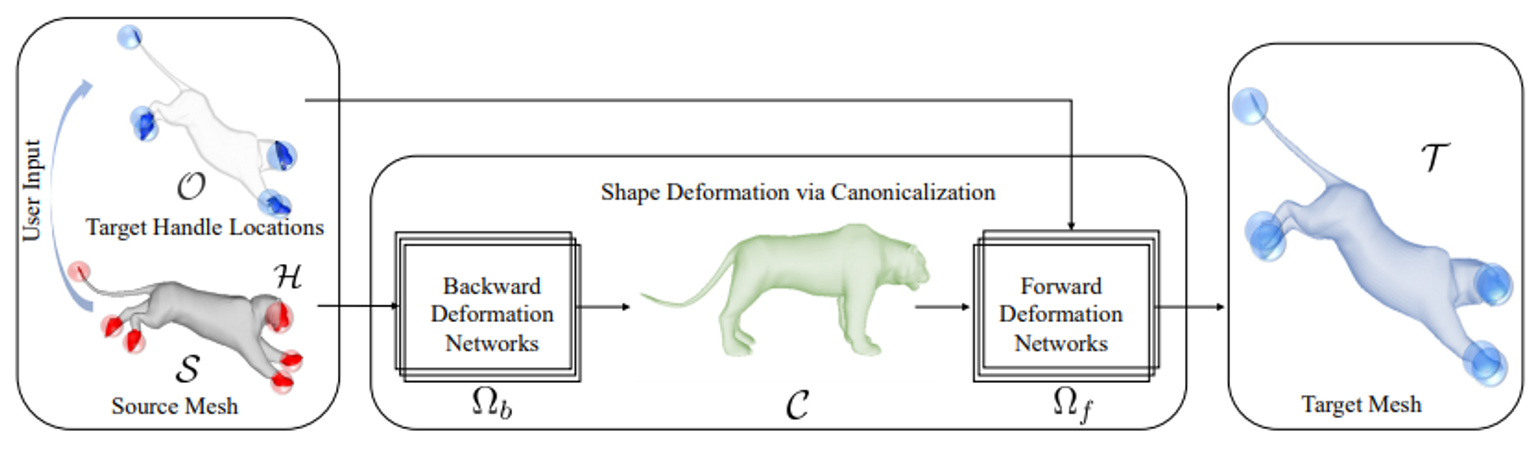
동기: 기존의 ARAP 등의 deformation 방식은 triangle 구조에는 dependent 하지만 global한 prior 정보는 이용하지 못한다. (Global한 prior 정보의 예로는 머리와 발은 움직이는 방식이 다르다는 것) 딥러닝을 통해 prior를 활용할 수 없을까?
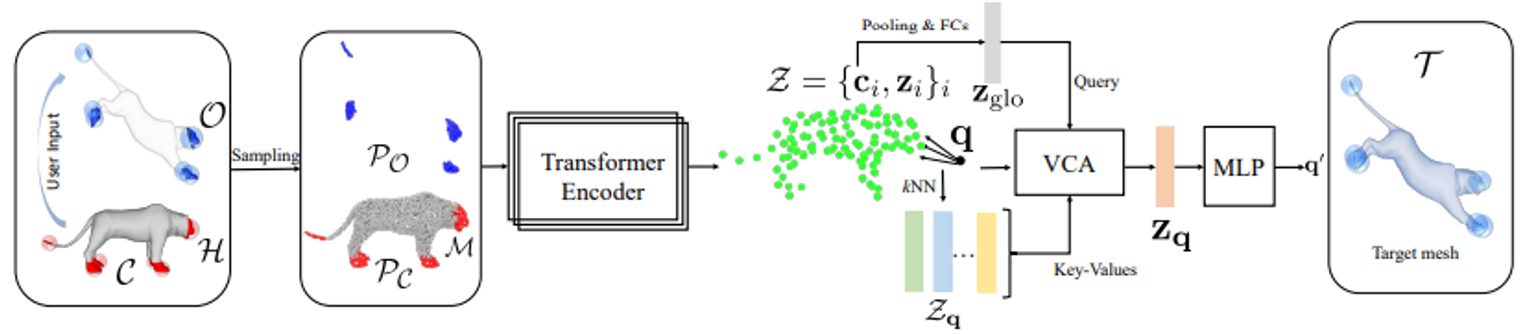
요약: 먼저, source mesh를 backward deformation network를 통해 canoncialize한다. 그 후 handle constraint에 대한 정보를 forward deformation network에 넣어 target mesh를 만든다. Canonicalize 하는 이유는 각 deformation network의 입력 또는 출력의 형태를 제한하여서 learning complexity를 낮추기 위함이다. 내부적으로는 point transformer를 이용한다.
입력은 source mesh 과 sparse handle 과 handle의 목표지점 (어느 point가 어디로 가야한다는 constraint 얘기)이다. 이를 통해 를 target mesh 로 deform하고 싶다. 입력에 대해 deformation field 를 얻으면 deform된 mesh 는 이다.
입력 에 대해서 point cloud를 샘플하여 를 만든다. Backward deformation field (임의의 포즈에서 canonical 포즈로 deform하는 field)를 approximate하는 을 이용해서 를 로 deform한다. Canonical 포즈에서 를 이용하여 를 로 deform하는 forward deformation field 를 approximate 하는 를 학습한다. 딥러닝 모델 구조는 point transformer를 사용하니 스킵.
Loss는
단순히 deform된 point와 target point와의 차이이다. 여기서, Query point set이라는 걸 이용하는데 의 공간에서 표면 위에 위치하지 않은 점들 중 개를 random하게 sample한 것이다. 이를 라고한다. , 에 대해서도 loss를 계산하는데 deform이 공간 상에서 regular 할 수 있게 만드는 역할로 추측된다.
한계: 실험에 사용한 dataset은 canonical pose가 있지만 없는 경우가 많지 않을까? 그리고 surface 위의 correspondence는 얻을 수 있다고 치지만 query point set의 correspondence는 어떻게 얻는가?
