MapReduce 개요
- MapReduce의 기본 컨셉은 데이터에서 원하는 정보만을 가져와 병렬처리 하는 것
- Mapper : 데이터에서 원하는 정보만을 key-value형식으로 mapping
- Reducer : key-value를 토대로 요구된 집계를 병렬적으로 수행
- MapReduce 과정에서 failure를 처리하는 메커니즘도 제공
MapReduce의 동작
Single node
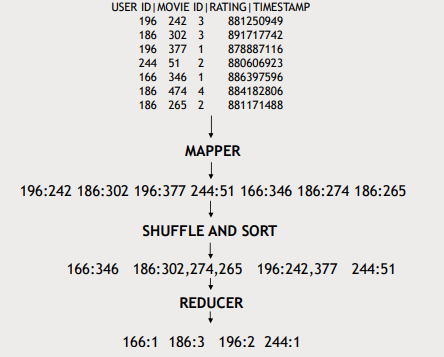
- Mapping : 데이터에서 원하는 정보를 key-value 형태로 추출
- Shffle and sort : key-value들을 key값 기준으로 정렬하고 같은 key값을 가지는 것들을 grouping
- Reducer : 각 key의 value에 대해 함수 적용(위의 예에서는 len(), reducer가 받는 key는 unique → grouping했으니까)
Multiple nodes
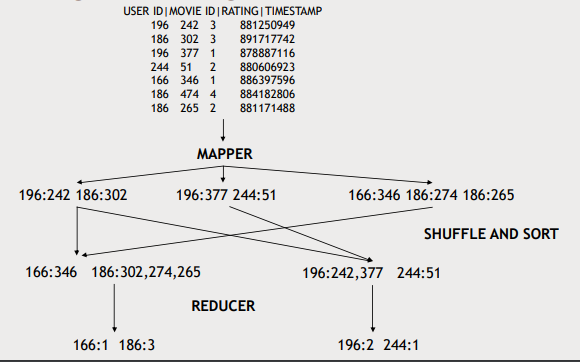
1. data 를 여러 partition로 나눠서 mapper들에게 나눠 전달
2. mapper들로 data를 key-value쌍으로 변환하는 작업을 병렬적으로 수행
3. Shffle and sort : mapping 결과로 나온 key-value쌍들을 key값을 기준으로 merge sort해서 grouping
4. Reducer들로 aggregate을 병렬처리하여 결과를 뽑아냄(key가 unique해서 병렬처리 해도 됨)
Anatomy of MapReduce
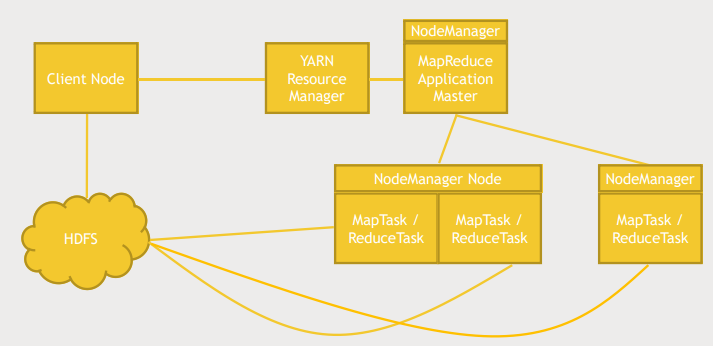
- YARN에게 MapReduce job을 실행할 것을 알림, 동시에 HDFS에 필요한 데이터를 복사
- YARN : 클러스터의 어떤 머신이 가용하고 어떤 머신의 성능은 얼마인지 등의 정보를 가지고 어떤 머신에서 무엇을 실행할지 관리
- MapReduce Application Master 동작
- 각각의 Map, Reduce task에 대해 감시함
- resource manager와 협업해 일을 클러스터에 분배함
- MapReduce 일을하는 모든 노드들은 node manager에 의해 추적됨
- node manager : 노드 관리자는 어떤 노드가 무얼 하고 있고 사용 가능한지, 작업 중인지 등을 추적함
- resource manager는 data와 가능한 가까운 mapper, reducer에게 해당 작업을 할당함
- 왠만하면 그 데이터를 가지고 있는 머신에게 작업을 할당
- 불가능하다면 네트워크상으로 가장 가까운 머신에 할당
MapReduce STREAMING
- MapReduce is natively java
- STREAMING을 이용하면 java를 이용해 mapping,reducing 함수를 작성하는 대신 다른 언어로 작성하여 stdin/stdout 방식으로 소통할 수 있다.
Handling failure
- Application master가 worker task가 잘 작동하는지 감시
- 만약 에러가 발생하면 재실행하거나 다른 노드에서 실행할 수 있음
- Application master가 down되면
- YARN이 Application master를 재실행
- YARN : Watcher who's watching the watchers.zz
- resource manager가 down되면?
- 잘 일어나지 않는 상황이지만 아래와 같은 대응전략을 고려해볼 수 있음
- 이런일은 잘 일어나지 않지만 zookeeper를 이용해 hot standby resource manager를 유지
- 기존의 것이 down되면 zookeeper는 mapreduce 작업을 standby resource manager에게 redirect
MapReduce 기타
- 위에서 설명한 것 외에도 MapReduce를 구성요소가 존재(counter, combiner...)
- 이러한 것들은 필요할때 알아보면됨
- MapReduce는 아직까지도 기초가 되는 부분이여서 이해하고 넘어가는 것이 좋긴하다.
- 요즘은 다른 기술들이 더 각광받고 있음 Spark, SQL style queries(hive...)
mrjob 실습
from mrjob.job import MRJob
from mrjob.step import MRStep
class RatingsBreakdown(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper_get_ratings,
reducer=self.reducer_count_ratings)
]
def mapper_get_ratings(self, _, line):
(userID, movieID, rating, timestamp) = line.split('\t')
yield rating, 1
def reducer_count_ratings(self, key, values):
yield key, sum(values)
if __name__='__main__':
RatingsBreakdown.run()-
yeild: MapReduce에게 반환하는 값 -
mrjob
- Run locally
- 실제 데이터 부분집합을 들고와서 테스트겸 실행
python RatingsBreakdown.py u.item
- 실제 데이터 부분집합을 들고와서 테스트겸 실행
- Run with Hadoop
- Run locally
python MostPopularMovie.py
-r hadoop
--hadoop-streaming-jar {hadoop-streaming.jar 위치}
{data 위치}-r hadoop : mrjob에게 실제 hadoop cluster에서 실행할거라고 알려줌
--hadoop-streaming-jar : hortworks에서는 hadoop streaming을 어디서 찾아야하는 지 모름. Amazon ECT, Elastic MapReduce 서비스 같은 플랫폼에는 알아서 찾아줌
{data 위치} : 대용량 데이터를 로컬에 저장하지는 않을거임. 보통 HDFS://URL 와 같이 HDFS 내 데이터의 경로를 특정
