⭐ DL 쌩으로 이해해보기
import numpy as np
X = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
])
def sigmoid(x): #0~1 사이 출력을 가지는 함수
return 1.0 / (1.0 + np.exp(-x))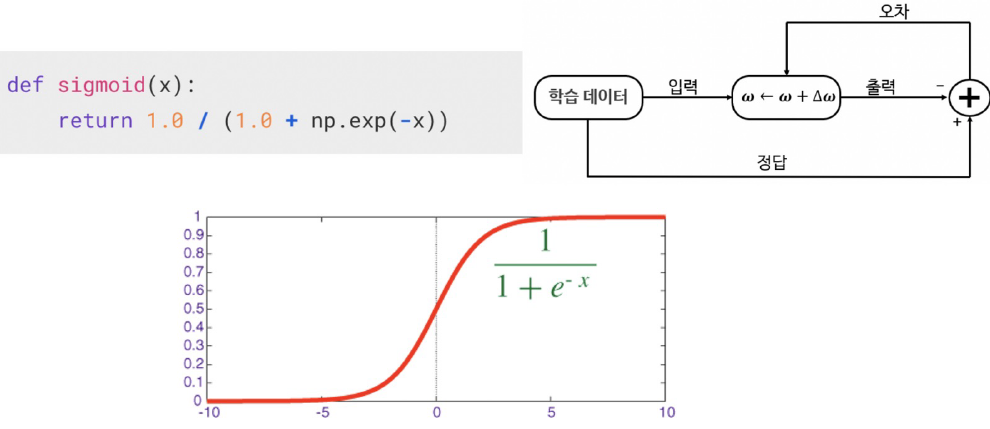
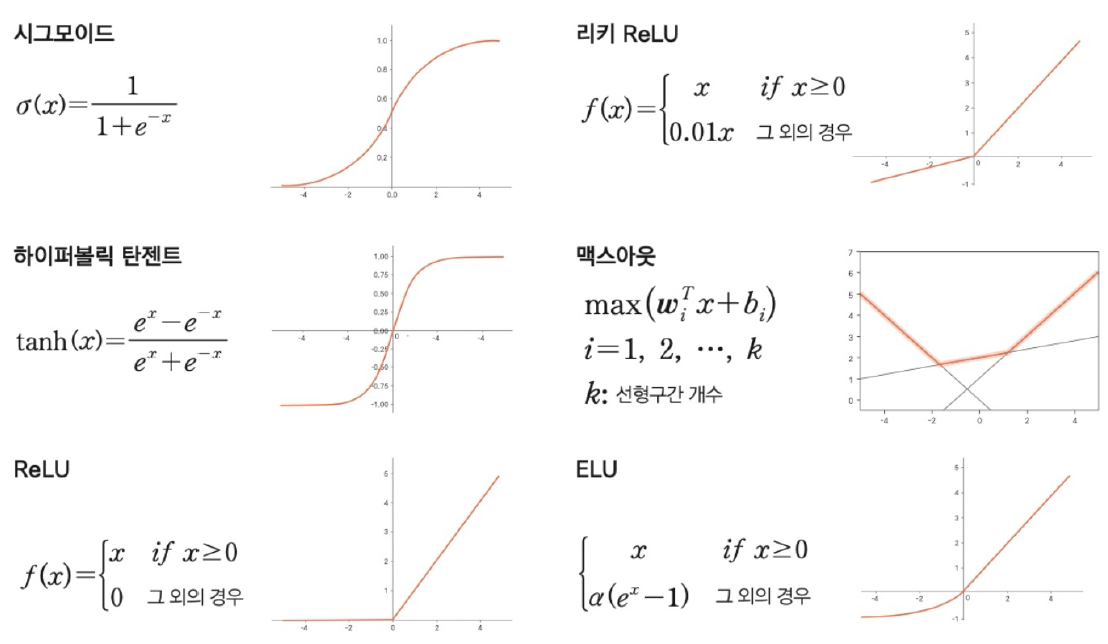
⭐활성화 함수의 종류
가중치를 랜덤하게 선택. 원래는 학습이 완료된 가중치를 사용해야 된다.
W = 2*np.random.random((1,3)) - 1
Warray([[-0.45495649, -0.25031492, -0.76646462]])추론결과
np.matmul(W,X[0]) #[0,0,1]에 array([[-0.45495649, -0.25031492, -0.76646462]]) 곱한 값array([-0.76646462])n=4
for k in range(n):
x = X[k, :].T
v = np.matmul(W,x)
y = sigmoid(v)
print(v)[-4.57503618]
[-4.78417554]
[4.99063899]
[4.78149962]⬆
X array
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
에 각각 [-0.45495649, -0.25031492, -0.76646462]] 곱한 값의 결과
가중치가 이제 정답을 맞추도록 학습시키기 --> 정답을 알려주는 지도학습
D = np.array([
[0],[0],[1],[1]
])def calc_output(W,x):
v = np.matmul(W,x)
y = sigmoid(v)
return y딥러닝 간단 절차 -->가중치 갱신
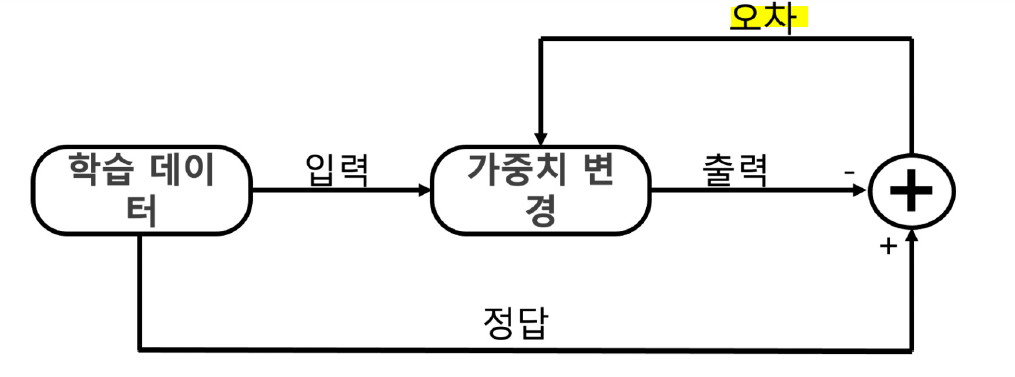
def calc_error(d,y): #d: 정답 y:추론값
e = d-y #d-y :오차
delta = y*(1-y) * e #에러와 활성화함수의 미분값
return delta
# 한 epoch에 수행되는 W 계산
def delta_GD(W,X,D,alpha):
for k in range(4): # 4개 데이터를 for문으로 다 돌림
x = X[k,:].T
d=D[k]
y = calc_output(W,x)
delta = calc_error(d,y)
dW = alpha*delta*x #alpha : 학습률
W = W+dW
return W
가중치를 랜덤하게 초기화하고 학습 시작.
W =2*np.random.random((1,3))-1
alpha = 0.9
for epoch in range(10000):
W = delta_GD(W,X,D,alpha)
print(W)N=4
for k in range(N):
x = X[k, :].T
v = np.matmul(W,x)
y = sigmoid(v)
print(y)[0.0102008]
[0.00829169]
[0.99324463]
[0.99168628]0.5 이상을 1, 0.5 이하를 0 이라고 본다면 위의 결과 [0,0,1,1]
Warray([[ 9.56567516, -0.20913937, -4.57503618]])Xarray([[0, 0, 1],
[0, 1, 1],
[1, 0, 1],
[1, 1, 1]])Darray([[0],
[0],
[1],
[1]])XOR
# XOR 데이터 다시
X = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
])
D = np.array([
[0],[1],[1],[0]
])
W = 2*np.random.random((1,3)) - 1# 학습
alpha = 0.9
for epoch in range(1000):
W = delta_GD(W,X,D,alpha)# 출력 확인
n=4
for k in range(n):
x = X[k, :].T
v = np.matmul(W,x)
y = sigmoid(v)
print(y)[0.52965337]
[0.5]
[0.47034663]
[0.44090112][0,1,1,0] 결과가 나와야하는데 결과가 좋지 않음
🔹 역전파 Backpropagation
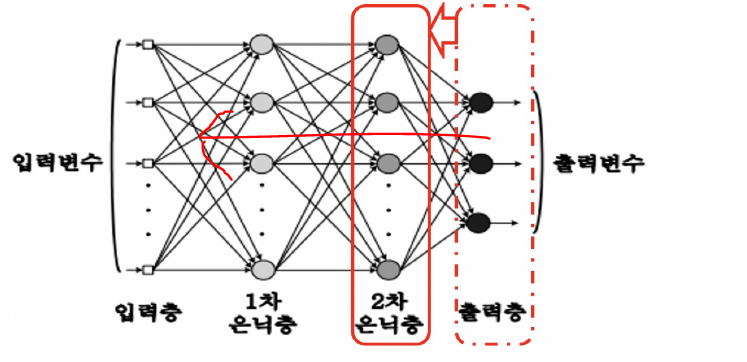
Output 계산 함수
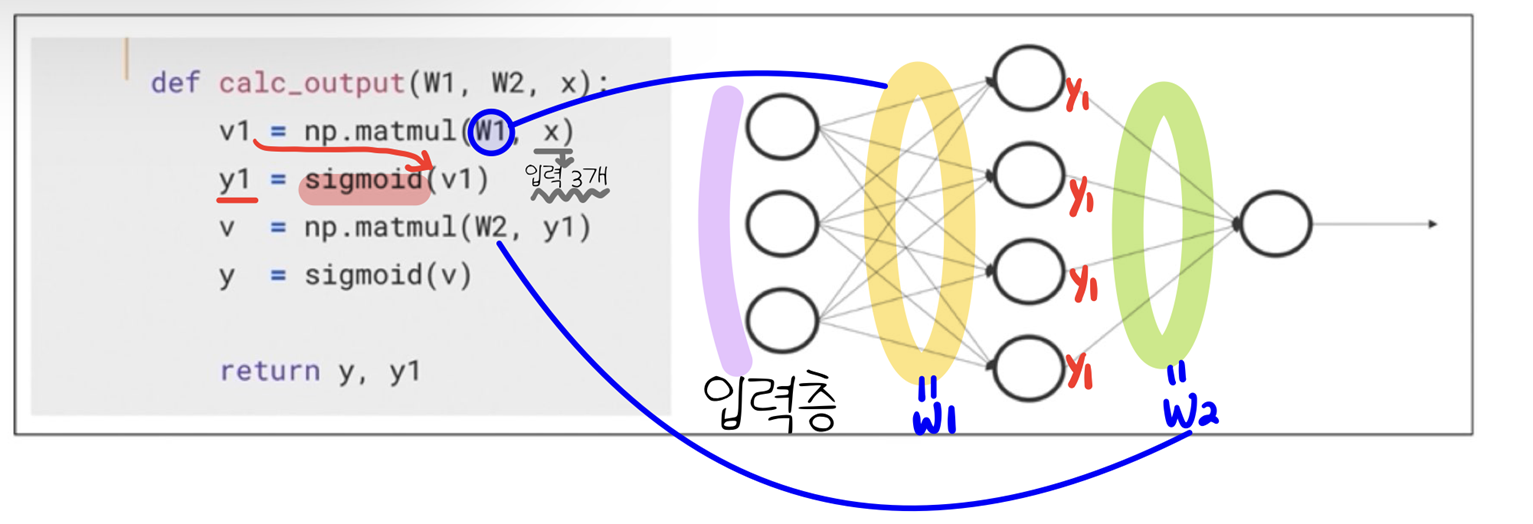
def calc_output(W1,W2,x):
v1 = np.matmul(W1,x)
y1 = sigmoid(v1)
v = np.matmul(W2,y1)
y = sigmoid(v)
return y,y1출력층 delta 계산
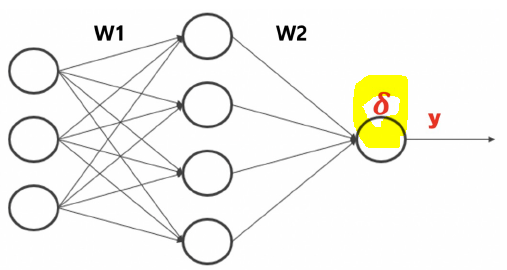
def calc_delta(d,y):
e = d-y
delta = y*(1 - y) * e
return delta은닉층 delta 계산
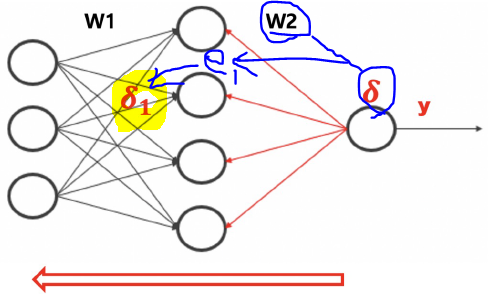
def calc_delta1(W2,delta,y1):
e1 = np.matmul(W2.T, delta)
delta1 = y1 * (1-y1) * e1
return delta1역전파 코드
def backprop_XOR(W1, W2, X, D, alpha):
for k in range(4):
x = X[k, :].T
d = D[k]
y, y1 = calc_output(W1, W2, x)
delta = calc_delta(d,y)
delta1 = calc_delta1(W2,delta, y1)
#가중치 업데이트
dW1 = (alpha * delta1).reshape(4, 1) * x.reshape(1, 3)
W1 = W1 +dW1
dW2 = alpha * delta * y1
W2 = W2 +dW2
return W1, W2,X = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
])
D= np.array([
[0],[1],[1],[0]
])W1 = 2 * np.random.random((4,3)) - 1 #(4,3)크기인 이유 : 출력층 델타 계산 시 3 -> 4
W2 = 2 * np.random.random((1,4)) - 1alpha =0.9
for epoch in range(1000):
W1, W2 = backprop_XOR(W1, W2 ,X, D, alpha)N = 4
for k in range(N):
x = X[k,:].T
v1 = np.matmul(W1,x)
y1 = sigmoid(v1)
v = np.matmul(W2,y1)
y = sigmoid(v)
print(y)[0.04690893]
[0.94945619]
[0.94943076]
[0.05037732]전에 비해 개선된 결과로 [0,1,1,0] 확인
🤔오차를 어떻게 뒤로 전달한다는 건가?
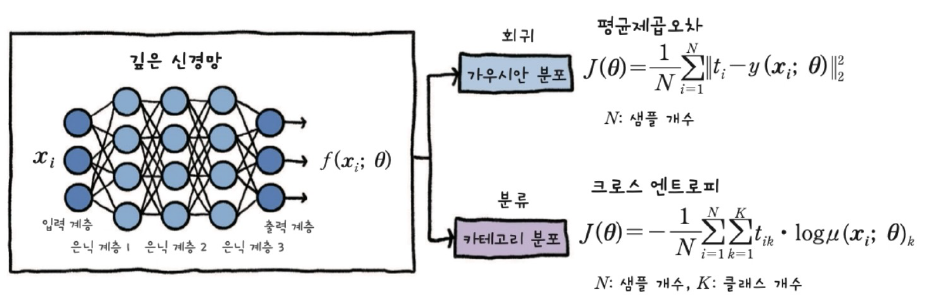
🔹 Cross_entropy
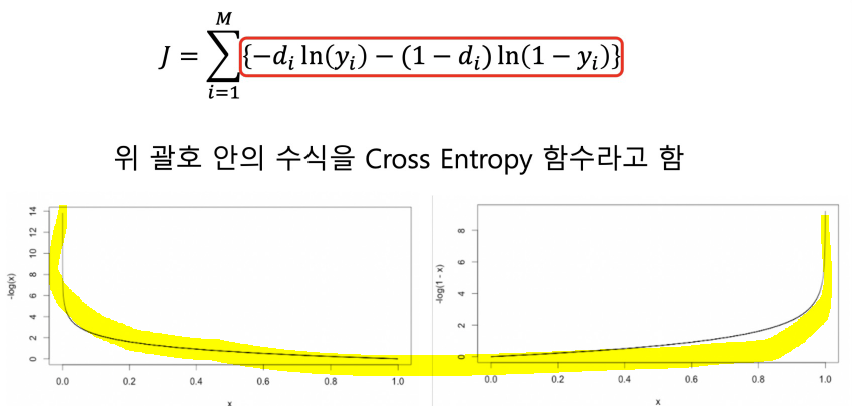
델타를 구할때 cross_entropy 사용하면, 델타는 오차와 같다.
def calcDelta_ce(d, y):
e = d - y
delta = e
return e# 은닉층
def calcDelta1_ce(W2,delta,y1):
e1 = np.matmul(W2.T, delta)
delta1 = y1*(1-y1)*e1
return delta1def backpropCE(W1, W2, X, D, alpha):
for k in range(4):
x = X[k, :].T
d = D[k]
y, y1 = calc_output(W1, W2, x)
delta = calcDelta_ce(d,y)
delta1 = calcDelta1_ce(W2,delta, y1)
#가중치 업데이트
dW1 = (alpha * delta1).reshape(4, 1) * x.reshape(1, 3)
W1 = W1 +dW1
dW2 = alpha * delta * y1
W2 = W2 +dW2
return W1, W2W1 = 2 * np.random.random((4,3)) - 1
W2 = 2 * np.random.random((1,4)) - 1
alpha =0.9
for epoch in range(10000):
W1, W2 = backpropCE(W1, W2 ,X, D, alpha=0.9)N = 4
for k in range(N):
x = X[k,:].T
v1 = np.matmul(W1,x)
y1 = sigmoid(v1)
v = np.matmul(W2,y1)
y = sigmoid(v)
print(y)[0.00010316]
[0.99988224]
[0.99991593]
[0.00023606]💡활성화 함수 하나의 차이로도 결과가 상당히 개선됨

데이터분석 스터디노트🧐✍️