
배경
지난 1편에서는 브로커가 컨슈머가 죽었는지 알기위해서, 어떻게 살아있는지 확인하는 방법에 대해 알아봤었다.
이번편에서는 컨슈머가 종료될 때 어떤 동작을 하게되는지 한번 살펴보고자 한다.
1. 브로커가 컨슈머의 생존여부를 감지하는 방법 (Kafka Client 1편)
2. 컨슈머가 종료될 때 브로커로 전달되는 내용 (정상종료 / 비정상 종료)
3. 컨슈머가 살아났을 때 브로커로부터 가져오는 데이터
간단 목차
- 정상 종료와 / 비정상 종료의 프로세스
- 종료 시 넘어가는 데이터의 내용
- 정상 종료 시 컨슈머의 종료 프로세스
컨슈머가 종료되는 경우
비정상 종료
JVM 크래시 혹은 여러 인프라적인 요소에 의해 정상동작하지 않게 된다면, 당연히 로컬에서는 어떠한 종료 처리도 하지 못한다.
이 경우 자연스럽게 브로커 쪽에서 특정 기간 이상 heartbeat를 받지 못해 리밸런싱 동작을 진행하게 된다.
비정상 종료된 컨슈머는 종료 프로세스를 통해 브로커로 전달할 수 없기에 소비한 offset 커밋 및 다른 데이터를 전달하지 못하기 때문에 리밸런싱 이후 같은 offset에 대해서 중복 consume의 위험이 있다. (사실 요게 내가 겪었던 현상의 원인이었다)
정상 종료 되었을 때
컨슈머가 정상 종료되는 경우는 언제가 있을까?
- 의도된 Exception으로 Application 혹은 Kafka Spring이 기능적으로 정상 종료될 때 (흔치 않은 경우다...😅)
- 리밸런싱 등의 이유로 브로커로부터 종료 콜백을 받을 때
브로커가 Heartbeat 미수신으로 컨슈머의 상태를 감지하게 되는 경우와 다르게, 정상 종료 케이스는 종료 프로세스를 타게 된다.
그러면 이 종료 프로세스는 어떻게 진행될까??
정상 종료 케이스로 진행될 때, Application Context가 종료되면서 KafkaMessageListenerContainer에 종료 이벤트가 전달되게 된다.
위 객체가 상속받은 것 중
SmartLifecycle이 Spring 프레임워크에서 애플리케이션 시작/종료 시점에 자동으로 빈(Lifecycle Bean)을 시작하고 종료하는 데 도움을 준다고 한다. (스프링 까도까도 뭐가 자꾸 나온다...)
이때 공통적인 stop() 메서드가 실행되면서 KafkaMessageListenerContainer의 doStop()메서드가 수행되게 된다.
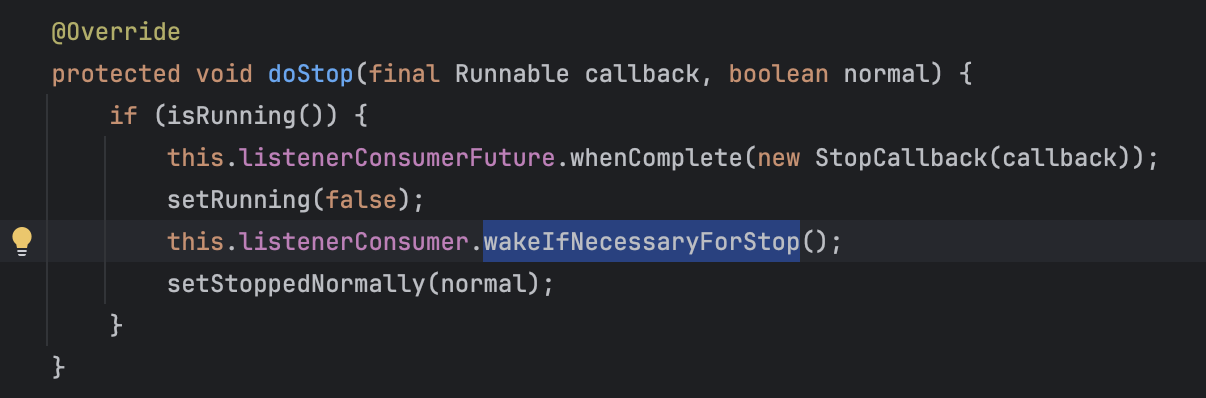
 내부 running 상태를 false로 변경하고, consumer.wakeup() 함수를 콜하는 구현체
wakeup 수행 시 Exception을 발생시켜 poll 상태를 중단하게되기도 하지만, 크게 바라보면, running 상태가 false로 변경된 점에 집중해보겠다.
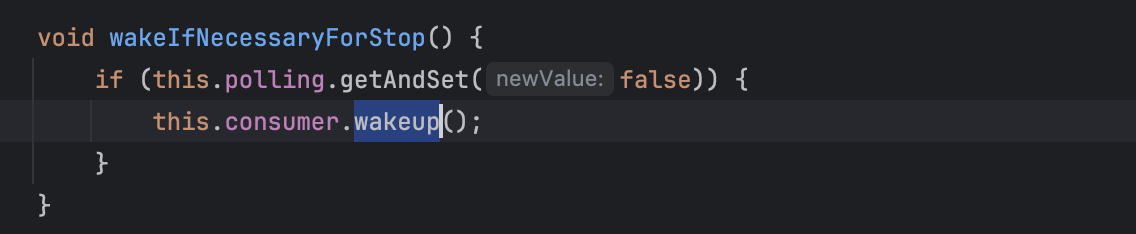
내부 running 상태를 false로 변경하고, consumer.wakeup() 함수를 콜하는 구현체
wakeup 수행 시 Exception을 발생시켜 poll 상태를 중단하게되기도 하지만, 크게 바라보면, running 상태가 false로 변경된 점에 집중해보겠다.
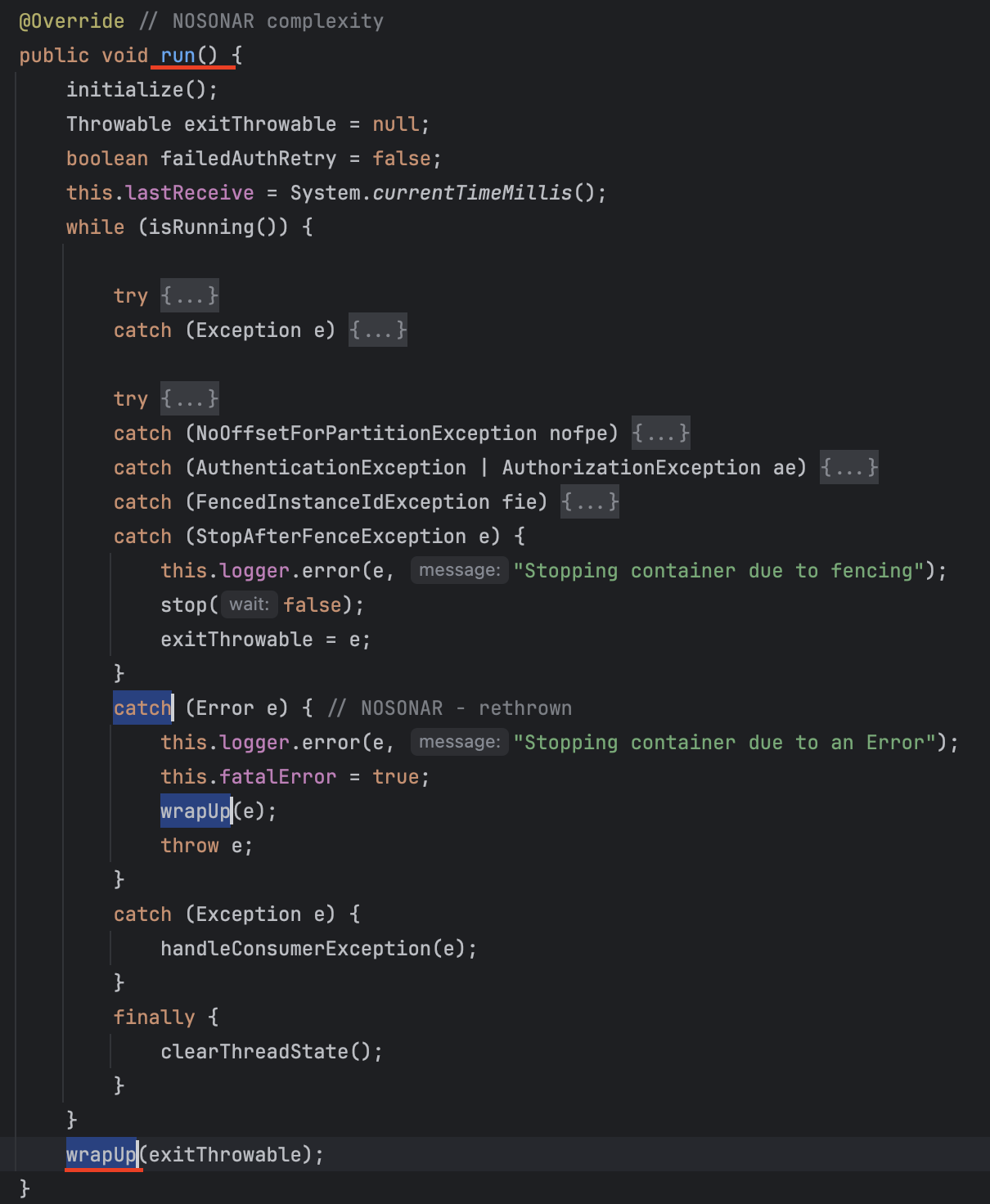 KafkaMessageListenerContainer의 run 구현체
KafkaMessageListenerContainer의 run 구현체
running 상태가 false로 변경되면서, 하단 wrapUp() 함수가 수행된다.
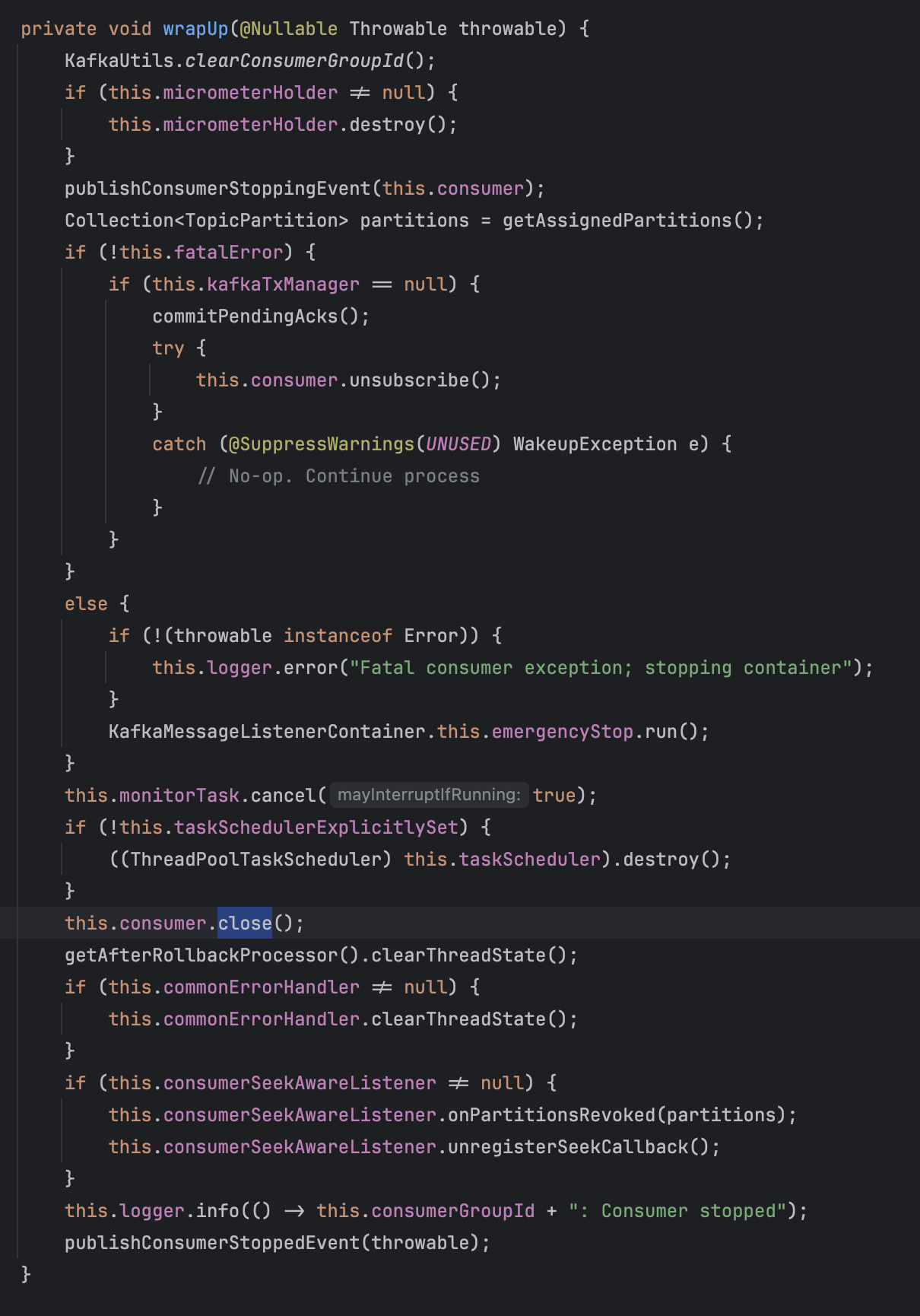 wrapUp() 함수 내부 드디어 consumer의 close()를 확인할 수 있다.
wrapUp() 함수 내부 드디어 consumer의 close()를 확인할 수 있다.
wrapUp()함수는 아래와 같은 작업을 진행하게 된다.
- 컨슈머 스레드에 바인딩된 그룹 아이디 제거 (메트릭 정리)
- Kafka consumer 종료 진행중 이벤트 발행
- 기존 할당된 파티션 정보 관리 (어디에 쓰일까?)
- 정상 종료 시 진행중인 offset 정보 commit, 및 consumer 구독 종료 프로세스
(fatalError 시 emergencyStop 진행) - 모니터링 및 consumer 중지 실행
- 에러 헨들링 및 Kafka consumer 종료 완료 이벤트 발행
그러면 KafkaConsumer의 close() 함수를 살펴보자.
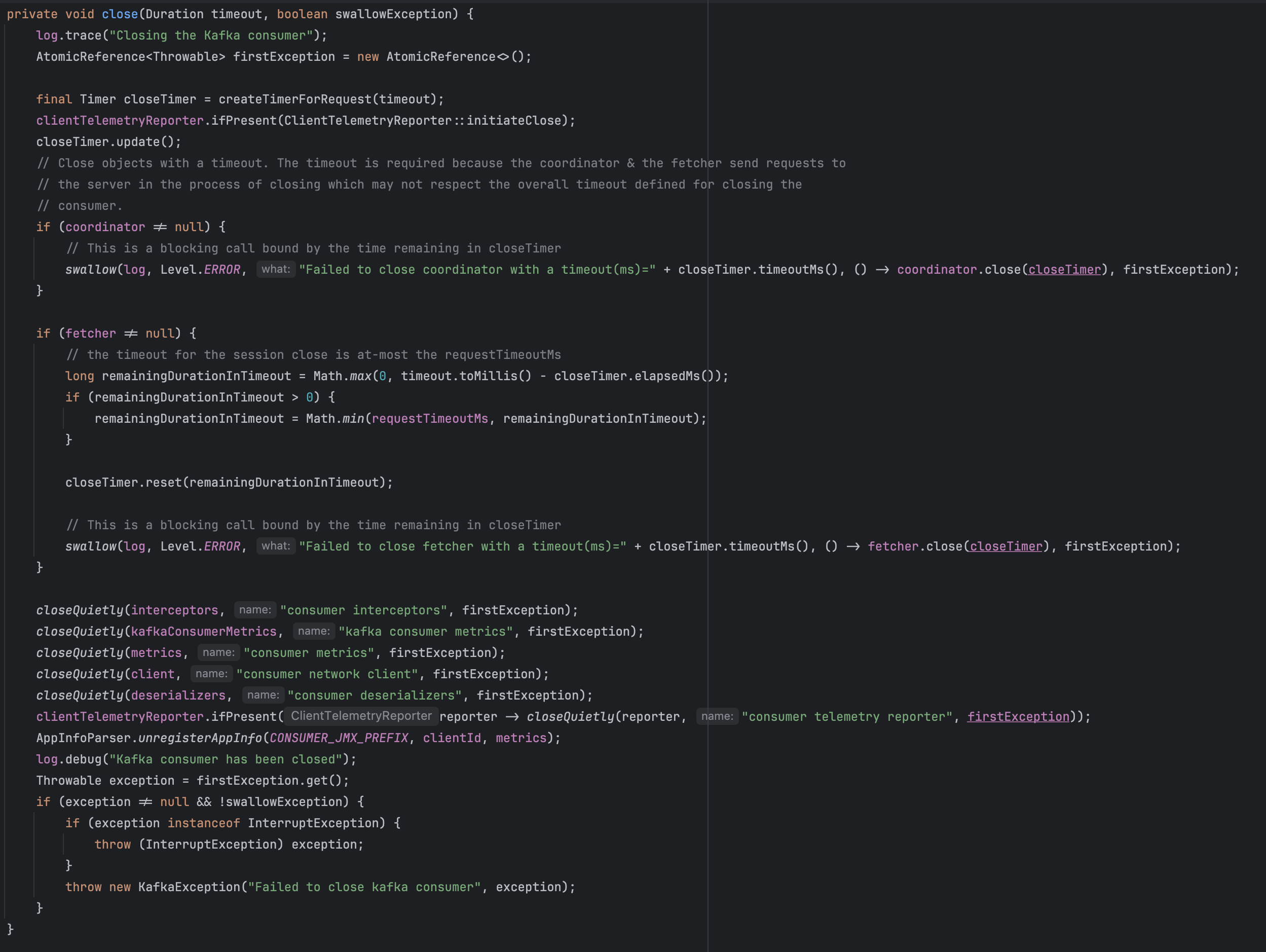 LegacyKafkaConsumer를 기준으로 살펴봤으며, close() 구현체 하위 close() private 구현체를 살펴봤다.
LegacyKafkaConsumer를 기준으로 살펴봤으며, close() 구현체 하위 close() private 구현체를 살펴봤다.
close() 함수에서는 보이듯이 여러 객체들을 정리해주는 역할을 하는데, 특이한 점이 있다.
설명에 적혀있듯, coordinator와 fetcher 종료시 의도적으로 timeout을 기다리게 된다.
coordinator.close(closeTimer),fetcher.close(closeTimer) 은 각각 closeTimer 시간만큼 대기 후 종료하게 되는데, 이는 두 작업이 네트워크 통신을 바탕으로하는 요청이기 때문에, 진행중인 요청에 대한 충분한 응답 대기 후 질서있게 처리하기 위함이라고 한다.
결론
카프카 클라이언트 종료로직에 대해 살펴보면서 내가 겪은 경우에 대한 명확한 이유를 파악하고자, 평소보다 조금 기대 넘치는 마음으로 구현체들을 들여다보게 된 듯 하다.
한편으로는 종료단계에 엮여있는 수많은 구현체들을 관리하는 정교한(?) 로직을 살펴보게되어 감회도 조금 남다른 것 같다.
특히나 종료 시 직접 종료를 시켜버리기 보단, timeout을 활용한 자연스러운 종료처리에 감탄하기도 했다.
추가로, Rebalancing 동작 시에도, consumer가 컨슘을 멈추고 파티션 재할당 이후 다시 컨슘 시작하는 것으로 알고있어 동일하게 consumer.close()가 사용될줄 알았는데 이건 또 완전 별개의 구현인 듯 하다. 조만간 ConsumerRebalanceListner (ListenerConsumerRebalanceListener) 쪽도 세세하게 살펴봐지 싶다. 😅
