1. 데이터 탐색
import plotly.express as px
fig = px.histogram(wine, x='quality')
fig.show()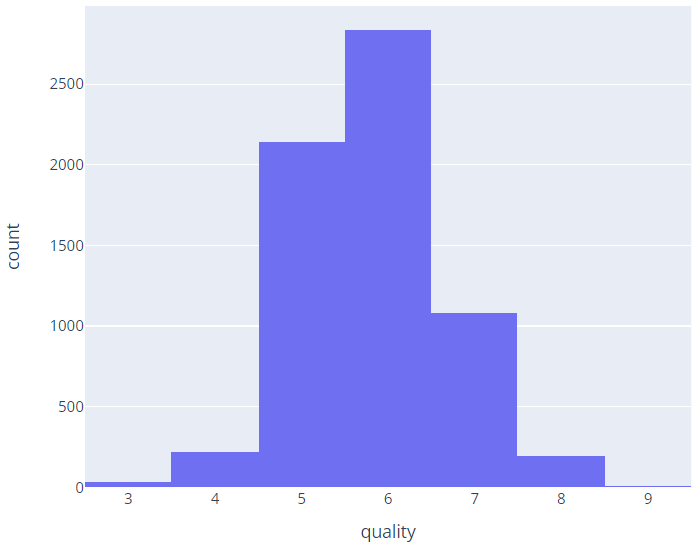
fig = px.histogram(wine, x='quality', color='color')
fig.show()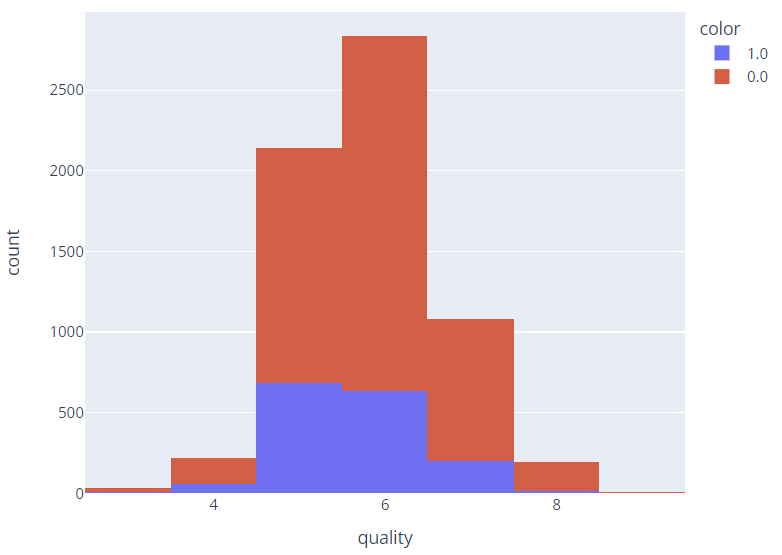
데이터셋 나누기
from sklearn.model_selection import train_test_split
import numpy as np
X = wine.drop(['color'], axis=1)
y = wine['color']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)np.unique(y_train, return_counts=True)
>>>
(array([0., 1.]), array([3913, 1284]))import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Histogram(x=X_train['quality'], name='Train'))
fig.add_trace(go.Histogram(x=X_test['quality'], name='Test'))
fig.update_layout(barmode='overlay')
fig.update_traces(opacity=0.7)
fig.show()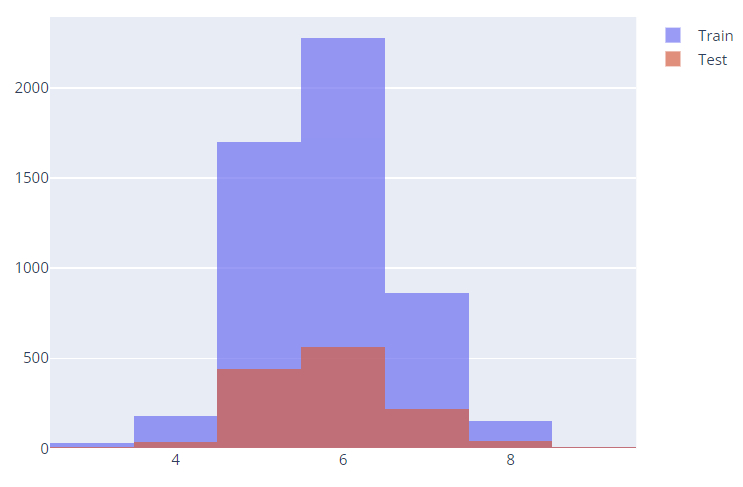
2. Scaler
- 컬럼 간 범위의 격차가 클 때는 모델 학습이 제대로 되지 않을 수 있다.
- 어떤 스케일러가 좋은지는 사용해봐야 알 수 있다.
fig = go.Figure()
fig.add_trace(go.Box(y=X['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X['quality'], name='quality'))
fig.show()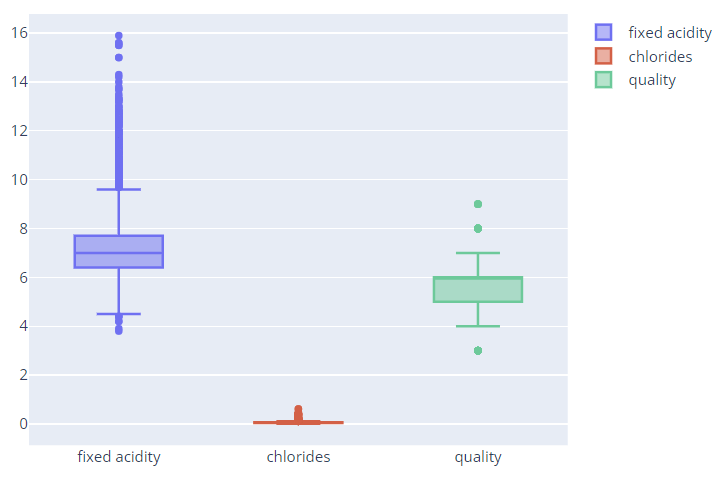
- plotly.graph_objects.Figure
- 시각화 라이브러리는 정말 다양한 것 같다. 비슷해보이지만 분명 장단점이 있을텐데...
3. 모델링 및 평가
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print(accuracy_score(y_train, y_pred_tr))
print(accuracy_score(y_test, y_pred_test))4. 맛의 이진 분류
결정 트리는 레드와인과 화이트와인을 어떻게 구분할까?
from sklearn.tree import plot_tree
plt.figure(figsize=(12, 8))
plot_tree(wine_tree, feature_names=X.columns, class_names=['white', 'red']);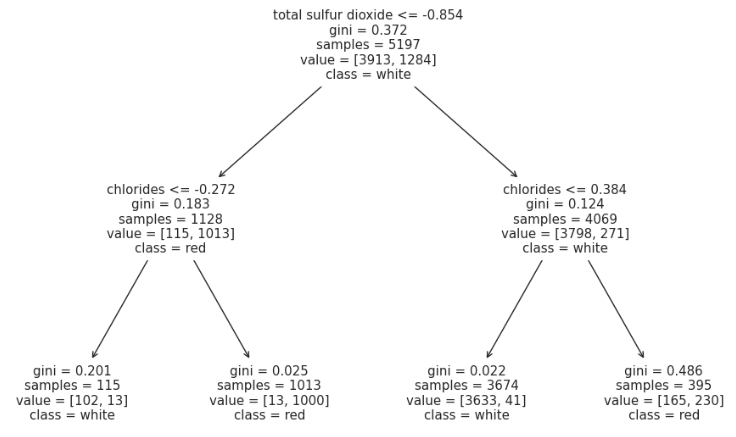
dict(zip(X_train.columns, wine_tree.feature_importances_))
>>>
{'fixed acidity': 0.0,
'volatile acidity': 0.0,
'citric acid': 0.0,
'residual sugar': 0.0,
'chlorides': 0.24230360549660776,
'free sulfur dioxide': 0.0,
'total sulfur dioxide': 0.7576963945033922, # 이산화황
'density': 0.0,
'pH': 0.0,
'sulphates': 0.0,
'alcohol': 0.0,
'quality': 0.0}와인에 이산화황은 방부제 및 향균제로 사용된다. 레드 와인보다는 화이트 와인에 더 많이 들어있는데, 레드 와인에는 탄닌과 껍질에 와인을 보호하는 데 도움이 되는 천연 화합물이 있기 때문이다.
# quality 컬럼 이진화
wine['taste'] = [1. if grade > 5 else 0. for grade in wine['quality']]
# 모델링 및 평가
X = wine.drop(['taste'], axis=1)
y = wine['taste']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print(accuracy_score(y_train, y_pred_tr))
print(accuracy_score(y_test, y_pred_test))
>>>
1.0
1.0100%가 나오면 무조건 의심해봐야 한다.
plt.figure(figsize=(12, 8))
plot_tree(wine_tree, feature_names=X.columns, class_names=['bad', 'good']);
quality 컬럼 값만으로 정확하게 둘로 나뉜다. taste 컬럼을 만들 때 사용한 quality 컬럼을 지우지 않았기 때문에 1.0이 나온 것이다.
taste, quality 컬럼을 제외하면 0.7294593034442948, 0.7161538461538461이 나온다.
plt.figure(figsize=(12, 8))
plot_tree(wine_tree, feature_names=X.columns,class_names=['bad', 'good'],
filled=True, rounded=True);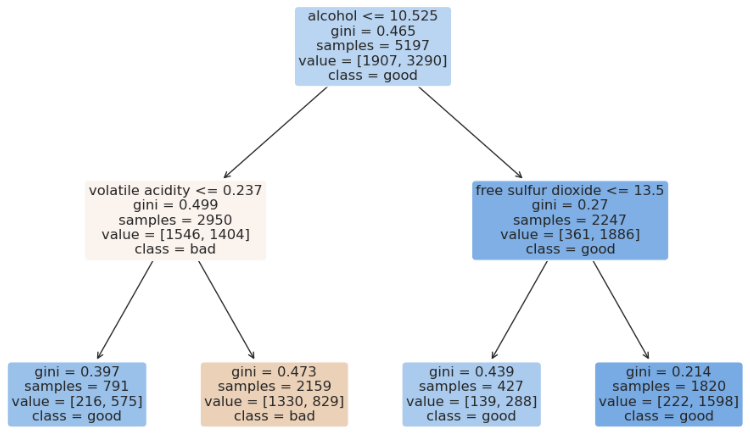
dict(zip(X_train.columns, wine_tree.feature_importances_))
>>>
{'fixed acidity': 0.0,
'volatile acidity': 0.2714166536849971, # 휘발성 산도
'citric acid': 0.0,
'residual sugar': 0.0,
'chlorides': 0.0,
'free sulfur dioxide': 0.057120460609986594, # 유리 이산화황
'total sulfur dioxide': 0.0,
'density': 0.0,
'pH': 0.0,
'sulphates': 0.0,
'alcohol': 0.6714628857050162, # 알코올
'color': 0.0}5. Pipeline
- 데이터의 전처리와 알고리즘의 반복 실행, 하이퍼 파라미터 튜닝 과정을 번갈아 하다보면 코드 실행 순서에 혼돈이 올 수 있디.
- 클래스를 만드는 것도 좋지만, sklearn의 pipeline 기능을 사용해보자.
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)
pipe.fit(X_train, y_train)
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print(accuracy_score(y_train, y_pred_tr))
print(accuracy_score(y_test, y_pred_test))pipe
pipe.steps
>>>
[('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())]# 스케일러
pipe[0]
pipe['scaler']# 파라미터 설정
pipe.set_params(clf__max_depth=2)
pipe.set_params(clf__random_state=13)6. 교차검증
6-1. KFold
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
for train_idx, test_idx in kfold.split(X):
print(len(train_idx), len(test_idx))
>>>
5197 1300
5197 1300
5198 1299
5198 1299
5198 1299KFold는 index를 반환한다.
cv_accuracy = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
np.mean(cv_accuracy)
>>>
0.7095782554627826-2. StratifiedKFold
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
np.mean(cv_accuracy)
>>>
0.6888004974240539정확도가 더 내려갔다. 모델 성능이 예상보다 좋지 않을 수 있다.
6-3. cross_val_score : 교차검증을 간편하게
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)
>>>
array([0.55230769, 0.68846154, 0.71439569, 0.73210162, 0.75673595])매개변수를 바꿔서 결과값을 보고 싶을 때 함수를 이용하면 어느 부분을 바꿨는지 확인하기 쉽다.
def skfold_dt(depth):
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=5, random_state=13)
print(cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold))
skfold_dt(3)
>>>
[0.50076923 0.62615385 0.69745958 0.7582756 0.74903772]6-4. cross_validate : train score 확인하기
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfold, return_train_score=True)
과적합도 관찰된다.
7. 하이퍼파라미터 튜닝
모델의 성능을 확보하기 위해 조절하는 설정값이다.
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth': [2, 4, 7, 10]}
wine_tree = DecisionTreeClassifier(max_depth=5, random_state=13)
# 분류기에 파라미터를 넣어서 5겹 교차검증
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)이때 n_jobs 옵션을 높여주면 CPU의 코어를 병렬로 활용하여 속도가 빨라진다.
가장 좋은 성능을 가진 모델은?
gridsearch.best_estimator_
gridsearch.best_score_
gridsearch.best_params_ # {'max_depth': 2}Pipeline을 적용한 모델에 GridSearch를 적용하고 싶다면?
from multiprocessing import Pipe
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier(random_state=13))]
pipe = Pipeline(estimators)
param_grid = {'clf__max_depth': [2, 4, 7, 10]}
gridsearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
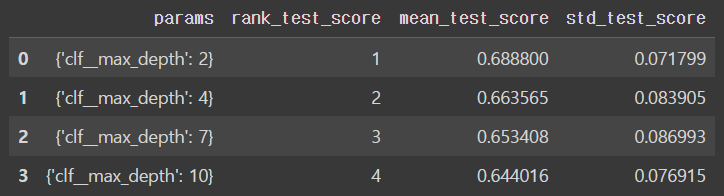
gridsearch.fit(X, y)결과를 데이터프레임으로 정리하기
score_df = pd.DataFrame(gridsearch.cv_results_)
# 다양한 결과값 중에서 필요한 컬럼만 가져오기
score_df[['params', 'rank_test_score', 'mean_test_score', 'std_test_score']]