Apache Kafka란?
이 글은 데브원영님의 Kafka 강의를 듣고 정리 및 추가로 공부한 내용을 정리한 글입니다
Apache Kafka란 무엇인가?
실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산 데이터 스트리밍 플랫폼. 링크드인(LinkedIn)에서 개발하여 2011년 오픈소스로 공개.
Kafka 이전
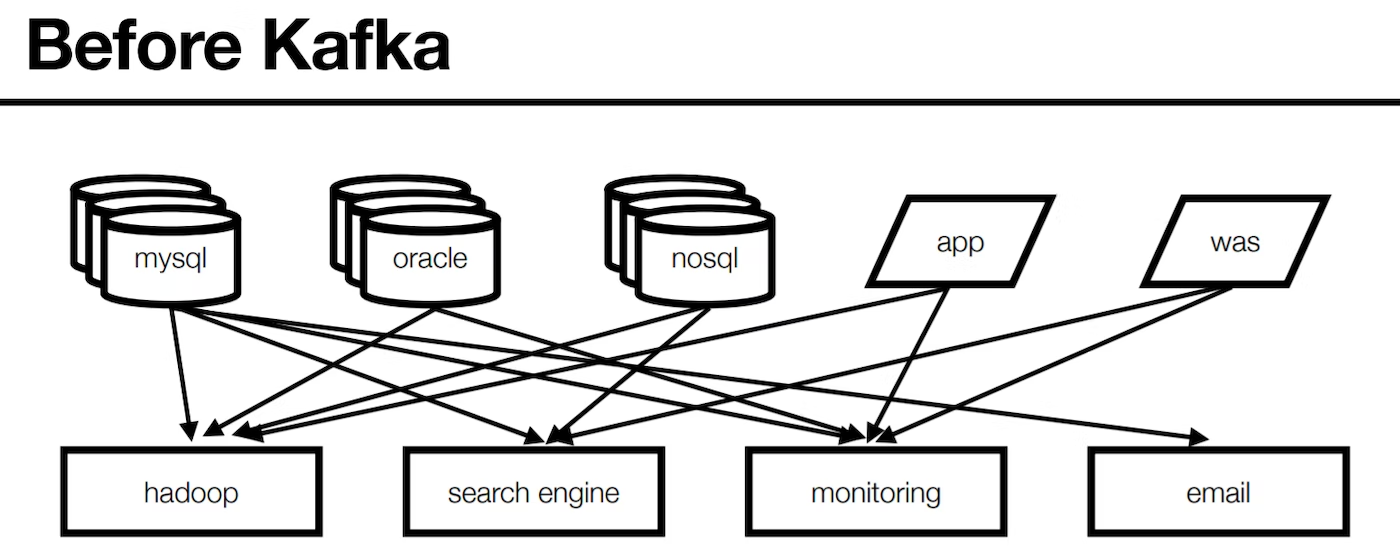
- 서비스간 데이터 전송하는 라인이 복잡해짐
- 배포와 장애 대응이 어려워짐
- 데이터 전송시 프로토콜 파편화가 심해져 유지보수가 어려워짐
Kafka 이후
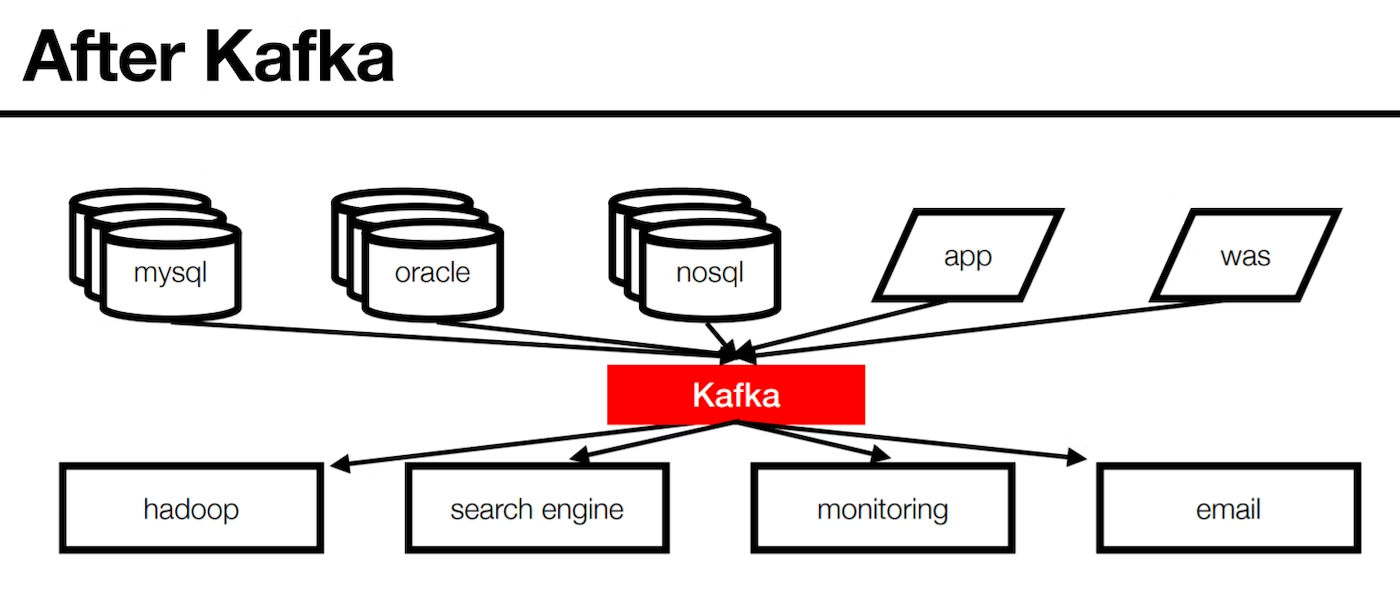
Kafka의 특징
- Pub/Sub 형태로 서비스간 결합도를 약하게 함
- 전송하는 데이터의 포맷은 json, tsv, avro 등 여러 포맷 지원
- 고가용성 및 확장성 제공
- 디스크에 메세지를 저장하여 Consumer가 메세지를 읽어가도 일정 보관 주기동안은 디스크에 저장해둠
- 높은 성능을 유지하기 위해 내부적으로 분산처리, 배치처리 등 다양한 기법 사용
Topic
Kafka에서 데이터가 들어가는 공간. 일반적인 AMQP와는 동작이 다름.
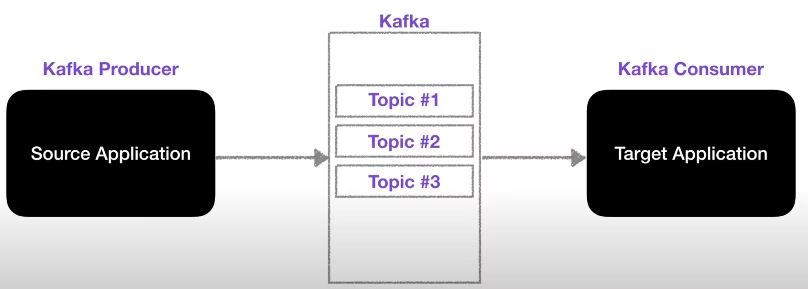
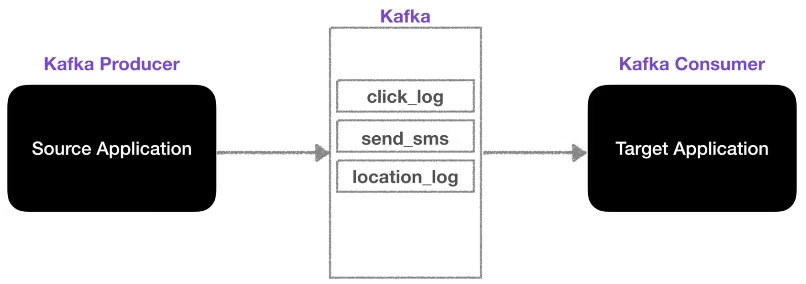
Topic에는 이름을 설정할 수 있어서, 목적에 따라 이름을 붙이면 유지보수가 용이
Partition
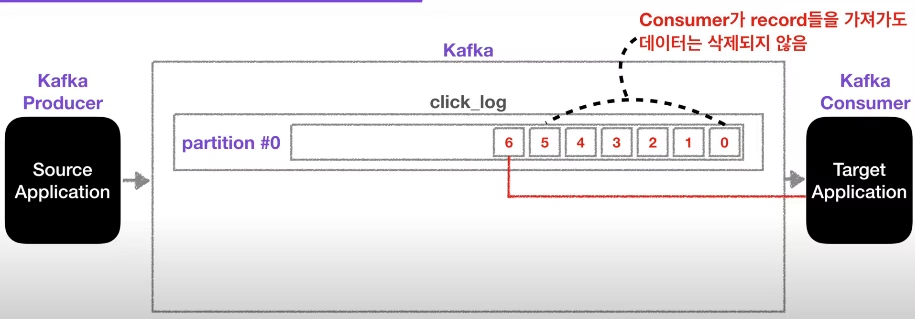
- 하나의 Topic 내부는 여러개의 Partition으로 이루어져 있음
- Partition의 번호는 0번부터 시작
- Partition은 큐와 같이 끝에서부터 데이터가 쌓임
- Consumer는 데이터를 오래된 순서부터 가져감
- 새로운 Consumer가 붙었을때 데이터를 처음부터 가져감
- 단, Consumer group이 다르고 auto.offset.reset=earliest로 설정되어 있는 경우
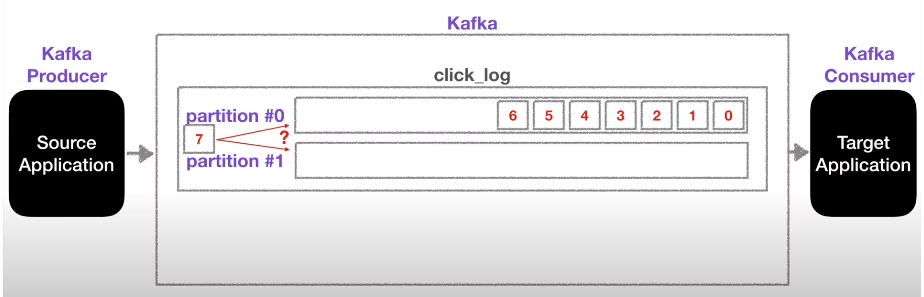
- Partition이 2개 이상인 경우, 다음 데이터는 기본적으로 round-robin으로 partition이 지정
- key를 지정해주고 기본 파티셔너를 지정해줄 경우, key의 해시값을 구하여 특정 partition에 할당
- Partition의 수는 늘릴 수 있지만, 줄일 수는 없음
- Partition내의 record는 옵션에 따라 삭제되는 시기가 다름
- log.retention.time : 최대 record 보존 시간
- log.retention.byte : 최대 record 보존 크기(byte)
Broker, Replication, ISR
Broker
- Kafka가 설치되어 있는 서버 단위
- 일반적으로 3개 이상의 broker로 구성하여 사용하는 것을 권장
Replication

- replication의 수만큼 partition 존재
- broker의 수보다 높을 수 없음
- 원본 partition은 leader partition, 복제본은 follower partition이라고 부름
ISR (In Sync Replica)
- leader partition과 follower partition을 합쳐 ISR이라고 부름
- producer에는 ack라는 옵션이 존재
- 0 : leader에 요청을 전송하고 응답값은 받지 않음. 따라서 요청이 제대로 전송되었는지 데이터가 follower에 제대로 복제되었는지 알 수 없음. 속도는 빠르지만 데이터 유실 가능성 존재.
- 1 : leader에 요청을 전송하고, 정상적으로 받았는지 응답을 받음. 데이터가 follower에 복제가 되었는지는 알 수 없음.
- all : leader에 데이터를 전송하고, follower에 데이터가 잘 복제가 되었는지에 대한 응답을 받음. 데이터 유실이 없지만 속도가 느려짐.
Partitioner
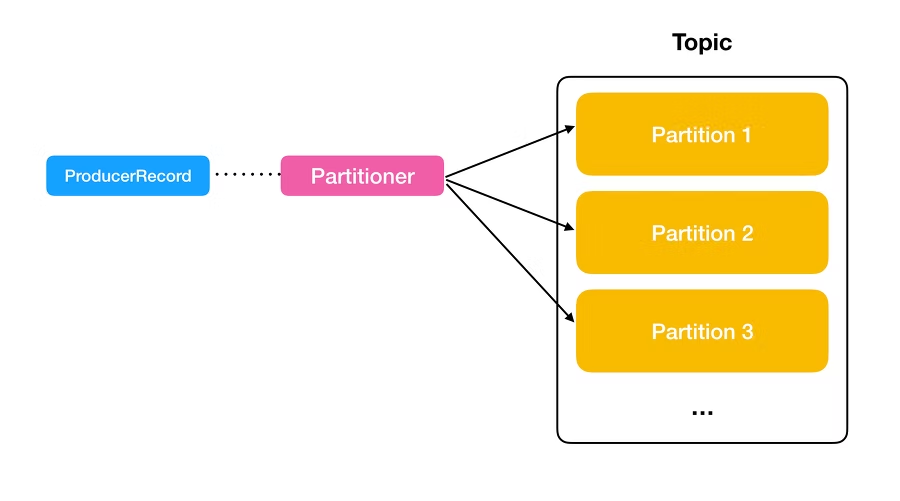
- 데이터를 어떤 파티션에 넣을지 결정하는 역할
- 기본파티셔너는 UniformStickyPartitioner
UniformStickyPartitioner
- key가 있는 경우, 특정한 hash값을 만들고 hash값에 따라 파티션 결정
- 동일한 key를 가진 record는 동일한 hash값이 생성되어 항상 동일한 partition에 들어가는 것을 보장
- 동일한 key를 가지면 record를 순차적으로 처리할 수 있게됨
- key가 없는 경우, round-robin으로 partition 결정
- batch로 모을 수 있는 최대한의 record를 모아서 batch단위로 보냄
Partitioner Interface
- 커스텀 파티셔너를 만들 수 있도록 kafka에서 interface 제공
- 원하는 방식으로 어떤 partitioner로 보낼지 정할 수 있음
Consumer Lag
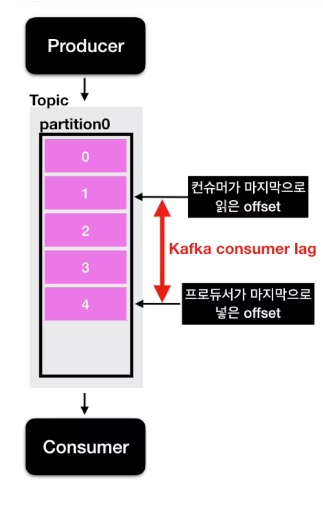
- producer에서 생성한 데이터는 partition에 하나씩 들어가게 되는데, 각 데이터에는 offset이라는 숫자가 붙게 됨
- producer가 생성한 마지막 offset과 consumer가 마지막으로 읽은 offset의 차이가 발생하는데 이를 consumer lag 이라고 함
- partition이 여러개인 경우, lag도 여러개 존재하는데 이 때 가장 높은 lag을 records-lag-max 라고 부름
Kafka Burrow
- Consumer lag을 모니터링 하기 위한 오픈소스
- multi-kafka cluster 지원
- sliding window를 통한 consumer의 status 확인
- http API 제공

back-end developer