[논문리뷰]A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios(ACL Anthology, Jun 2021)
NLP
Paper: https://aclanthology.org/2021.naacl-main.201/
0. Abstract
Deep neural network, 그리고 huge language model은 점점 NLP 분야를 지배하고 있습니다.
하지만, 대부분의 모델이 많은 양의 데이터를 필요로 하는 문제가 있었으며, 이에 따라 필연적으로 low-resource 상황에서도 잘 작동할 수 있는 모델에 대한 연구도 많아졌습니다.
대표적으로 NLP 분야에서 쓰이는 방법은 large-scale에 pre-train시킨 다음 downstream-task에 fine-tune하는 방법들이 있는데, 본 서베이 논문도 마찬가지로 low-resource NLP 분야에서 쓸만한 좋은 접근법들을 다룹니다.
그 후, 사용 가능한 데이터의 규모에 따라 여러 관점을 제시하고, 학습 데이터가 적을 때 사용할 수 있는 학습 방법들에 대한 구조적인 틀을 제공합니다.
여기에는 다들 아는 transfer learning, data augmentation 뿐만 아니라 distant supervision도 포함됩니다.
결론적으로, resource가 적은 상황에 알맞은 테크닉을 고르는 것은 너무나도 중요하기 때문에, 다양한 방법들이 어떻게 다르고, 어떤 특징을 지니는 지는 알 필요가 있다는 것입니다.
1. Introduction
오늘날 대부분의 NLP 연구들은 주로 영어에 초점을 뒀으며, 데이터를 많이 필요로 하는 분야 특성상 데이터가 별로 없는 언어들에 있어서는 좋은 성능을 기대할 수가 없습니다.
그렇기 때문에 low-resource senarios를 위한 NLP는 해결해야 할 과제이기도 하죠.
본 논문에서 언급하는 low-resource는 애초에 티벳 언어와 같이 언어 자체가 널리 쓰이지 않거나, 널리 쓰이더라도 NLP 분야에서 연구되지 않은 language를 포함합니다.
전 세계에는 수백 개 이상의 언어가 존재하기 때문에, 이들의 디지털 커뮤니티 참여를 위해서라면 충분히 다루어져야되는 이슈라고 봅니다.
다만, 제가 이 서베이 논문을 택했던 이유이기도 한데, low-resource 'language' 가 아니라 low-resource 'settings'(domain, tasks, ...)도 포함 대상입니다.
즉, 영어처럼 널리 쓰이는 언어더라도 데이터가 부족한 도메인(의학 등)이나 태스크가 있다는 것입니다.
따라서, 본 논문에서 용어 "언어(language)"는 이러한 domain-specific language도 포함하는 개념입니다.
NLP 뿐만 아니고 딥러닝 관련 연구계에서 이러한 low-resource 문제는 엄청 많이 강조되어 왔습니다.
일반적으로 라벨링 데이터가 부족한 상황을 극복하는 것에 초점을 두죠.
하지만 이런 데이터를 보충하기 힘든 경우도 많습니다.
가령, 연구자 개인의 manual heuristics이나 cross-lingual alignments같은 경우에는 데이터도 별로 없을 뿐더러 구축하기도 쉽지 않겠죠.
아무튼, 각 상황에 맞는 접근법을 취하기 위해서 이러한 low-resource 상황과 테크닉들에 대한 총체적인 이해가 필요합니다.
본 서베이 논문에서는 이러한 궁극적인 목표를 필두로, 아래의 요소들을 다룹니다.
- low-resource NLP를 위한 광범위하고 구조적인 개요.
- low-resource settings의 다양한 양상 분석
- 실질적인 연구를 위한 가이드라인으로, 필요한 리소스와 데이터-가정(data assumptions)을 강조
- 현재 이슈와 미래 나아가야할 방향 제시
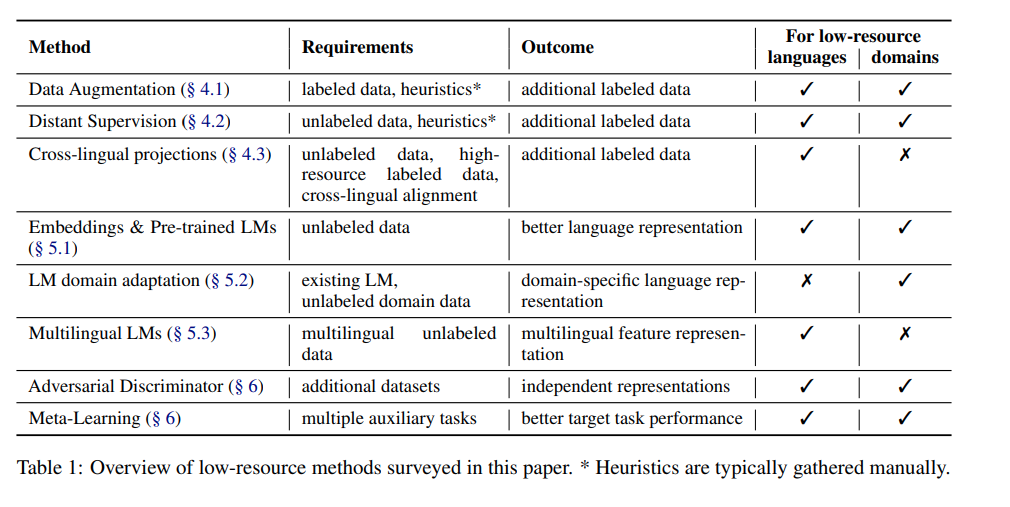
아래의 테이블은 연구를 할 때 (low-resource 상황에서) 고려해야할 요소들(방법, 요구사항, 결과 등)을 보여줍니다.

2. Aspects of "Low-Resource"
본 논문에 포함된 Related Surveys는 다루지 않았습니다(별 내용 없음).
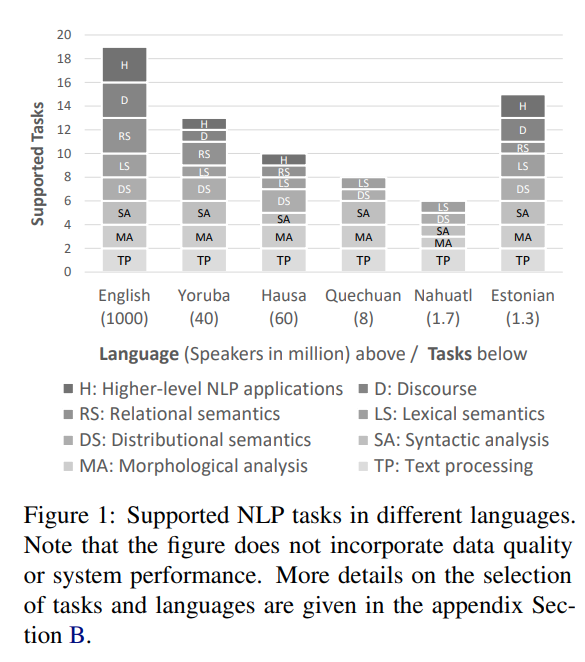
위의 그림은 언어별로, 그리고 수행되는 태스크의 레벨 별로 어떻게 다루어지고 있는지 보여줍니다.
당연히 영어가 아닌 다른 언어들은 high-level tasks에 대한 토대가 많이 부족하며, 설령 Tokenization이나 NER(Name Entity Recognition)과 같은 basic system이 갖춰졌다 하더라도 데이터 퀄리티 자체가 영어보다 낮을 수밖에 없습니다(양이 일단 적으니).
2.1. Dimensions of Resource Availability
NLP & low-resource와 관련된 연구들은 많은 반면, 그 테크닉들의 범주를 완전히 나누고, 평가하고, 다른 방법들과 겹치지 않게 다루는 것이 워낙 어렵습니다.
본 연구에서 다뤄지는 많은 테크닉들은 low-resource 상황에 대한 특정한 가정을 기반으로 하기 때에, 저자들은 아래와 같이 low-resource settings을 범주화했습니다.
(1) availability of task-specific labels
특정한 도메인이나 언어에 대한 라벨링 데이터의 사용가능성(availability of task-specific labels)은 지도학습 관점에서는 가장 대표적인 관점입니다.
라벨링은 (어지간하면) 매뉴얼하게 진행되어야 하며, 이는 시간과 비용 관점에서 너무나도 비싼 태스크입니다.
그 라벨링 하기가 어려운 도메인(의학)이라면 전문적인 인식이 필요하기 때문에 더더욱 다루기 힘들고요.
(2) availability of unlabeled language- or domain-specific text
라벨링되지 않은, 언어 및 도메인에 특화된 텍스트는 또 다른 관점입니다.
특히, 요즘 수 많은 현대 NLP 방법론들이 unlabeled texts에 학습된 input embeddings에 의존하기 때문에 관심을 받고 있는 부분이라 볼 수 있습니다.
(3) availability of auxiliary data
바로 다음 섹션에서 논의될 아이디어들이 대부분 **보조 데이터의 사용가능성(availability of auxiliary data)를 가정합니다.
- 전이학습은 다른 언어나 다른 분야의 task-specific label을 활용할 수 있습니다.
- Distant Suprvision은 외부 지식을 활용할 수 있습니다(knowledge bases or gazetteers 등).
- 혹은 다른 접근법들은 데이터를 만들기 위해 여러 NLP tools을 활용할 수 있습니다.
한국어 감성분석 데이터가 없다면, 영어 감성분석 데이터를 번역기로 돌려서 한국어 감성분석 데이터를 만들 수 있겠죠.
즉, 위의 테크닉이나 방법론들은 low-resource scenario에 의한 결과라고 볼 수 있습니다.
2.2. How Low is Low-Resource?
task-specific labels의 관점에서, low-resource의 경계를 나누는 여러 threshold가 있습니다.
part-of-speech(POS) tagging 태스크에서는, 1,000~2,000개로 제한하기도 했습니다. 또한 다른 연구들에서는 10k, 40k-60k 가량의 token을 가지는 데이터 셋에 대해서 다루었구요.
일반적으로 tasks가 복잡해질수록 이를 위한 자원이 많이 필요하겠죠. 데이터는 적을거구요.
Text Generation task에서는 350k의 labeled training instances를 low-resource라고 언급한 연구도 있습니다.
이렇듯, 태스크마다도 다르지만 사용된 언어 또한 중요합니다.
가령, 같은 양의 데이터일지라도 사용된 언어에 따라서 성능이 다르기 때문에, low-resource의 기준도 다를 수밖에 없습니다.
이처럼, 언어, 태스크마다 low-resource의 기준은 다르기 때문에, low-resource techniques들 또한 다양한 상황을 염두에 두고 방법론의 성능을 평가하고, 연구를 진행해야 합니다.
가령, 데이터가 매우 적을 때에는 딥러닝을 안 쓰는 방법론이 딥러닝을 쓰는 방법론보다 성능이 좋았지만, 데이터가 몇 백개라도 있다면 오히려 딥러닝의 방법론이 더 좋은 성능을 보였다거나...
3. Generating Additional Labeled Data
데이터가 많이 필요해짐에 따라서, labeled data를 대체하기 위한 여러 방법들이 제안되고 있습니다.
저자들은 이런 방법론들을 아래와 같이 나눠서 소개하고 있습니다.
- data augmentation (task-specific instance를 사용해 더 많은 labeled instance를 생성)
- distant supervision(unlabeled data를 라벨링)
- cross-lingual projections
- learning with noisy labels
- involoving non-experts
3.1. Data Augmentation
해당 논문 내에 모든 기법에 대한 주석이 달려있으므로 구체적인 논문에 대한 정보는 담지 않도록 하겠습니다.
https://aclanthology.org/2021.naacl-main.201.pdf
기존에 존재하는 labeled data를 이용해서, 그 특징을 약간의 transform 함으로써 같은 라벨을 갖는 새로운 data를 생성할 수 있습니다.
Image 분야는 생략하고, Text는 어떤 방식으로 augmentation이 행해질까요?
간단히 data의 수준 별로 나눠서 정리해보겠습니다.
3.1.1. Token-level Methods
- token을 동의어로 대체하기
- token을 같은 type의 entities로 대체하기
- token을 같은 형태소를 공유하는 단어로 대체하기
- token을 맥락을 고려한 language model을 사용해 대체하기.
3.1.2. Sentence-level Methods
token level을 넘어서, setence 단위로 augmentation을 적용한다면 더 풍부한 표현들을 얻을 수 있습니다.
Label이 바뀌지 않는 Operation
- manipulation of parts of the dependency tree
- simplification of sentences by removal of sentence parts (문장 단순화)
- inversion of the subject-object relation(피동형 표현 <-> 사동형 표현)
뿐만 아니라, target 문장을 source 문장으로 다시 역 번역해 추가적인 데이터를 얻을 수도 있습니다.
- paraphrasing through back-translation(역번역)
일련의 pseudo labeling으로 볼 수 있는 기법들도 있지만(역번역을 할 때 애초에 완벽하게 번역하는 게 아닌, 딥러닝 모델을 이용해 번역하므로), 아무튼 일반적으로 source text를 간략화하거나, 임의로 변형시키는 기법들입니다.
전체적으로 위의 기법들이 사용될 수 있는 이유는 모델이 generated target text를 예측하는 데 있어서 input(source) features 내 error는 크게 악영향을 주지 않기 대문입니다.
따라서, 위와 같은 기법들은 abstract summarization이나 table-to-text generation같은 text generation tasks에도 쓰일 수 있습니다.
Back-Translation은 text classification task에도 쓰일 수 있습니다.
위의 요소들은 아무래도 번역 모델이 필요합니다만, 대신 language model을 사용해서 text classification에 쓰이는 데이터셋을 augment할 수도 있습니다.
이 또한 pseudo labeling이긴 하지만, 라벨을 갖는 task-specific data에 랭귀지 모델을 학습시킨 다음, 이 라벨에 해당하는 새로운 additional sentences를 생성해서 사용할 수 있습니다.
이런 아이디어를 token level에 적용시킨 논문도 있습니다.
대부분 2018~2020년에 진행된 연구들입니다.
적대적 방법을 활용한 모델
적대적 방법(Adversarial methods)는 종종 모델의 취약점을 찾기 위해서 사용되곤 합니다.
논문을 보진 않았지만 아마 Adversarial Attack에 대한 얘기일텐데, 일반적인 사람들에게는 GAN과 같이 '생성'관련된 개념에 더 익숙할 것 같습니다.
아무튼, 적대적 방법은 NLP dataset을 augment하는 데도 활용될 수 있습니다.
직접 매뉴얼하게 transformation rule을 정해서 사용하는 것보다, 적대적 방법을 사용한다면, text의 의미를 바꾸지 않는 선에서 input에 간섭을 주는 방법을 학습할 수 있습니다.
자연어 text가 아닌 vector repsentations에 대해서도 적용될 수 있습니다.
가령, 라벨을 완전히 뒤바꿀 수 있는 transformation을 적용해 데이터를 보충한다거나..
원래는 특정 라벨을 갖는 데이터에 어그멘테이션을 적용해, 같은 라벨을 갖는 새로운 데이터를 만드는 게 보통이다.
이런저런 방법을 활용하기 위해 grammar correction task를 부차적으로 진행해, 더욱 그럴싸한 새로운 학습 데이터를 만들 수도 있습니다.
3.1.3. Open Issues
사실 컴퓨터 비전 분야에서 Data Augmentation은 굉장히 널리, 일반적으로 쓰일 수 있는 방법들이 대부분입니다(Mixout, flip, affine, ..., ).
하지만, NLP 분야에서는 위에서 소개했던 기법들을 포함해서 널리 쓰일 수 있는 기법들을 별로 없습니다(task-independent(?)).
이는 아마 몇몇 접근법들은 언어에 대한 깊은 이해를 필요로 하기 때문일 수 있습니다.
tasks에 따라, 그리고 languages에 따라 data augmentations을 손쉽게 적용할 수 있는 통합된 프레임워크가 별로 없습니다.
data augmetnation이 마치 트랜스포머 모델에 사전학습 시키는 것과 유사하다는연구 결과도 있습니다만, 저자들은 data augmentations이 언어학자나 전문가들의 인사이트를 활용하기에는 더 적절하다고 주장합니다.
(특히 데이터나 하드웨어가 별로 없는 상황에서)
3.2. Distant & Weak Supervision
3.2.1. Methods
Labeled data를 사용하는 Data augmentation과는 대조적으로, distant or weak supervision은 unlabeled text를 이용하고, 이 text를 수정하지 않습니다.
이 unlabeled text에 대응하는 label은 외부 정보 지식을 활용해 (반)자동적으로 얻습니다.
가령 NER(Named Entity Recognition) task의 경우 list of location names은 사전에서 얻을 수 있으며, text 내 토큰과 list내 entity 매칭도 이 location을 이용해 라벨링될 수 있습니다.
아무튼, 다시 말하면 NER이나 RE(Relation Extraction) 같은 정보 추출(information extraction) 태스크에서는 knowledge bases, gazetteers, dictionaries, structured knowledge source와 같은 곳에서 외부 정보를 얻어서 사용할 수 있습니다.
NER
RE
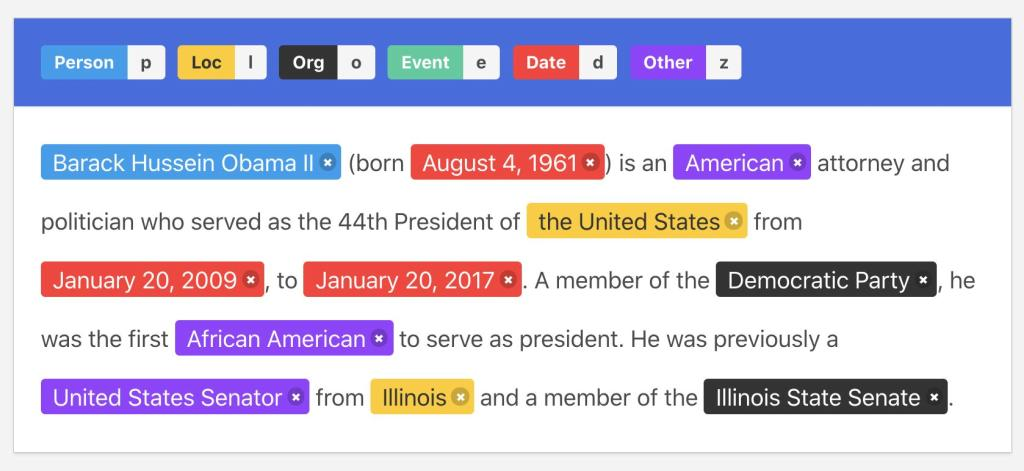

automatic annotation은 간단한 string matching에서부터 classificier & manual steps을 포함한 복잡한 파이프라인까지 다양합니다.
reg-ex rules, simple programming, ...,
Distant Supervision은 NER이나 RE같은 정보추출 분야에는 널리 쓰이고 있지만, 다른 NLP Tasks에는 잘 쓰이지 않습니다.
그래도, 종종 성공적인 결과를 보여주는 연구도 있습니다.
-
document-level로 주어진 sentiment label을 sentence-level instances로 전이시키는 데 맥락을 사용한 연구(Learning with Noisy Labels for Sentence-level Sentiment Classification)
-
또한, list of seed words에 대한 간단한 bag-of-words classifier를 만들고(teacher), 이를 이용해 second deep learning model(student)을 학습시킨학습시킨 연구(weak supervision).
후자의 연구는 https://aclanthology.org/D19-1468/ 참고
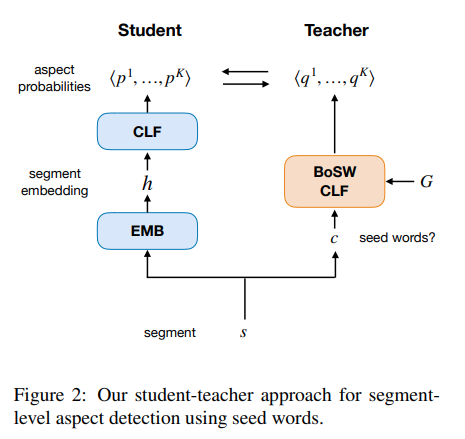
- text classification을 위해 meta-data를 활용한 연구(META: Metadata-Empowered Weak Supervision for Text Classification)
- sentiment annotations으로부터 가이드를 받아 discourse-structure(대화형 구조정도) dataset을 구축한 연구(MEGA RST Discourse Treebanks with Structure and Nuclearity from Scalable Distant Sentiment Supervision)
그 밖에도, Topic Classification task에 있어서, 휴리스틱을 NER과 같은 다른 classifier로나 entity lists로부터 나온 input과 함께 사용하는 방식으로 수행한다거나, Some Classification tasks에서 간단한 규칙을 이용해 라벨을 sentences로 리프레이즈한다거나, Pre-trained language model도 라벨링되지 않은 input에 제일 가까운 label sentence를 판단한다거나 할 수 있습니다.
예를 들어 라벨링되지 않은 영화 리뷰에서, "It was ( )"
라는 문장을 랭귀지 모델링을 이용해 수행하면, great / bad라는 단어를 얻어 라벨로 활용할 수 있겠죠.
3.2.2. Open Issues
NER이나 RE같은 태스크를 위한 distant supervision은 널리 활용되고 있는데요, 애초에 이를 위한 보조 데이터(auxiliary data)가 마련되어 있기도 하고, 성능 자체도 잘 나오기 때문이라고 볼 수 있습니다.
여러 논쟁들이 있지만, 미래에는 distant supervision이 더 많은 NLP Task에 쓰일 수 있다는 연구가 많습니다.
다만, distant supervision을 위해 필요한 보조 데이터는 low-resource settings에서 얻기 어려울 때도 많습니다(Labeled data는 물론이거니와).
가령, low-resource language에서는, high-coverage & error-free dictionaries의 부재로 weak supervision의 성능이 안 좋았다는 연구도 있습니다(POS Tagging에서).
그러니, 평가할 때는 이런 현실적인 요소를 더 반영해야 하고, 만일 high-resource language를 쓴다면 labeled data에만 눈을 두지 말고, 조금 더 많은 보조 데이터를 사용할 필요도 있습니다.
손수 라벨링 하는것보다 훨씬 빠르게 라벨링을 얻을 수 있지만, 여전히 distant supervision을 설계하는 과정에서 규칙을 만들어 준다든지, 아니면 엄밀한 기준의 (좋은) 라벨링 데이터를 만든다든지 하는 데 시간이 걸릴 수 있습니다.
이 과정에서 전문가들과 함께 소통할 필요도 있습니다.
3.3. Cross-Lingual Annotation Projections
3.3.1. Methods
저에게는 컴퓨터 비전 관련 태스크에서 더 익숙한 Annotation 기법입니다.
가령 [그림<->Segmentation] Dataset이 없다면,
(사진에 pre-trained 된 Segmentation 모델을 이용하여)
[사진<->Segmentation] Dataset을 얻고,
(해당 사진을 그림으로 바꾸는 Cycle-GAN같은 모델을 이용하여)
최종적인 [그림<->Segmentation] Dataset을 구축하는 방법을 사용할 수 있습니다.
NLP에서도 task-specific classifier는 high-resource language를 대상으로 학습됩니다.
그러므로, unlabeled low-resource data를 high-resource data로 대응시킨 다음(parallel corpora), 그 high-resource data에 대한 라벨을 위에서 언급한 task-specific classifier를 이용해 얻습니다.
그 결과, (위에서 대응시킨 token 간 alignment를 기반으로) 이 label을 다시 unlabeled low-resource data로 project해 low-resource data에 대한 라벨을 얻을 수 있게 됩니다.
그러니 이것 또한 일종의 distant supervision으로 바라볼 수 있습니다.
Cross-lingual projections이 적용되는 태스크는 주로 (자원이 부족한)POS taging, parsing과 같은 task에 적용되며, 이 때 사용하는 parallel text는 OPUS project, Biblecopora, JW300 corpurs 등이 있습니다.
위와 같이 parallel corpora를 사용하는 것 대신에, 그냥 기계 번역을 활용해 high-resource labeled dataset을 low-resource로 번역해 사용할 수도 있습니다.
3.3.2. Open issues
Cross-lingual projections을 위해 필요한 요소는 아래와 같습니다.
- high-resource language에 대한 labels
- 이 label을 low-resource language로 project하기 위한 수단.
1.은 그렇다 치고 2.는 애초에 기계번역 자체가 low-resource language에는 잘 작동하지 않을 수도 있기 때문에 문제가 커질 수 있습니다.
사실 한국어 정도만 해도 괜찮은데요..
또한 언어에 따라서 정치 / 종교적 texts같은 도메인에는 parallel copora가 제대로 갖춰지지 않았을 수도 있습니다.
한국인들도 잘 모르는 토속신앙들에 대해서는 영어 데이터를 손쉽게 활용할 수 없겠죠.
그래서, word translation, bilingual dictionaries, task-specific seed words를 기반으로 요구조건이 덜 까다로운 시스템을 제안하기도 합니다.
3.4. Learning with Noisy labels
위의 3.2, 3.3 에서 언급한 것처럼 Unlabeled data에 라벨링하는 것은, 빠르고 저렴하지만, 당연하게도 여러 문제를 불러일으킬 수 있습니다.
psuedo labelling(가짜 라벨링)
애초에 완벽하지 않은 모델을 사용해 라벨링하는 것이기 때문에 noisily-labeled data가 쌓이게 되고, 이를 이용해 또다른 학습을 진행한다면 에러가 더더욱 중첩될 수 있다.
그렇기 때문에, distant supervision을 사용하는 최근의 많은 방법들은 이런 부정적 영향을 다루기 위한 노이즈 핸들링 기법들과 같이 사용하곤 합니다.
크게 두 가지로 나누면 아래와 같습니다.
- Noise Filtering
- Noise Modeling
3.4.1. Noise filtering
Noise filtering 방법은 잘못된 라벨일 확률이 높은 학습 데이터를 그냥 지워버리는 방법입니다.
가장 대표적으로는 '이 데이터가 노이즈 데이터냐, 아니냐'를 판단하는 auxiliary classifier를 학습시켜서 사용하는 방법이 있겠죠.
조금 더 자세히 나열하면 아래와 같은 연구들이 있었습니다.
노이즈 데이터를 아예 학습 데이터에서 제거하는 방법(completely filtering)
- through a probability threshold
- through a binary classifier
- use of a reinforcement-based agent
여담이지만, 마지막의 reinforcement-based agent(강화학습 기반 방법)은 train 상황과 test 사이의 불일치를 줄이기 위해(즉, 과적합을 줄이고 test 성능을 높히기 위해) 쓰이기도 합니다(SCST - Self Critical Sentence Training인가..)
**노이즈 데이터를 약간 조정해 사용하는 방법(soft filtering)
- 올바른 데이터일 확률에 따라 re-weights
- attention measure에 따라 re-wieghts
3.4.2. Noise Modeling
라벨 내 노이즈를 아예 모델링할 수도 있습니다.
가장 대표적인 방법은, clean label과 noisy label 간의 관계를 파악하기 위한 confusion matrix를 활용하는 방법입니다.
엄청 많이 쓰였음.
4.4.1. 에서 다루었던 것처럼 noisily-labeled data에 classifier를 학습시키는 것이 아니라, 대신 noise model을 추가해 noisy label을 (우리가 명시적으로 알 수는 없는) clean label distribution으로 옮기는(shift) 방법을 수행하는 것입니다.
- shift prediction 'during testing'
- relabel noisy instances by 'a group of reinforcement agents'
- leverage 'several sources of distant supervision' (and learn how to combine them)
NER tasks에서는 distant supervision으로 생성된 noisy labels은 주로 false negative인 경향이 있습니다.
즉, 특정 엔티티에 대한 언급이 누락되곤 합니다.
이를 다루기 위해 Partial annotation Learning 기법을 활용해 명시적으로 다룰 수 있습니다.
그 밖에도 다양한 방법들이 존재합니다.
- learn latent variables
- use constrained binary learning
- construct a loss assuming that 'only unlabeled positive instances exit'
3.5. Non-Expert Support
뭐 그냥 말그대로 전문가가 아닌 사람이 라벨링을 해주는 방법입니다.
여전히 데이터의 양을 늘리는 대신 라벨의 퀄리티는 조금 떨어질 수밖에 없구요.
non-native-speakers한테 데이터를 얻거나, 라벨링(annotations)에 대해 크게 컨트롤하지 않거나..
(gold-standard-dataset을 마련하는 게 쉽지는 않으니까 ㅎㅎ;)
4. Transfer Learning
- 에서 다뤘던 distant supervision과 data augmentation이 필요한 데이터의 양을 늘렸다면, Transfer Learning은 이미 학습된 representation과 model을 활용해 필요한 데이터의 양을 줄이는 태스크라 할 수 있습니다.
Unlabeled data를 활용해 language representation을 사전학습시킨 BERT같은 모델이 최근에는 점점 더 많이 쓰이고 있습니다.
저자들은 Transfer Learning 단락을 아래와 같이 나눕니다.
- Over view
- domain-specific low-resource settings
- multilingual low-resource settings
4.1. Pre-Trained Language Representations
4.2. Over view of language representations
Feature vectors는 거의 대부분의 딥러닝 모델에서 input으로 받는, 핵심적인 요소임니다.
컴퓨터는 문자를 (거의) 못 다루니까, 숫자로 이루어진 vector로 넣어주어야 합니다.
BERT, GPT 등의 large-scale pre-trained model이 널리 사용된 건 비교적 처음이지만, large-scale corpus에 학습시킨 language-model은 아주 좋은 성능의 word representations을 만들어낼 수 있다는 연구는 2011년에 수행됐었습니다.
또한 이를 downstream task를 위해 다시 사용할 수도 있구요.
우선, 아래와 같이 Subword-based embeddings을 생각해봅시다.
- fastText
- n-gram embeddings
- byte-pair-encoding embeddings
위의 모델들은 out-of-vocabulary issues를 해결하기 위해, original word를 몇 개의 subword로 나눠서, 이들의 조합으로 original word를 나타내는 방식을 취합니다.
out-of-vocabulary issue가 생긴다는 것은 voca의 차원이 높아지기 때문입니다.
즉, (연구마다 다르긴 하지만)voca의 복잡도를 낮추기 위한 방법으로 위와 같은 방법들을 활용할 수 있다는 것입니다.
가령, 수십, 수백억 개의 parameter를 갖는 대규모 모델인 DALL-E에서도 byte-pair-encoding을 사용해 Text features를 생성하곤 합니다.
(데이터만 수백만개, 수천만개, 수억 개를 받는데, 이 voca들을 모두 고려할 수는 없겠죠.)
DALL-E : [논문정리]DALL-E
특히, 이처럼 subword information을 사용하는 임베딩 레이어들은 마찬가지로 low-resource sequence labeling tasks에서 좋은 결과를 보일 수 있다는 연구 결과도 있습니다.
가령, NER tasks나 typing task에서는 word-level embeddings의 성능을 앞설 수 있었습니다.
마찬가지로, rare words에 대한 편향을 줄이기 위한 방법으로 word2vec model에 smoothing을 적용하는 방법도 low-resource settings에서 성능 향상을 불러 일으켰습니다.
Dirichlet-Smoothed Word Embeddings for Low-Resource Settings(ACL, 2020)
다시, 최근으로 오면, Language Modeling 방식으로 Un-labeled data를 학습하는 pre-training large embeddings models들이 요즘 트렌드입니다.
아무튼 위와 같은 pre-trained transformer는 BERT나 RoBERTa 등이 있습니다.
위의 모델들은 주로 unlabeled data는 많고, **task-specific labeled data는 적은 low-resource languages를 다룰 때 굉장히 도움이 됩니다.
위에선 Un-labeled data를 이용한다고 말했습니다만, 엄밀히 따지고 보면 이 data를 이용해 빈칸을 뚫어 Language Modeling을 수행하는 것이기 때문에 비지도학습이라고 하지는 않고, 주로 자기지도학습(Self-superivsed Learning)이라고 부르는 편입니다.
특히, Transformer는 CNN / LSTM 계열과 다르게 모델의 규모를 키우기 쉬우며, 데이터를 많이 받을수록 성능 향상에 유리한 모델로 알려져 있습니다.
반면 데이터가 비교적 적다면 CNN / LSTM보다 (일반적으로는) 성능이 낮습니다. Inductive bias가 낮아서.. --> [논문리뷰]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE : Vi-T(Vision Transformer)
4.1.2. Open issues
pre-trained language model은 분명 기존의 word embeddings 방법들보다는 좋은 성능 향상을 불러 일으켰습니다만, 여전히 문제점은 있습니다.
- 이 모델들은 large hardward requirements를 요구한다.
- 특히, 트랜스포머 모델은 너무나도..
- 그러니 hardward 관점에서 low-resource라면 사용하기 힘들다.
실제로, low-resource language에서는 large-size의 transformer보다 low-to-medium-depth-transformer가 더 잘 작동하는 모습을 보였다거나(On Optimal Transformer Depth for Low-Resource Language Translation), 파라미터가 훨씬 적은 모델이 GPT-3의 성능에 버금가는 모습을 보이는 연구들도 있습니다(It’s not just size that matters: Small language models are also few-shot learners.).
그밖에도 데이터가 아주 없을 때라면 simple bag-of-words 접근법이 Transformer보다 잘 작동하는 연구도 있구요..
유사하게, cross-view training을 이용해 unlabeled data를 활용한다면 BERT같이 general representations을 학습하는 모델보다 좋은 성능을 뽑아낼 수도 있습니다.
그래도 data quality가 낮다면 low-resource language는 high-resource language에 비해 안 좋은 embeddings 성능을 보일 수밖에 없다고 합니다.
Massive vs. Curated Embeddings for Low-Resourced Languages: the Case of Yorùbá and Twi
4.2. Domain-Specific Pre-Training
specialized domain에 쓰이는 language는 general domain에 쓰이는 language랑 한참 다를 수도 있기 때문에, 결국 특정 도메인에선 그 자체로 low-resource인 상황도 자주 있습니다.
예를 들어, 아래와 같은 도메인들이 있겠죠.
- scientific articles(기호, 이론 등)
- Bio-Medical(전문용어 등)
- e.t.c.
위의 도메인들 모두 general-domain data와는 다르기 때문에 "domain-gap" 문제를 불러일으킬 수 있습니다.
이를 다루는 솔루션 중 대표적인 것은 Target Domain에 Adaptation을 진행하는 것입니다.
즉, language model을 finetune하는 방법입니다.
굉장히 중요한 연구 중 하나인데요, Gururangan et al의 연구인 Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks에서는 모델을 domain or task-adaptive한 방식으로 계속해서 (Unlabeled data를) 사전학습시킬 경우 high-resource든 low-resource든 여러 도메인과 tasks에 대해 성능이 높아질 수 있음을 보였습니다.
그 밖에도 수 많은 domain-adapted language models 연구들에도 이러한 사실이 나타나있습니다.
(Alsentzer et al., 2019; Huang et al.,
2019; Adhikari et al., 2019; Lee and Hsiang, 2020;
Jain and Ganesamoorty, 2020,...)
특히, Biomedical PubMED articles을 대상으로 학습한 BioBERT가 괄목할 만한 성과를 보였습니다.
당연히 General-Domain BERTqhek domain-adapted SciBERT(BioBERT)가 성능이 좋았습니다.
어쩌면 당연해보이는 이런 사실들에 대해 심층적으로 분석한 연구도 존재합니다.
읽어보진 않았지만, 대략적으로 pre-trained language model에는 도메인마다 클러스터가 존재하고, 입력 data의 특성에 따라 특정 cluster가 활발하게 이용되는 등의 연구인듯 합니다.
그 밖에도 (보통 general-domain의) high-resource embeddings을 (specific한 target domain의) low-resource embeddings**에 같이 활용할 수도 있습니다.
- attention-based meat-embeddings을 이용해서.
- 도메인에 상관하지 않는 reprensentation을 생성하기 위해 embedding spcae를 구별하게끔 설계된 adversarial discriminator을 이용해서.
- 이 방법을 사용하면 다양한 도메인에 학습된 embeddings을 align할 수 있다(Adversarial learning of feature-based meta-embeddings).
4.3. Multilingual Language Models
pre-trained language model들 경우에 single model을 다양한 언어에 학습시킨 multilingual BERT, XLM-RoBERTa나, monolingual representation을 결합함으로써 multilingual represnetation을 학습하는 Lange et al의 방법 등이 있습니다.
이 모델들은 모두 사전학습 과정에서 다양한 언어를 접하기 때문에 언어 간, 혹은 다차원 언어를 다루어야 하는 태스크에 적합합니다.
귀찮으니 나중에 영어 데이터셋 말고 한글 데이터셋 활용할 때 보는 걸로..
뭐 예를 들어 labeled data가 아예 없는 low-resource language와 labeled data가 있는 high-resource language를 활용하는 cross-lingual zero-shot learning같은 경우에 적용될 수 있습니다.. 만은, 우선 방향성 자체가 거의 접할 일 없는 태스크인 것 같아서 해당 섹션은 생략하겠습니다.
5. Ideas From Low-Resource Machine Learning in Non-NLP Communities
5.1. Meta Learning
비단 NLP 뿐만 아니라 컴퓨터 비전, 강화학습, 음성 등 다양한 분야에서 쓰이는 방법들로부터 아이디어를 얻을 수도 있겠죠.
일반적으로는 data-augmentation이나 pre-training이긴 한데요, 위에서 다루었으니 해당 단락에서는 메타러닝(Meta-Learning)에 대해서 다루어봅시다.
메타 러닝은 일반적으로 task-specific한 모델이 아닌, 다양한 태스크에 잘 작동하는 multi-task learning을 잘하는 것을 목표로 합니다.
메타러닝에 대한 간략한 설명은 아래의 글로 대치하겠습니다.
메타러닝에 대해 간단히 다룬 글 : Introduction to Few-Shot Learning & Meta Learning(velog)
NLP 분야에서도 이런 메타러닝 관련 접근법들이 제안됐었는데요, 수행한 태스크들은 아래와 같습니다.
- Sentiment analysis
- user intent classification
- natural language understanding
- text classification
- dialogue generation
일반적으로 일련의 auxiliary tasks를 수행하는게 기본이지만, 대신 language-specific NER Model에 대한 앙상블을 구축해 zero- or few-shot target language에 적용하는 방법도 있습니다.
5.2. Adversarial methods(and Reinforcement?)
결국 전이학습의 핵심은 pre-trained domain과 target domain(downstream domain)의 차이를 고려하는 것입니다.
애초에 딥러닝 기반 방법은 모델에게 어떤 정보를 줄 지 디자인할 수가 없기 때문에 더욱 어렵긴 합니다.
이런 이슈를 다루는 방법들 중에, 2014년 이안 굿펠로우가 제안한 Adversarial Discriminator를 사용하는 방법이 있습니다.
즉, 모델이 data source에만 치중된 feature representation을 배우지 못하도록 방지하는 것이죠.
data-specific한 representation 대신 general한 feature representation을 배워야 다른 도메인에 활용할 때도 잘 작동할 수 있습니다.
이런 적대적 학습(adversarial training을 이용해 domain-independent한 representation을 학습하는 방법들은 꽤나 많이 쓰여왔습니다(Gui et al. (2017), iu et al. (2017), Kasai et al. (2019), Grießhaber et al. (2020) and Zhou et al. (2019)).
6. Discussion and Conclusion
- low-resource NLP에 대해 최근의 연구들을 다루었다.
- 연구자들에게 올바른 도구(Method, Technique, ...)를 선택하게끔 가이드라인을 주었다.
- 이런 테크닉들을 연구하고 평가할 때는 data-availability에 대해 다차원적으로 접근할 필요가 있다.
- 가령, 특정 domain이나 특정 언어 간에는 기본적으로 필요한 data 규모가 다르기 때문에.
- 그래야 나중에 더 적절한 테크닉을 선택할 수 있지 않겠냐.
- 중간에도 말했듯 Data Augmentation과 pre-trained language model은 비슷하다는 연구 결과가 있었다(How effective is task-agnostic data augmentation for pretrained transformers?.
- 근데 (예를 들어) augmentation 테크닉을 제안할 때에는 그냥 비슷한 augmentation 기법들과만 비교하지 않느냐?
- 때로는 pre-trained model들도 비교 대상에 둘 필요가 있다.
- 물론 이게 너무 어렵고 노력이 많이 드는 태스크인 것 맞다만, 미래를 위해 열정을 좀 보였으면 좋겠다.
