
배경
개인 작업물을 게시하는 프로젝트를 진행하고 있습니다.
(https://www.si-tree.com)
홈 화면 상단에 개인이 속한 소속(회사/학교 등)의 순위를 보여주는 부분이 있습니다.
랭킹의 기준은 소속에 속한 사람의 프로젝트 수 및 프로젝트의 관심도를 바탕으로 계산됩니다.
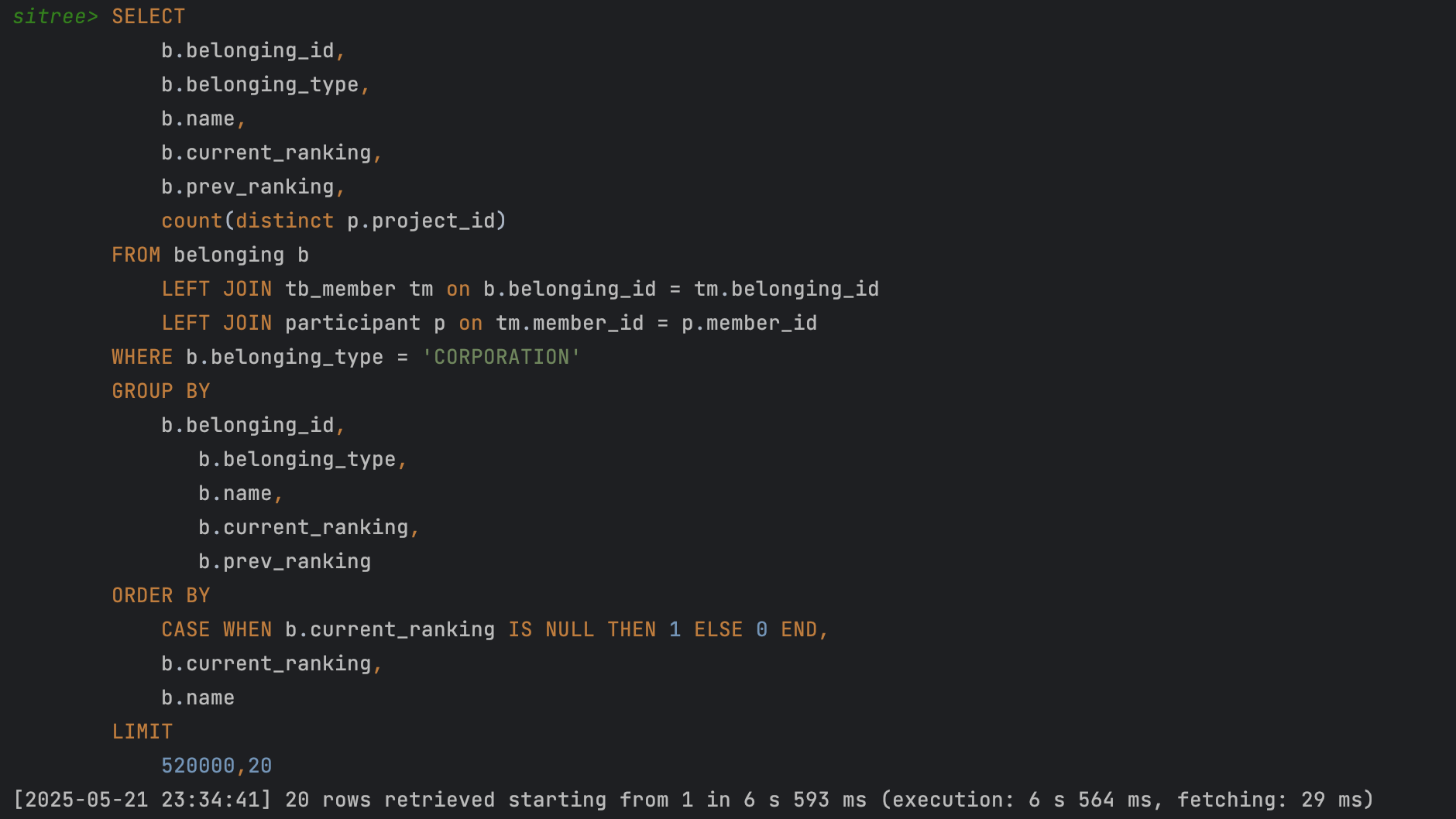
문제는 이 소속의 순위를 조회할 때 55만개의 Row를 정렬 및 다른 테이블과 Join하여 연산하는데 6~7초 가량 소요되는데 있었습니다.
개선 과정
개선 전 쿼리를 확인해보자
1. 인덱스 적용하기
흔히 알고있는 쿼리 개선의 기본, 인덱스를 적용해봤다.
WHERE문과 정렬 기준으로 사용되는 칼럼을 기준으로 (belonging_type, current_ranking, name) 순으로 생성했다.
또한, ORDER BY에 있는 CASE문이 인덱스 사용에 영향을 줄 수 있기에, Null 대신 Default 값을 최대 값으로 초기화하고 ORDER BY 조건문을 (b.current_ranking, b.name) 으로 단순화했다.
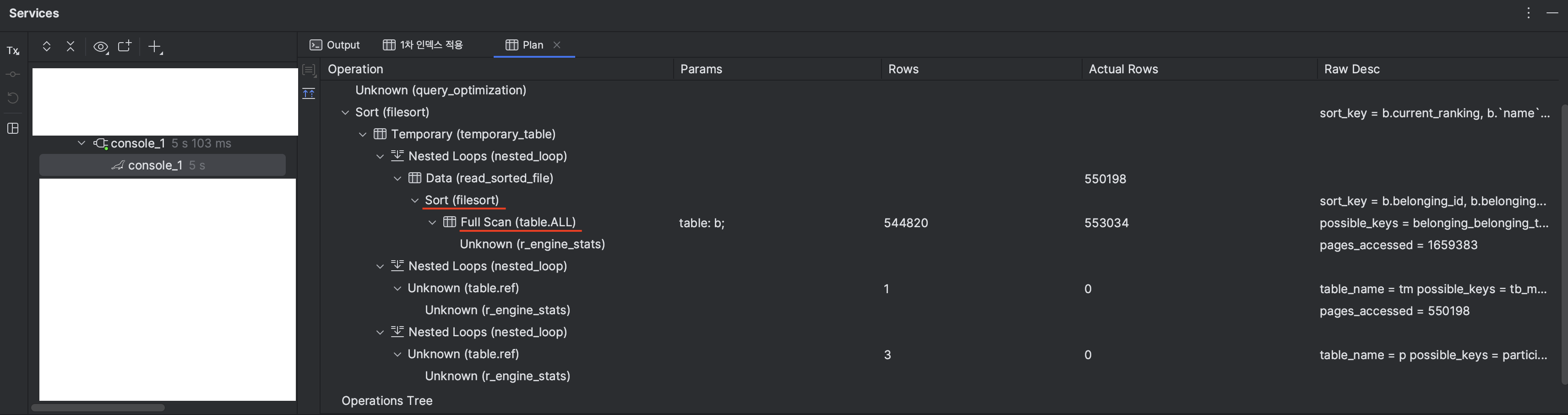
하지만 생각했던 내용과 다르게, 여전히 File sort와, Full Scan을 수행중인 내용을 확인했다.
왜 버젓이 있는 index를 활용하지 않았을까? 관련 리서치를 열심히 해봤다.
1. 너무 큰 offset
원하는 데이터를 얻기 위해서 필요한 (offset + limit) 지점까지 데이터를 가져오고 정렬 후, offset 이전의 데이터를 버리게 되는데, 옵티마이저 입장에서 상위 작업이 random disc I/O 기반으로 동작하는 Index 활용 방식이 full scan 방식보다 비용이 크다고 판단했을 가능성이 크다.
2. 설정한 index 1컬럼의 낮은 카디널리티
첫번째belonging_type칼럼에서 55만건 중 50만건이 WHERE절에 걸려있는 CORPORATION 값이었다.
3. GROUP BY 및 SELECT까지 포함하지 못하는 인덱스 (커버링 인덱스가 아님)
1번과 비슷한 이유로, 커버링 인덱스가 아닌 경우 추가적인 disc I/O가 발생하기때문에 옵티마이저의 비용 계산 시 full scan의 판단 근거가 된 듯 하다.
2.그러면 인덱스의 활용도를 높이고, Full Scan과 File Sort를 없애기 위해 쿼리를 분리해보자.
일단, belonging 테이블에서 가져올 수 있는 데이터와, Join으로 가져와야하는 데이터 (project수)를 분리하기로 했다.
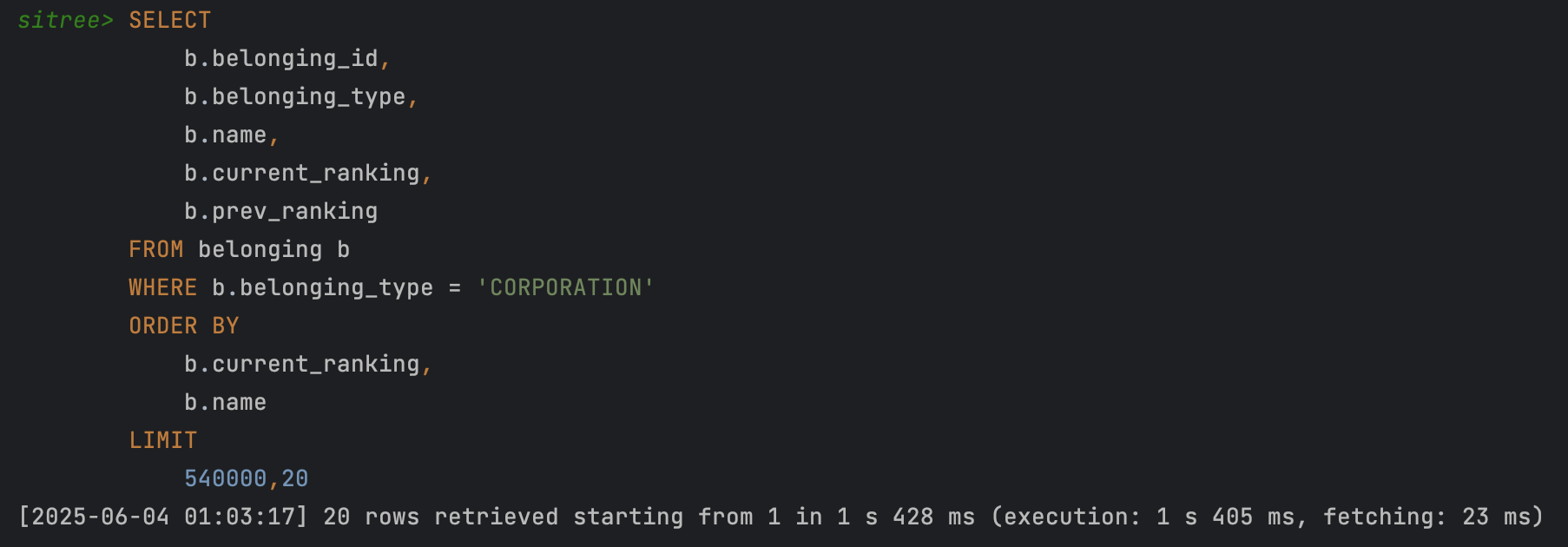
Join을 분리하고, 추가적인 Table Row Scan을 없이 index만 활용하기 위해 select 구분을 id 값만 반환하도록 추가 수정을 진행했다.
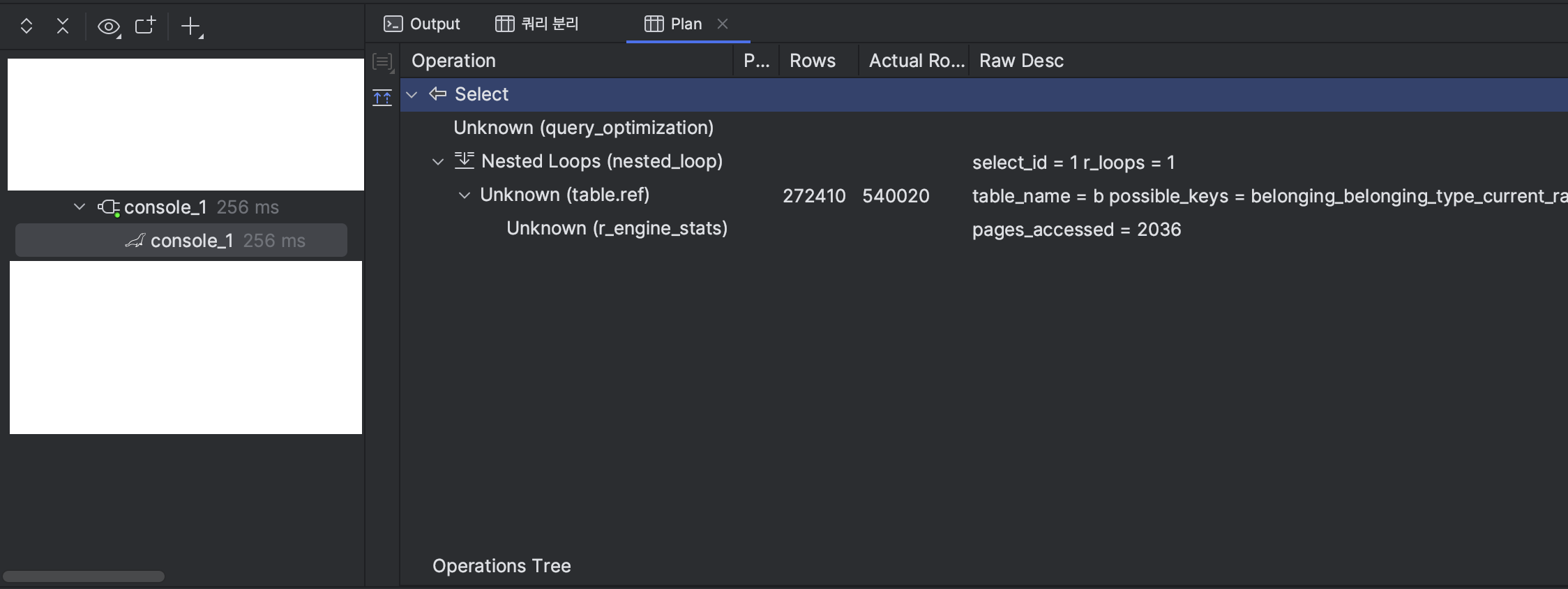 인덱스를 잘 활용하고 있는 모습. 수행시간도 매우 짧아졌다. 250ms 정도
인덱스를 잘 활용하고 있는 모습. 수행시간도 매우 짧아졌다. 250ms 정도
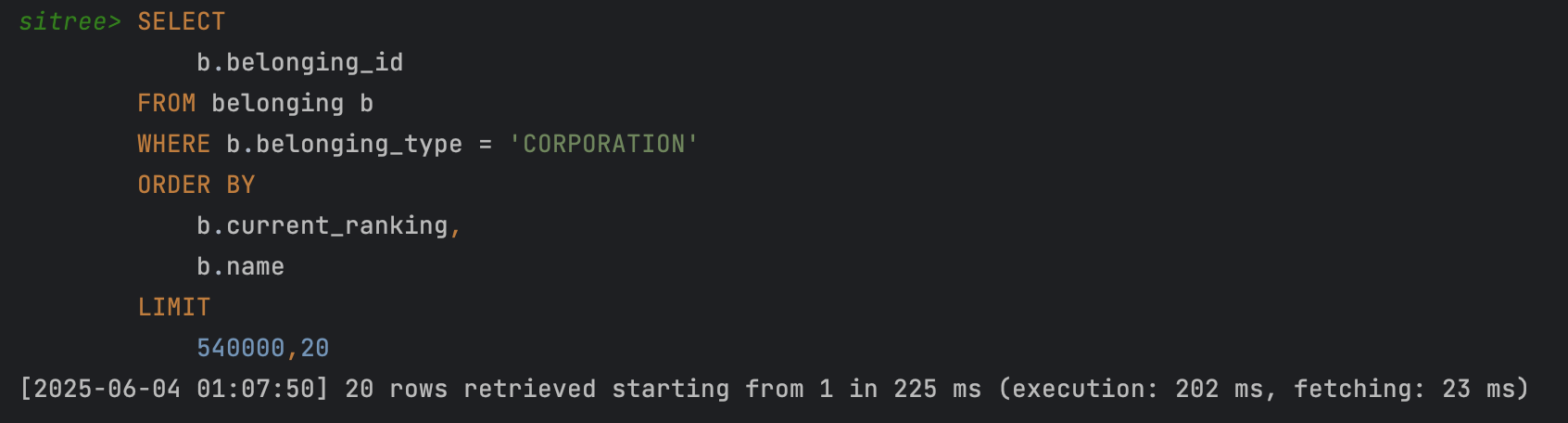
추출된 id 값을 기준으로 나머지 데이터를 Join 연산해오는 쿼리 수행 시, 이미 기준이 되는 id 값으로 조회해서 25ms 언저리로 수행시간이 매우 짧았다. (아래 사진)
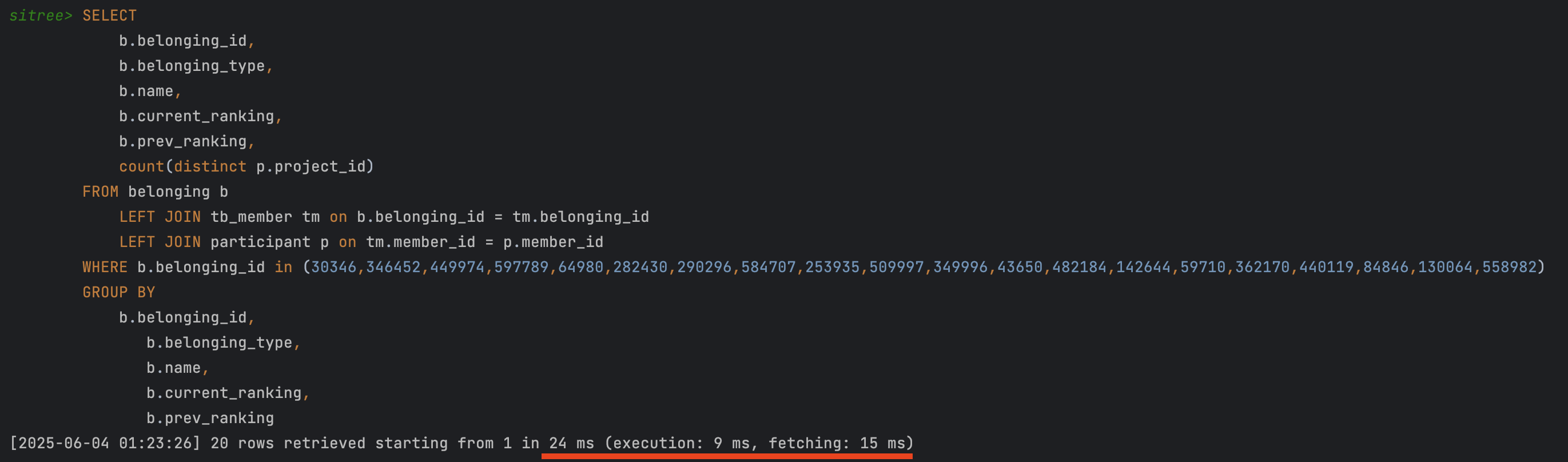
결론
해서 기존 7초 언저리 걸리는 쿼리를 분할하는 과정을 통해 총 0.3초 미만으로 줄일 수 있었다.
계산해보면 23배 개선인데 이거 완전 대박이죠!
조금 답답했던 부분은 옵티마이저의 인덱스 활용 부분을 찾는 과정에서 대부분의 내용에서 옵티마이저가 판단하는 명확한 기준을 설명하고있지 않았다.
filtered, 연산되는 데이터의 량, I/O연산 등등 수많은 복합적인 기준에 따라 옵티마이저가 판단한다고만 나와있어서, 왜 옵티마이저가 이렇게 연산했지?에 대한 부분을 직접 인덱스와 쿼리를 만져보며 실행계획 변경내용을 통해 바뀐 이유를 유추해야 했다.
(아직 익숙하지 않아서 방법을 잘 모를수도 있겠다)
결과적으론 하나씩 뜯어보고 정의에 대해 찾아보며 튜닝과 조금 더 익숙해질 수 있던 기회가 되어 값진 경험이었다.
화이팅!
