
동일한 값을 가진 것들끼리 합쳐서 평균 등의 통계를 계산하기 위해 '그룹화'를 사용한다.
"다소 복잡하니 복습 잘 하시길!!"
- 데이터 준비 (이전과 동일)
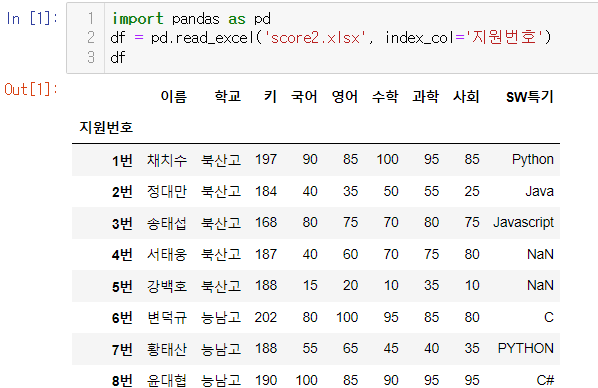
그룹화 by 학교
.groupby(): 입력된 카테고리에서 같은 값끼리 그룹으로 묶어줌.
.get_group(): 입력된 그룹의 데이터를 출력해줌.
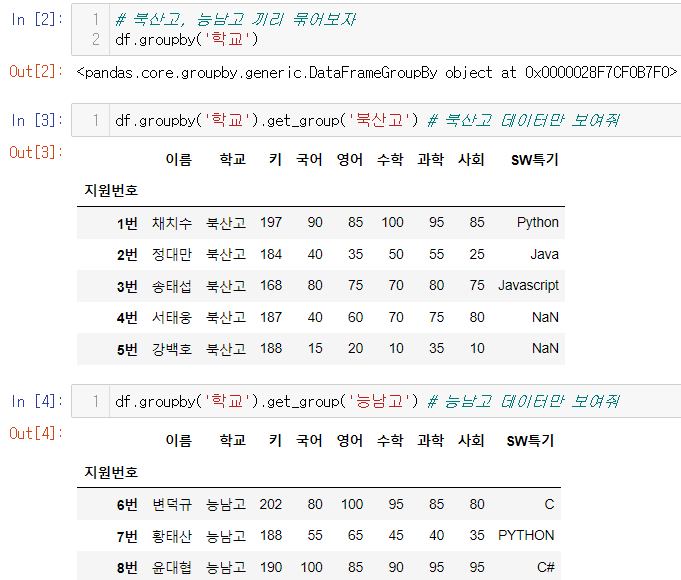
.mean(): 계산 가능한 데이터들의 평균값을 "그룹 별로" 계산해줌.

.size(): 그룹 별 크기를 구해줌.

그룹화 by 학년
- 그룹화 기준을 여러 개 쓰려면, 역시 [ ]로 입력해주면 됨.
('학년'은 전에 배웠던 Column 추가 방법으로 새롭게 만들어줬음)
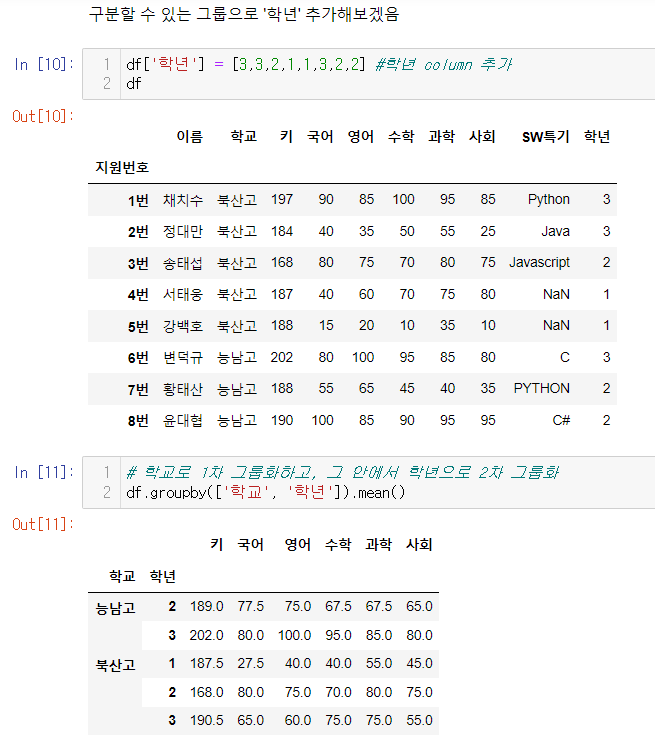
.sort_values()를 붙여서 정렬을 할 수도 있음.
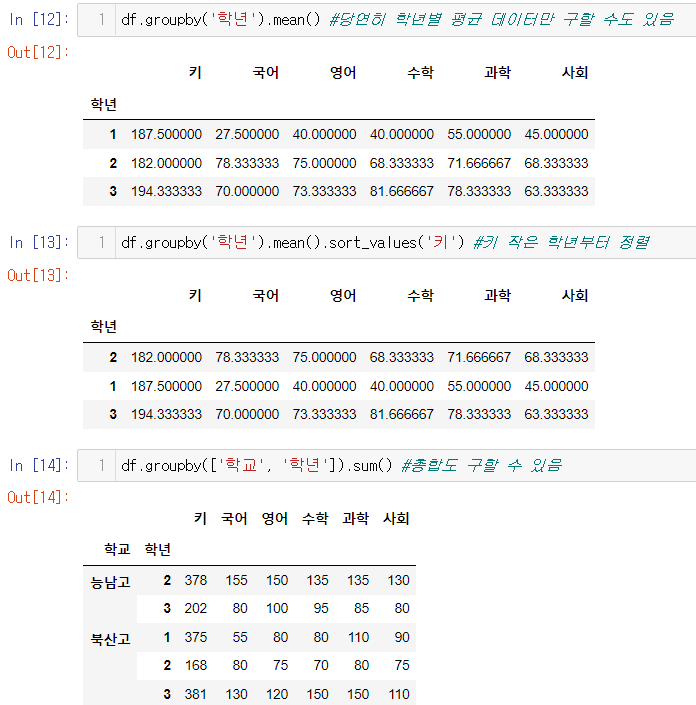
.sum(): 계산 가능한 데이터들의 총합을 "그룹 별로" 계산해줌.
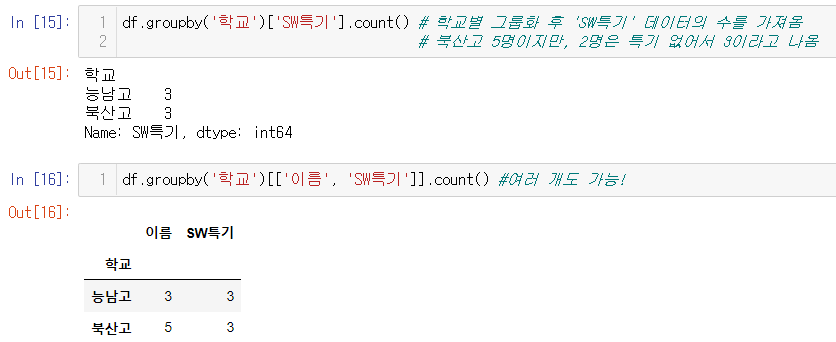
.count(): 그룹 별로 특정 데이터의 개수를 구해줌.
🆚 'SW특기' column에 데이터가 총 몇 개 들어있는지
.value_counts(): 그룹 별로 특정 데이터의 고유값별 개수를 구해줌.
🆚 '학년' column에 1,2,3이 각각 몇 개씩 있는지
↪ 뒤에.loc붙이면 특정 그룹만 골라서 볼 수도 있음.
↪normalize=True설정하면 비율로 바꿔서 볼 수도 있음.

🧐My Point
❓[9] 왜 size()의 ()안에 안 넣고, 뒤에 갖다붙이는지 의문이었는데.. ➡️ 아마 () 안에는 size에 대한 옵션이 (normalize 옵션을 괄호 속에 넣듯이) 들어가는 게 아닌가 싶다..!
❗.count()🆚.value_counts() 잘 이해하자!
: count는 말 그대로 입력한 열에 데이터가 몇 개 들어있는지 보는 것이고,
value_count는 입력한 열의 고유값들이 각각 몇 개인지 보는 것이다.
예를 들어, '학년'이라는 열에 대해 count하면 학년이라는 열에 데이터가 몇 개 있는지 보여주지만, value_counts하면 학년이라는 열 속에서 고유값 1,2,3이 각각 몇 개씩 있는지를 보여준다.

생각은 그만