03. 캐글 설문조사 분석하기
.T.astype.count.drop().filter().groupby.isin.plot.bar.plot.barh.range.set_index.set_title.sort_index.sort_values.str.replace.str.split.tolist.value_countsPalettedoc stringexpand=Truehuematplotlibnormalize=Truepandaspd.crosstabregexseabornsns.barplot()sns.countplot()불리언 인덱싱
0
프로젝트 연습
목록 보기
3/4

캐글에서 실시한 설문조사 내용을 시각화해보고 간단히 분석해보려 한다.
- 박조은 님의 인프런 강좌를 기반으로 한 내용이다.
" 캐글에선 해마다 설문조사가 올라옵니다. 세계적으로 어떤 기술들이 많이 쓰이는지 등 현황을 볼 수 있어 데이터사이언스 공부를 시작하는 사람들이 보면 도움이 됩니다."
캐글 소개
- 캐글은 전 세계 데이터 전문가들이 경쟁하는 플랫폼이다.
- <Competitions> : 다양한 경진대회. 상금, 상, 리크루팅 등의 보상 있음.
- <Datasets> : 다양한 데이터셋 제공. 코로나 데이터 인기 많았음.
- <Code> : 다른 사람들의 분석사례를 볼 수 있음. 'most votes'로 필터 걸어서 보는 걸 추천. → 'copy and edit'로 복사해서 실습해볼 수도 있음!
- <Discussions> : 다양한 토론의 장.
- <Learn> : 다양한 커리쿨럼의 스터디 제공.
Kaggle Survey 분석 (Lv.1)
기본 설정
- 이번 프로젝트를 위한 기본 설정을 먼저 해줌. (자세한 설명은 따로 없었음)
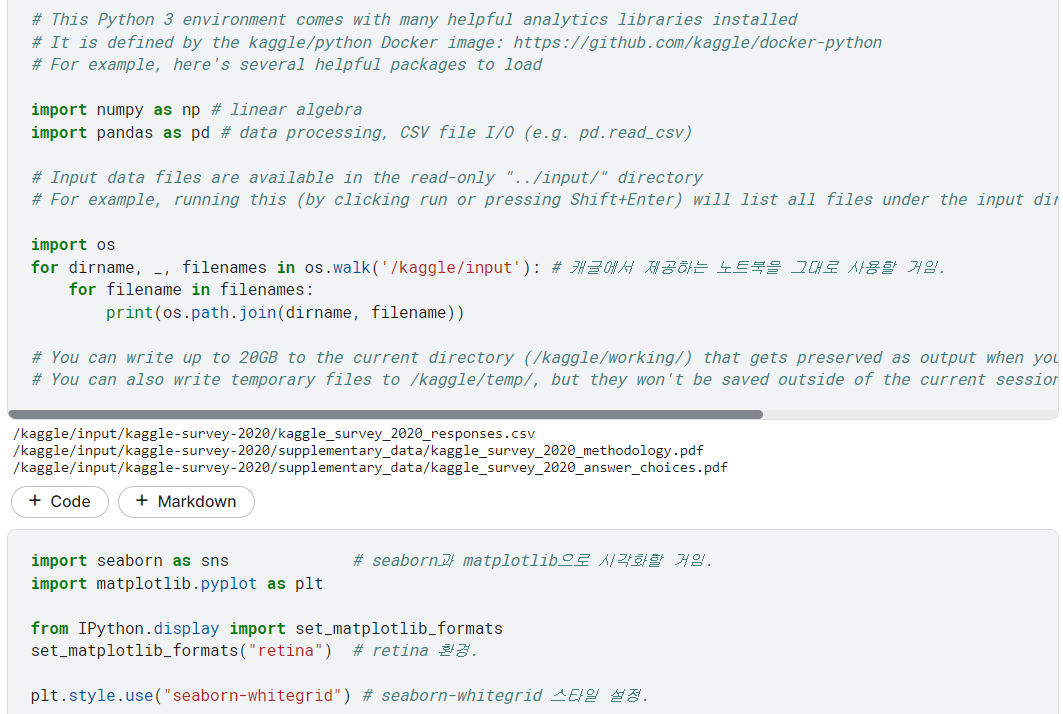
데이터 불러오기
- 판다스로 csv 파일을 불러오고, 데이터 크기를 확인함.
low_memory=False: 여러 타입 섞여있어서 이거 설정하라고 떴음.

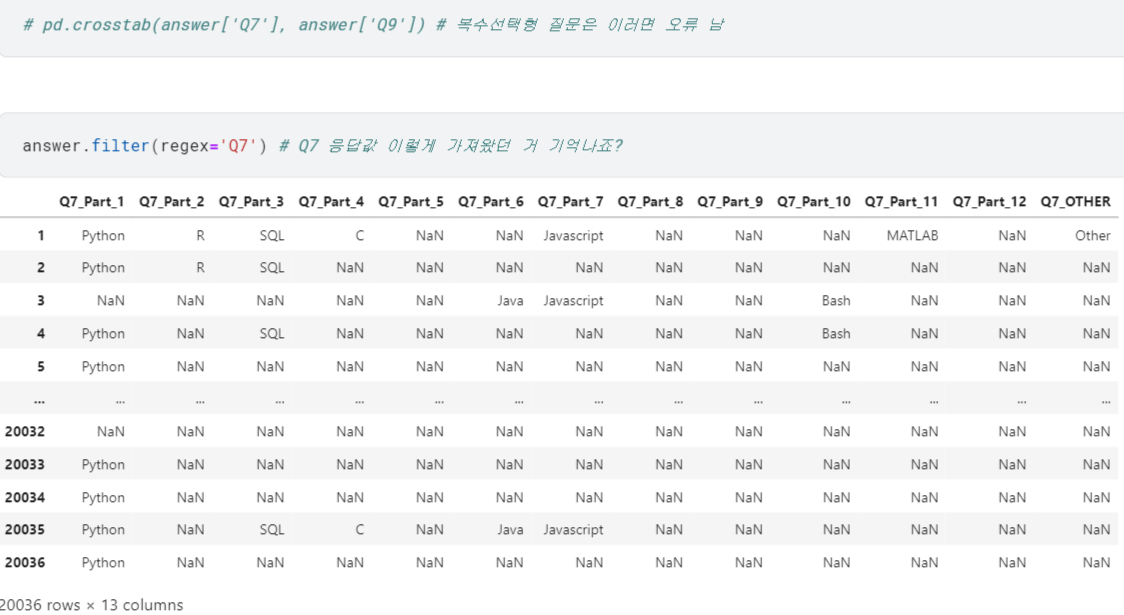
.head()로 미리보기 찍어봄.- 각 열은 질문들의 번호가 매겨져 있는데, Q7처럼 복수응답 가능한 질문은 세부적으로(ex. 'Q7_part_1') 나눠져 있음.
- 0행은 질문 내용이 들어있고, 그 아래로는 응답 내용이 들어있음.
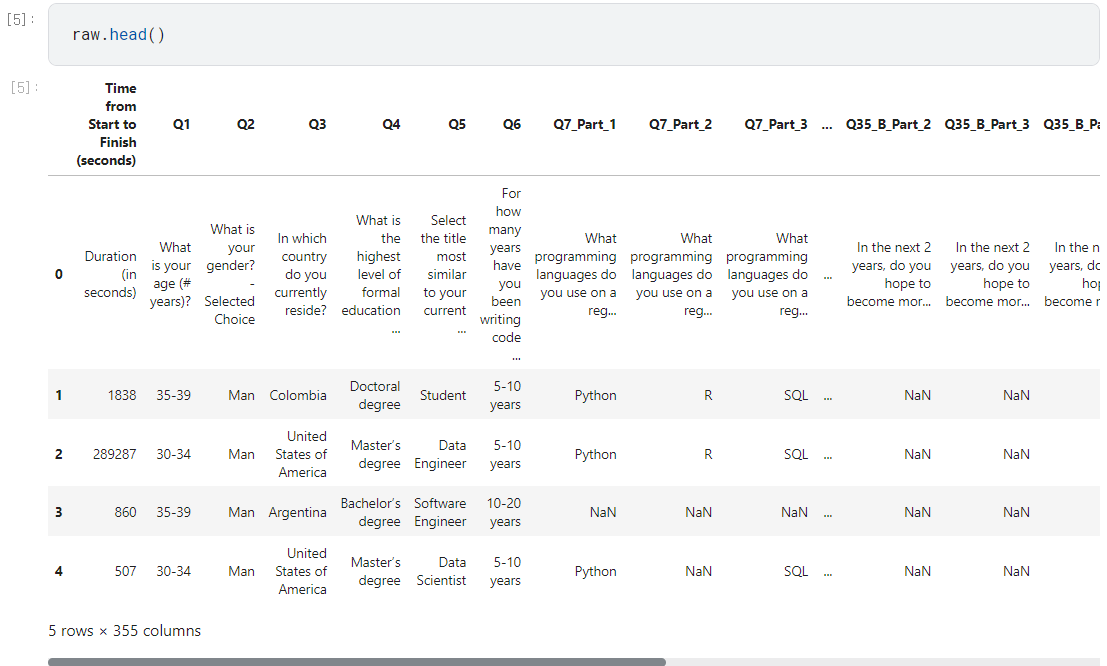
질문과 응답 분리하기
- 0행은
question변수에 넣음. 35개의 질문이 들어있음.
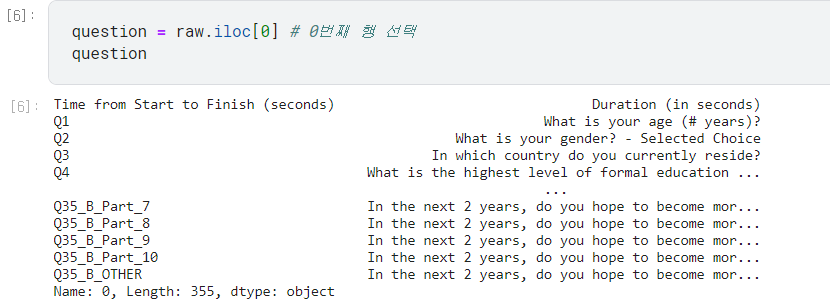
- 나머지 1~20036행은
answer변수에 넣어서 응답 내용을 따로 모음.
(raw.drop?해보면 'axis=0'이라고 나옴 = '행 기준 삭제'가 기본값임을 알 수 있음)
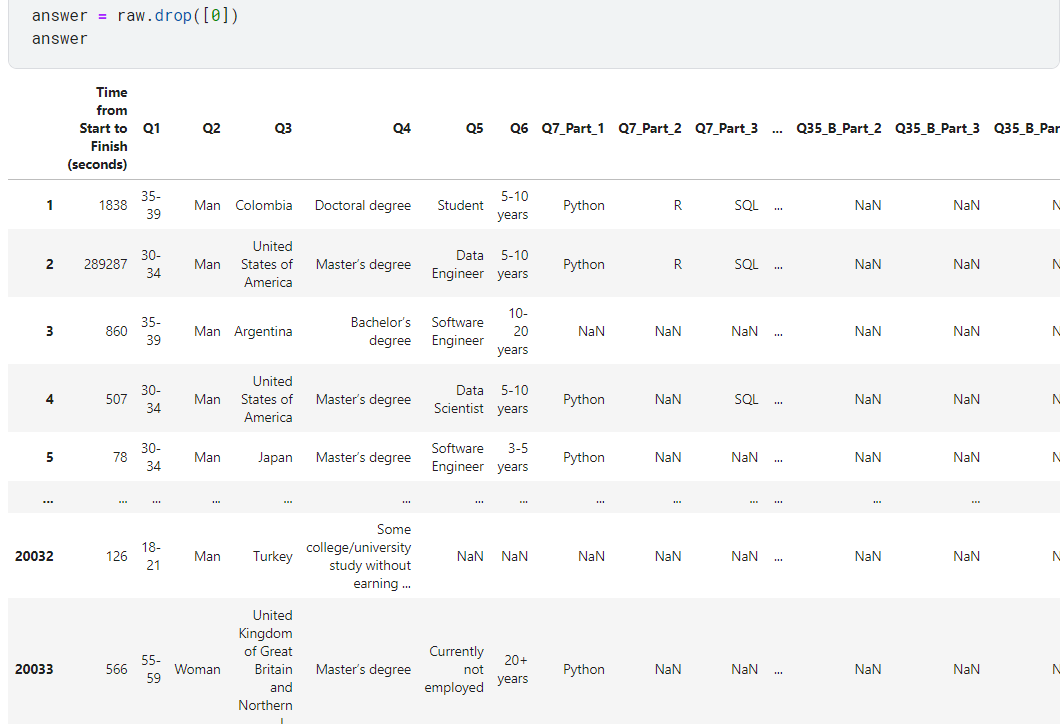
.info()로 정보 확인해보니, object 데이터 355개라는 걸 알 수 있음.
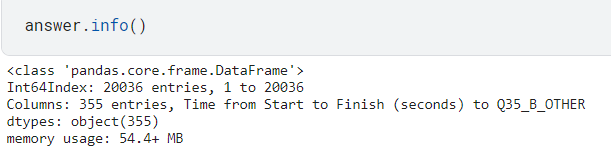
🅰️ 단일 질문 데이터 파악
.value_counts()를 쓰면 value별 빈도 수를 출력해줌.
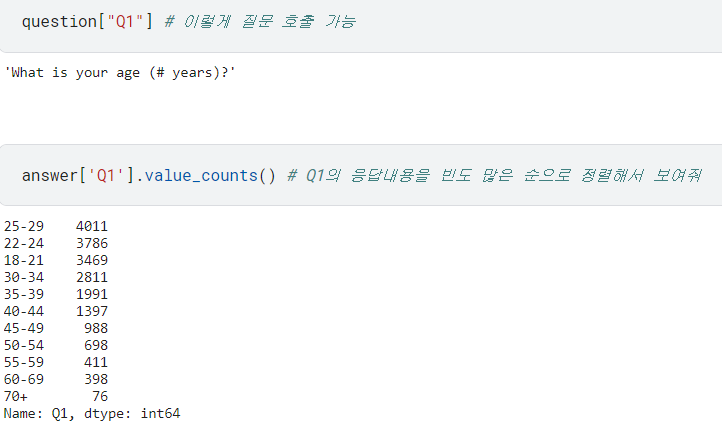
normalize=True: 빈도를 비율로 출력할 수 있음.
- 구한 빈도 뒤에
.plot()을 붙여서 바로 그래프로 볼 수 있음.
.sort_index(): 인덱스 기준으로 정렬함.
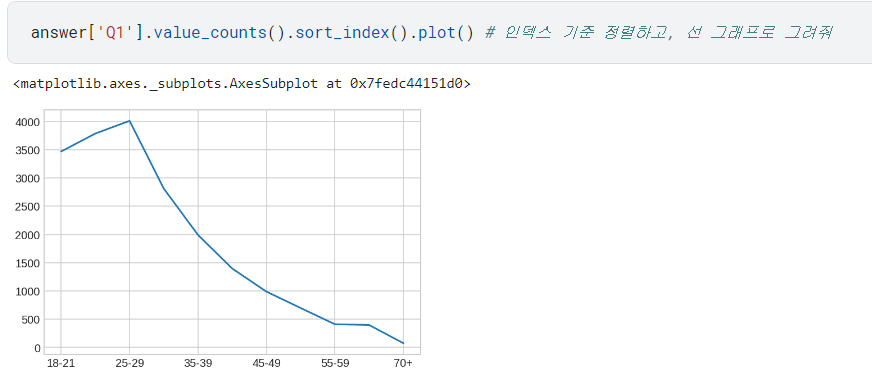
- 🆕 seaborn의 countplot으로 그려볼 수도 있음
sns.countplot(): data와 x값을 지정해주면 그릴 수 있음.
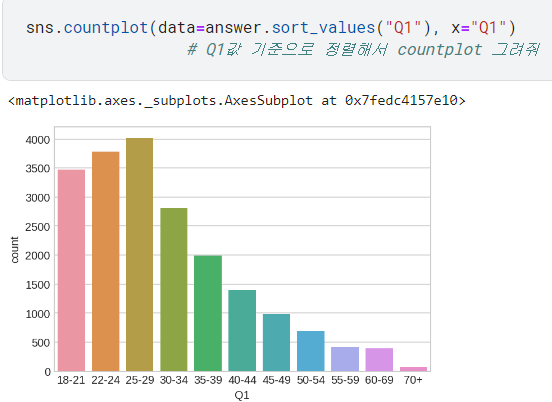
.set_title(): 제목 설정 /palette: 색상 테마 설정
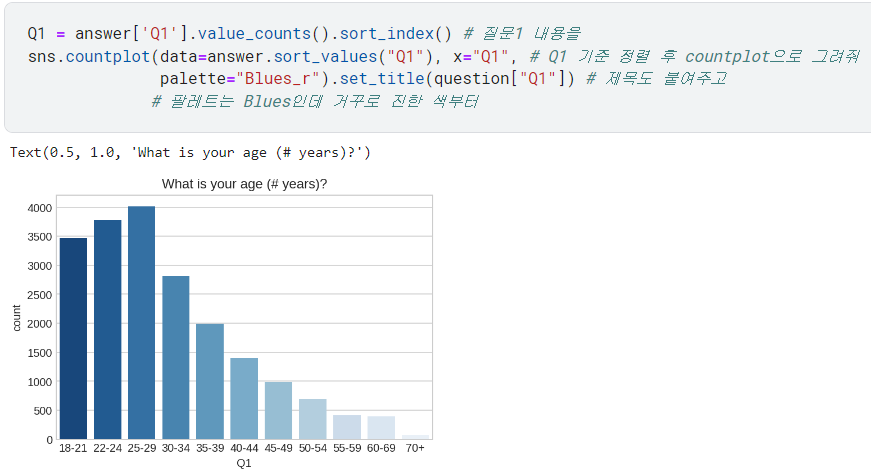
- 마찬가지로 질문2에 대한 내용도 시각화해 봄.
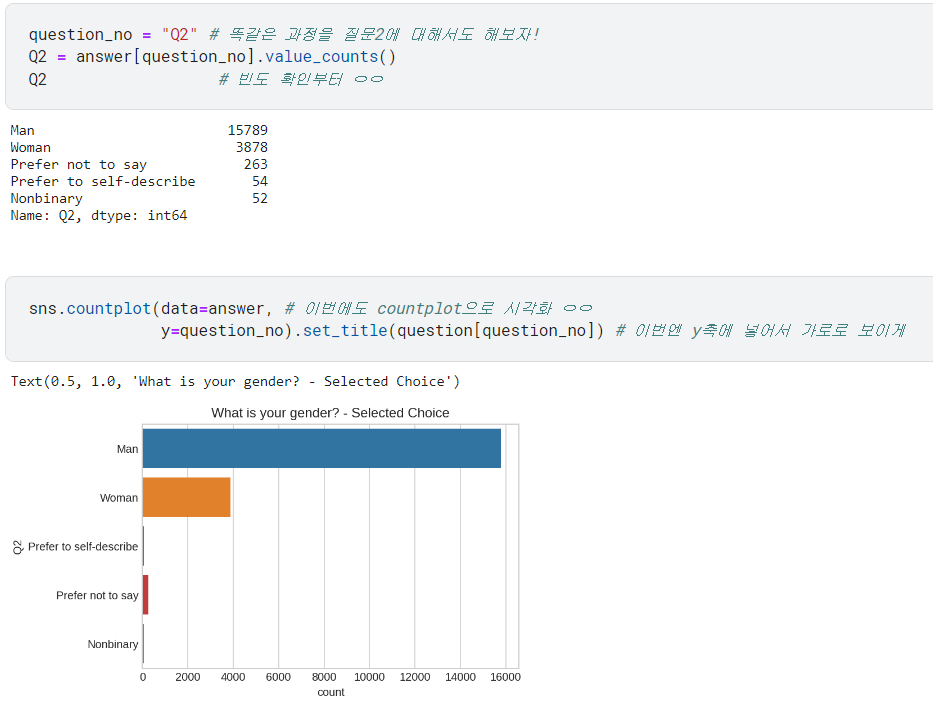
🅰️ countplot 그리는 함수 만들기
어차피 countplot 그리는 걸 반복해야 하니까 이걸 함수로 만들면 편하겠는걸?
show_countplot_by_qno: 질문 번호(qno)만 입력해주면 그 질문에 대한 countplot 그려주는 함수를 만듦.
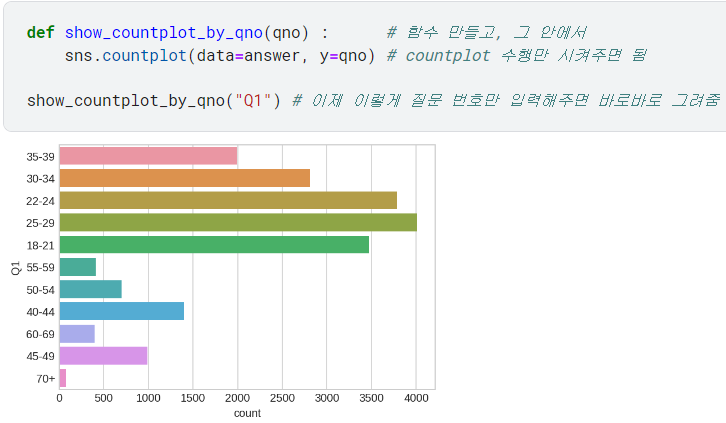
.set_title(),palette등의 세부설정을 추가함.fsize와order는 (전달 따로 안 했을 때 적용될) 기본값을 설정해둠❗
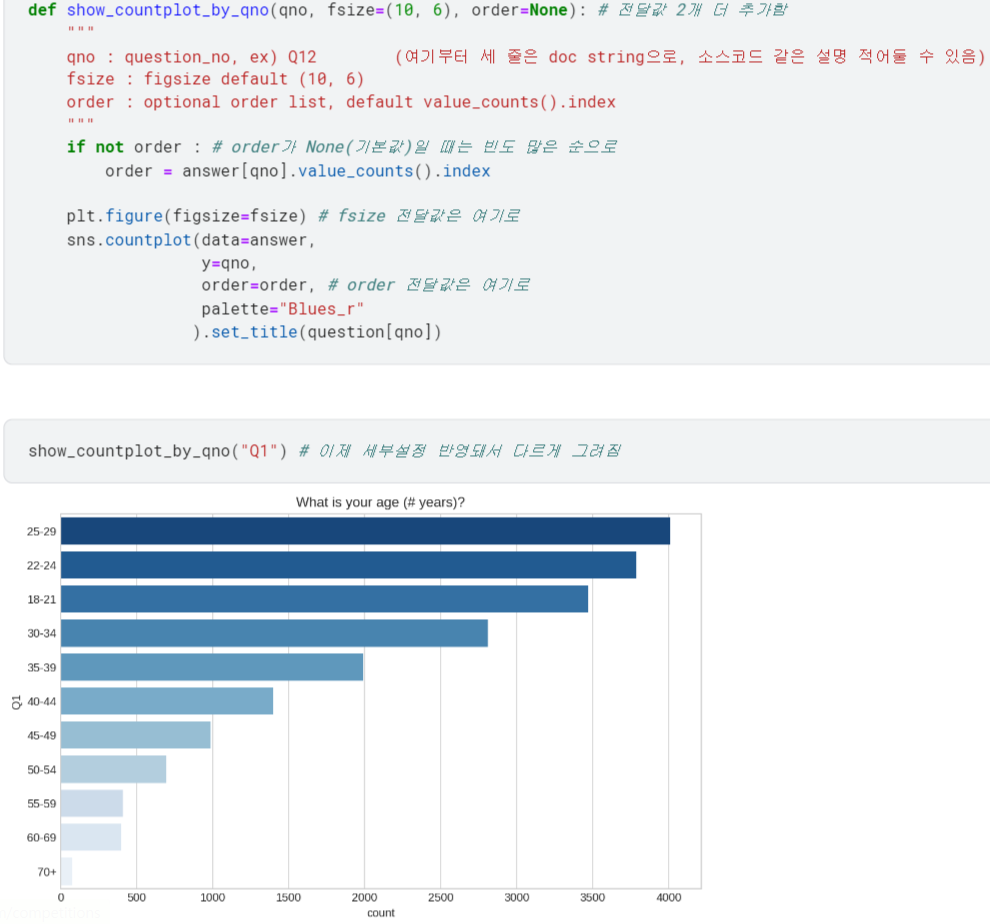
- ➕ 함수 만들 때 doc string(''' 사이에 적은 내용) 적어두면, 나중에
?로 호출했을 때 그 설명을 띄워줄 수 있음. - 당연히
fsize와order도 따로 전달값 넣으면 임의로 설정할 수 있음❗
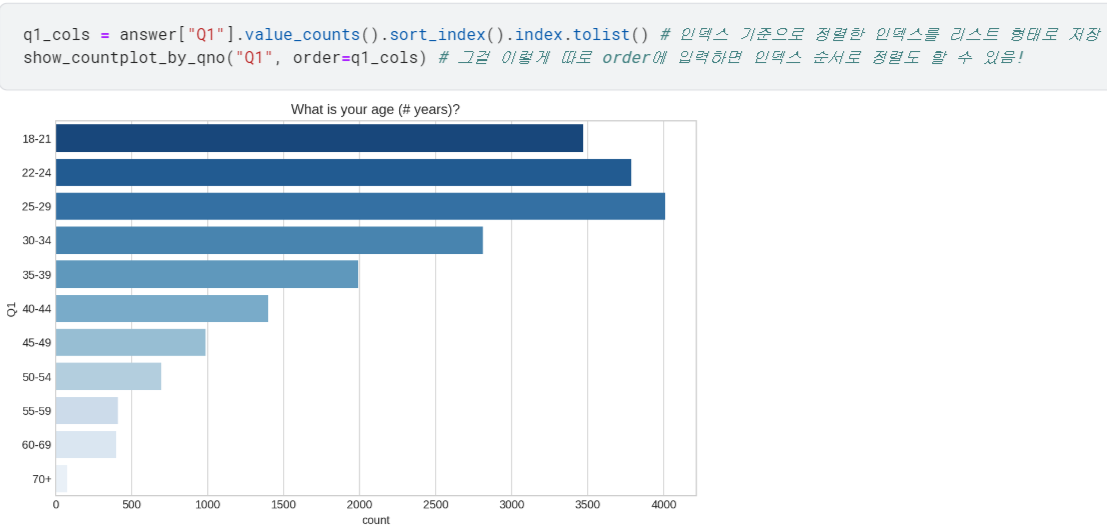
- 이제 Q1~Q6에 대해 어떤 응답이 제일 많았는지 확인할 수 있게 됨.
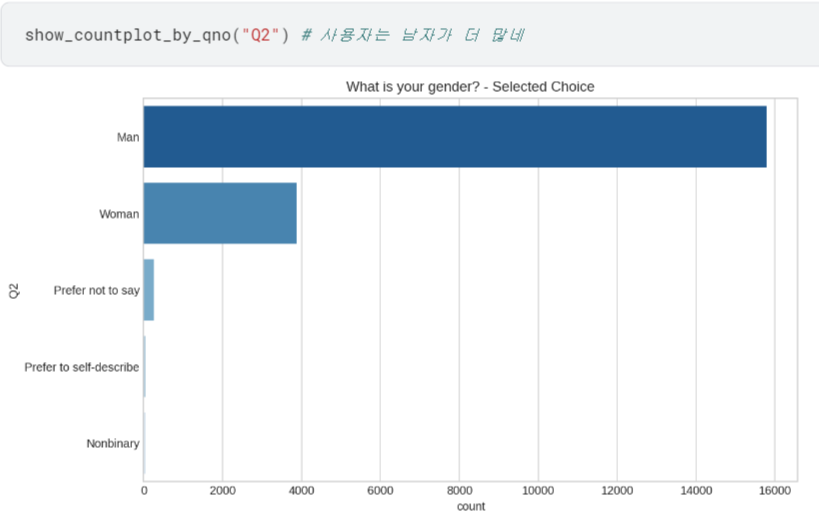
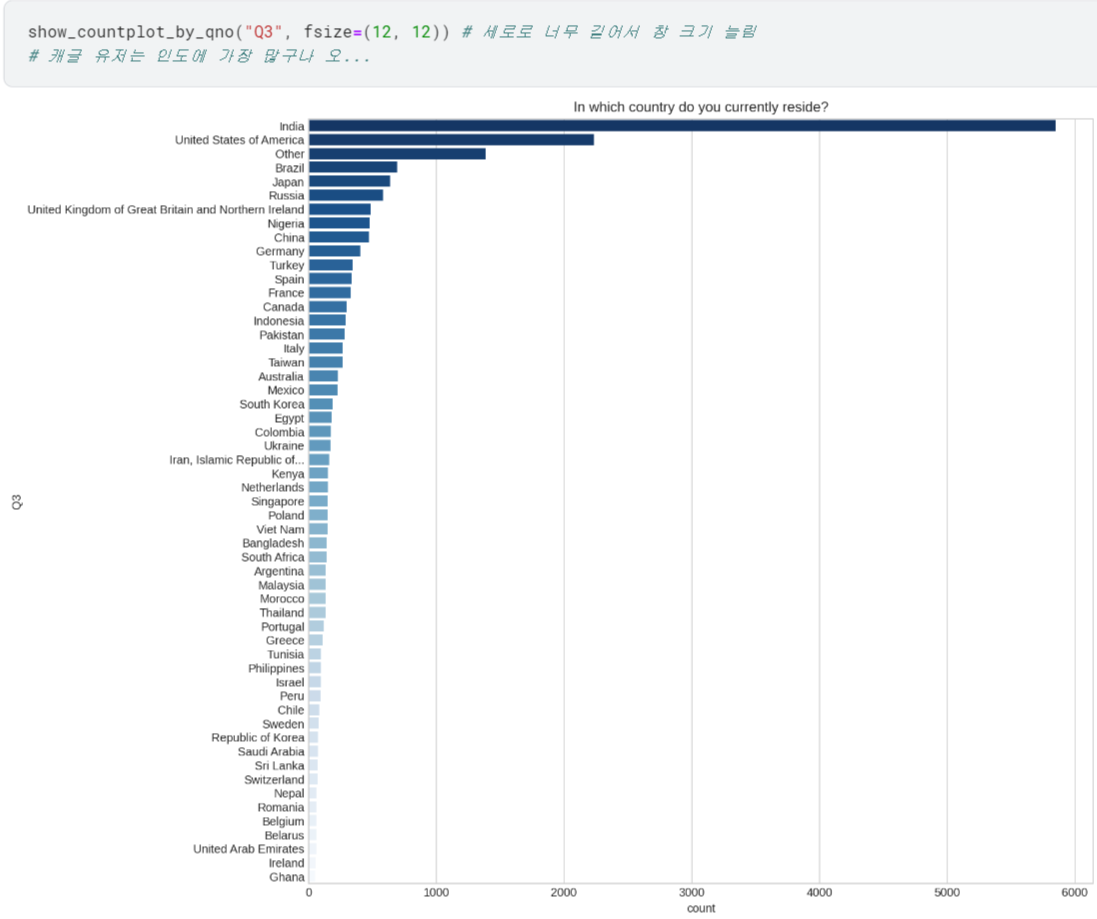
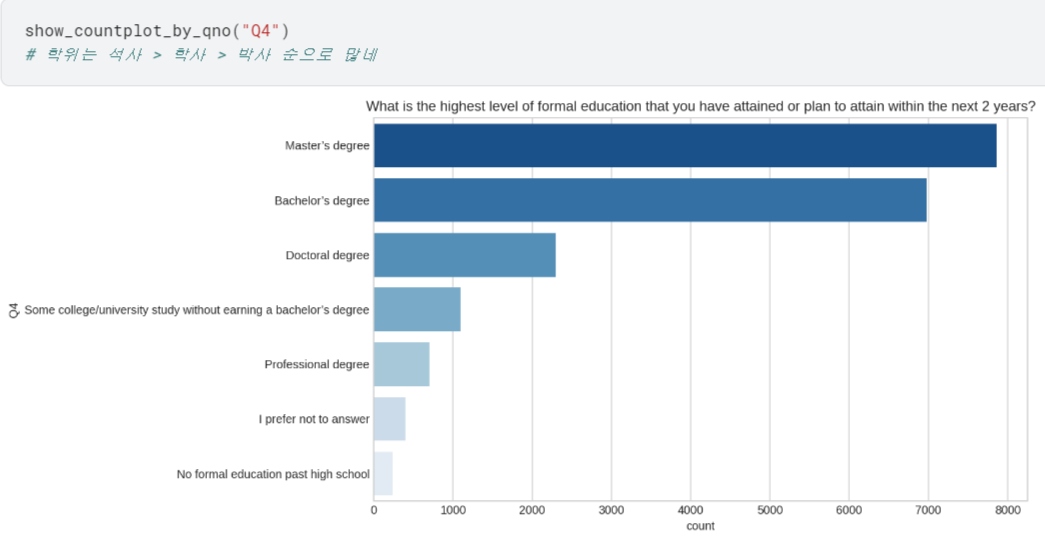
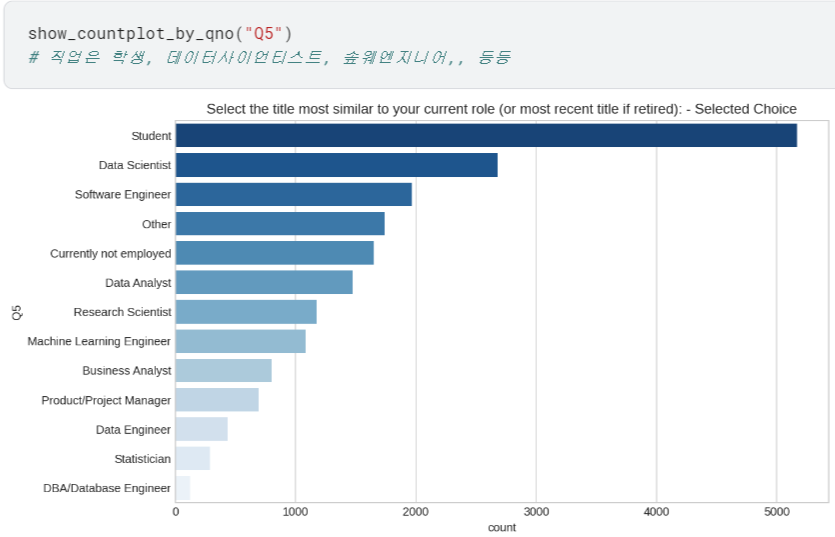
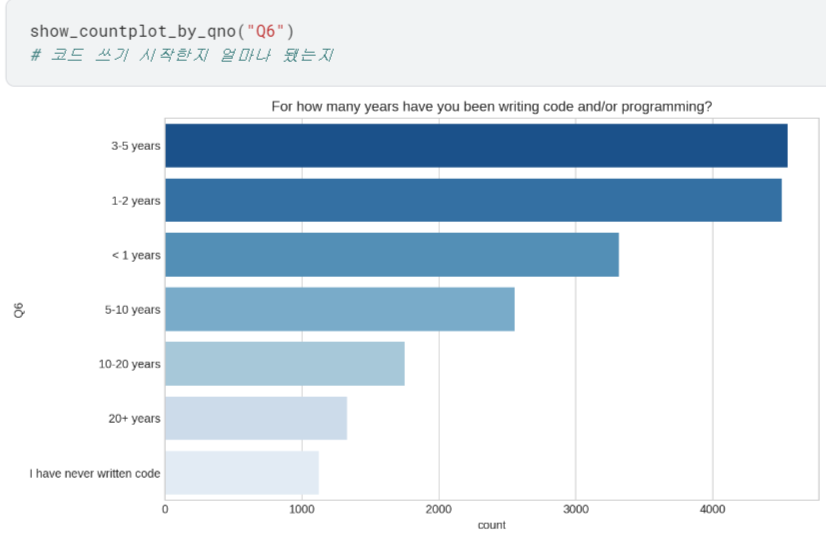
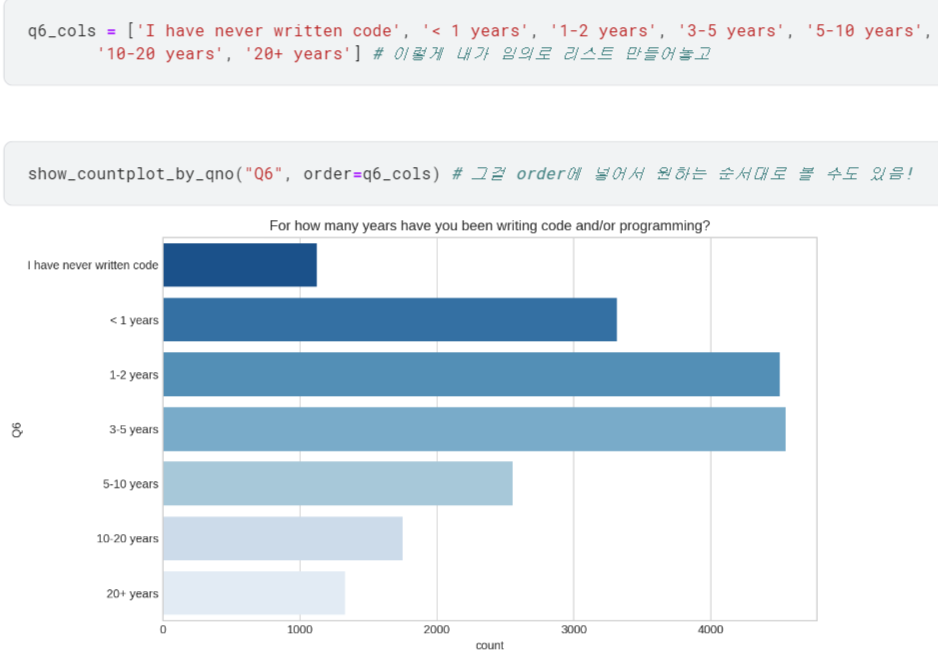 여기까지는 다 그냥 show_countplot_by_qno 함수로 간편하게 countplot 그릴 수 있었음.
여기까지는 다 그냥 show_countplot_by_qno 함수로 간편하게 countplot 그릴 수 있었음.
But, Q7부터는 복수선택형 질문이라서 위의 함수를 사용할 수 없음!
🅱️ 복수선택 질문 데이터 파악
Q7부터는 질문:답변=1:1이 아니라서 위에서 만든 함수 그대로 쓰면 오류 발생 ㅠ ..
- 사실 그래프 그리는 것뿐만 아니라, 애초에 데이터 출력하는 방식도 다르게 해야 함.
→ 판다스의.filter()⭐를 활용해 Q7에 대한 열을 가져옴! regex='Q7': 정규표현식(regular expression)으로 'Q7' 들어가는 건 다 가져오도록 함. 🆚그냥Q7만 넣으면 딱 'Q7'이라고 적힌 것만 가져와서 우리가 의도한 대로 안됨!!
질문 가져오기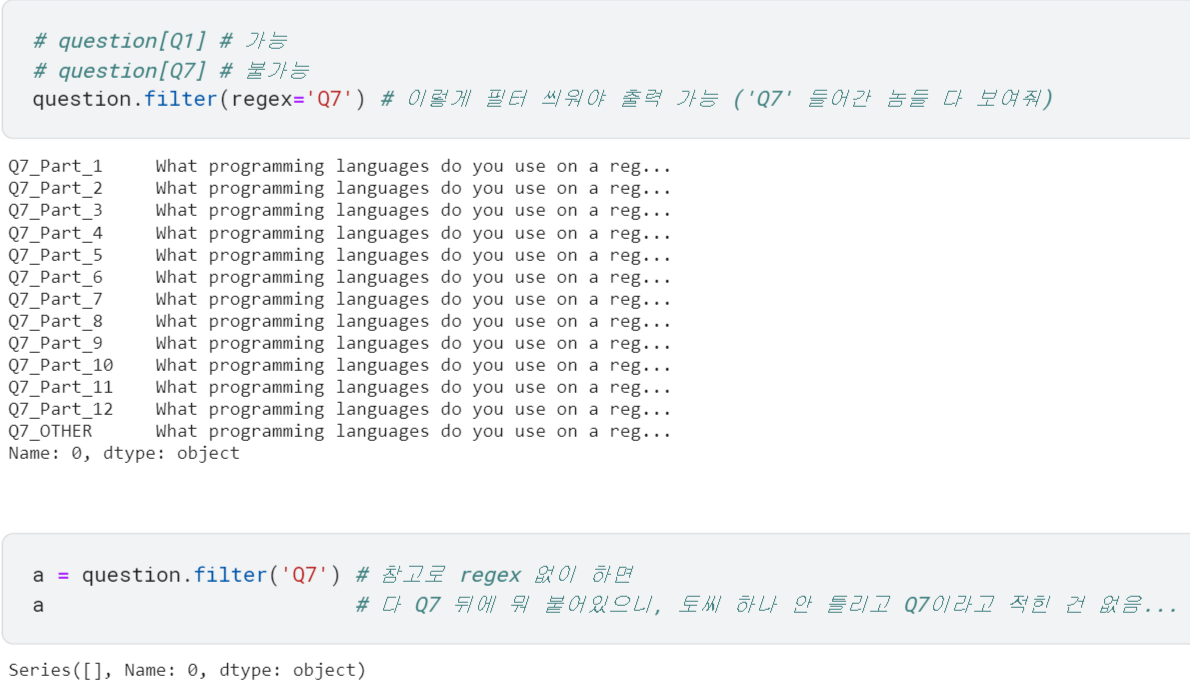
- 'Q7' 있는 것 중에 첫 번째 질문 가져옴 → 그 질문을
.split()으로 다시 쪼개고 그 중 첫 번째 조각 가져옴 = 최종 질문!
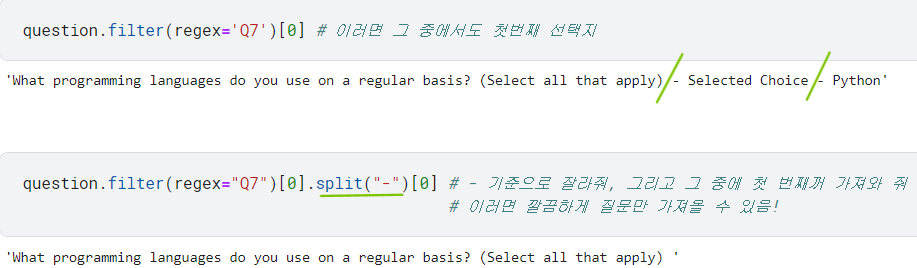
응답 가져오기
- 마찬가지로
.filter()와regex써서 Q7에 대한 열을 가져옴.
→ NaN 빼고 응답한 것들의 개수만 합치면 각 선택지의 빈도가 나옴.
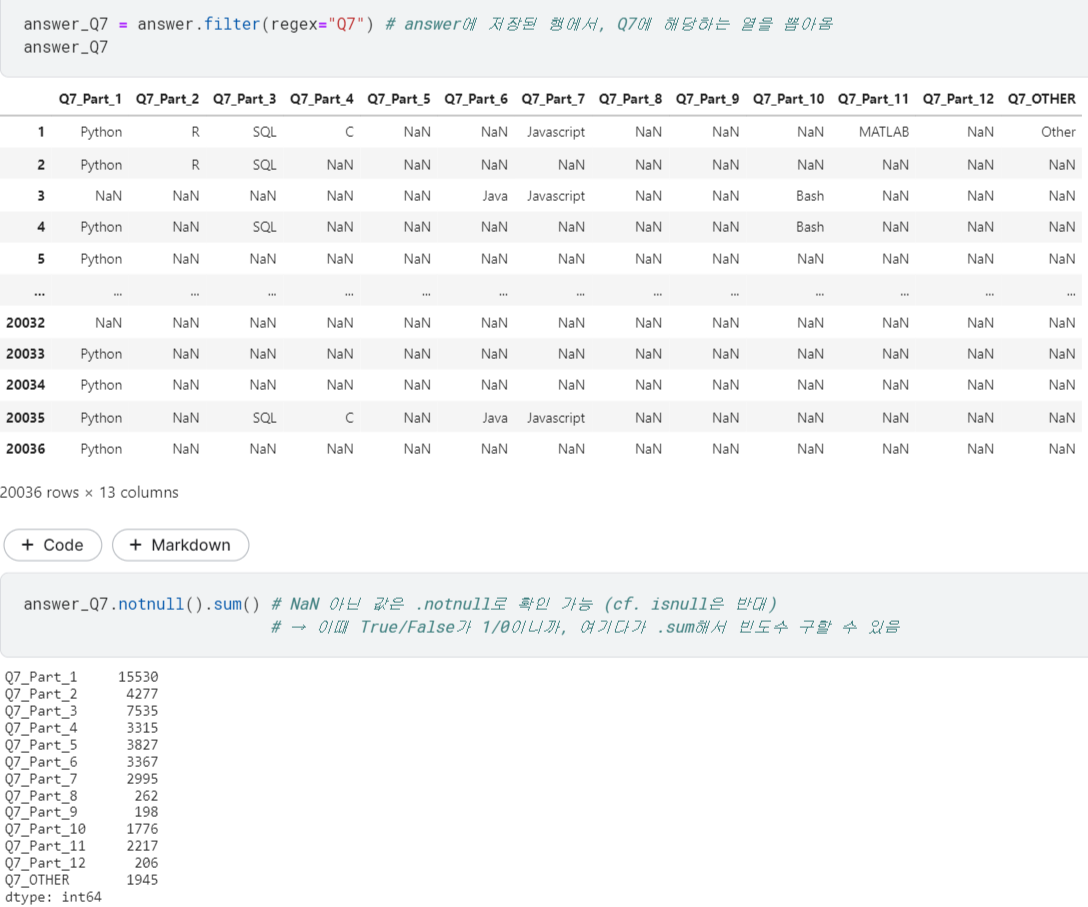
- 근데, 'Q7_Part_1'처럼 나오니까 뭐가 뭔지 안 보임. 구체적인 응답 내용도 같이 보고싶음.
→.describe(): 기술통계치를 보여줌 (top : 최빈값 / freq : top값의 빈도수) →.set_index()로 top 값을 인덱스로 만들면, 그게 곧 응답 내용!
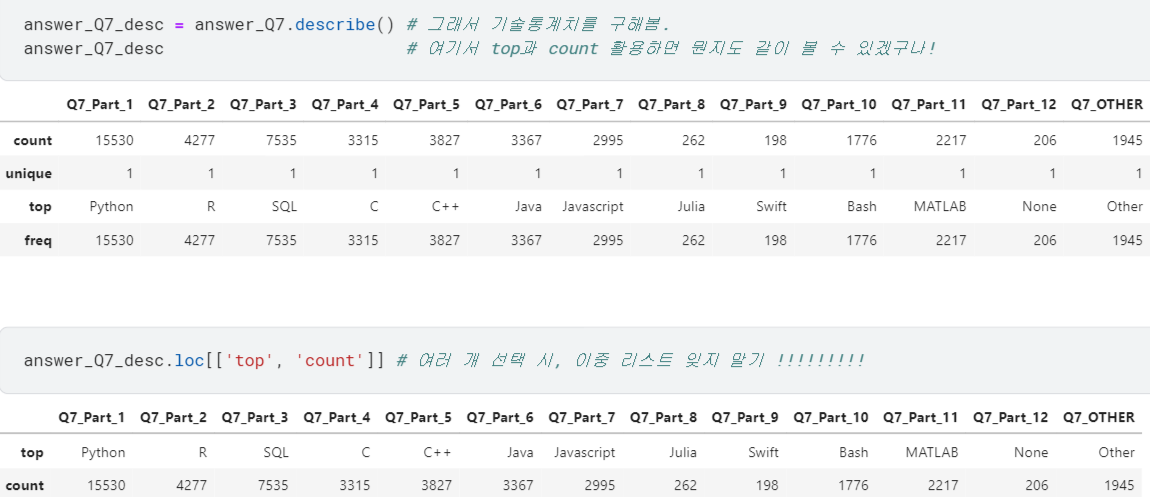
.sort_values(): 원하는 값을 기준으로 정렬할 수 있음. (➕이렇게 출력한 빈도값에 그대로.plot()붙여서 그래프로 볼 수도 있음)
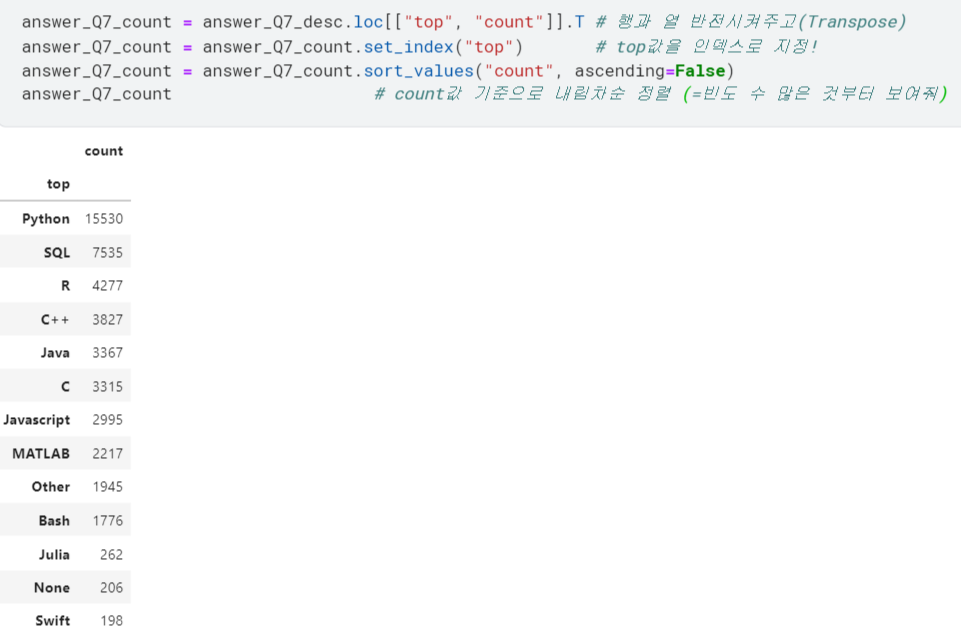
barplot으로 그려보기
- 위에서 구한 결과값(Q7에 대한 응답)은, 형태가 달라서 countplot으로 그릴 수 없음... (🆚countplot은 흩어져있는 각 값들의 빈도 수를 구해주는 건데, 우리는 이미 각 응답 별로 빈도를 직접 구해놨고 이걸 시각화하고 싶은 거임)
- 그래서
sns.barplot()으로 막대그래프 그림. (역시 색상, 제목 등 옵션 설정 가능)
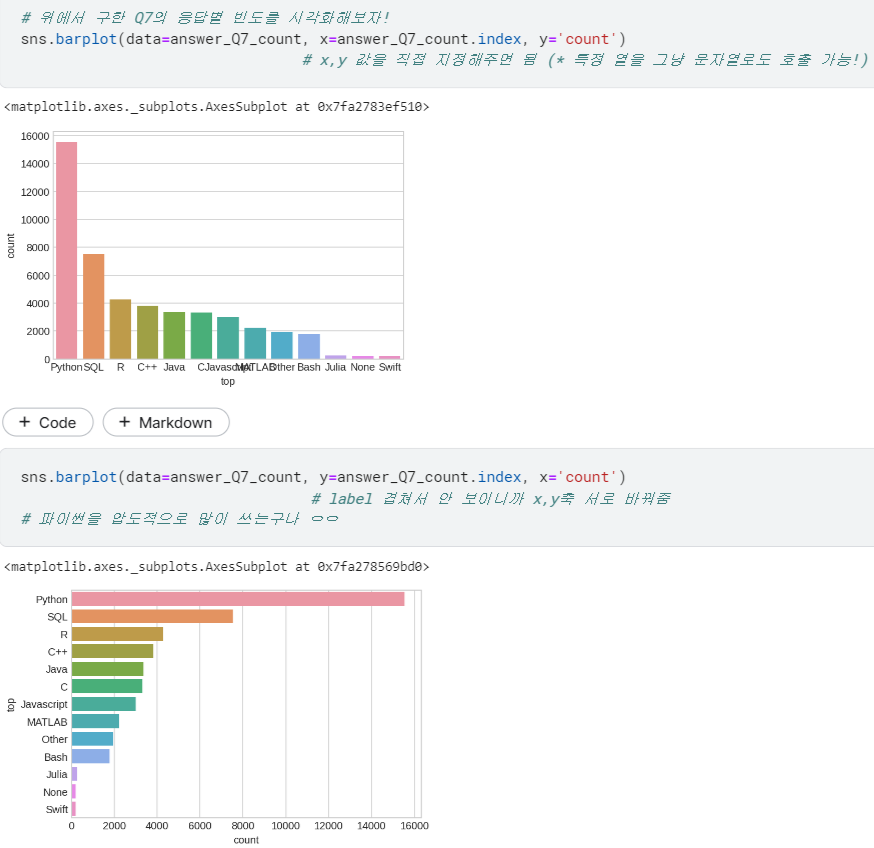 자 그럼, 이렇게 복수선택형 질문(Q7~)에 대해서도 시각화 할 줄 알게 되었다! 그렇다면 (countplot처럼) 얘도 함수로 만들어 볼까? ㅎㅎ
자 그럼, 이렇게 복수선택형 질문(Q7~)에 대해서도 시각화 할 줄 알게 되었다! 그렇다면 (countplot처럼) 얘도 함수로 만들어 볼까? ㅎㅎ
🅱️ barplot 그리는 함수 만들기
방금 위에서 한 과정에 모두 함수를 적용해보자
질문 출력하는 함수
- 단일 질문 & 복수선택형 질문, 2가지 경우를 나눠서 함수로 구현함.
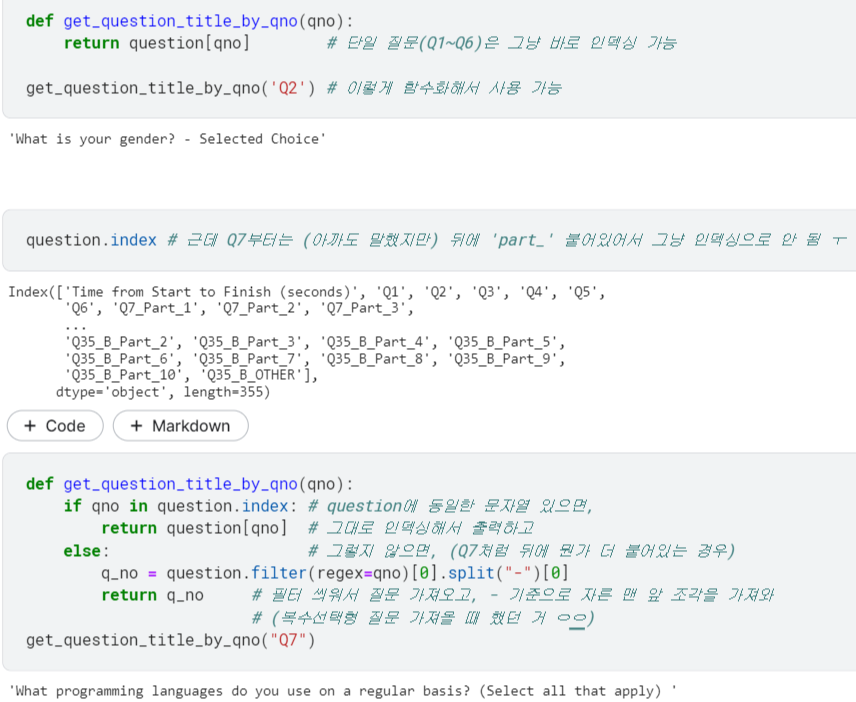
응답 출력하는 함수
- <응답 가져오기>에서 했듯이, describe로 빈도랑 내용 구하고 Transpose 한 뒤에 정렬했던 걸 그대로 함수로 구현함.
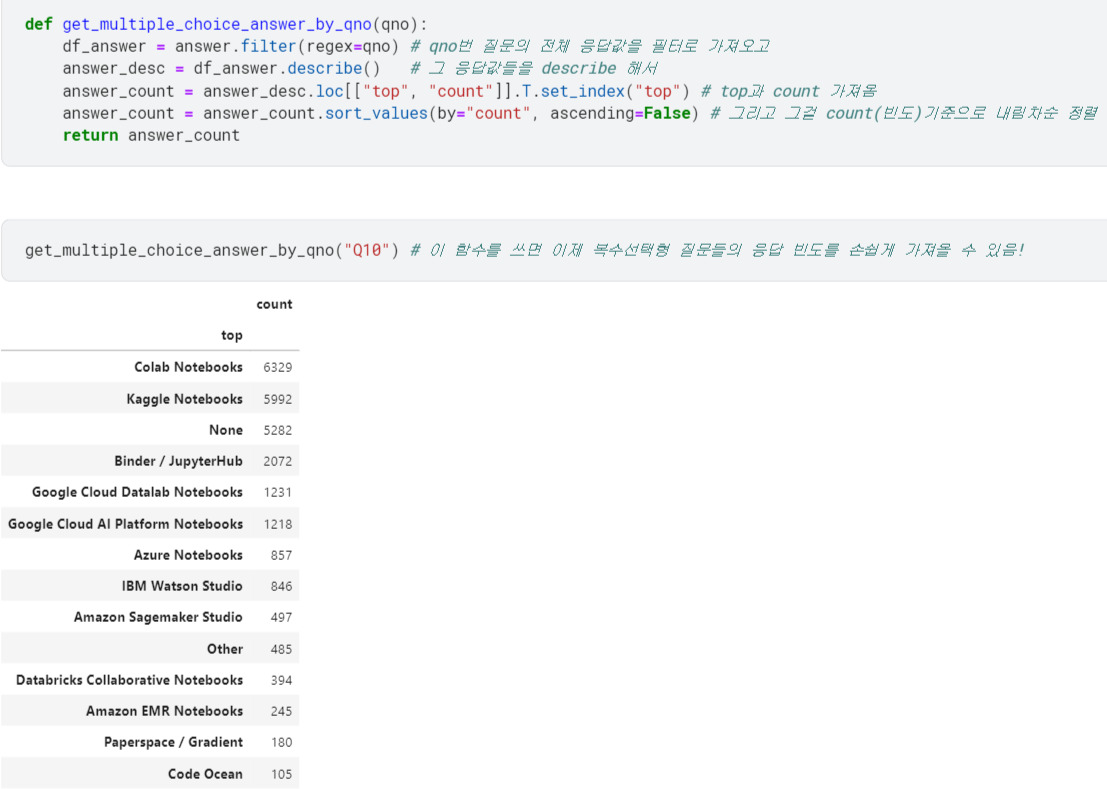
barplot 그리는 함수
show_multiple_choice_bar_plot_by_qno: 이것도 역시 위 <barplot으로 그려보기>에서 했던 내용 그대로 가져와서 함수로 구현함.
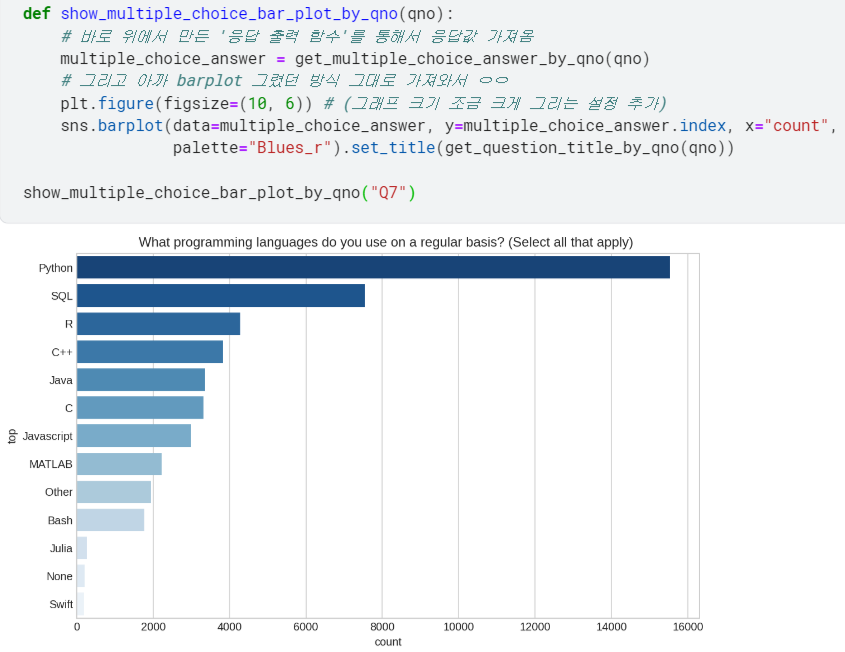
- 이제 복수선택형 질문도, 그냥 질문 번호(ex.'Q7')만 입력하면 바로 시각화할 수 있게 됨!
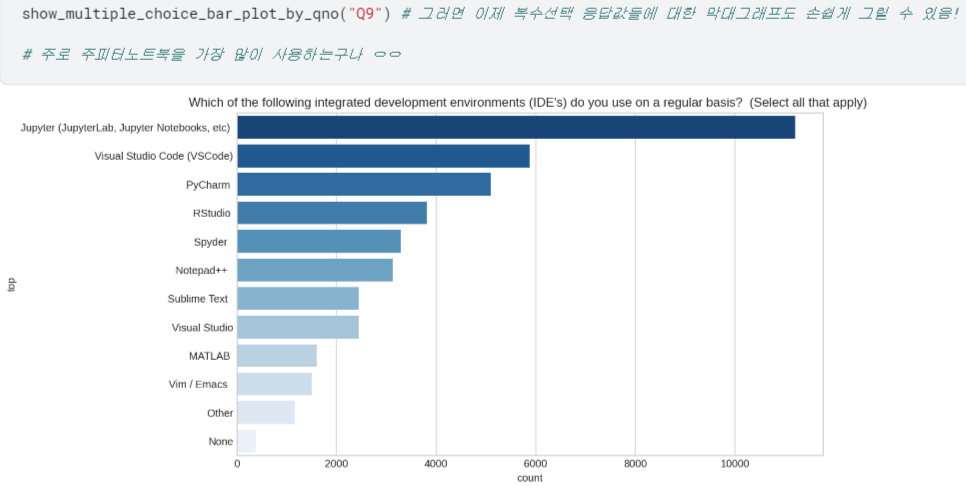
🆎 시각화 함수 통합
- 단일 질문 & 복수선택형 질문의 경우를 매번 귀찮게 구분하지 말고,
아예 통합된 함수를 만들어 버리자!
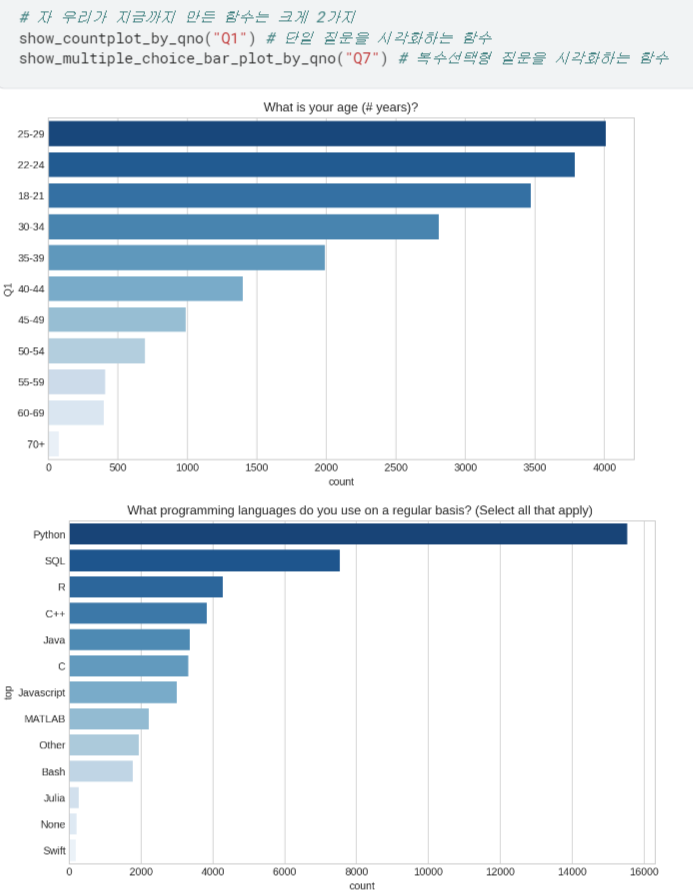
- 앞에서 만든 두 개의 함수를
show_plot_by_qno로 통합해버림.
- 이제 질문 유형 신경 쓰지 않고 그냥 질문 번호만 넣어도 시각화할 수 있게 됨!
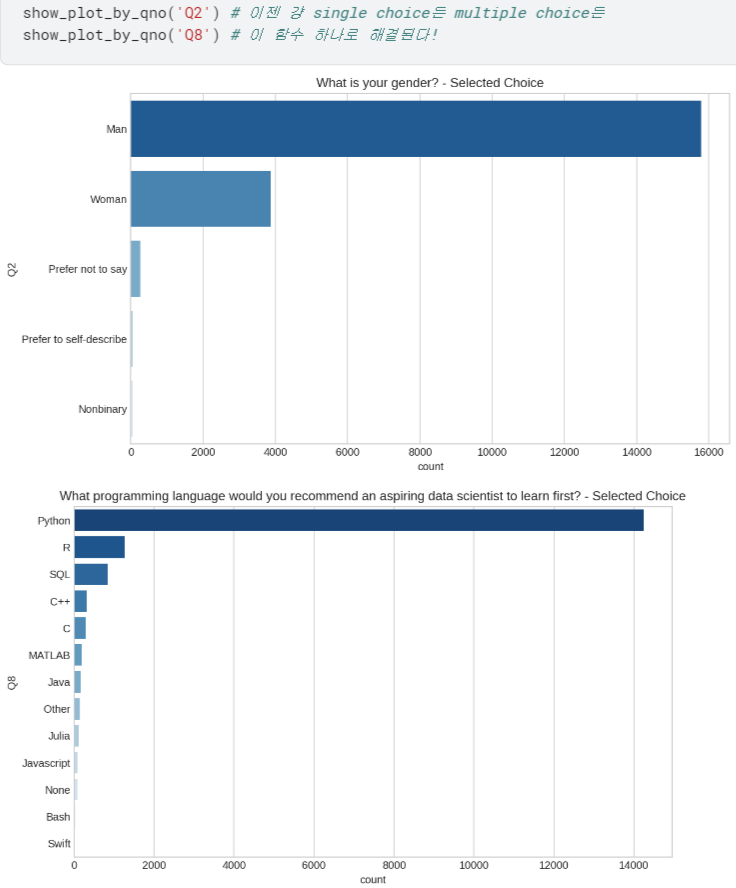
- Q8 ~ Q23 시각화하여 살펴보기
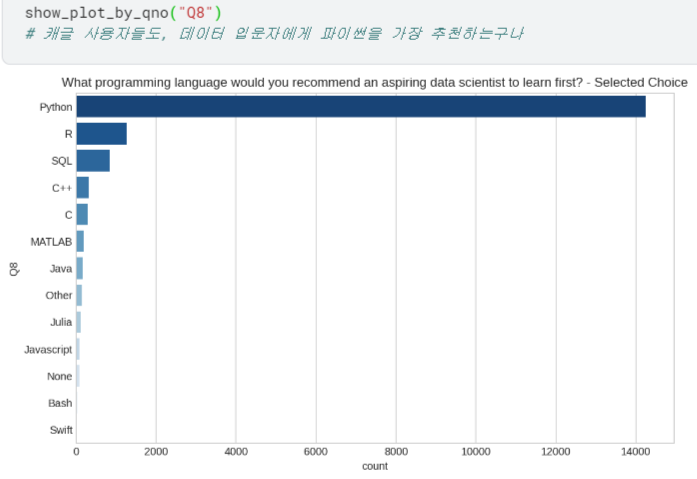
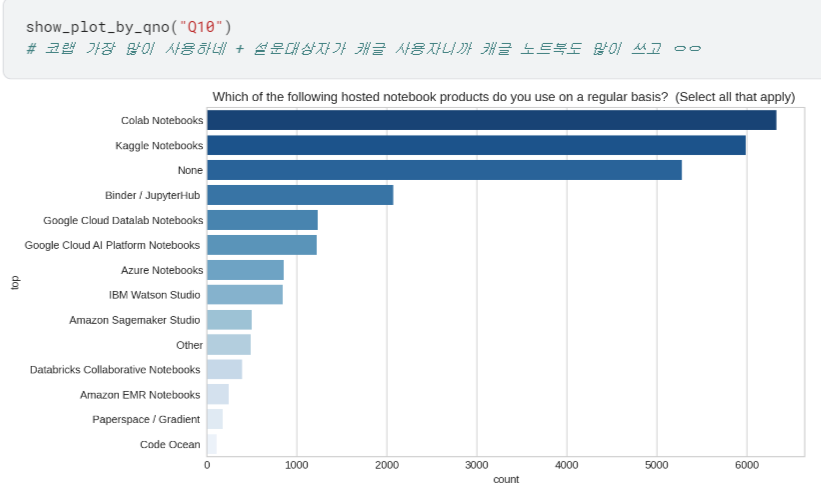
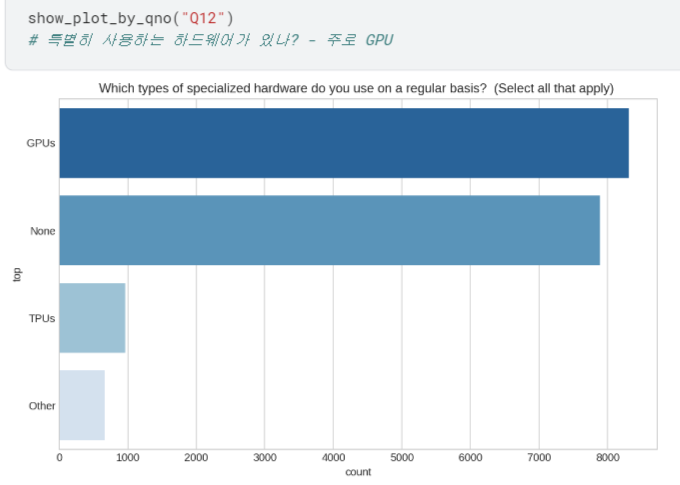
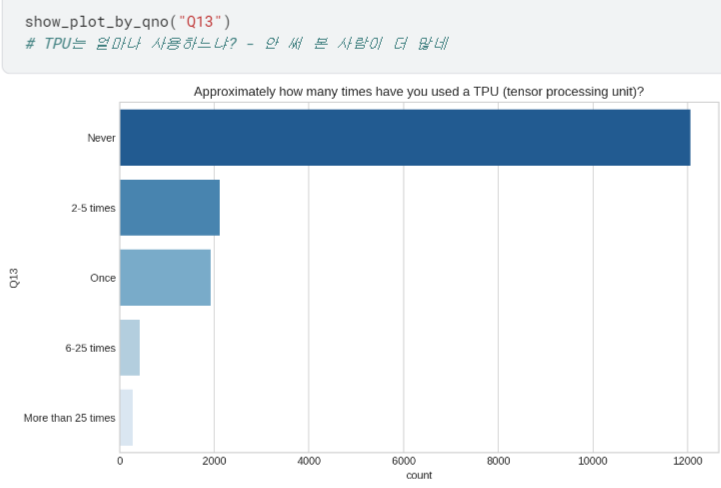
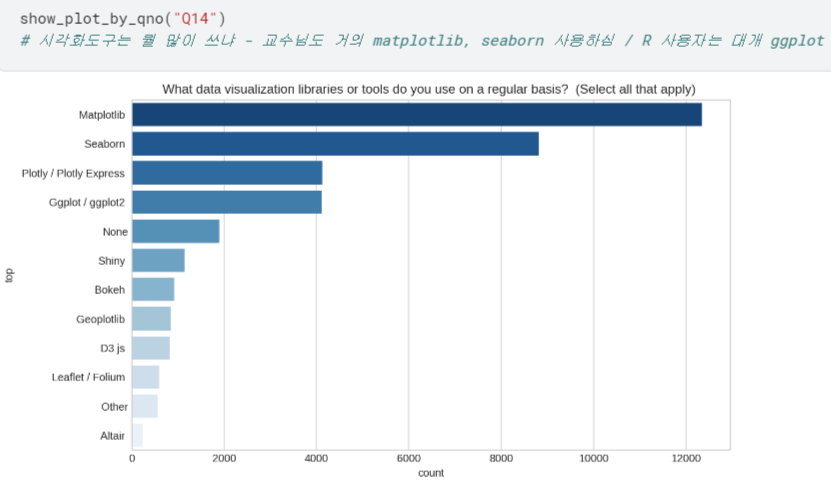
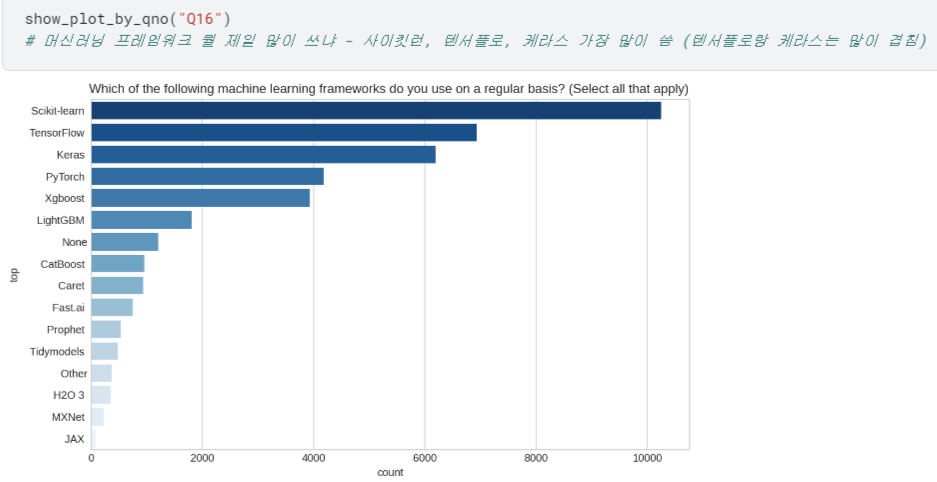
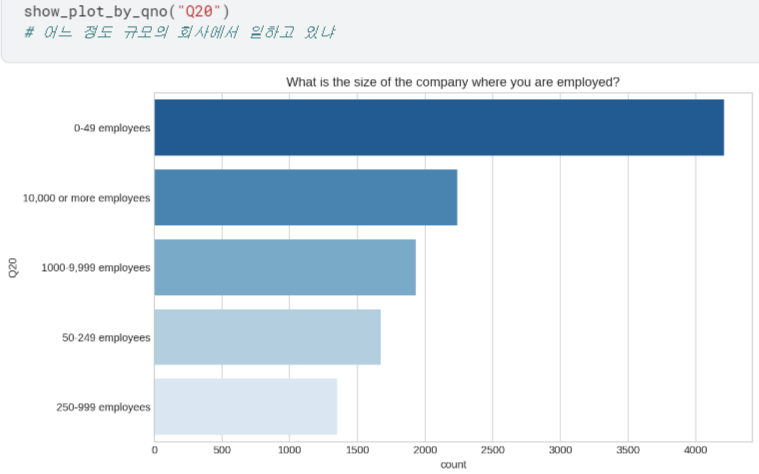
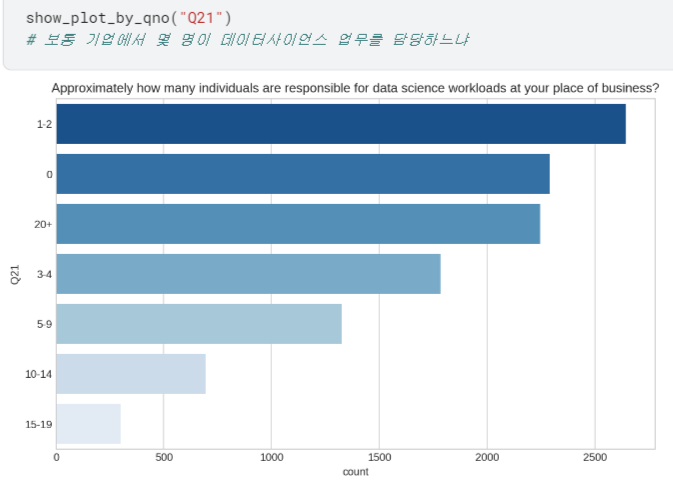 등등 ,, 너무 길어져서 자세한 내용은 캐글에서 확인..!
등등 ,, 너무 길어져서 자세한 내용은 캐글에서 확인..!
Kaggle Survey 분석 (Lv.2)
한 발 더 나아가, 이제는 두 질문을 엮어서 보는 방법에 대해 알아보자.
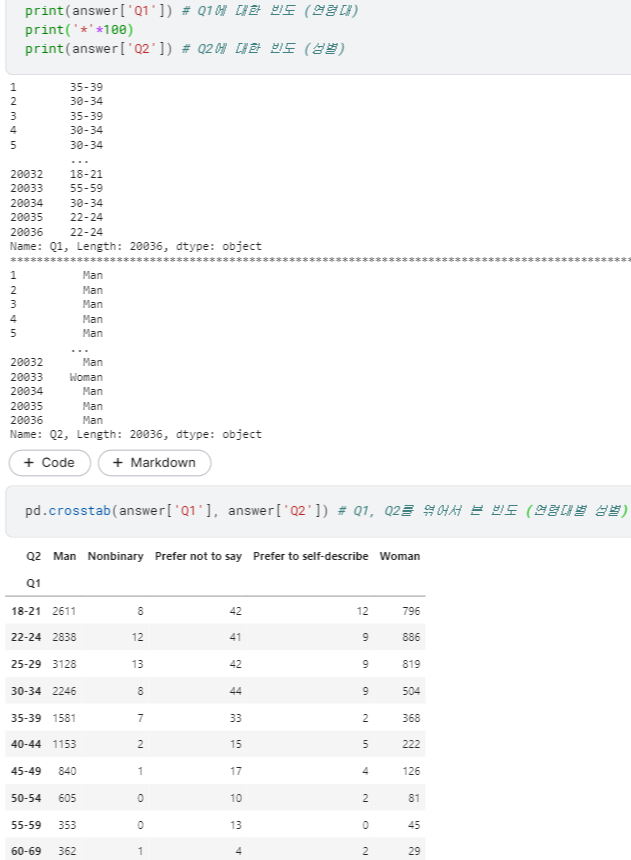
ex) 연령에 대한 응답(Q1)을 성별(Q2)에 따라 나눠서 보고 싶어!
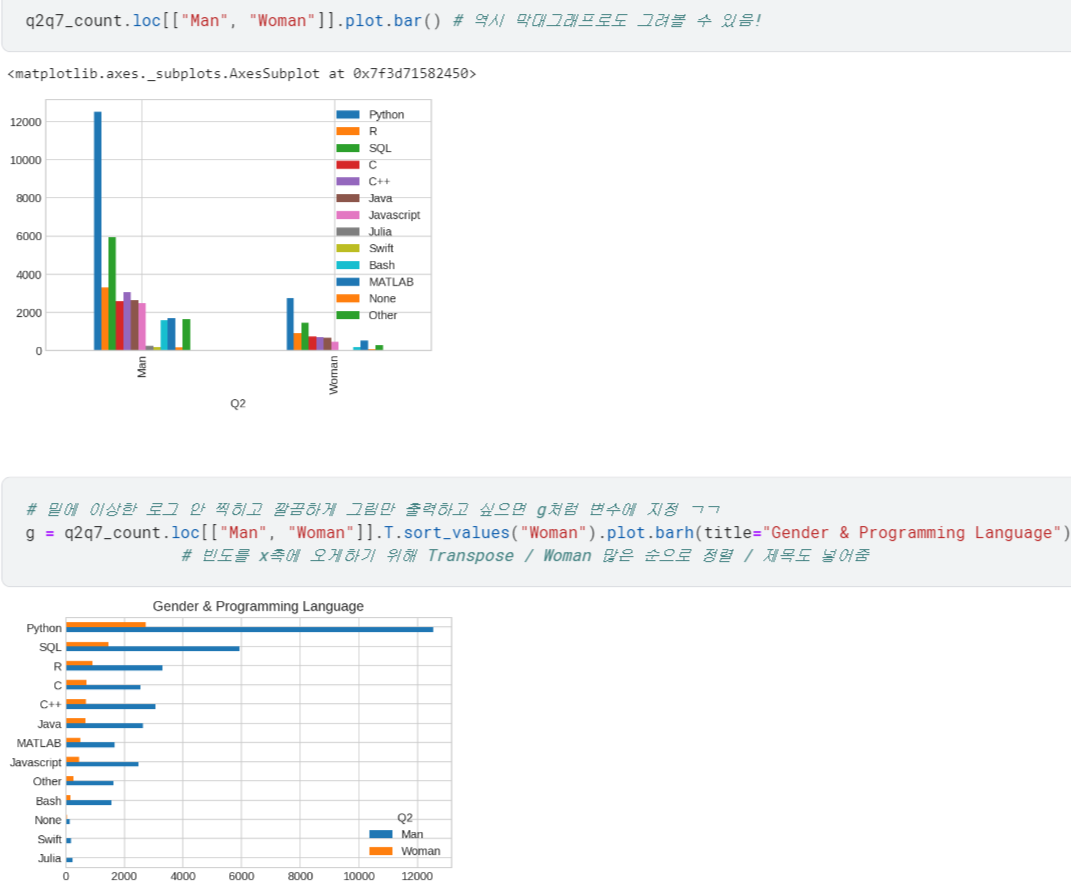
단일 질문 교차빈도
- 두 질문을 엮어서 시각화하고 싶다면, 당연히 두 질문의 빈도부터 엮어서 구해야 함.
- ⭐
pd.crosstab(항목1, 항목2): 두 질문의 빈도를 함께 보는 교차빈도표 출력함.
- 교차빈도표에서 원하는 컬럼만 뽑아볼 수도 있고, 바로 그래프를 그려볼 수도 있음.
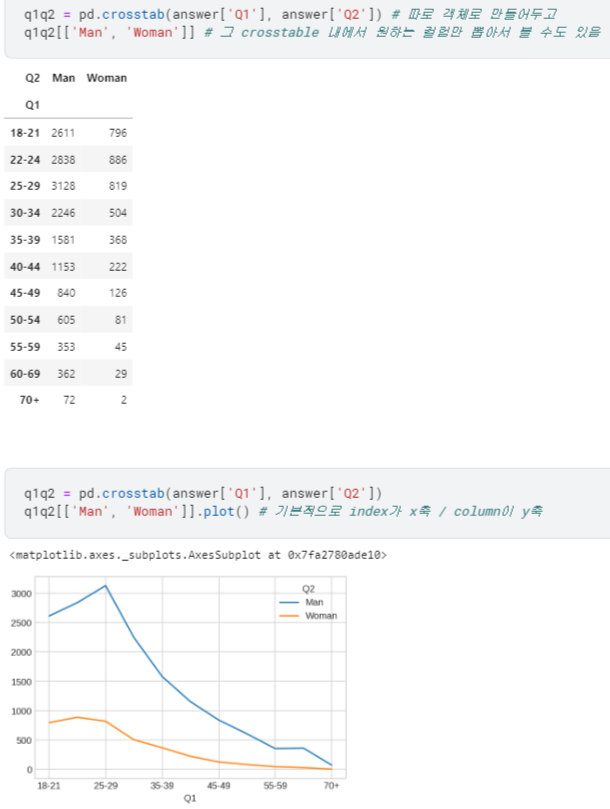
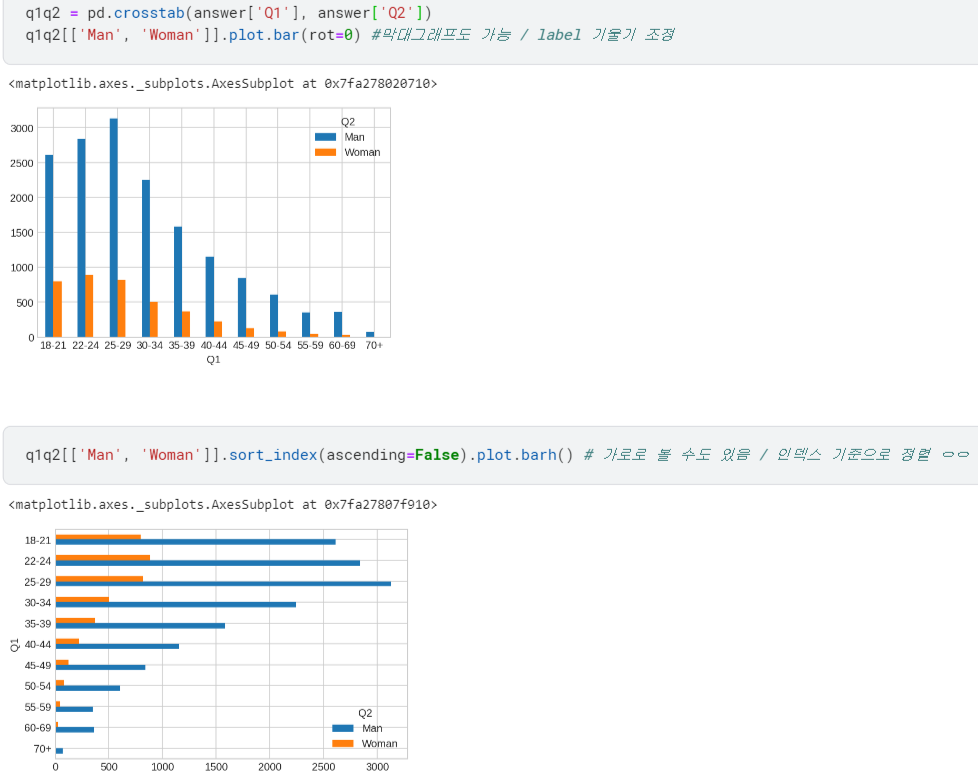
- 막대그래프는 Pandas의
.plot.bar()사용 /rot는 label 각도 회전 설정 - 가로로 보려면
.plot.barh()사용
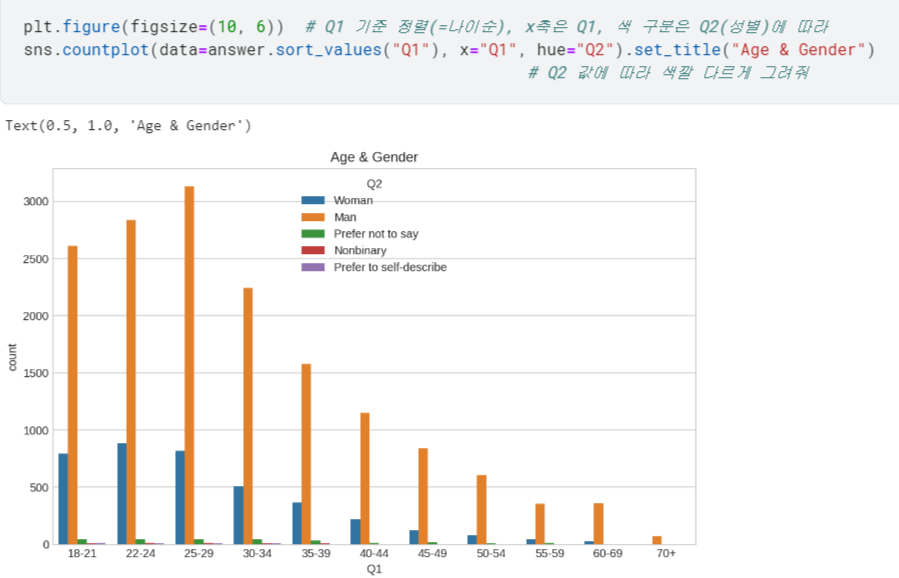
- Seaborn으로 그려볼 수도 있음 =
.countplot()
hue: 지정한 카테고리 값에 따라 색을 다르게 지정할 수 있음.
복수선택형 질문 교차빈도
- 복수선택형 질문의 경우 countplot 못 그렸듯이, 이것도
.crosstab()사용 불가...
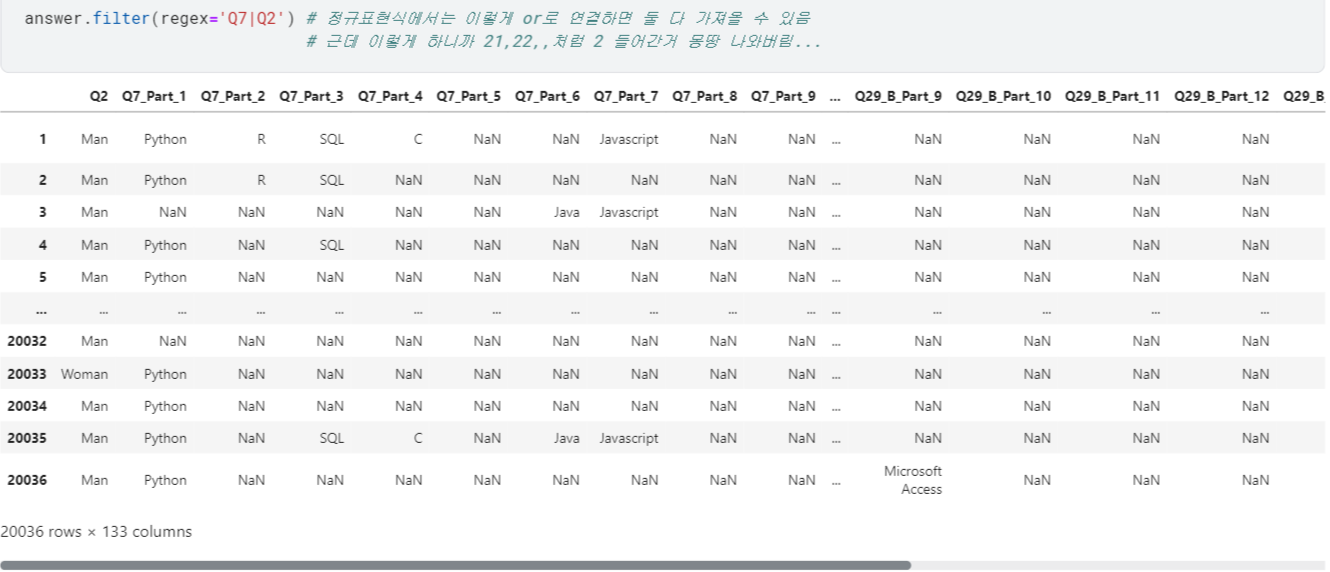
- 불러오는 건 이번에도
.filter()활용 +regex에서|(or)로 두 질문 함께 출력 가능! $: 입력한 문자로 끝나는 것만 가져옴. /^: 입력한 문자로 시작하는 것만 가져옴.
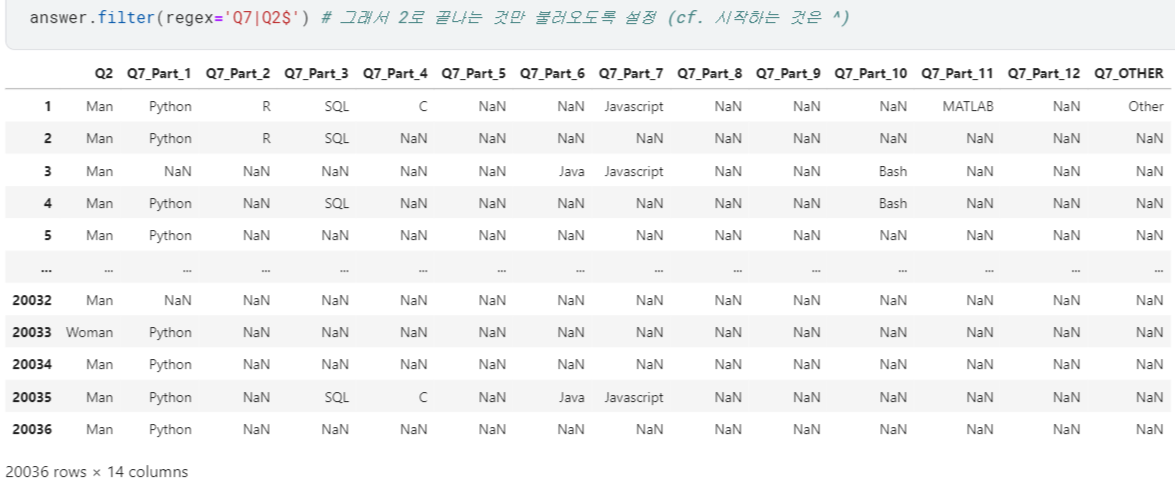
- 근데 출력한 값들의 빈도를
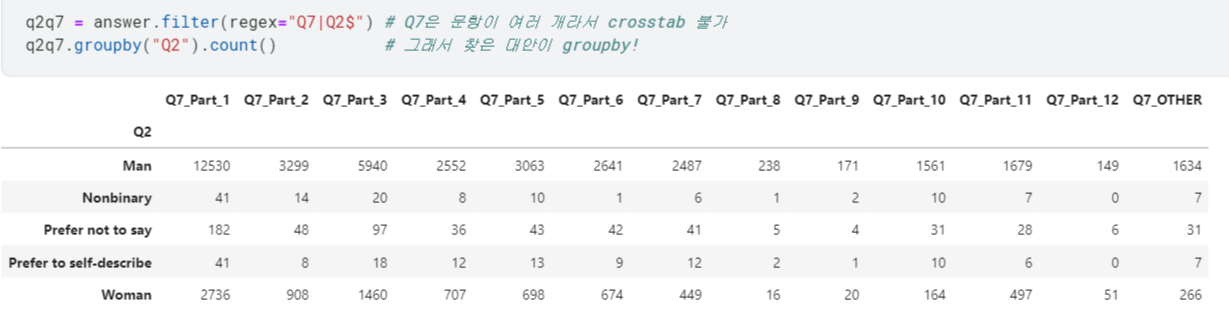
crosstab으로 구할 수 없음. - 대안은
.groupby()⭐ → 'Q2' 기준으로 그룹화하고,.count()로 빈도 수 구함!
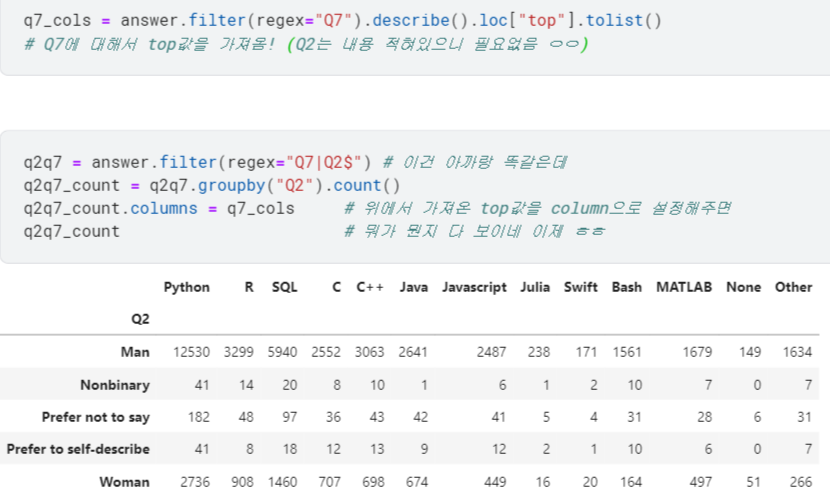
- 각 열의 구체적인 내용 보기 위해, 이전처럼
.describe()활용해서 top값 가져옴.
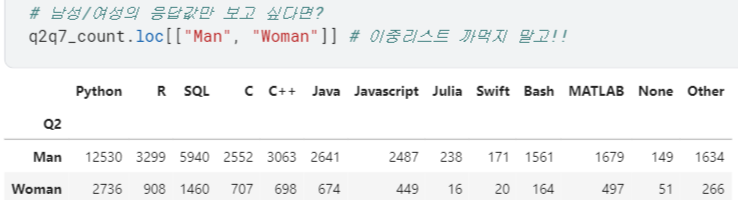
- 역시
.plot.bar(),.plot.barh()등으로 시각화 가능함!
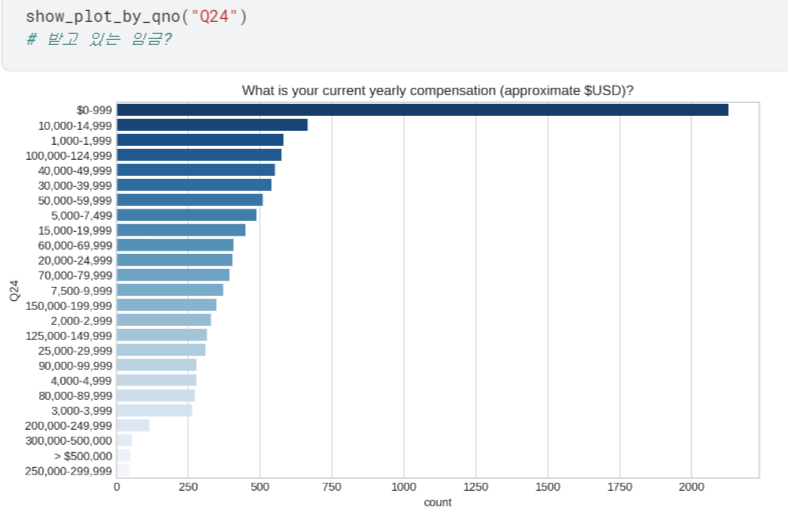
Kaggle Survey 분석 (Lv.3)
임금 많은 순으로 정렬하기
- 24번 질문을 들여다보면, value값들이 봉급의 범위로 찍혀있음.
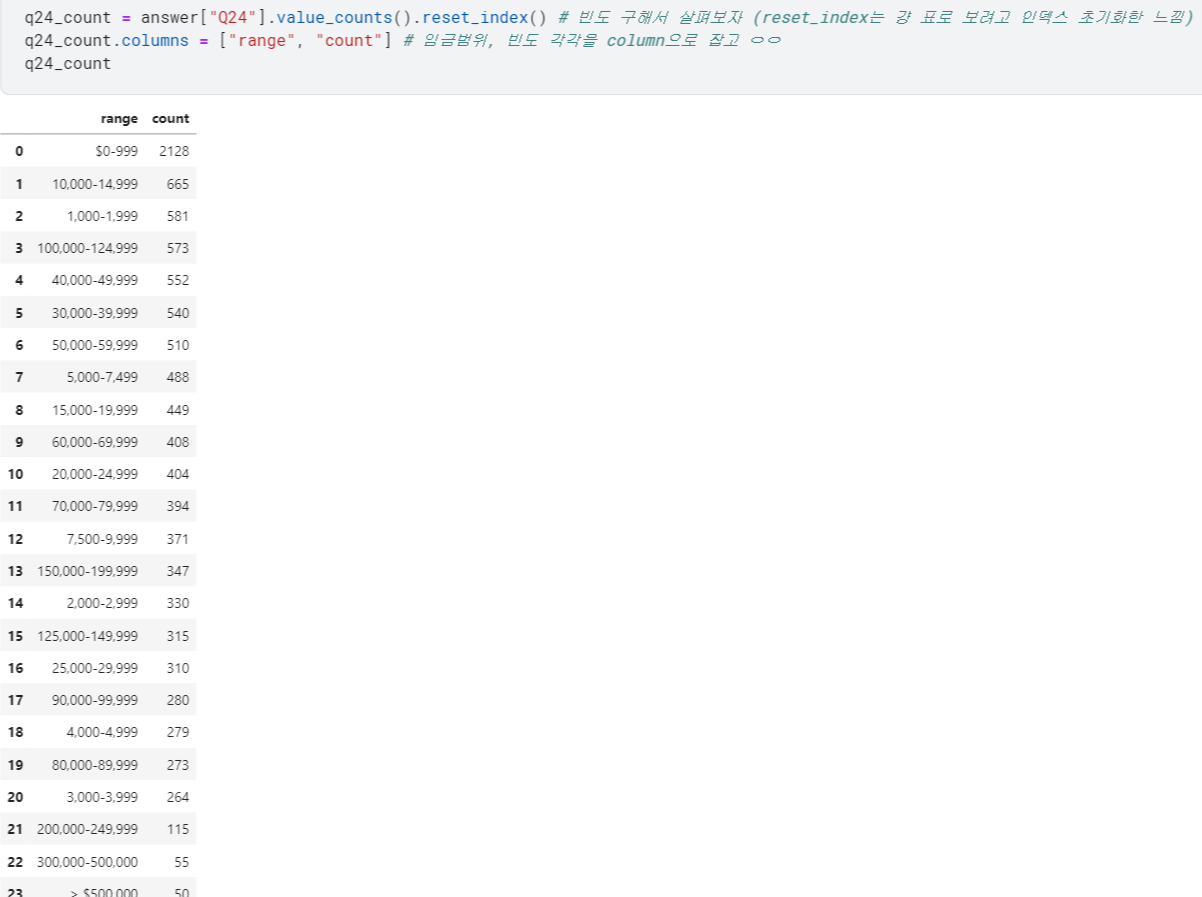
- ※ 이런 경우, 우리가 기존에 하던 대로 그냥
.sort_values()로 정렬하려고 하면
의도와 달리 이상한 결과를 낳을 수 있음 ;;
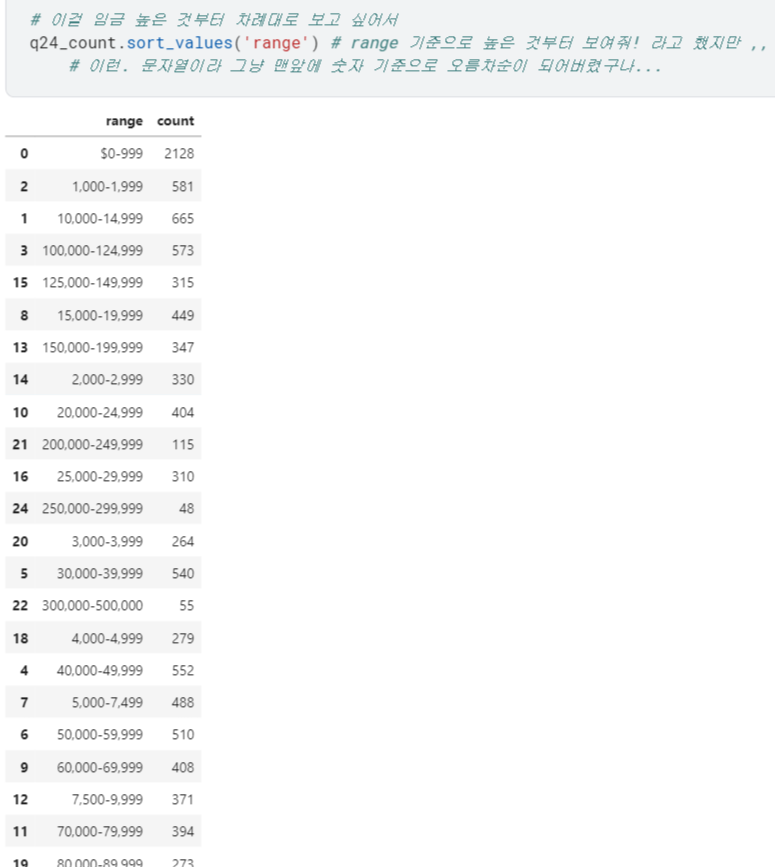
1) 양 끝값 분리하기
- 먼저,
.str.split()으로 양 끝값을 분리시켜 따로 다룰 수 있도록 함.

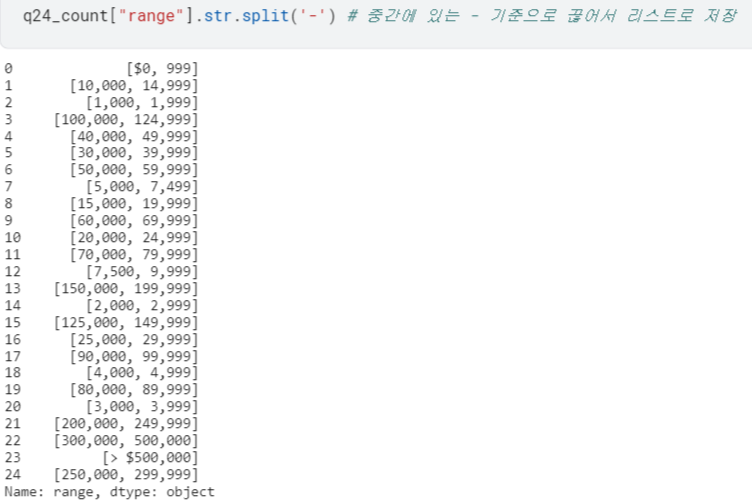
expand=True: 데이터프레임 형태로 확장해줄 수 있음.
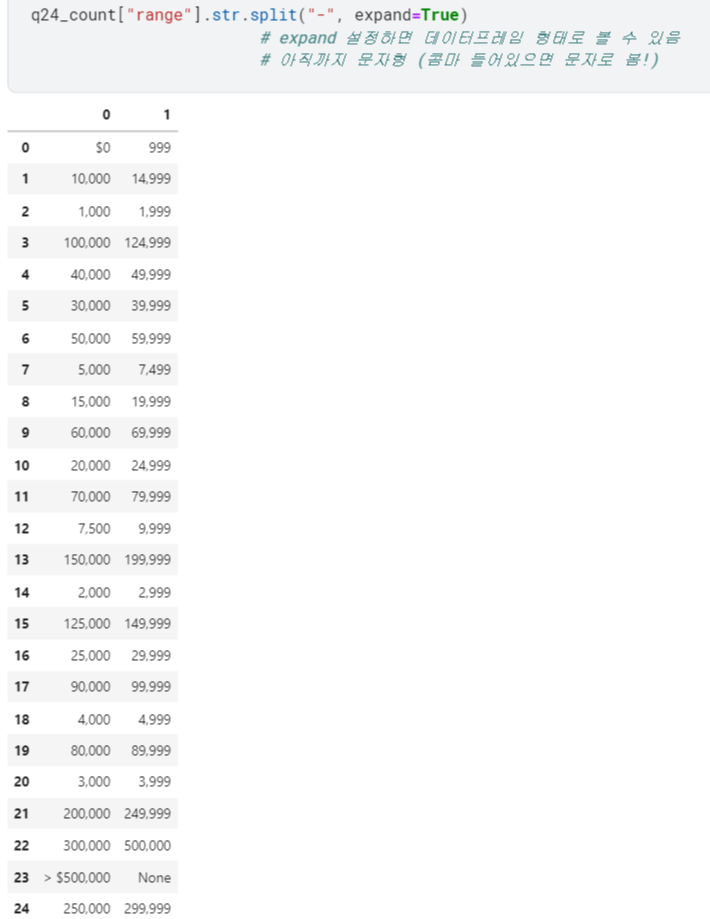
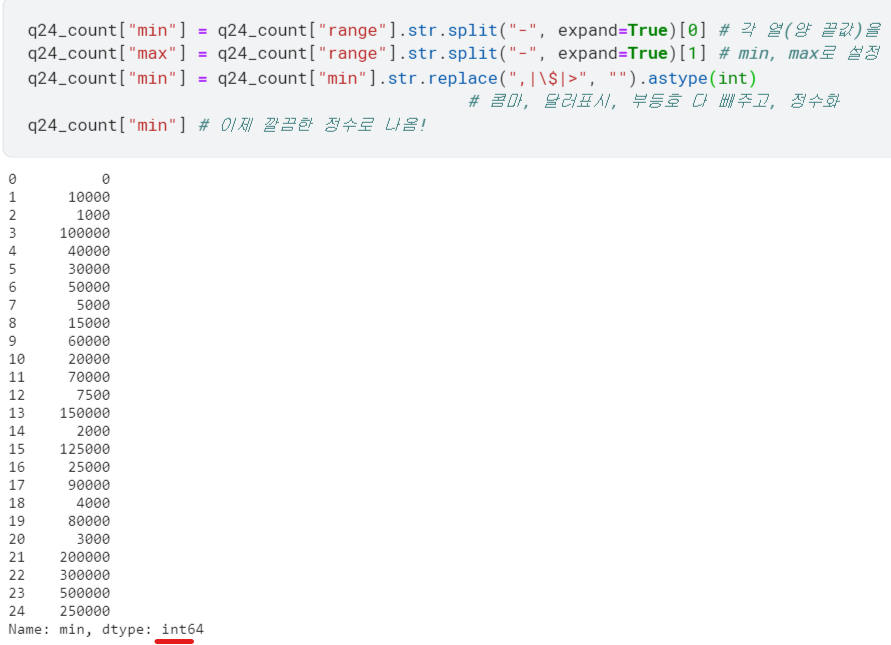
2) 정수형으로 바꿔주기
- 두 열 중 'min' 부분만 정수로 바꿔 봄.
.str.replace()로 숫자 아닌 것들 없애고,.astype(int)로 정수화 함.
(※$는 그냥 쓰면 정규표현식으로 이해해버려서, 탈출문자\써줘야 함!)
3) 정수로 바꾼 끝값을 기준으로 정렬
- 이제 정수가 된 끝값을 기준으로
.sort_values()를 사용하면 정렬 제대로 됨!
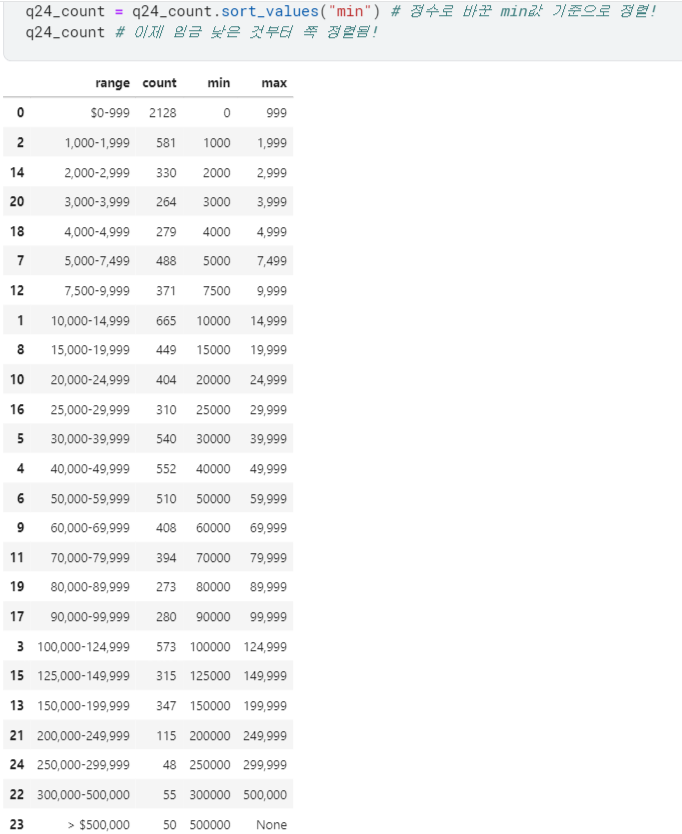
- 그렇게 정렬한 데이터로
.barplot()쓰면 그래프도 의도대로 잘 그려짐!
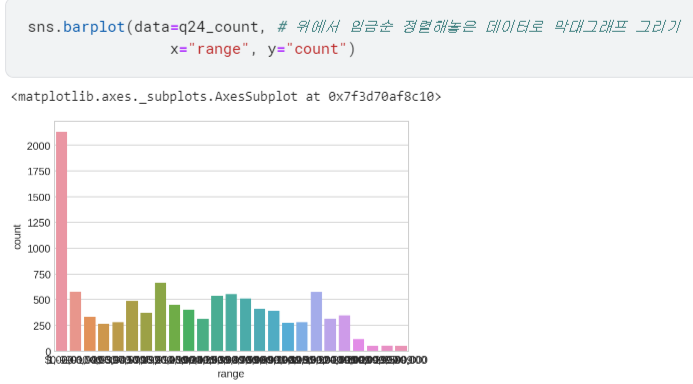
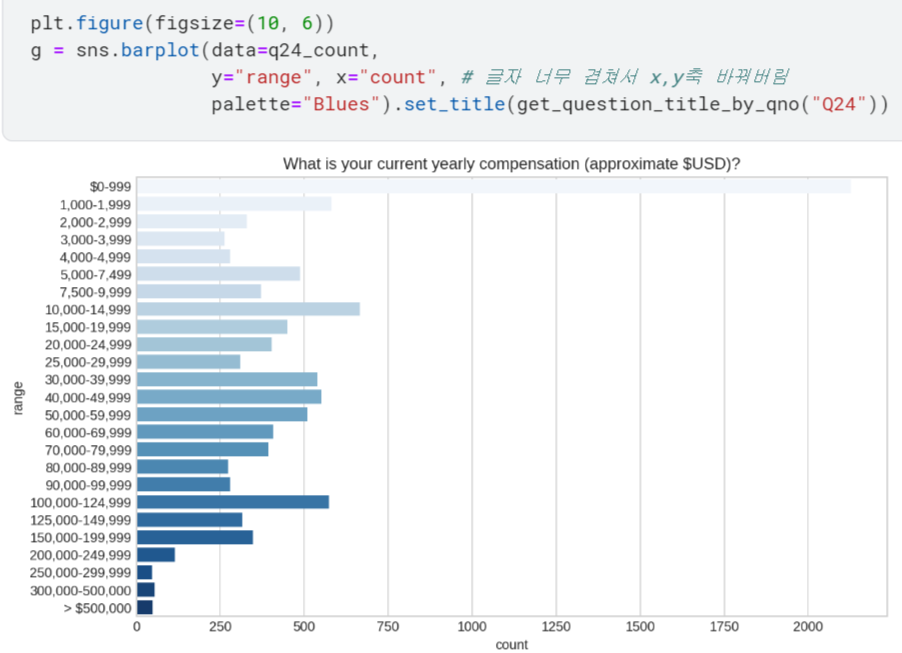
특정 국가 기준으로 보기
근데 보통 임금은 나라마다 차이가 있으니, 나라별로 구분해서도 한번 봅시다!
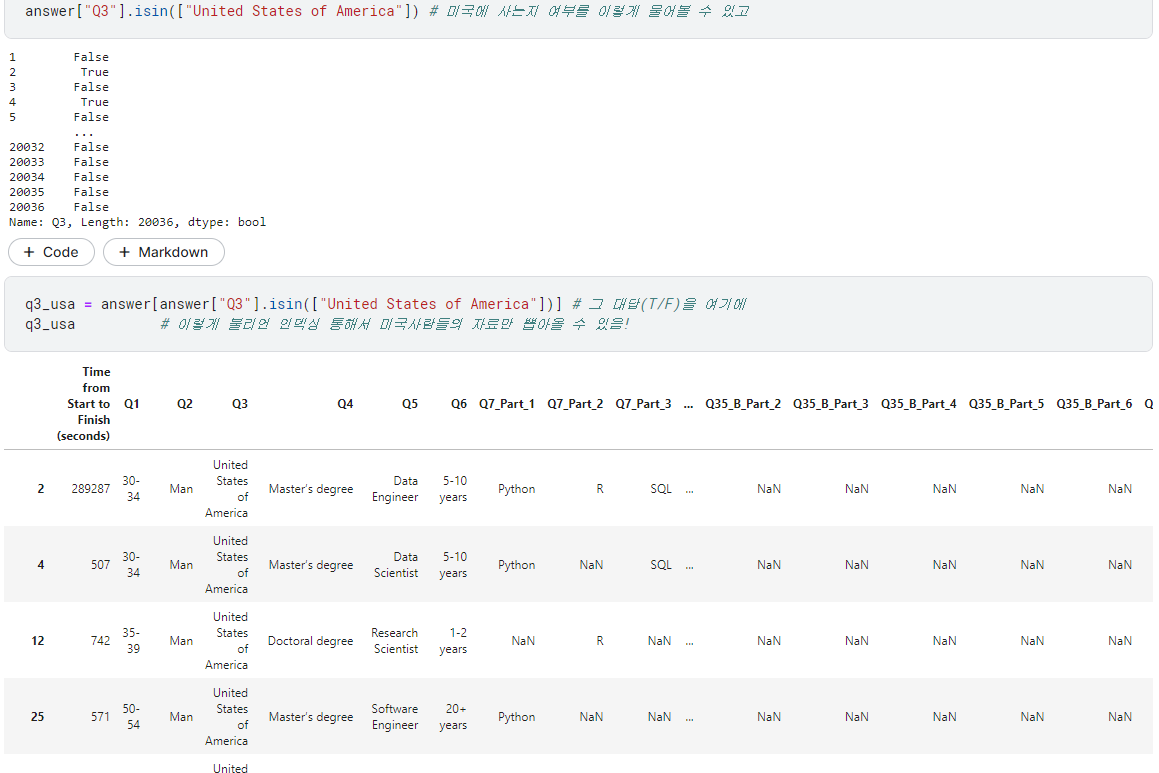
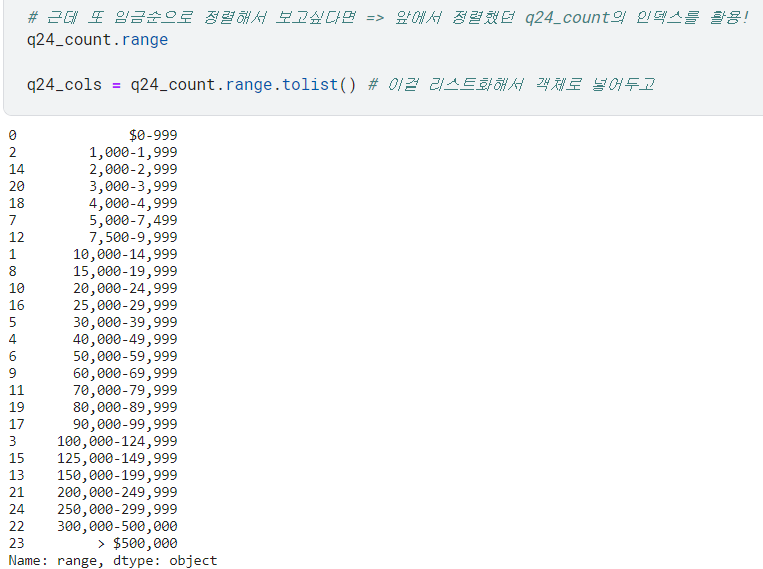
1) 미국
- 소속 국가에 대한 내용은 3번 질문에 있었음.

.isin()을 통한불리언 인덱싱을 활용해 미국의 데이터만 가져와 봄.
- 그리고 그걸로 countplot 그려볼 수 있음!
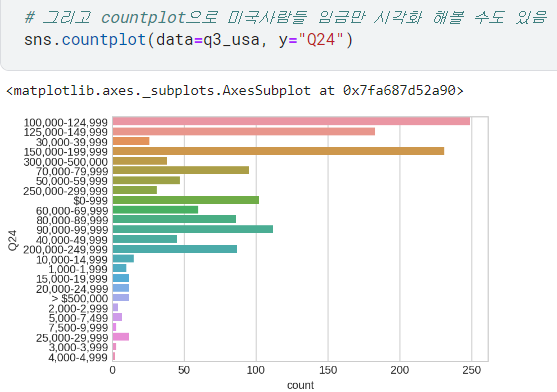
- ➕근데 이걸 또 임금 순으로 정렬하고 싶다면, 위에서 정렬했던 거 활용!
(.range,.tolist()사용)
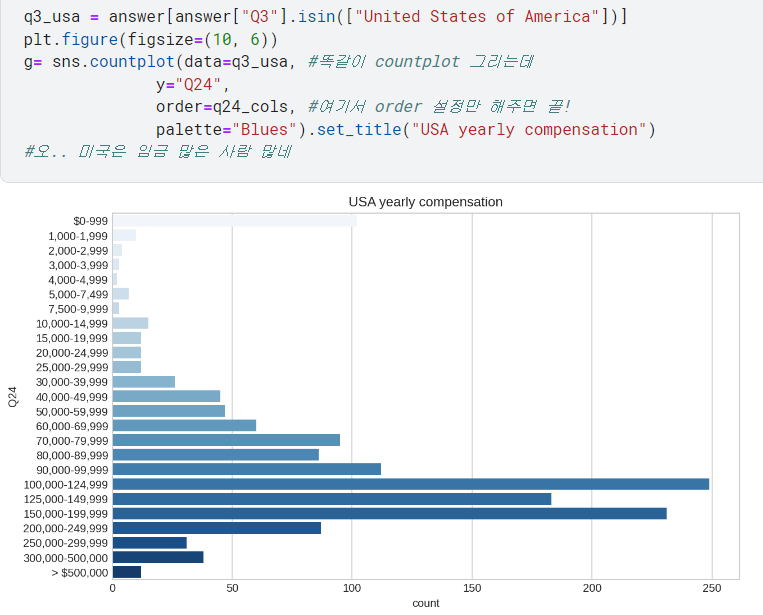
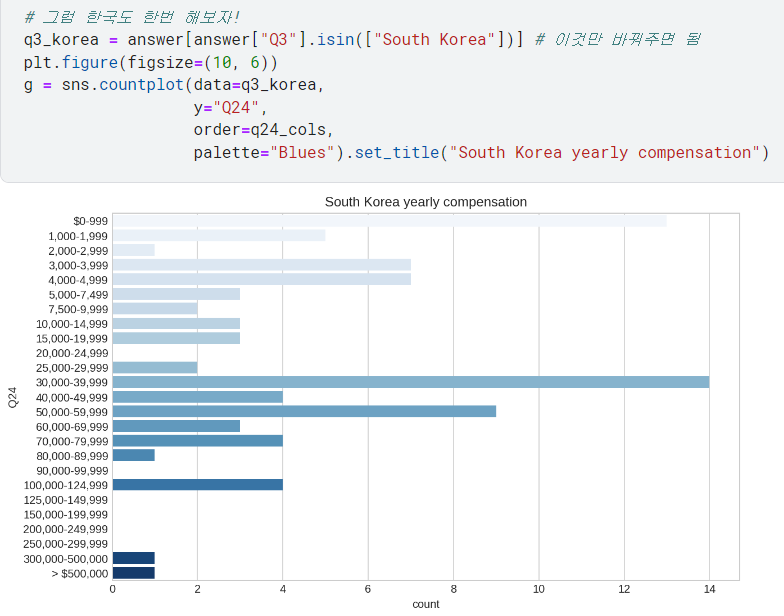
2) 한국
- 이번엔 한국 자료만 보고 싶다면,
.isin()에 들어있는 것만 바꿔주면 됨^^
마무리
남은 질문들
- 앞서 했듯이
show_plot_by_qno함수로, 25번부터 마저 살펴보면 됨.
(자세한 내용은 캐글에서 확인)
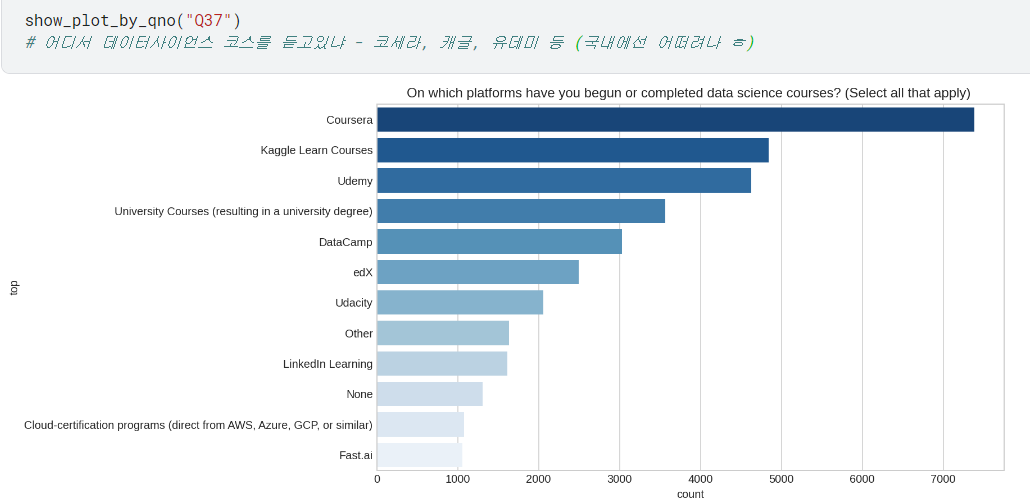
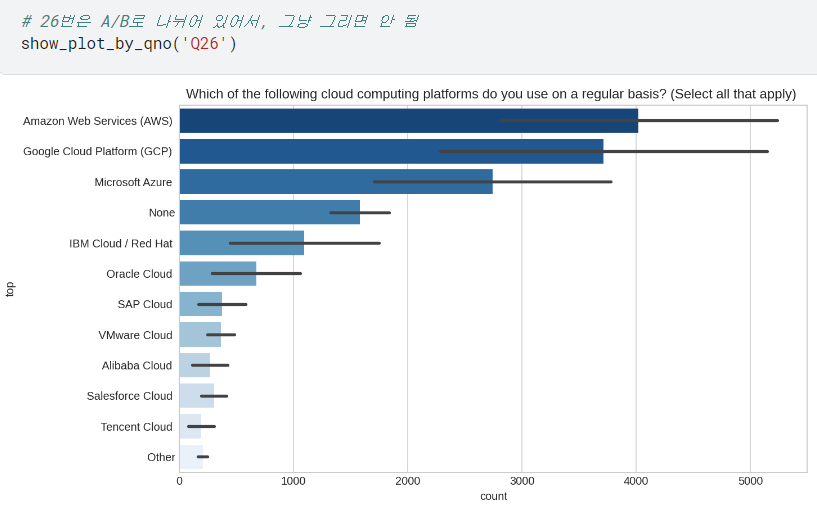
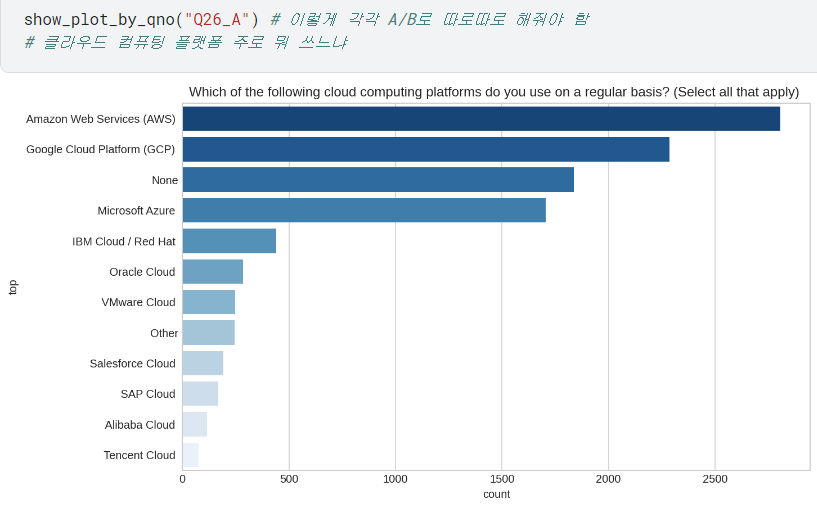
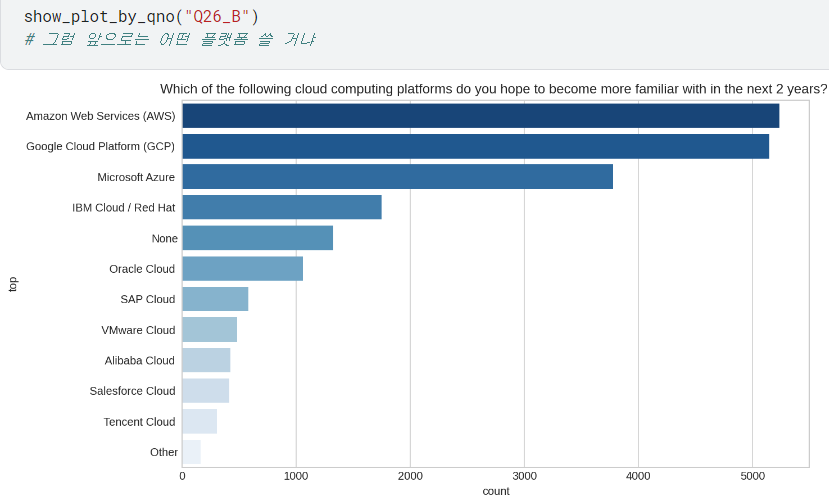
- 간혹 26번 질문처럼 A/B로 하위질문 있는 경우는, 나뉜 하위질문 대로 입력해서 각각 확인하면 됨!
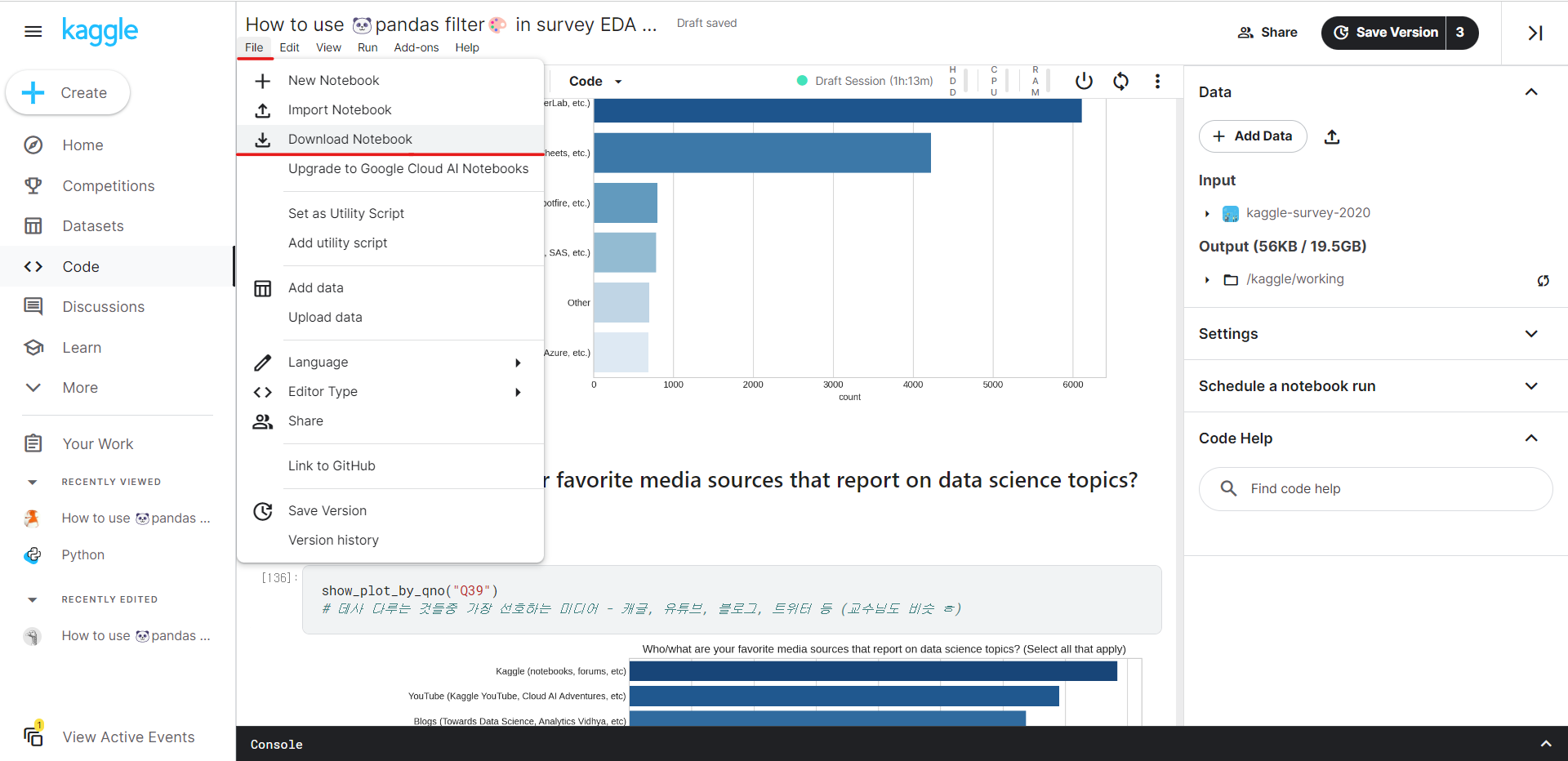
캐글 노트북을 내 컴퓨터로 가져오려면?
- 캐글에서 만든 notebook 파일을 내 로컬 주피터노트북으로 가져와서 작업하고 싶다면?
- Edit 상태 > File > Download > 파일을 주피터노트북 작업 경로(ex. PythonDataWorkspace)로 이동 >
import os에서 캐글로 경로설정된 부분만 지우거나 주석처리 >pd.read.csv해오는 것도 내가 따로 데이터 다운 받아와서 내 폴더에서 직접 불러와도 됨 ㅇㅇ
🧐My Point
- regex에 관한 부분은 다음에 따로 공부해서 추가해두자!!!
- Q26의 검은 선은 '신뢰구간'을 표시한다고 하셨는데, 추가로 알아봐야겠다.
❓<응답 출력하는 함수> 파트에서
sort_values쓸 때, 왜 저번에는 없던by라는 매개변수가 붙나요..?👨🏻🏫 함수는 def 함수명(parameter=argument) 으로 사용할 수 있습니다.
parameter 이름을 지정하고 함수나 메서드를 호출할 수도 있으며, 순서대로 argument 만 지정해서 호출할 수도 있습니다. 또, *args, **kwargs 를 사용할 수도 있습니다. 🆗

생각은 그만