
상황
ECS Fargate를 운영하면서 배포 속도가 너무 느리다 생각했다.
그래서 원인을 찾아본 결과
ECS의 컨테이너 오케스트레이션의 일부가 지나치게 안전하게 구성되어있기 때문임을 확인했다. 서비스에 지장이 가지 않는 선에서 약간의 안전성과 배포 속도를 trade-off하여 배포 속도를 개선해보고자 한다.
기존
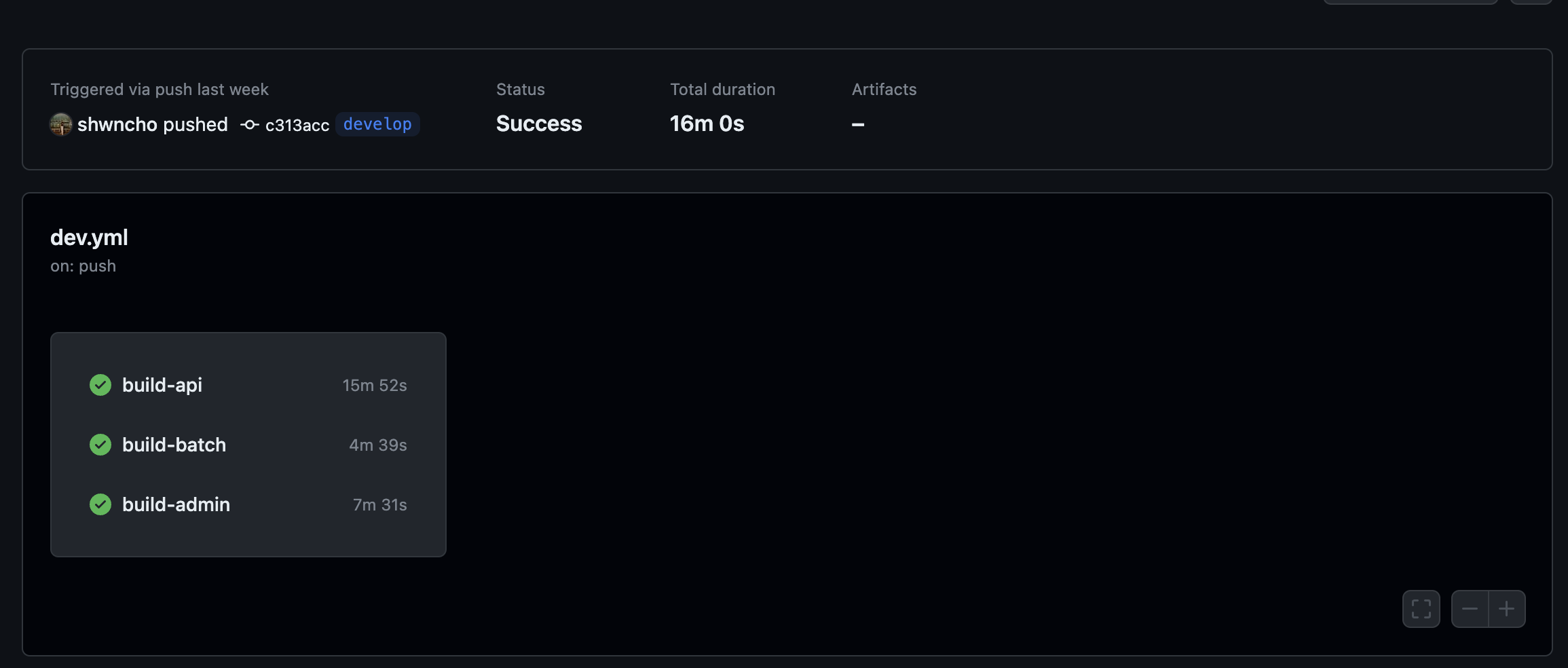
병렬적으로 각 서버들을 배포했음에도 총 16분이나 걸림을 알 수 있다.
(가장 늦은 api서버가 기준이 되어 약 16분 소요)
특히 Deploy 하는 과정이 대부분의 시간을 차지했다.

해결
1. Target Group 상태 검사 설정
- 초기 설정

기본적으로 로드 밸런서는 대상 컨테이너가 정상으로 간주되기 전에 5번의 상태 확인 통과가 필요하며 각 확인은 기본 설정값인 30초 간격으로 이루어진다.
(위에서 "간격" 설정을 의미한다. 기본 설정값은 30초고 위에서는 테스트를 위해 60초로 된 화면을 캡처한 것이므로 혼동하지않기를)
그 말인즉슨 5* 30 = 150초 = 2분 30초로 ECS 배포 과정에서 로드 밸런서의 상태 확인이 포함되기 때문에 최소 2분 30초의 소요시간이 든다는 것을 알 수 있다.
-
api 서버 대상 그룹 상태 검사 설정 변경 후

-
admin 서버 대상 그룹 상태 검사 설정 변경 후

위 설정을 보면 서버별로 간격이 다른 것임을 알 수 있는데 이 부분은 서버 스펙에 의해 달라진 것이다.
- 비교적 서버 스펙이 더 좋은 api 서버는 애플리케이션 실행 소요 시간이 약 20초대 이므로 30초 간격
- admin 서버는 애플리케이션 실행 소요 시간이 약 50대 이므로 60초 간격으로 설정해줬다.
기존 최소 2분 30초 소요 시간에서
- api 서버는 2번 * 30초 = 60초로 단축
- admin 서버는 2번 * 60초 = 120초로 단축
정상으로 간주하기 위해 최소 2번은 체크해야한다고 생각해서 정상 임계값은 2번으로 설정했다.
2. SIGTERM 민감도 변경
기본 값으로 ECS_CONTAINER_STOP_TIMEOUT는 30초로 구성된다.
이 값을 2초로 바꿀 것인데 그렇게 되면 ECS는 컨테이너를 종료하는 데 2초밖에 시간을 주지 않으며, 해당 시간 내에 작업을 완료하고 종료하지 않으면 컨테이너는 신호와 함께 강제 중지된다.
이 대기 기간(2초)은 가장 느린 요청 또는 트랜잭션 응답 시간의 최소 두 배로 설정되어야 한다.
지금 나는 애플리케이션에서 가장 부하가 많이 걸리는 기능이 약 1초안에 요청을 처리한다고 가정하므로 프로세스가 모든 진행 중인 요청을 처리하고 컨테이너를 종료하는데 2초로 설정했다.
=> ECS_CONTAINER_STOP_TIMEOUT=2초 설정
1,2번을 적용한 1차 결과
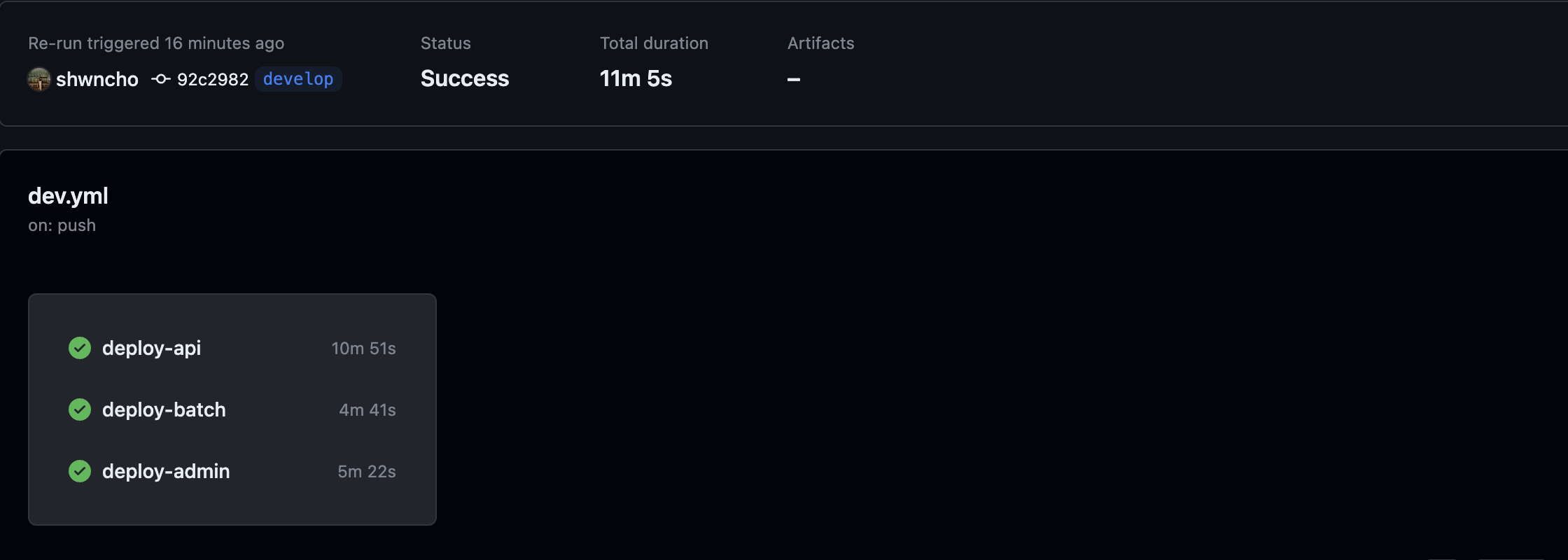
16분이 걸리던 배포시간이 11분 5초로 단축되었다.
그러나 여기서 더 개선해보자
3. Target Group의 등록취소지연 300 초→ 5 초로 조정
- 기본적으로 로드 밸런서는 강제로 연결을 끊기 전에 기존 유지 연결이 스스로 닫힐 때까지 최대 5분을 기다린다.
- ECS는 진행 중인 요청이 삭제되지 않도록 SIGTERM 신호를 컨테이너에 보내기 전에 등록 취소가 완료될 때까지 기다린다.
- 컨테이너 종료 시간(ECS_CONTAINER_STOP_TIMEOUT)을 2초로 설정했기 때문에 이보다 여유있는 5초로 조정
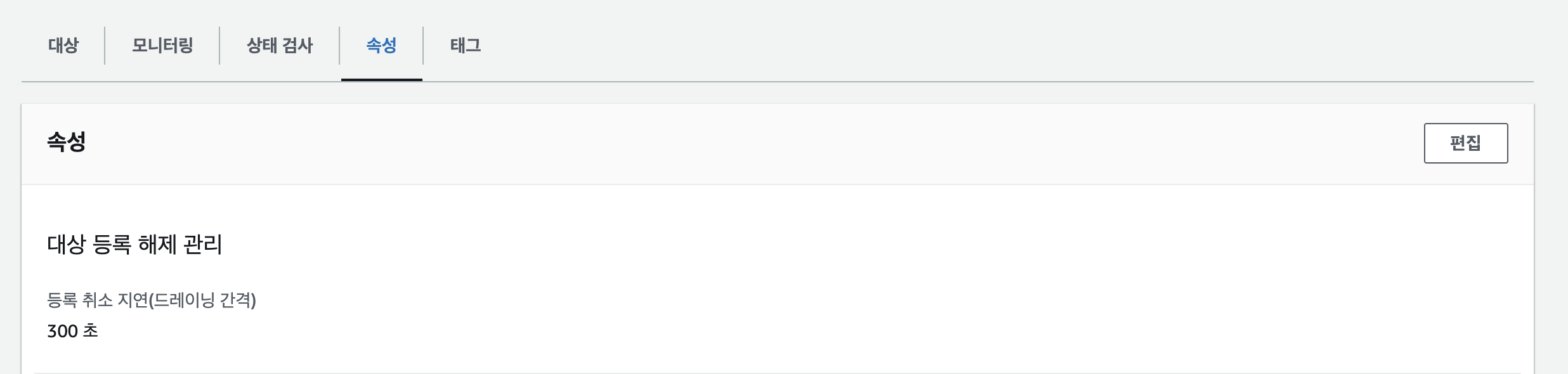

이렇게 설정해줌으로써 로드 밸런서는 클라이언트와 백엔드 서버 간의 연결 유지를 끊기 전에 5초만 기다린 다음 드레이닝이 완료되었음을 ECS에 보고하고 ECS가 작업을 중지할 수 있다.
주의
만약 서비스가 REST API와 같은 것이라면 이 지연을 줄이거나 제거해도 문제가 없다.
다만 느린 파일 업로드, 스트리밍 연결 등과 같이 오래 지속되는 요청이 있는 서비스가 있는 경우에는 이 작업을 수행하면 안된다.
위 사항들을 전부 적용한 결과
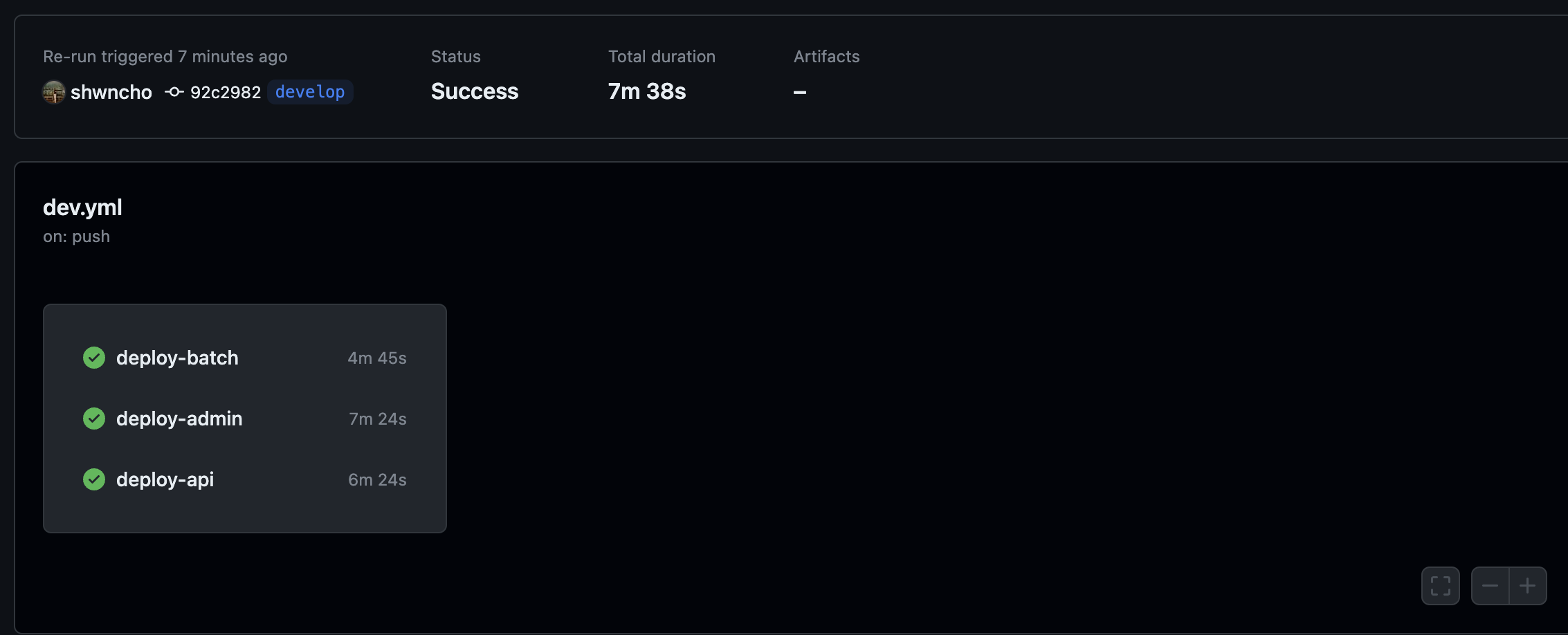
맨 처음 대비 16분 → 7분 38초로 약 2.09배 개선되었다.
참고
https://nathanpeck.com/speeding-up-amazon-ecs-container-deployments/
