1. 기본키(primary key)
- 테이블의 각 레코드를 식별하기 위함
- 중복되지 않은 고유값
- NULL❌
- 여러 개의 컬럼으로 지정 가능
1-1. 기본키 설정
# 하나의 컬럼으로 기본키 설정
create table person
(
pid int not null,
name varchar(16),
age int,
sex char,
primary key (pid)
);
# 여러 개의 컬럼으로 기본키 설정
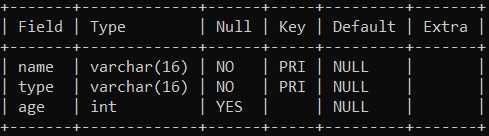
create table animal
(
name varchar(16) not null,
type varchar(16) not null,
age int,
primary key (name, type)
);
1-2. 기본키 삭제
alter table person drop primary key;1-3. 기존 테이블에 기본키 추가
alter table person add primary key (pid);
# constraint 생략 가능
alter table animal add constraint pk_animal primary key (name, type);2. 외래키(foreign key)
- 한 테이블을 다른 테이블과 연결해주는 역할
- 참조되는 테이블의 항목 = 테이블의 기본키 또는 단일값
- 기본키와 다르게 한 테이블에 여러 개 있을 수 있음 (여러 테이블 참조 가능)
2-1. 외래키 설정
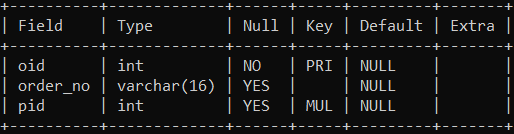
create table orders
(
oid int not null,
order_no varchar(16),
pid int,
primary key (oid),
constraint fk_person foreign key (pid) references person(pid)
);
2-2. constraint 확인
외래키의 경우, constraint 생략하면 자동으로 생성된다.
show create table job;
>>>
PRIMARY KEY (`jid`),
KEY `pid` (`pid`),
CONSTRAINT `job_ibfk_1` FOREIGN KEY (`pid`) REFERENCES `person` (`pid`)2-3. 외래키 삭제
alter table orders drop foreign key fk_person;desc orders;
>>>
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| oid | int | NO | PRI | NULL | |
| order_no | varchar(16) | YES | | NULL | |
| pid | int | YES | MUL | NULL | |
+----------+-------------+------+-----+---------+-------+여전히 MUL 표시가 남아있다.
show create table orders;
>>>
PRIMARY KEY (`oid`),
KEY `fk_person` (`pid`)참조 관계는 깨지고 키만 남아있는 상태라는 걸 알 수 있다.
2-4. 기존 테이블에 외래키 추가
alter table orders add foreign key (pid) references person(pid);
show create table orders;
>>>
PRIMARY KEY (`jid`),
KEY `pid` (`pid`),
CONSTRAINT `job_ibfk_1` FOREIGN KEY (`pid`) REFERENCES `person` (`pid`)2-5. police_station, crime_status 외래키 설정
select count(distinct name) from police_station;
>>>
+----------------------+
| count(distinct name) |
+----------------------+
| 31 |
+----------------------+
select count(distinct police_station) from crime_status;
>>>
+--------------------------------+
| count(distinct police_station) |
+--------------------------------+
| 31 |
+--------------------------------+select distinct name from police_station limit 3;
>>>
+--------------------------+
| name |
+--------------------------+
| 서울중부경찰서 |
| 서울종로경찰서 |
| 서울남대문경찰서 |
+--------------------------+
select distinct police_station from crime_status limit 3;
>>>
+----------------+
| police_station |
+----------------+
| 중부 |
| 종로 |
| 남대문 |
+----------------+각 테이블에서 표시되는 경찰서 이름 형식이 다르다.
select c.police_station, p.name
from crime_status c, police_station p
where p.name like concat('서울', c.police_station, '경찰서')
group by c.police_station, p.name;police_station 컬럼 앞뒤에 '서울', '경찰서'를 붙이면 name 컬럼과 매칭되는지 확인한다. 31개가 모두 매칭되므로 두 테이블의 관계를 설정할 수 있다.
# police_station 기본키 설정
alter table police_station add primary key (name);
# crime_status 테이블에 외래키로 사용할 컬럼 추가
alter table crime_status add column reference varchar(16);
# crime_status 외래키 설정
alter table crime_status add foreign key (reference) references police_station(name);
# reference 컬럼 업데이트
update crime_status c, police_station p
set c.reference = p.name
where p.name like concat('서울', c.police_station, '경찰서');이제 외래키를 기준으로 두 테이블을 연결하여 검색할 수 있다.
select c.police_station, p.address
from crime_status c, police_station p
where c.reference = p.name
group by c.police_station;3. 집계 함수(aggregate functions)
- count : 총 개수
- sum : 합계
- avg : 평균
- min : 가장 작은 값
- max : 가장 큰 값
- first : 첫 번째 결과값
- last : 마지막 결과값
count
select count(*) from police_station;
select count(distinct police_station) from crime_status;sum
# 총 범죄 발생 건수
select sum(case_number) from crime_status
where status_type='발생';
# 총 살인 발생 건수
select sum(case_number) from crime_status
where status_type='발생' and crime_type='살인';
# 중부 경찰서에서 검거한 건수
select sum(case_number) from crime_status
where status_type='검거' and police_station='중부';
# 종로 경찰서와 남대문 경찰서의 강도 발생 건수
select sum(case_number) from crime_status
where police_station in ('종로', '남대문') and crime_type='강도';avg
select avg(case_number) from crime_status
where crime_type = '폭력' and status_type='검거';
select avg(case_number) from crime_status
where police_station = '중부' and status_type='발생';min
# 강도 발생 건수가 가장 적은 경우
select min(case_number) from crime_status
where crime_type='강도' and status_type='발생';max
# 살인이 가장 많이 검거된 수
select max(case_number) from crime_status
where crime_type='살인' and status_type='검거';4. group by & having
그룹화하여 데이터를 조회할 때 집계 함수를 많이 사용한다.
4-1. group by
# 경찰서별로 그룹화하여 경찰서 이름 조회
select police_station
from crime_status
group by police_station
order by police_station
limit 5;
# distinct를 사용하여 조회할 수도 있으나, order by를 사용할 수 없음
select distinct police_station
from crime_status
limit 5;# 경찰서별로 총 범죄 발생 건수 조회
select police_station, sum(case_number) 발생건수
from crime_status
where status_type='발생'
group by police_station
order by 발생건수 desc
limit 5;
>>>
+----------------+--------------+
| police_station | 발생건수 |
+----------------+--------------+
| 송파 | 5410 |
| 관악 | 5261 |
| 영등포 | 5217 |
| 강남 | 4754 |
| 강서 | 4415 |
+----------------+--------------+# 경찰서별 평균 범죄 발생 건수, 평균 범죄 검거 건수
select police_station, status_type, avg(case_number)
-> from crime_status
-> group by police_station, status_type
-> limit 5;
>>>
+----------------+-------------+------------------+
| police_station | status_type | avg(case_number) |
+----------------+-------------+------------------+
| 중부 | 발생 | 411.4000 |
| 중부 | 검거 | 281.2000 |
| 종로 | 발생 | 338.8000 |
| 종로 | 검거 | 235.8000 |
| 남대문 | 발생 | 270.8000 |
+----------------+-------------+------------------+4-2. having
group 단위에 조건을 적용하고 싶을 때 사용한다.
# 경찰서별로 발생한 범죄 건수의 합이 4000건 초과인 경우
select police_station, sum(case_number) count
from crime_status
where status_type='발생'
group by police_station
having count > 4000;# 경찰서별로 발생한 폭력과 절도 범죄 건수 평균이 2000건 이상인 경우
select police_station, avg(case_number)
from crime_status
where status_type='발생' and crime_type in ('폭력', '절도')
group by police_station
having avg(case_number) >= 2000;# 경찰서별로 가장 적게 검거한 건수 중 4보다 큰 경우를 건수가 큰 순으로 정렬
select police_station, min(case_number)
from crime_status
where status_type='검거'
group by police_station
having min(case_number) > 4
order by min(case_number) desc;