목표 : 총 51개 페이지에서 정보 가져오기
(가게 이름, 대표 메뉴, 메뉴 가격, 주소)
3. 시카고 맛집 메인 페이지 분석
3-1. 시작
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com"
url_sub = "/chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
response = urlopen(url)
response
>>>
HTTPError: HTTP Error 403: Forbidden🍳 403 에러 해결 - 방법 1
req = Request(url, headers={"User-Agent": "Chrome"})
response = urlopen(req)
response.status
>>>
200크롬 개발자 도구의 Network 탭에서

맨 밑으로 내려가면
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ..."
페이지에 접속하기 위해 필요한 정보 중 하나이다.(어떤 웹 브라우저로 접속하는지)
"Chrome" 대신에 위의 내용을 적어도 200 OK
🍳 403 에러 해결 - 방법 2
pip install fake-useragentua = UserAgent()
ua.ie
>>>
Error occurred during getting browser: ie, but was suppressed with fallback.
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...결과값이 나오긴 하지만 에러가 떠서 문서를 찾아봤다.
https://pypi.org/project/fake-useragent/
ua.random
>>>
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) ...random 속성을 이용하니 에러가 발생하지 않는다.
req = Request(url, headers={"User-Agent": ua.random})
response = urlopen(req)
response.status
>>>
2003-2. 샘플 테스트 코드 작성
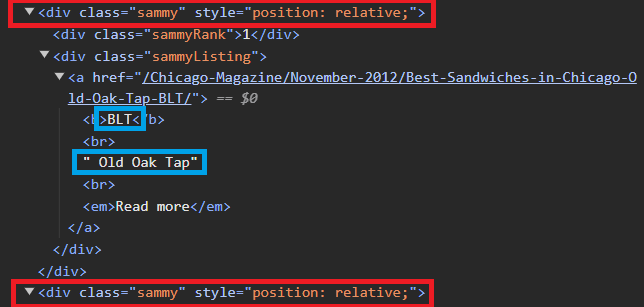
# tmp_one = soup.select(".sammy")[0]
tmp_one = soup.find_all("div", "sammy")[0]
type(tmp_one)
>>>
bs4.element.Tag # 변수에 find, find_all을 또 사용할 수 있음# tmp_one.select_one(".sammyRank").text
tmp_one.find(class_="sammyRank").get_text()
>>>
'1'# tmp_one.select_one(".sammyListing").text
tmp_one.find("div", {"class":"sammyListing"}).get_text()
>>>
'BLT\nOld Oak Tap\nRead more 'import re
tmp_string = tmp_one.find(class_="sammyListing").get_text()
# \n 또는 \r\n 기준으로 나누기
re.split(("\n|\r\n"), tmp_string)
print(re.split(("\n|\r\n"), tmp_string)[0])
print(re.split(("\n|\r\n"), tmp_string)[1])
>>>
BLT
Old Oak Tap# tmp_one.select_one("a").get("href")
tmp_one.find("a")["href"]
>>>
'/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'3-3. 데이터 가져오고 저장하기
from urllib.parse import urljoin
url_base = "https://www.chicagomag.com"
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div", "sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
# urllib.parse 모듈의 urljoin(기준이 되는 URL, 상대 URL) 함수
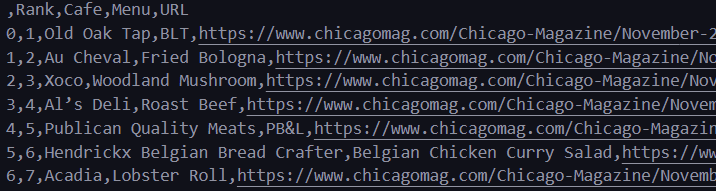
url_add.append(urljoin(url_base, item.find("a")["href"])) # DataFrame 만들기
import pandas as pd
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
# 저장
df.to_csv(
"../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8"
)
4. 시카고 맛집 하위 페이지 분석
정규식(Regular Expression) 맛보기
https://docs.python.org/3/library/re.html
정규식을 사용하여 문장 내에서 일정한 패턴을 가지는 내용을 쉽게 찾을 수 있다.
- .x ➡ 임의의 한 문자를 표현(마지막이 x로 끝남)
- x+ ➡ x가 1번 이상 반복
- x? ➡ x가 존재하거나 존재하지 않음
- x* ➡ x가 0번 이상 반복
- x|y ➡ x 또는 y 찾기
4-1. 샘플 테스트 코드 작성
req = Request(df["URL"][0], headers={"User-Agent": ua.random})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")price_tmp = soup_tmp.find("p", "addy").text
price_tmp
>>>
'\n$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'필요한 부분 = \n$10. 2109 W. Chicago Ave
price_tmp = re.split(".,", price_tmp)[0]
price_tmp
>>>
'\n$10. 2109 W. Chicago Ave'가격 데이터 가져오기
re.search("\$\d+\.(\d+)?", price_tmp).group()
>>>
'$10.'주소 데이터 가져오기
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price_tmp[len(tmp) + 2:]⭐tmp 인덱스 확인(\n은 제외)
price_tmp[1], price_tmp[2], price_tmp[3],
price_tmp[4], price_tmp[5], price_tmp[6]
>>>
('$', '1', '0', '.', ' ', '2')4-2. 데이터 가져오고 저장하기
conda install -c conda-forge tqdmfrom tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req = Request(row["URL"], headers={"User-Agent": ua.random})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2:])
print(idx)df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace=True)
# 저장
df.to_csv("../data/03. best_sandwiches_list_chicago2.csv", sep=",", encoding="utf-8")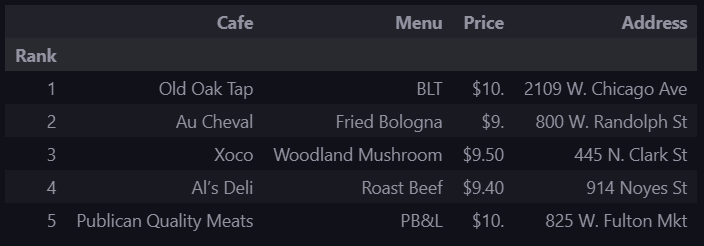
5. 시카고 맛집 데이터 지도 시각화
5-1. 위도, 경도 데이터 가져오기
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdm
gmaps_key = "인증키"
gmaps = googlemaps.Client(key=gmaps_key)lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple location":
target_name = row["Address"] + "," + "Chicago"
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)
df["lat"] = lat
df["lng"] = lng5-2. 맛집 위치 지도 시각화
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(
icon="coffee",
prefix="fa"
)
).add_to(mapping)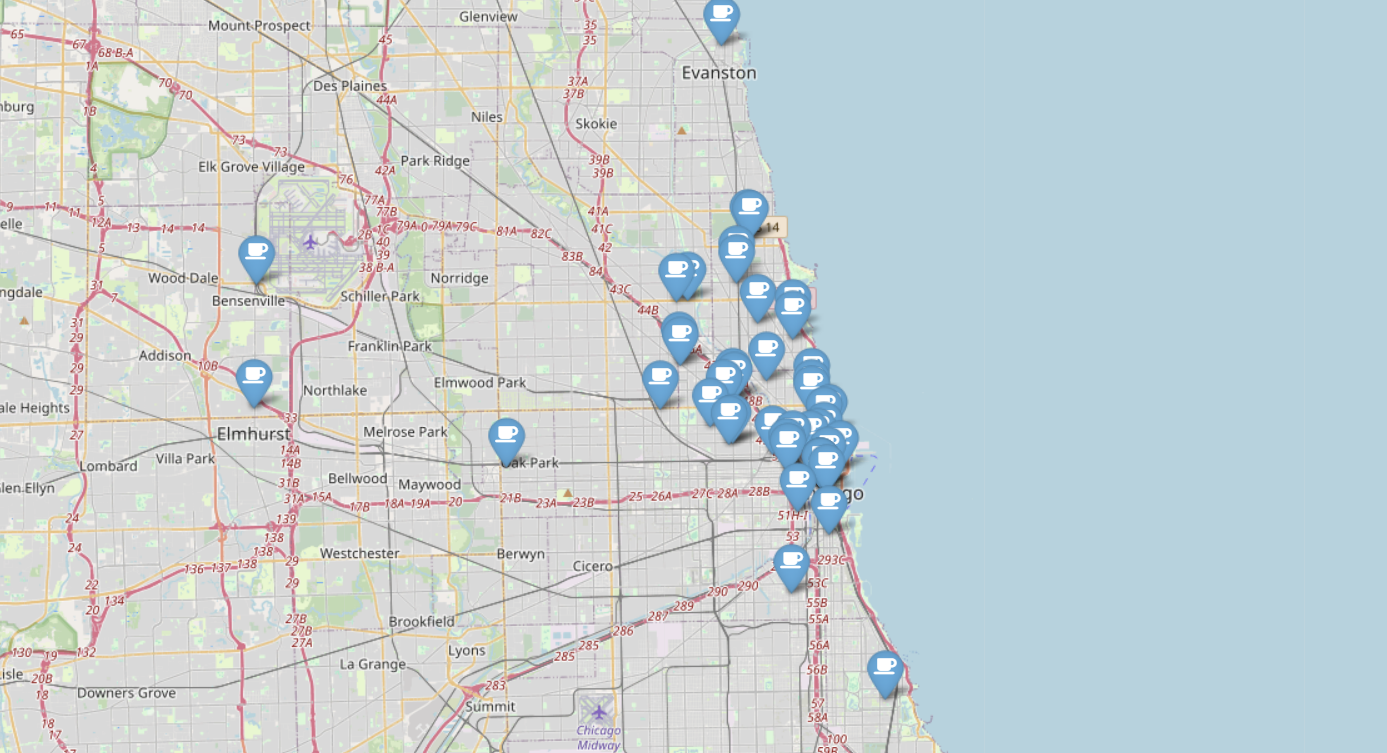
quiz 오답노트
regular expression 에서 000-0000-0000의 패턴을 지정하는 코드는?
1. \d+s-s\d+s-s\d+
2. \w+\s-\s\w+\s-\s\w+
3. \d+-\d+-\d+ ➡ 내가 고른 답
4. \d+\s-\s\d+\s-\s\d+ ➡ 정답
🚗🚗🚗
