논문 리뷰 - Diversity, Serendipity, Novelty, and Coverage: A Survey and Empirical Analysis of Beyond-Accuracy Objectives in Recommender Systems
부스트캠프 최종프로젝트 시작 전, 우리팀이 해결해야 할 문제중 하나인 추천시스템에서의 정성평가(Diversity, Serendipity, Novelty, Coverage...)를 어떻게 표현할 수 있는지 정의가 무엇인지 잘 정리된 논문이 있어 읽어보고 내용을 정리 및 요약해보려고 한다.
그 중에서 특히 Diversity와 Serendipity가 어렵다고 생각되어서, 그 부분에 중점을 두고 요약해볼 예정이다.
1. Abstract & Introduction
해당 논문에서는 좋은 추천시스템이 무엇인가에 대한 기준을 잡을 수 있는 4가지 지표 혹은 방법론에 대해 소개한다. 이전까지의 추천시스템은 모델의 예측이 정답을 맞췄는지, 실제값과 얼마나 가까운지에 중점을 뒀지만, 좋은 추천이 이루어지기 위해서는 추천이 얼마나 다양하게 또는 참신하게 이루어지고 있는지 고려해야한다고 말하고 있다. 예를들어, 요즘 사람들에게 호평을 받는 Youtube, Spotify의 추천 알고리즘은 사람들에게 유행을 타고 있는 영상,음악들을 추천해줄뿐더러 내가 처음 보는 영상, 음악도 추천해준다. 오죽하면 알고리즘이라는 단어가 하나의 밈, 유행어가 됐을까.
첫번째로는 diversity에 대한 설명이 나오는데, 정확도에서 조금의 손해를 보더라도 유저가 좋아할지도 모르는 아이템들도 최대한 다양하게 추천해주는 것이 필요하다고 소개하고 있다.
두번째는 Serendipity에 대한 설명으로, 미지의 가치있고 즐거운것을 찾는 과정이라고 설명한다. 또한 surprise와 relevance의 두가지 요소로 이루어져 있으며 추천시스템 연구에서 중요하게 다뤄지고 있는 부분으로써 몇몇 연구에서는 공식적인 정의를 제공한 연구가 없다고 한다. 왜냐면 얼마나 놀라운지, 예기치 않은 추천결과인지 그 정도를 측정하거나 개념을 정의하기는 매우 어렵기 때문이다.
세번째는 Novelty인데, Serendipity와 밀접한 관련이 있다. 이전에 추천되지 않은 아이템들을 의미하며, Serendipity와 굉장히 유사한 얘기 같지만 이를 별개로 구분짓기도 한다. Serendipitious(우연적인)하다는 것은 새롭고 놀라운것이어야 하기 때문에 우연함은 새로움의 하위 집합 개념이라고 설명한다.
또한, 일반적으로는 아이템을 기준으로 보지 않고 유저 기준으로 새로움을 정의하며 인기도가 낮은 항목이 사용자에게는 참신하게 다가올 것이라고 한다. 때문에 참신성과 우연성을 구분짓는것이 가능한 것 같다.
네번째는 Coverage이다. 추천된 아이템들이 어느정도 범위를 cover할 수 있는지를 의미한다. 즉 Coverage가 높다는 것은 사용자가 접할 수 있는 아이템이 굉장히 많음을 의미하기도 한다. 이를 통해 전체 제품 판매량이 증가할 수 있다고 한다. 보통 Coverage는 novelty와 연관이 있다고 한다. 이는 당연히 여겨지기도 하는데, 유저에게 참신한 제품을 추천하려면 그만큼 폭 넓은 추천이 이루어져야 하기 때문이라고 생각한다.
이러한 지표들은 정해진 수준이 없기 때문에 사용자 별 선호도에 맞추는 것이 적절할 것 같다. 한 가지 예로, 음악을 추천할 때 사용자가 친숙하지만 한동안 듣지 않았던 음악을 추천해주는 것은 리스크가 적지만 아예 알려지지 않은(놀라운) 음악을 추천해주는 것은 어느정도 리스크가 있기 때문에 항상 놀라운 추천을 추구하는 것은 옳지 않기 때문이다.
2.Diversity
Diversity의 개념은 검색 시스템 연구의 아이디에서 시작됐다고 소개한다. 검색된 문서의 가치는 질의에 대한 유사성뿐만 아니라 검색된 또 다른 문서와의 유사성에도 영향을 받는다고 한다.
예를 들어 "재규어"라는 검색어를 넣었을 때 자동차, 동물, ... 등의 결과가 나올 것인데 재규어-자동차 문서는 재규어와 자동차간의 유사성뿐만아니라 동물 재규어와의 유사성 또한 영향을 준다는 의미라고 해석했다.
그렇기 때문에 명확한 정보가 없다면 사용자가 실제로 관심있어하는 주제가 무엇인지 알기 어렵다.
따라서 검색된 문서 목록이 다양한 영역을 포함하면, 사용자의 관심 주제 혹은 원하는 정보를 충족시켜줄 수 있는 가능성이 증가하기 때문에 목록의 다양성 증가가 유효할 수 있다고 한다.
Diversity Metric
이를 정량적 지표로 나타내기 위하여 각 문서 쌍별 거리, 즉 유사도를 계산하는 식을 제안한 연구가 있었다고 소개한다.
다음 식은 추천된 리스트 R (|R| > 1 을 만족하는)의 다양성을 계산하기 위해 목록 내 항목간의 평균 쌍별 거리로 측정할 것을 제안한 식이다.
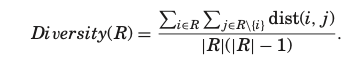
분모는 총 조합의 경우의 수(A,B와 B,A는 다르다고 판단한 경우), 분자는 총 조합의 거리 합을 뜻한다.
이 때의 거리함수는 Jaccard 유사도, Cosine 유사도 등 다양한 지표를 사용한다고 한다.
위의 식으로 계산된 점수가 높다면 그 만큼 다양성이 낮다는 것을 의미한다. (유사한 아이템쌍들이 많다는 것을 의미하기 때문에)
이를 CF 기법에 적용시킨다면 Item based CF에서 두 아이템간의 유사도를 통해 계산될 수도 있다고 한다.
Matrix Factorization 기법으로 접근한다면 각 아이템 latent vector를 이용하여 이를 계산할 수 있다고 한다. -> 이 부분을 MF 모델에 적용시켜봐야겠다는 생각이 들었다.
Finally, item distance can also be obtained from the latent feature vectors in matrix factorization approaches [Vargas et al. 2011; Willemsen et al. 2011; Shi et al. 2012; Su et al. 2013].
아이템의 장르 활용
또한 아이템을 장르로 설명할 수 있다면, 아이템의 다양성보다는 장르의 다양성이 사용자에게 다양한 추천으로 인식될 수 있다고 주장하면서 다양성을 정의하기 위해 장르를 사용하는것을 제안하기도 한다. 장르를 다양하게 추천하려면 가장 이상적인 것은 random sampling을 하는 것이라고 설명하기도 한다.
다양성과 정확성을 잘 결합하기 위한 metric 중 하나로 a-nDCG도 소개되었는데, 높은 순위에 추천된 아이템들이 서로 비슷한 성질을 띄고 있으면 페널티를 먹게되는 형태라고 한다. 특정 가중치를 둬 다양성을 반영하는것이 굉장히 중요하다고 주장하고 있다.
2.2 Increasing Diversity
다양성을 높이기 위한 두가지 방법이 있는데, 첫번째는 순위를 일부러 재조정하는 것을 기반으로 하는 방법이고 두번째는 다양성 지표를 위해 새로운 모델을 정의하는 방법이 있다고 한다.
2.2.1 Recommendataion Reranking for Diversity
알고리즘으로 추천한 리스트인 C를 이용하여 크기가 N(|C| > N)인 추천 리스트 R을 생성한다. C는 CF등 기존 알고리즘으로 추천한 리스트이기 때문에 알고리즘에서 정의한 유사성, 연관성을 기준으로 추천이 되어있을것이다. 그러한 리스트들에서 필터링을 거쳐 R로 이동한다고 생각하면 될 것 같다. 이와 같은 작업을 Reranking이라고 한다.
목적함수는 이미 수록된 항목에 대한 적합성과 다양성을 조합하여 정의되었다. 이런 목적함수를 최대화 하는 C의 항목이 R로 이동하게 된다.
자세한 설명은 아래에 첨부하겠다.

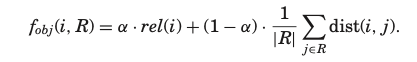
수식을 살펴보면, 아이템 i에 대한 관련도 와 아이템 i와 R에 있는 모든 j에 대한 평균 거리의 가중합으로 결합되어있다.
즉, 검색으로 예를 들면 앞의 항인 는 사용자의 쿼리와 검색 결과간의 유사성을 나타내고, 뒤의 항은 두 개의 결과간의 유사성()을 보완하는 개념과 유사하다.
마치 competition형 프로젝트에서는 항상 앙상블 기법이 좋은 성능을 냈던 것과 유사한 접근법이라고 생각하고 있다. (단순 가중평균을 이용한 앙상블 기법과 같은)
2.2.2 Diversity Modeling
유저가 얼마나 다양한 항목에 관심이 있는지를 표현하기 위해 공분산행렬을 이용한다. 즉, 유저별로 취향 범위나 다양화 수준을 각각 적용시킨다. 예를들어, 다양한 항목을 이용하고 평가했던 유저의 분산이 유사한 항목들만을 이용하고 평가했던 유저의 분산보다 큼을 의미한다.
pair-wise한 유사성을 계산하기 위해 두 아이템의 latent vector를 내적하는 연산을 수행한다고 언급이 되어있기도 하다.
자세한 모델링이나 모델 구조는 따로 나와있지 않아서 간략히 요약하고 넘어가겠다.
3. Serendipity
3.1 Defining and Measuring Serendipity
Serendipity를 정의함에 있어서 핵심 요소는 Surprise이다. 일부 논문 혹은 문헌에서는 비공식적으로는 Surprise를 "어쩌면 발견하지 못할 수도 있었을 정도로 놀라운, 흥미로운"으로 정의했다.
이러한 개념을 이용하기 위해 일반적으로 기존에 추천해오던 항목들과 예측하기 어려훈 항목들을 결합하고자 하면서 Serendipity Metric 공식이 제안되었다.
Serendipity Metric
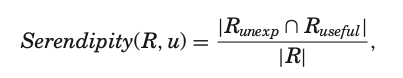
- : 한 유저에 대해서 생성된 추천 아이템 집합
- : 유저에 대해서 unexpected 한 아이템 부분집합
에서 기존의 예측모델인이 예측한 아이템들인 을 제거해서 만들어진다. ( \ )
의문점1) 기존 예측모델인 은 어떤걸 사용하는가?
의문점2) R이 결국 으로 만들어낸 추천 아이템 집합 아닌가?
-> Top 10개()를 뽑을 때, 이미 100개()를 뽑아놓는다고 가정하면 10개를 제외한 90개()가 뽑히긴하는데 이것을 의미하는지 확실하지 않다. - : 유저에 대해서 useful 한 아이템 부분집합
유저 혹은 유저가 아이템에 매긴 ratings에 근사하여 정의 된다.
위와 같은 방법은 PM의 예측에 민감하다는 한계점이 있다.
최근에는 를 \ 로 정의한 연구가 있는데, 는 사용자가 기존에 매긴 ratings와 유사한 아이템들을 포함한, 즉 추천된 아이템 집합이다. 때문에 위에서 비공식적으로 정의했다는 surprise와는 다른 맥락이기도 하여 주의해야한다고 전달하고 있다.
추후 7장에서 실험을 진행할 때에는 unexpectedness or surprise를 expected items으로 부터 거리로 측정하는 아이디어를 채택한다고 한다.
정리하자면, 아이템간의 dist를 계산하여 이를 토대로 diversity, novelty, serendipity등에 이용을하는 경우가 많은 것 같다.
그렇기 때문에 논문에서 아이템 latent vector를 사용할 수 있는 모델들을 주로 얘기하는 것 같기도 하다.
3.2 Increasing Serendipity
- 웹 크롤링을 통해 우연한 정보검색을 지원하게끔 소프트웨어를 설계한 예시. (어려워서 생략)
- 지도학습을 이용하여 0과 1을 예측하게 하는데, 예측 결과의 확률 값의 차이가 크면 클 수록 우연하다고 간주 한다. 예를 들자면 0.1과 0.9는 굉장히 우연하다고 볼 수 있고, 0.1와 0.4은 비교적 덜 우연하다고 간주하는것 처럼 절대적인 차이가 큰 항목은 우연한 것으로 간주되어 추천 항목에 포함되도록 하였다.
-
그래프 기반 알고리즘을 사용하는 방식. 유저-아이템간 양방향 그래프를 이용하여 bridging score를 계산하고 서로 분리된 다른 영역을 잇는 노드는 높은 bridging score를 부여받는다. 이 bridging score는 아이템 연관도와 결함되어 추천항목을 생성하는데에 이용된다. A와 관련되어있지만 너무 비슷하지는 않은 B를 선택하면 그로 인해 A와 B는 좋은 suprising한 추천을 서로에게서 제공받을 수 있다고 주장한다.
-
LDA(Latent Dirichlet Allocation)을 이용하는 방식으로, 음악 추천 시스템 서비스를 제공하고 있는 last.fm에서는 아티스트를 LDA 벡터로 표현하면 사용자의 음악 감상 기록에서 아티스트간의 유사성을 계산할 수 있다고 한다. 그렇게 한 뒤 사용자들에게 주로 듣고 있는 아티스트들의 클러스터 밖에 있는 아티스트들을 홍보하고 추천함으로써 우연성을 보장해준다고 한다.
-
아이템 유사도 점수와(CF와 같은 기존 추천 알고리즘에서 계산되는) 우연성 점수(추천 항목에 들어갈 것으로 예상되는 아이템들과의 거리(dist)를 이용한 점수)의 선형 결합으로 만든 함수를 활용하는 방식. 추천항목에 들어갈 것으로 예상되는 아이템들은 사용자가 평점을 매긴 아이템과 유사한 아이템들로 이루어진다. (예를 들면 같은 감독이 만든 영화, 같은 장르의 영화들 등등) 이 선형결합된 함수를 이용해 유사한 아이템과 의외의 아이템을 같이 추천해주는 효과를 기대한다.
