개념 이해하기
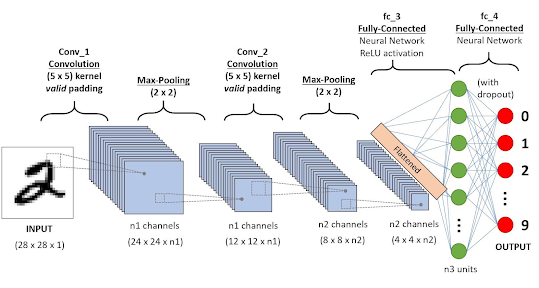
2장에서는 분류하고자 하는 물체가 정확히 사진 중앙에 있는 작은 크기의 흑백 사진만을 대상으로 신경망을 학습시켰는데, 실제 사진의 경우 컬러 사진이 많고 크기가 크며 분류하고자 하는 물체가 사진 중앙에 있지 않은 경우도 있으며 물체가 회전하거나 일부만 보이는 등 매우 다양한 경우가 있어 2장에서 학습시킨 신경망을 그대로 이용하기에는 어려움이 있는데, 이를 해결하기 위해 다음과 같은 방법을 고안하였다.
입력 이미지에 합성곱(convolution) 필터를 적용하여 분류하고자 하는 물체의 특성이 잘 드러나도록 이미지를 변형시킨다면 다양한 상황에서도 물체를 잘 분류할 수 있는 확률이 높아지는데, 이러한 최적의 필터를 학습하는 신경망을 합성곱 신경망(convolutional neural network, CNN)이라고 한다.
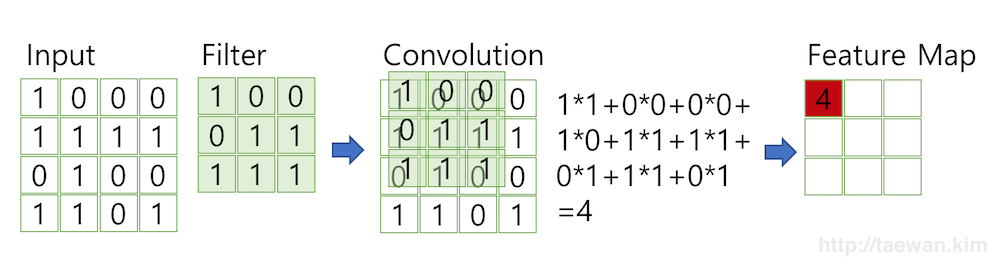
이미지에 합성곱 필터를 적용하는 방법은 아래와 같은데, 이미지의 모든 픽셀에 대해 필터의 크기만큼 주변 영역을 대응시킨 후 이미지와 필터의 같은 위치에 있는 원소를 곱하여 더하게 된다. 즉 이미지와 필터의 아다마르 곱(Hadamard product)의 결과에서 모든 성분의 합을 구하여 목표 픽셀의 값을 업데이트하고, 필터를 한 픽셀씩 옮겨가며 이를 반복하는 것이다. 합성곱을 적용한 뒤 특정 숫자를 모두 동일하게 더해주기도 하는데 이를 편향(bias)이라고 하며, Keras의 필터도 각각의 편향 값을 가지고 이를 학습한다.
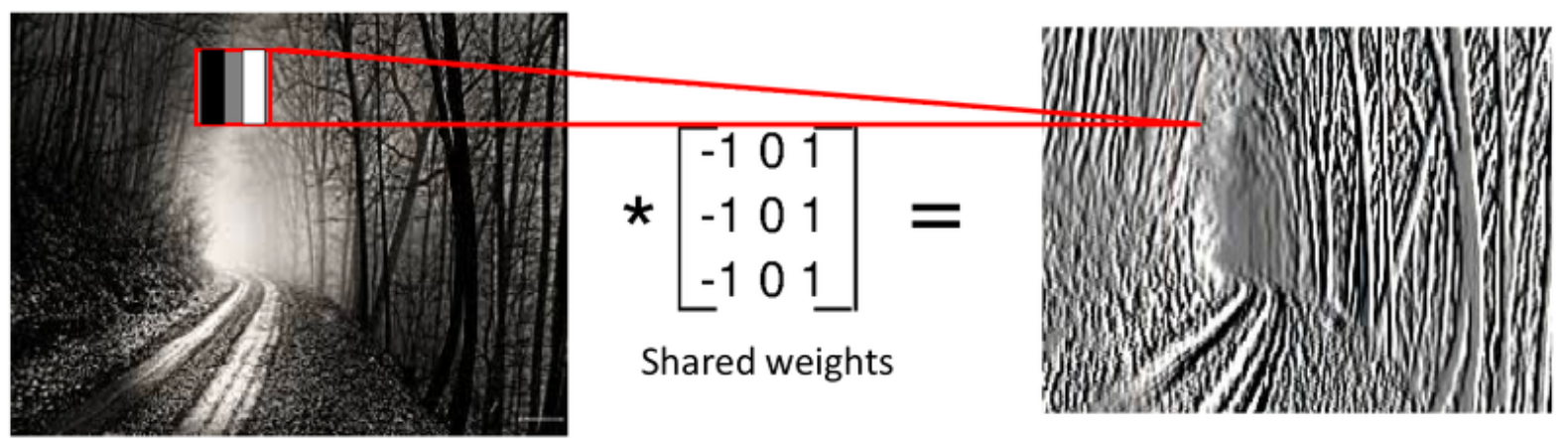
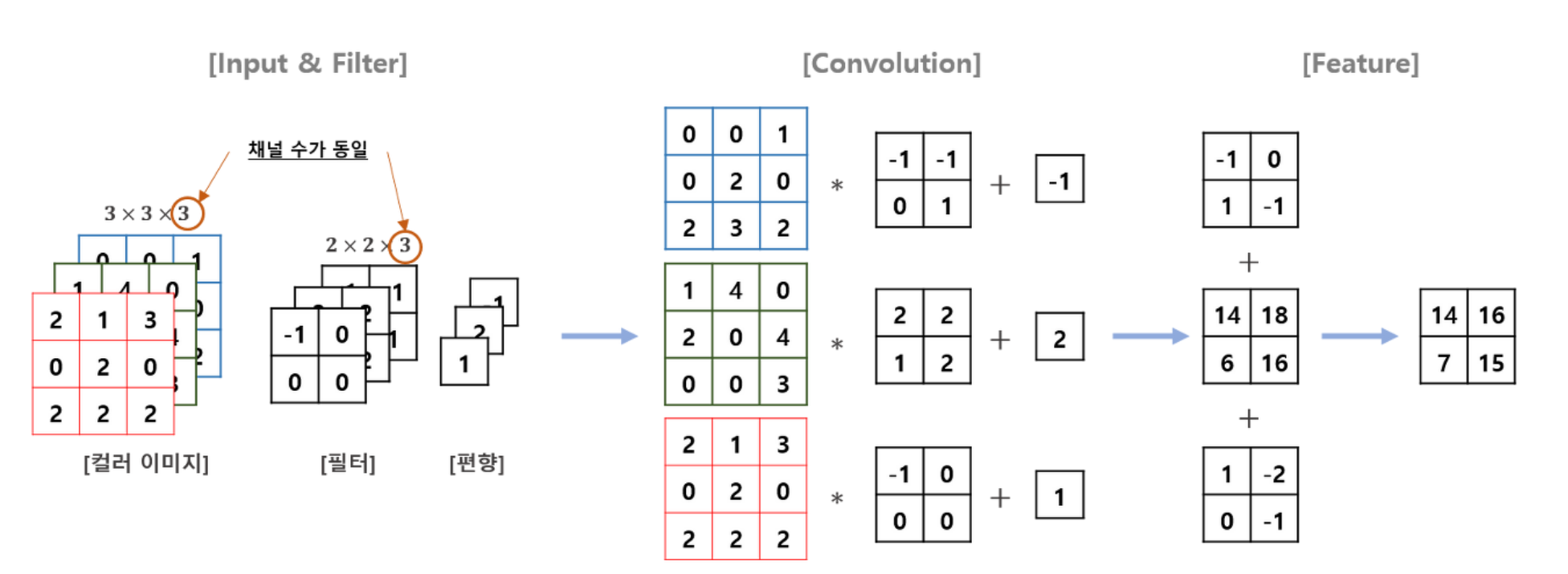
한편, 흑백 사진이 아니라 RGB 컬러 사진이 입력으로 주어졌을 때는 하나의 필터가 각각의 가중치가 다른 3개 채널로 이루어져 있고, 각각의 채널에서 연산한 결과를 합한다는 점이 다르다고 할 수 있다. 즉, 필터가 하나일 때 흑백 사진과 RGB 사진 모두 결과(특성)의 채널은 1개가 된다.
보통은 원본 이미지에 필터를 적용하게 되면, 필터의 크기가 이 아니기 때문에 가장자리의 픽셀을 잃게 되는데, 이러한 문제를 해결하기 위해 원본 이미지와 결과 이미지의 크기가 같도록 입력 이미지의 가장자리에 0을 추가하는 패딩(padding)을 적용하기도 한다.
합성곱 필터를 적용한 다음에는 이미지를 축소하기 위해 풀링(pooling) 작업을 거치게 되는데, 이는 이미지 내의 콘텐츠의 의미를 최대한 보존하며 크기를 줄이는 과정으로, 최대 풀링, 최소 풀링, 평균 풀링 등이 있다.
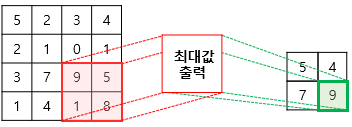
Tensorflow에서는 합성곱 필터와 풀링을 각각
tf.keras.layers.Conv2D()와tf.keras.layers.MaxPooling2D()생성자를 이용하여, 기존 Sequential 클래스에 간단하게 추가할 수 있다.
2장의 신경망에 합성곱 층과 풀링 층을 2개씩 추가한 코드는 아래와 같다.
import tensorflow as tf
data = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = data.load_data()
# Conv2D 층이 컬러 이미지를 위해 설계되어 28*28 배열을 28*28*1의 크기로 변환
training_images = training_images.reshape(60000, 28, 28, 1)
training_images = training_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images = test_images / 255.0
model = tf.keras.models.Sequential([
# 두 개의 합성곱 층과 풀링 층
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# 2장과 동일한 신경망 구조
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(training_images, training_labels, epochs=50)
model.evaluate(test_images, test_labels)위 예제 코드에서 합성곱 층을 생성하는 부분을 parameter의 이름과 함께 살펴보자.
tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3),
activation='relu', input_shape=(28, 28, 1))이때 filter 매개변수는 합성곱에 사용되는 필터의 개수를 의미하고 출력 공간의 깊이를 결정하는 역할을 하게 된다. kernel_size 는 필터의 크기를 나타내며 보통 , , 처럼 홀수를 주로 사용한다. 처음 이미지를 합성곱 층에 넣을 때 하나의 필터만 적용하는 것이 아니라 64개의 필터를 적용하여 64개의 채널(특성)을 만들어낸다는 의미가 될 것이다.
여기서 나는 '왜 합성곱 층과 풀링 층을 한 번이 아니라 굳이 두 번씩 사용하지?'라는 의문을 가지게 되었는데, 여기에서 그 이유를 찾아본 결과 합성곱 층의 개수가 적으면 직선 정도처럼 낮은 차원의 특징만을 강조하게 되므로, 조금 더 고차원적인 특징을 추출하기 위해 합성곱 층을 여러 개 사용한다고 하였다. 합성곱 층과 풀링 층을 적게 사용하거나 많이 사용해도 되는데, 대신 그에 따른 정확도나 계산량에서 차이가 발생할 것이다.
위의 예제 코드를 실행한 결과는 아래와 같은데, 합성곱 층의 추가로 인해 훈련 데이터의 정확도가 크게 향상된 것을 알 수 있고 테스트 정확도의 경우에도 조금 향상된 결과를 가져오게 되었다.

다음으로, model.summary() 메소드를 적용하여 주어진 model의 구조와 학습한 parameter의 개수를 알아볼 수 있다.
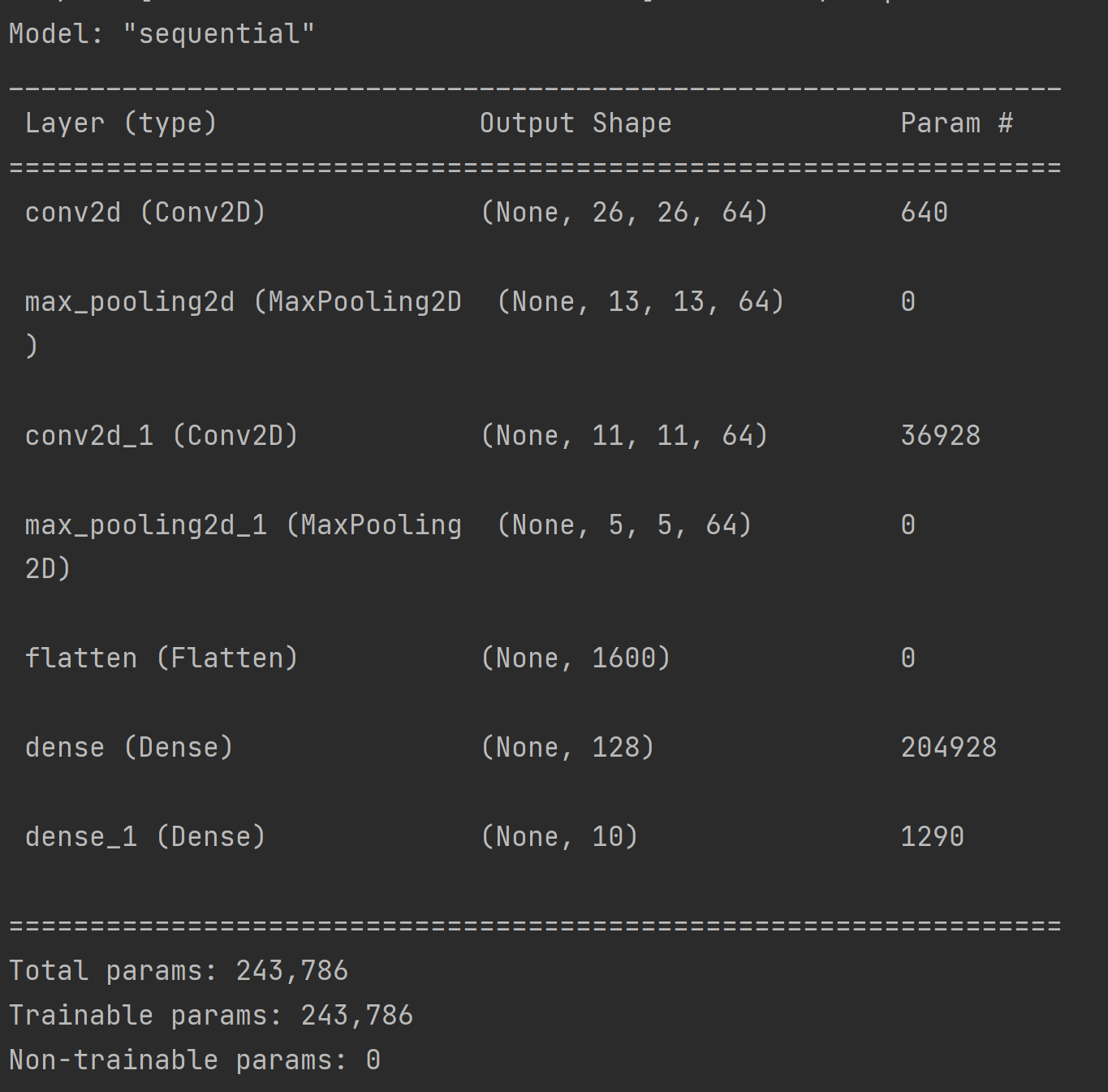
우선 처음 (28, 28, 1) 의 shape로 이루어진 이미지가 첫 합성곱 층의 크기의 64개 필터를 통과하면서 (26, 26, 64) 로 가로, 세로에서 2픽셀만큼의 손실이 발생하고 64개의 채널을 갖는 특성이 추출되었다. 여기서 학습할 parameter는 9개의 값과 편향 1개로 이루어진 필터가 64개 있으므로 640개가 된다.
다음 풀링 층은 추출된 특성의 가로와 세로 값을 절반으로 줄여주는 기능만을 하므로, 출력 shape는 (13, 13, 64)가 되고 학습할 parameter는 없다.
풀링 층을 통과한 64개의 채널을 갖는 특성은 다시 크기의 64개 필터를 통과하게 되는데, 첫 번째 합성곱 층의 필터의 shape가 (3, 3, 1) 이었던 것과 달리 64개의 채널을 가지므로 두 번째 합성곱 층의 필터 1개의 shape는 (3, 3, 64)가 되며, 편향 값 역시 64개의 숫자로 이루어져 있을 것이다. 따라서 이를 통과하였을 때의 shape는 (11, 11, 64) 가 될 것이고, 학습할 paramter의 개수는 9개의 값과 64개 채널이 있는 필터가 64개 있고 각각의 필터에 대해 편향이 1개씩 있으므로, 개의 parameter를 학습하게 된다.
두 번째 풀링 층을 통과한 이후의 과정에서 입출력 데이터의 shape와 parameter의 개수를 구하는 과정은 2장에서 다루었기 때문에 생략한다.
삽질 후기
처음 패션 MNIST 데이터셋에 CNN을 적용하며 model.summary() 메소드로 shape와 parameter 개수를 분석하던 중 아래와 같은 오개념을 가지고 있었음을 깨달았다.
처음에는 '이미지가 개의 필터를 가진 합성곱 층을 통과하면 개의 특징 이미지가 생성된다'라고 생각해서, '두 번째 합성곱 신경망을 통과하면 개의 특징 이미지가 만들어져
conv2d_1 (Conv2D)의 output shape가(None, 11, 11, 4096)이 되어야 하는 것이 아닌지 궁금했는데, 첫 번째 합성곱 층을 통과한 결과를 개의 이미지로 생각하는 것이 아니라 RGB처럼 개의 채널을 가진 하나의 이미지로 생각한다면 위의 내용을 이해하는 데 도움이 될 것 같다!
이 부분이 잘 이해가 되지 않았고 구글링할 키워드도 마땅히 떠오르지 않아 거의 3시간 정도 고민에 빠졌는데, 책에서는 아직 다루지 않은 RGB 이미지에 대한 합성곱 필터 연산을 보고 이를 확장하여 위의 내용을 이해할 수 있었다. 나의 이해가 정확한 것인지 사실 100% 확신은 없어서, 이럴 때면 '주변에 누군가 같이 공부할 사람이 있었으면...' 하는 생각이 들 때가 있다. 그래도 긍정적으로 생각하면, 누군가한테 물어보고 간단히 답변을 받지 않고 혼자 깊게 고민해 보는 것도 좋은 것 같다는 생각도 든다.
그리고 이렇게 입출력 데이터의 shape를 따지고 parameter의 개수를 생각하는 것이 아직 처음 공부하는 나에게는 쉽지 않지만, 그것마저도 사실 Keras에 클래스 하나만 추가해 주면 이런 것들을 생각하지 않아도 신경망을 구성할 수 있을 만큼 편리하게 디자인되어 있다는 것이 놀랍기도 하다!
