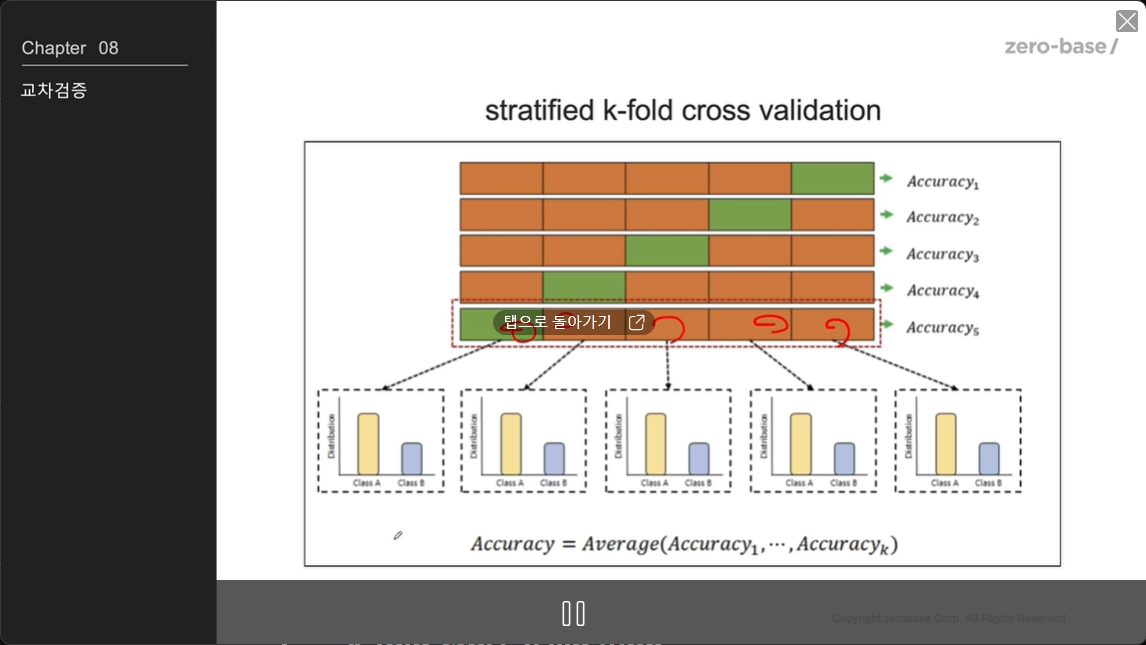
stratified k-fold cross validation
구현하기
from sklearn.model_selection import KFold
x = np.array([[1,2],[3,4],[1,2],[3,4]])
y = np.array([1,2,3,4])
kf = KFold(n_splits=2)
# n_splits 매개변수는 데이터를 몇 개의 부분집합으로 나눌지를 결정
print(kf.get_n_splits(x))
print(kf)
for train_idx, test_idx in kf.split(x):
print('---idx')
print(train_idx, test_idx)
print('---train data')
print(x[train_idx])
print('---val data')
print(x[test_idx])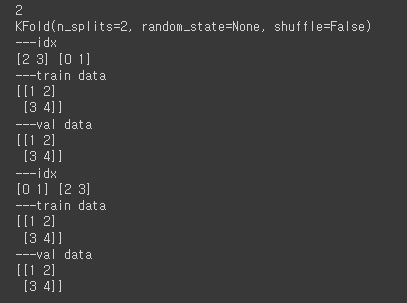
x = wine.drop(['taste', 'quality'], axis=1)
y= wine['taste']
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size = 0.2, random_state = 13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(x_train, y_train)
y_pred_tr = wine_tree.predict(x_train)
y_pred_test = wine_tree.predict(x_test)
print('taste train : ', accuracy_score(y_train, y_pred_tr))
print('taste test : ', accuracy_score(y_test, y_pred_test))taste train : 0.7294593034442948
taste test : 0.7161538461538461
KFold
보통 5폴드 씀
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)아직은 연결되진 않은 상태
KFold의 훈련, 검증 값 분류 확인
for train_idx, test_idx in kfold.split(x):
print(len(train_idx), len(test_idx))5197 1300
5197 1300
5198 1299
5198 1299
5198 1299
각각의 fold에 대해 학습 후 정확도 확인
cv_accuracy = []
for train_idx, test_idx in kfold.split(x):
x_train, x_test = x.iloc[train_idx], x.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
# 각 폴드의 학습(train) 및 검증(test) 인덱스를 순회
wine_tree_cv.fit(x_train, y_train)
pred = wine_tree_cv.predict(x_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy[0.6007692307692307,
0.6884615384615385,
0.7090069284064665,
0.7628945342571208,
0.7867590454195535]
만약, stratified K fold를 사용하고 싶다면
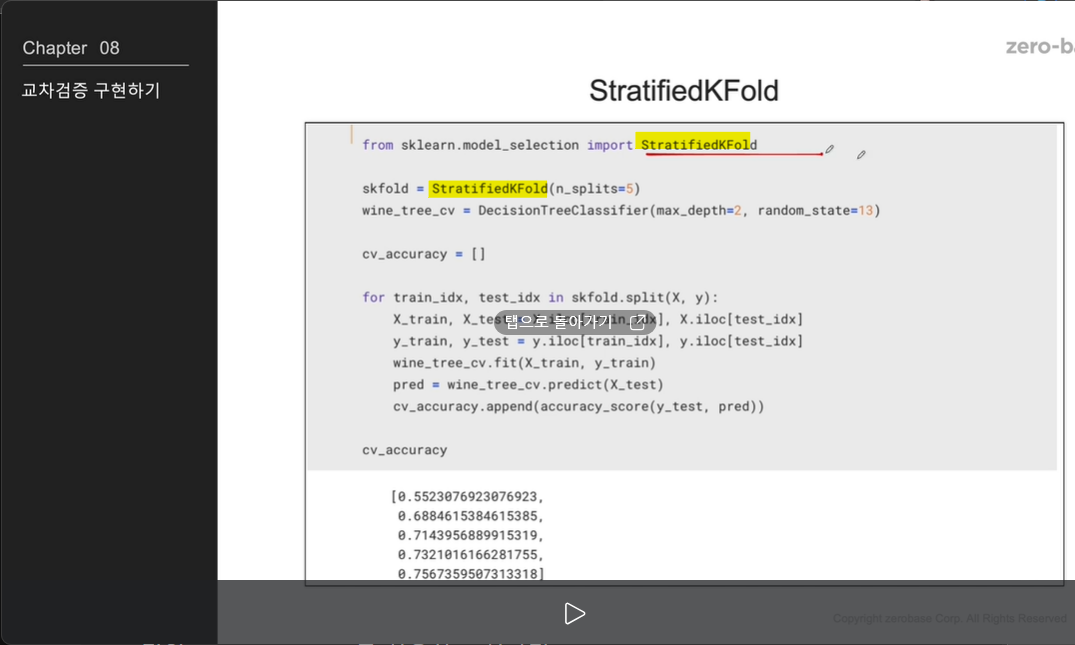
각 정확도의 분산이 크지 않다면 평균을 대표값으로 함
np.mean(cv_accuracy)0.709578255462782
그런데 stratified K fold 평균이 일반보다 더 나쁘다

그럴떄는

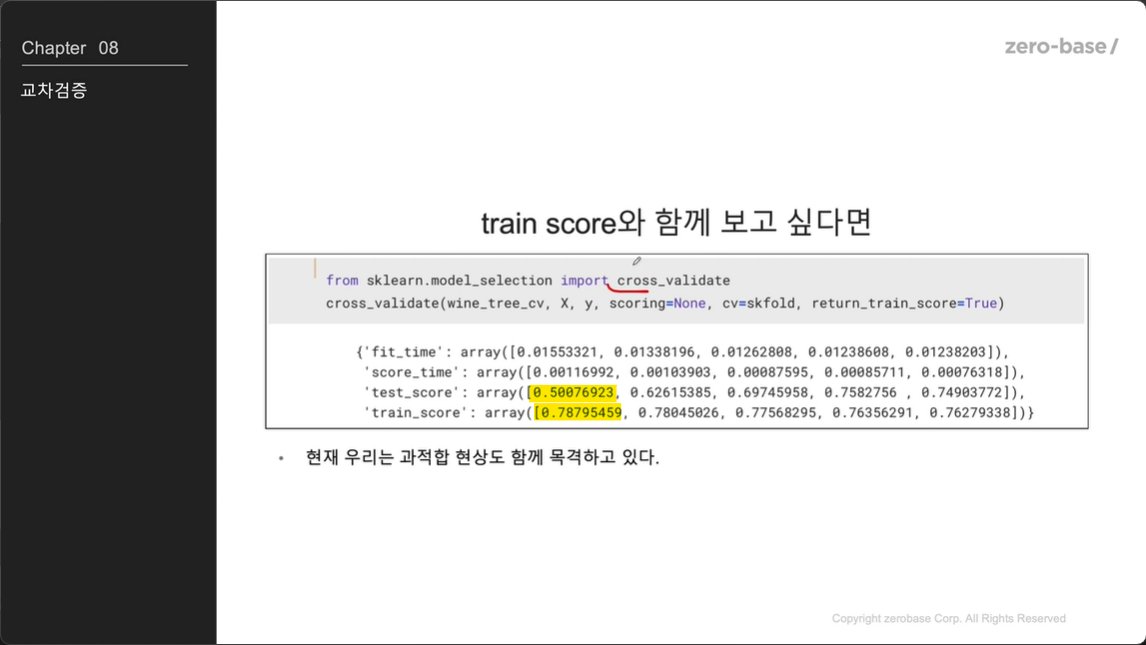

수야는 코린이에서 더 나아갈거야