
1. 프로젝트 주제 선정 및 분석 배경
- 주제
- OCR 서비스 구현 및 완결성, 이식성을 갖춘 코드 작성
- 기획의도
- 이미지로 되어있는 제품의 정보를 문자열로 치환하여 유용한 데이터로 저장
- 목표
- OCR + GPT api를 통해 이미지에서 정확한 식품 정보를 추출
- 필요에 따라 활용할 수 있는 지속가능한 서비스로 구현
2. 프로젝트 개요
-
독립적인 환경과 지속 가능한 개발을 위한 환경설정
→ 독립적인 개발환경을 구성하기 위해서 docker 환경을 구성하여 필요한 라이브러리 설치
→ 차후 다른 프로젝트에 코드 이식성을 위해서 코드 refactorization 및 abstraction 진행 -
수집된 데이터에 최적화된 OCR 모델 선정이 필요 (Open source)
→ OCR모델 테스트 진행: DONUT, Paddle-ocr, Pororo-ocr, Easy-ocr, Tesseract ocr -
데이터 보완을 위해 사용한 GPT api
→ fine-tuning 없는 ocr 만으로는 데이터 구조화에 한계가 있어 따로 GPT-api를 활용하여 parsing 및 correction 진행
3. 프로젝트 일정
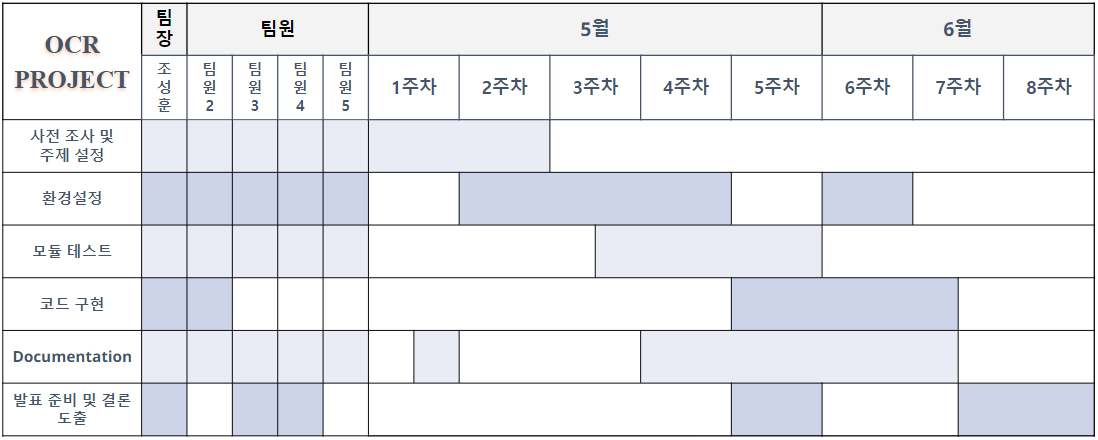
<이름은 본인 제외하고는 게제하지 않았음>
4. 개발환경 및 사용 라이브러리
개발언어 및 라이브러리, IDE, 소통 tool 등등
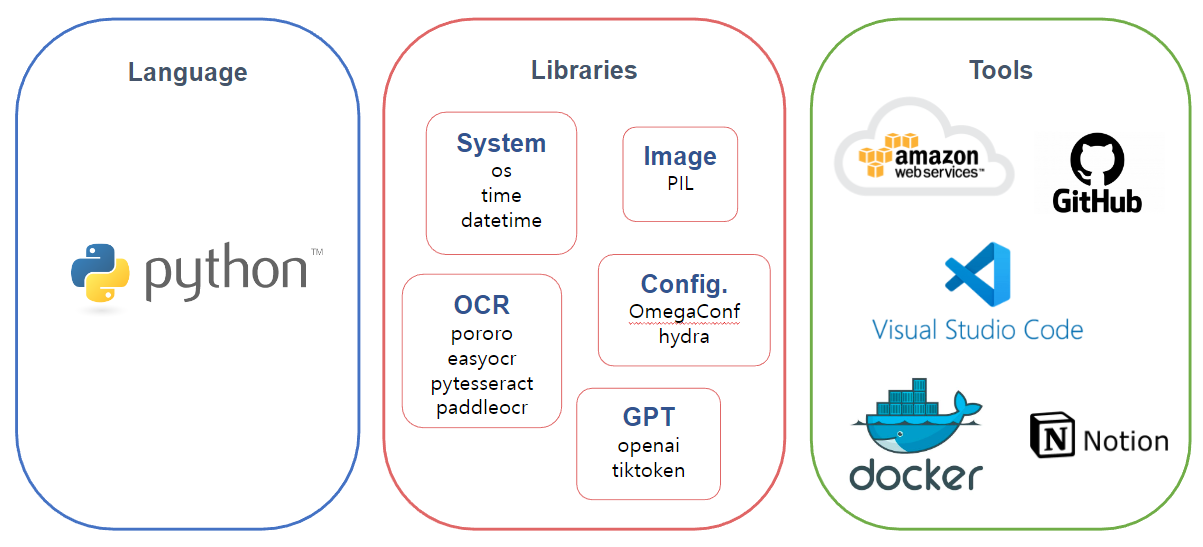
전체 프로젝트 구조도
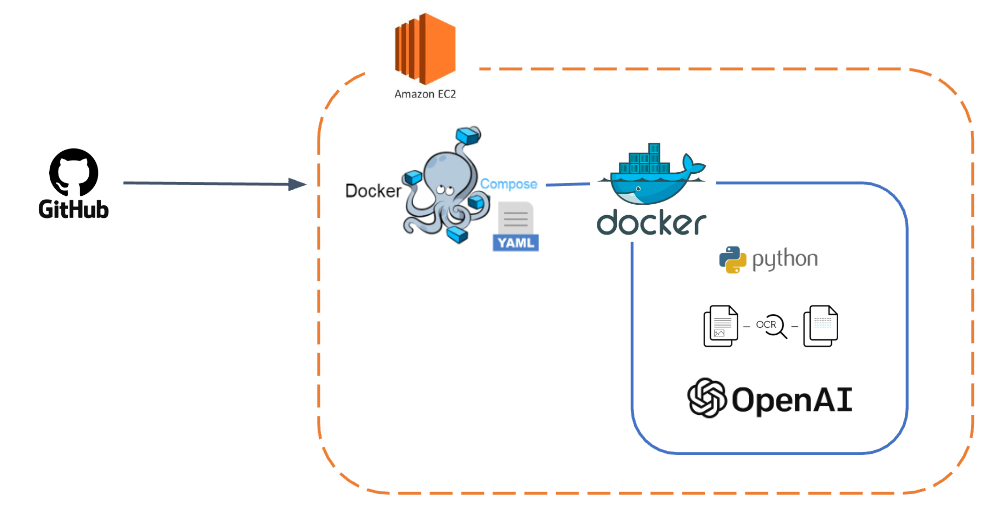
5. 데이터
데이터는 협업을 진행한 기업에서 제공해주었으며 꽤나 많은 종류의 데이터가 존재하였다.
-
깔끔한 라벨 이미지

위와 같이 정말 딱 식품의 라벨 데이터만 깔끔하게 detection되어 있는 형태로 가장 이상적인 데이터이다. 하지만 각각 라벨마다 다 유사한 정보가 기록되어 있는 부분들이 달라서 어떻게 처리해야하나 고민이 들었다. -
제품 자체를 촬영한 이미지

위와 같이 제품자체를 촬영한듯한 이미지로 품질 자체가 좋은 편이 아니었다. -
제품 광고를 그대로 가져온 이미지

가장 난감한 타입의 이미지이다. 가장 전처리가 필요한 종류의 데이터이며 가장 걱정되었던 타입의 데이터이다. 하지만 전체 데이터 셋에서 그렇게 많은 부분을 차지하지 않는 데이터의 형태였기 때문에 크게 신경쓰지 않기로 했다.
6. OCR 모델 테스트
팀원들이 나눠서 실험한 각각의 모델테스트이다. 각각 테스트한 데이터는 동일하지 않지만 대체적으로 위에서 언급한 1번 형태의 이미지를 사용하여 테스트 하였다.
아래는 팀원들이 나눠서 실험한 분석 결과이다.(본인은 easy_ocr, donut을 테스트하였다.)
tesserect_ocr
실행 결과는 그 유명세만큼 했던 기대에 미치지 못했다. 구글링을 조금 해보면 국내의 몇몇 Big Tech 기업들이 자체적으로 개발한 OCR 모델들이 있는 것을 알 수가 있는데, 영어와 달리 한글을 읽어내는 데에는 아무래도 그 모델들이 좀 더 좋은 성능을 발휘할 가능성이 높다고 예상해본다.
easy_ocr
정말 간단하게 사용할수 있는 detection + OCR 형태의 모델이다. 간단하게 사용할수 있는 만큼 실제로 사용하기에는 좋지 않은 모습을 보여준다. 아주 큰 문자는 어느정도 인식하고 제대로 변환하는것처럼 보이지만 현재 목표는 많은 수의 글자를 정확하게 식별하고 문자데이터로 변환하는것이 목적이므로 적합하지 않은 모델인것으로 판단된다.
paddle_ocr
ocr의 결과는 텍스트의 좌표, 텍스트 인식 결과, 정확성을 포함함. 깃허브의 예시와는 달리 생각보다 좋지 않은 성능을 보임. 필요하다면 training 가능
dount
기존의 OCR 모델은 detection + text configuration으로 2단계의 모형으로 이루어져 있다면 donut 모델은 이러한 전통적인 모델을 따르지 않는다. Transformer 모델을 차용하여 직접적으로 이미지와 json 파일을 생성하는 방식으로 OCR을 진행하기 때문이다. 만약에 이 모델을 더 효율적으로 사용할수 있는 방법이 있다면 사용하는것이 가장 좋은 방법이다. 왜냐하면 이 모델의 최종적인 목표는 이미지에 있는 text 데이터를 활용하여 챗봇기능까지 구현하고 있기 때문이다. 하지만 demo 코드를 돌려보니 현재 데이터에서 잘 작동하지 않는것으로 관찰되었고 새로운 데이터로 fine-tuning을 하거나 모델을 사용할 다른방법이 없다면 다른 모델을 사용하는것이 더 좋아보이는것으로 판단된다.
Pororo_ocr
2021년 2월 카카오브레인에서 다양한 한글 자연어 처리를 위해 통합된 형태의 자연어 프레임워크인 PORORO를 오픈소스로 공개했습니다. PORORO는 Platform Of neuRal mOdels for natuRal language prOcessing의 약어이며 HuggingFace와 같은 목적으로 개발되었다고 보시면 됩니다. 다만 PORORO는 한국어에 대해 좀 더 최적화 되어 있고 텍스트 분류, 시퀸스 태깅, 음성 인식 등 여러가지 기능들을 지원한다는 장점이 있습니다.
7. 코드
<전체 코드 구조도>

코드의 설계 같은 경우에는 전적으로 내가 담당하여 진행하였다.
전체적으로 외부에서 사용하기에는 run_ocr.py 파일만 실행하면 되도록 설계를 진행하였다. 코드의 실행은 외부의 라이브러리의 영향을 받지 않게 docker container 위에서 실행되며 app 디렉토리를 기준으로 디렉토리에 있는 모든 파일들이 mount 된다.
필요한 라이브러리와 환경설정을 위해서 dockerfile, docker-compose.yml 파일을 작성하였다. 아래는 전체 dockerfile이다.
FROM python:3.8
# 패키지 설치를 위해서 터미널을 interactive하지 않게 변경
ENV DEBIAN_FRONTEND=noninteractive
# 작업 디렉토리를 설정
WORKDIR /app
RUN python -m pip install --upgrade pip
# 의존성 파일을 Docker 이미지로 복사
COPY requirements.txt .
# 필요한 파이썬 패키지와 필요한
RUN pip install --no-cache-dir -r requirements.txt
# open-cv dependecy file update
# tesseract-ocr 설치
# libtesseract4 설치가 되지 않는 상태가 있음
RUN apt-get update && apt-get -y install libgl1-mesa-glx
RUN apt-get update && apt-get -y install tesseract-ocr tesseract-ocr-korocr_api 파일은 위에서 실험한 모든 모델들을 한번에 실험할수 있도록 제작하였다.
하지만 현재 ubuntu 20.04 버젼이 아닌경우 pytesseract를 사용하기 위해서 설치해야하는 라이브러리가 설치되지 않는 현상이 발생한다. 또한 dounut도 구현은 되어 있지만 주로 사용한 pororo와는 pytorch 버전 충돌이 나기 떄문에 donut 모듈도 실행되지 않는다. 다음은 ocr_api.py 의 부분 코드이다.
...생략됨
class ocr_api :
def __init__(
self,
config: OmegaConf
) -> None:
# init function for ocr_api function it will push your config file to use ocr api
self.config = config
def pororo(
self,
img_pth: str
) -> str:
# OCR api that use pororo
ocr = Pororo(task="ocr", lang=self.config.ocr.pororo.lang)
result = ocr(img_pth)
return result각각의 매개변수 설명을 위해서 타입에 대한 설명을 써주었고 외부에서 보기에는 그냥 결과만 출력하도록 작성하였다.
ocr.py 파일은 api 파일에 비해서 더 큰 범위를 상정하고 제작하였다. ocr의 결과를 받아서 어떤 동작을 하는지(gpt_api, token_counting, file_genenration) 정의하였다. 아래는 ocr.py의 init 코드이다.
class OCR:
def __init__(
self,
config: OmegaConf
) -> None:
# making most upper class OCR it must include config.yaml in your file
self.config = config
self.ocr_api = ocr_api(config)
if config.ocr.api == "pororo":
self.ocr_tool = self.ocr_api.pororo
elif config.ocr.api == "easy":
self.ocr_tool = self.ocr_api.EasyOCR
elif config.ocr.api == "paddle":
self.ocr_tool = self.ocr_api.paddleocr
elif config.ocr.api == "tesseract":
self.ocr_tool = self.ocr_api.tesseract외부에서 현재 이 서비스를 통제하기 위해서는 단지 config.ymal 파일만 수정하면 각각 원하는 동작을 하도록 제작하였다. 현재 github에서는 gpt_api의 key가 들어있기 때문에 생략되어 있는 상태이다.(gitignore 에 포함되어 있어서 추적되지 않음)
run_ocy.py는 실행파일이라 별로 특별한 점이 없다. 모든 동작들이 위에서 언급한 파일들이 정의해주고 있기 때문에 객체를 정의하고 올바른 config 파일을 가져와서 실행하면 원하는 결과가 나온다. 아래는 run_ocr.py의 코드이다.
...생략됨
@hydra.main(version_base=None, config_path="./", config_name="config")
def run_ocr(config) -> None:
# main function
ocr_instance = OCR(config = config) # config 호출
ocr_instance.File_gen()
# run_ocr()
if __name__ == "__main__":
run_ocr()8. 결과 및 분석
위의 코드를 실행하면 아래의 형태로 txt 파일이 하나 출력된다.
(확장자명도 config 파일에 포함되어 있다.)
(결과 텍스트)
ocr result (실행 모듈)
ocr 결과 내용
gpt parsing+correction
gpt api parsing + correction 결과 내용
length: 전체 토큰수
start : 작업 시작 시간
end : 작업 종료시간
duration : 작업에 걸린시간
성능을 결정하는 요인은 총 2가지 정도 된다. 실험을 하는 과정에서는 프롬프트와 이미지 품질이 둘다 영향을 미치지만 사용자 입장에서는 이미지 품질이 가장 중요한 부분이다.
아래는 gpt에게 주는 프롬프트를 바꾸어 가면서 실험한 결과이다.

이미지 품질에 따라서 성능이 결정되는것은 아주 당연한 일이지만 위에서 언급한 2, 3번 이미지 둘다 결과가 그렇게 좋지는 않았다.


하지만 이미지의 품질이 적절하게 이미지의 라벨만 있는 데이터라면 정말 놀라운 성능을 확인할수 있다.
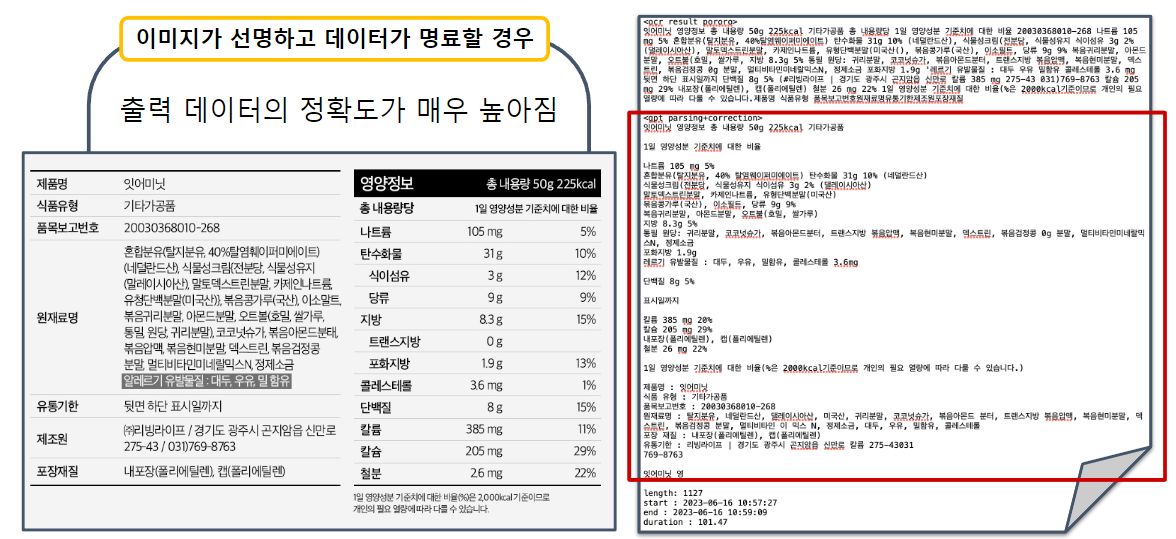
위와 같이 항목별로 분류되어서 정말 쓸만한 텍스트 데이터가 만들어진것을 확인할수 있다.
9. 결론 및 소감
- 구성한 application의 결과로 차후의 프로젝트에서 활용 가능한 문자열을 재구성 할수 있다는 것을 확인할 수 있었다.
- 예외적으로 chat gpt의 성능이 뛰어나 pororo가 아닌 다른 모델을 사용해도 성능이 괜찮은것을 확인할수 있었다(하지만 여전히 ocr 결과에 따라서 최종결과물이 달라짐).
- 다른 프로젝트에서 코드를 재활용할때 개발자들이 이해하기 쉬운 형태로 코드를 작성하는것이 중요하다는 것을 알게 되었다.
- 실제로 코드를 실행시키는 입장에서 config 파일로 상수들을 조절 할 수 있도록 설계하면 차후에 처음 이 코드를 실행하는 사람이 편리하게 사용할 수 있다.
깃허브 주소
