Lochter, Johannes V., Renato M. Silva, and Tiago A. Almeida. "Deep learning models for representing out-of-vocabulary words." Brazilian Conference on Intelligent Systems. Springer, Cham, 2020.
Introduction
자연어처리(NLP)는 폭발하는 규모의 비정형 데이터, 즉 텍스트를 자동으로 처리하기 위해 발전한 인공지능의 한 분야이다.
텍스트를 컴퓨터가 이해하고, 효율적으로 처리하기 위해 텍스트를 숫자로 표상하는 방법론들이 고안되었다. 고전적인 방법은 bag-of-words (BoW) 이다. 코퍼스 내의 모든 어휘에 인덱스가 부여되고, 하나의 문서는 각 단어의 빈도수로 이루어진 벡터로 표현된다. 이는 단어의 위치 정보를 상실하여 의미론적, 통사론적 특징을 포착하지 못한다. 이러한 문제의식 아래 널리 쓰이는 방법은 단어를 벡터로 표상하는 워드 임베딩(word embedding) 이다. 이때의 벡터는 고정된 차원으로 실수값들을 가지는 밀집 벡터(dense vector)이다. 신경망 훈련으로 단어 문맥을 벡터공간에 표상함으로써 단어 간 의미적 유사성을 포착할 수 있게 된다.
워드 임베딩 모델들은 일종의 함수를 각 샘플의 단어들에 적용하여 임베딩 벡터(embedding vector)를 생성한다. 그런데 임베딩 모델의 단어 집합에 없는 단어, 즉 훈련 시 누락되었거나 낮은 빈도로 인해 삭제된 단어가 실험 데이터에 포함된 경우 임베딩 모델은 해당 단어에 대해 적절한 임베딩 벡터를 생성해내지 못한다. 단어 표상 과정에서 Out-of-Vocabulary (OOV) 단어들도 사전에 제대로 처리할 수 있어야 고품질의 임베딩 벡터를 획득하고 NLP 과제 성능을 개선할 수 있다.
본문에서는 딥러닝(DL)을 이용하여 OOV를 처리하는 방법들을 소개 하고, 다양한 NLP 과제에서의 성능을 비교한다.
OOV Handling
OOV 문제에 대처하는 가장 단순한 방법은 OOV 단어의 정보를 무시하고 새로운 벡터로 대체하는 것이다. 다음 벡터들로 대체할 수 있다.
- 랜덤 벡터
- 모든 OOV 단어에 대해 동일한 랜덤 벡터
- OOV 단어에 대해 각기 다른 랜덤 벡터
- 영(0)벡터: 해당 OOV 단어의 활성화(activation)를 무효화할 수 있다는 장점
- OOV 단어 이웃 단어들의 임베딩 벡터의 평균
하지만 임베딩 단계에서 OOV 단어의 존재를 부정한다면 예측 모델들이 다운스트림 과제에서 부정적인 성능을 표시할 수도 있다. 이에 OOV 단어의 형태학적 구조(morphological structure)와 문맥 정보를 활용하거나, 단어들의 의미론적 특징들을 학습한 언어 모델(language model)이 OOV 단어와 가장 유사한 단어를 예측할 수 있도록 활용하는 방법이 사용되고 있다.
Approaches based on the word context or structure
FastText
OOV 단어 내 서브워드(subword)의 구조
- 각 단어뿐만 아니라 각 단어의 n-gram (즉, 서브워드)에 대해서도 워드 임베딩이 된다.
- OOV 단어의 서브워드가 다른 단어의 서브워드에서 발견되었다면 해당 서브워드 임베딩 벡터들로 OOV 단어의 임베딩 벡터를 구성할 수 있다. 하지만 서브워드로부터 OOV 단어의 의미를 유추할 수 없는 경우 문제가 된다. 또는 OOV 단어의 서브워드들이 모델이 학습한 결과에 포함되어 있지 않아도 임베딩이 불가능해진다.
Mimick
OOV 단어 내 모든 문자(character)의 구조
- 각 단어의 모든 문자들을 입력으로, 다른 훈련된 단어 표상 모델의 임베딩 벡터를 목표로 하여, 입력과 목표 간 거리를 최소화하는 목표함수로써 신경망을 훈련시킨다.
- OOV 단어 내 문자들만으로 임베딩 벡터를 구할 수 있지만, 같은 OOV 단어에 대해서는 문맥과 의미에 상관없이 항상 동일한 벡터만을 출력한다는 문제가 있다.
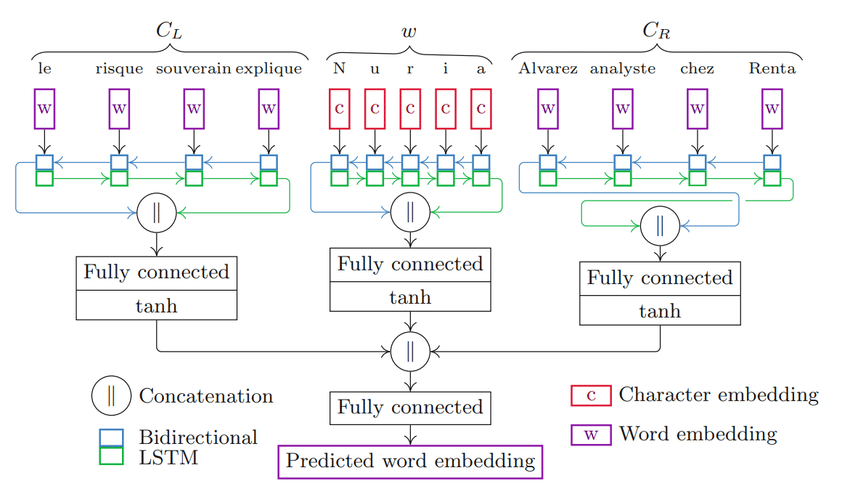
Comick
OOV 단어 내 모든 문자(character)의 구조 + 주위 문맥 정보
- 왼쪽 문맥 단어들, OOV 단어 자신, 오른쪽 문맥 단어들에 대한 임베딩 벡터를 각각 생성하고 완전연결계층을 통과시켜 최종 OOV 단어에 대한 임베딩 벡터를 생성한다.
- 문맥 단어들은 단어 임베딩 벡터를 양방향 LSTM (Bi-LSTM) 모델에 입력, OOV 단어는 문자 임베딩 벡터를 Bi-LSTM 모델에 입력한다.
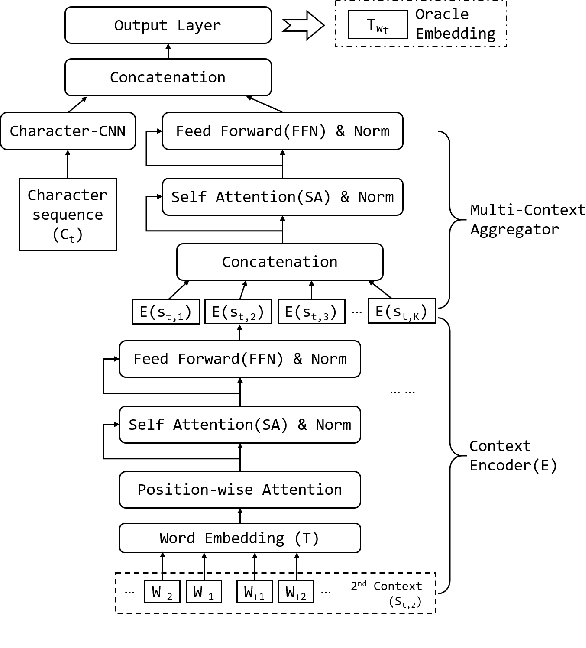
HiCE
OOV 단어 내 모든 문자(character)의 구조 + 주위 문맥 정보
- Context encoder: 2개(왼쪽, 오른쪽) 이상의 문맥 단어들을의 임베딩 벡터를 어텐션 메커니즘(Attention Mechanism)에 사용한다.
- Aggregator: Context encoder로부터 인코딩된 모든 문맥 정보에 다시 어텐션 메커니즘을 적용한다.
- Character CNN: OOV 단어 내 문자들을 vanilla CNN의 입력값으로 활용하여 문자 임베딩 벡터를 생성한다.
- Aggregator와 Character CNN의 출력을 결합하여 최종 OOV 단어에 대한 임베딩 벡터를 생성한다.
Deep learning based language models
언어 모델의 변천사와 상세한 구조는 별도 포스팅에 게시할 예정
LSTM
기존 vanilla RNN의 장기 의존성 문제(시퀀스의 길이가 길어질수록 기울기 소실 문제로 인해 앞의 정보가 뒤로 충분히 전달되지 못하는 현상) 보완
- 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 정보는 삭제하고 이후의 결정에 필요한 정보는 업데이트한다.
Transformer
기존 LSTM 모델이 입력 시퀀스를 순차적으로(좌에서 우 또는 우에서 좌) 처리함으로써 전체 문맥을 고려하지 못하는 문제 보완
- 한 단어를 학습하기 위해 자기 자신과 이전의 모든 문맥을 고려하는데, 셀프 어텐션(self-attention) 기법을 차용하여 컴퓨팅 비용을 줄이고 병렬 처리를 강화한다.
GPT-2
트랜스포머 기반 생성적 언어 모델
- 다음 단어를 예측하는데, 미세조정(fine-tuning) 없이도 과제를 수행하는 제로샷 러닝(zero-shot learning) 성능 강조
cf) BERT: 양방향 셀프 어텐션(bidirectional self-attention) 기법으로 한 단어를 학습하는 데 문장 전체의 문맥을 고려, 자연어 이해 능력을 대폭 향상시켰다. 사전 학습 목표를 Masked Language Model (MSM), Next Sentence Prediction (NSP)로 설정한다.
RoBERTa
BERT 사전학습 최적화 모델
- BERT의 NSP 목표를 제거하고 더 큰 배치 사이즈와 학습률을 사용하여 사전 학습을 최적화한다.
DistilBERT
소형 범용 자연어 이해 모델
Electra
BERT 사전학습 저비용(컴퓨팅 리소스) 모델
- BERT의 기존 MSM 목표에서 단어 하나를 마스킹하는 대신 가능성 있는(likely) 토큰들로 대체함으로써 훈련 비용은 절감하고 성능은 개선한다.
Intrinsic Evaluation
Dataset
인위적으로 생성한 OOV 단어인 Chimera를 사용한다. 하나의 Chimera는 실제 단어 두 개의 의미를 병합한 것이며, 임베딩 모델은 2개, 4개, 또는 6개 문장으로부터 Chimera의 의미를 유추하게 된다. 사람이 해당 문장들로부터 유추한 Chimera의 의미와 주어진 probe words의 의미 간 유사도(human annotated similarities)가 데이터셋에 포함되어 있다.

평가 방식
- Twitter7(T7) 데이터셋을 학습한 FastText 모델로부터 Chimera 데이터셋 내 문장들의 단어 임베딩을 획득한다.
- 평가의 대상이 되는 DL 모델들은 제각기 방식으로 Chimera가 포함된 문장들의 임베딩 벡터를 구한다. 이 벡터들의 평균이 Chimera의 임베딩 벡터가 된다.
- 구한 Chimera의 임베딩과 probe words의 임베딩들 간의 코사인 유사도를 계산한다. DL 모델의 성능은 해당 코사인 유사도와 human annotated similarities 간의 스피어먼 상관 계수(Spearman correlation)로써 평가한다.
Baseline methods
- Oracle: Chimera의 임베딩 벡터는 Chimera를 이루는 실제 단어 두 개의 임베딩 벡터의 평균 (performance upper bound)
- Sum: Chimera가 포함된 문장의 임베딩 벡터는 문장 내 단어들의 임베딩 벡터의 합
- Average: Chimera가 포함된 문장의 임베딩 벡터는 각 문장 내 단어들의 임베딩 벡터의 평균
Results
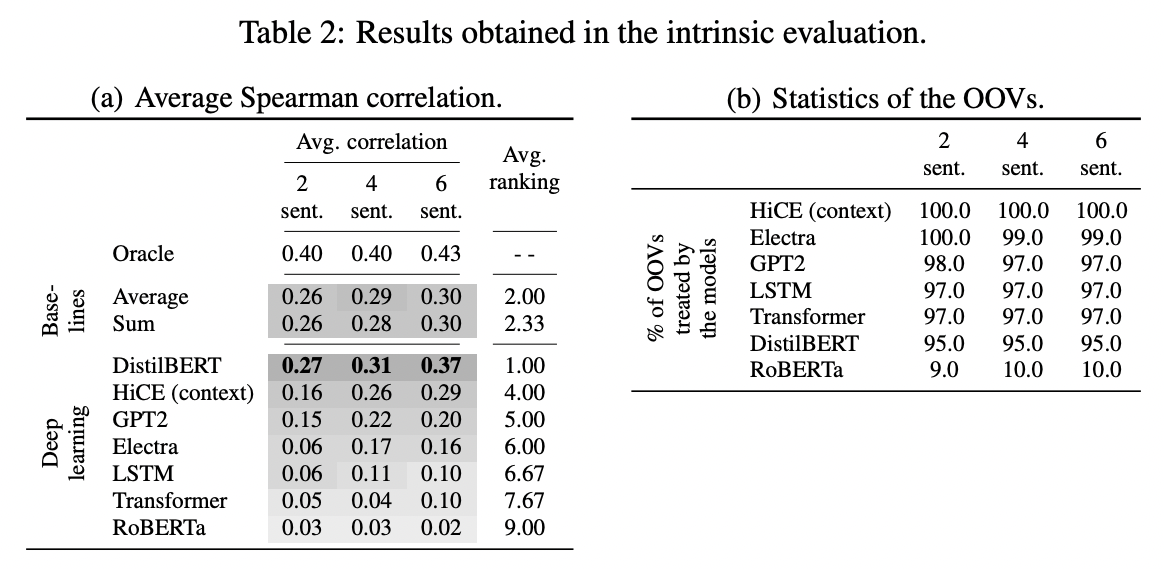
- DistilBERT가 최고성능
- RoBERTa는 OOV 단어 10%만 처리하는 안 좋은 성능
- GPT2, LSTM, Transformer는 OOV 양쪽 문맥을 모두 고려하지 않고 왼쪽 문맥만 고려하므로 문장 맨 처음에 등장하는 OOV 단어는 처리하지 못한다.
Extrinsic Evaluation
문서의 임베딩 벡터들은 Intrinsic Evaluation에서와 동일하게 FastText로부터 얻는다.
Baseline methods
- Sum: OOV는 문서 내 단어들의 임베딩 벡터의 합으로 표현
- Average: OOV는 문서 내 단어들의 임베딩 벡터의 평균으로 표현
- Zero: OOV는 영벡터로 표현
- Random: 모든 OOV는 동일한 랜덤 벡터로 표현
- FastText: OOV는 FastText로부터 얻은 임베딩 벡터로 표현
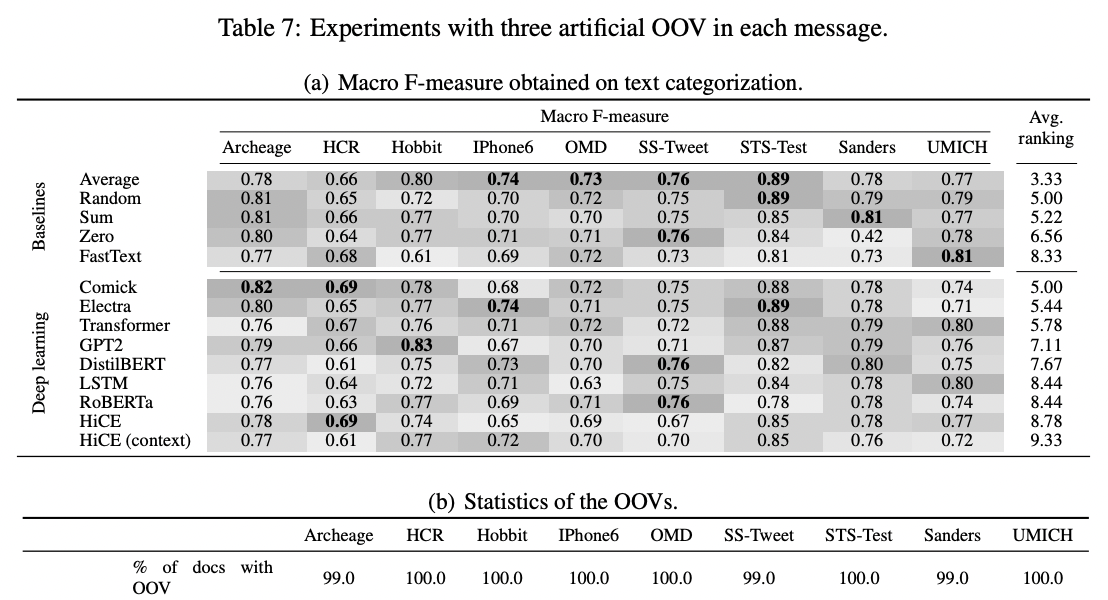
Results: Text categorization
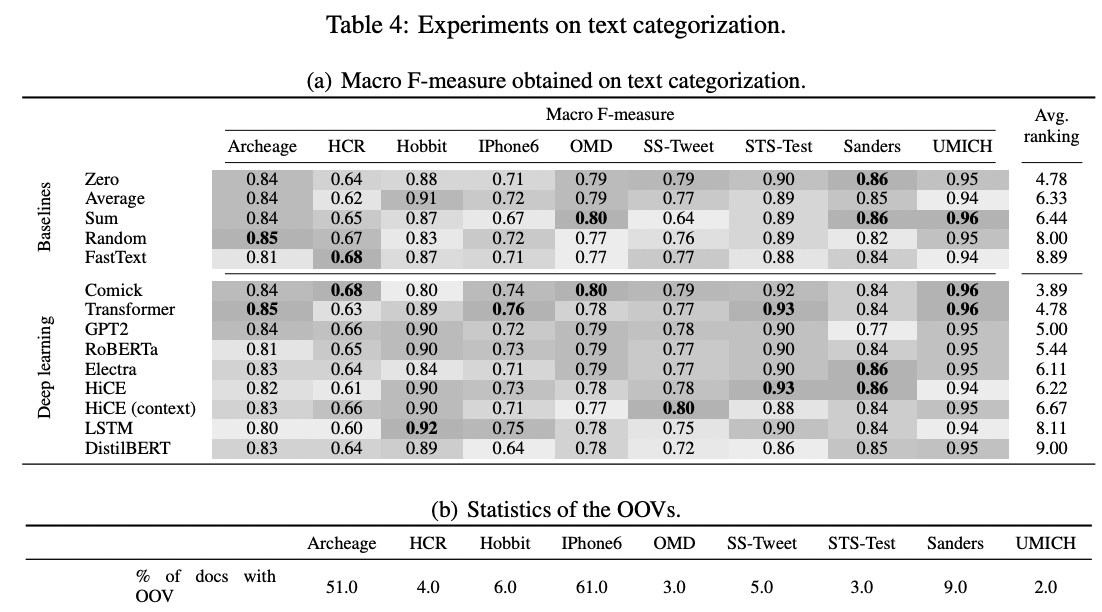
감성 분석 과제에 한정
- Global하게 성능을 압도하는 DL 모델은 없으나, 대체로 Comick이 준수한 결과를 보인다.
- 일부 baseline 기법(특히 average)들이 우위를 차지하는 결과를 보인다.
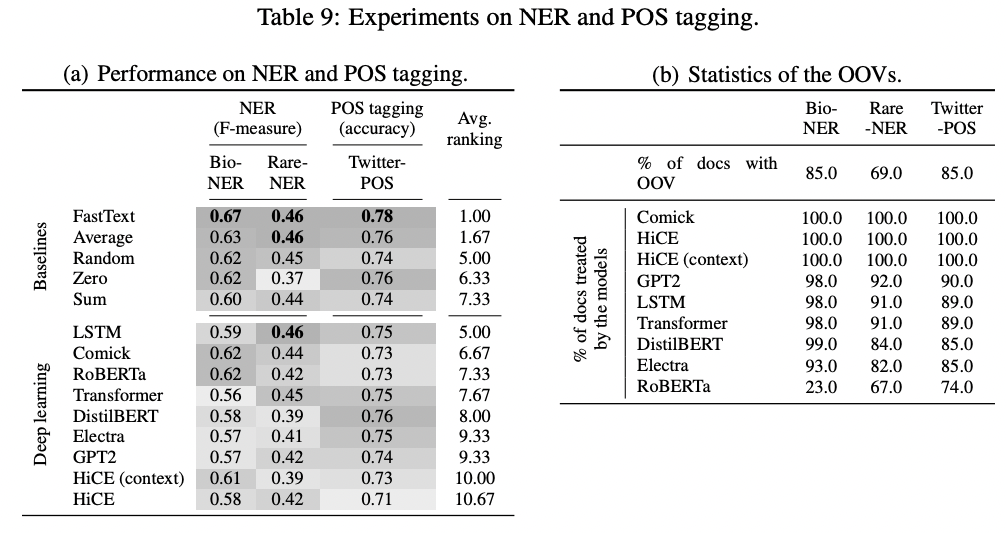
Results: NER and POS tagging
Named Entity Recognition (NER): 문장 내 개체(entity) 위치 및 분류
part-of-speech (POS) tagging: 품사 분석
- baseline 기법 중 하나인 FastText가 최고성능
- Comick이 여기서도 준수한 성능
- Text categorization 데이터셋에서보다 OOV 단어가 더 많다.
- DL 모델들의 성능 순위를 보면, 해당 과제에서는 OOV의 문맥을 이해하는 것보다 구조적 특성을 십분 활용하는 것이 더 중요해보인다.
Conclusion
DL을 이용한 OOV 처리는 golden rule이 아니고, 안정적이지 못한 성능을 보여줄 때가 많다.
- 데이터셋에 OOV가 많은지 적은지
- 데이터셋이 특정 도메인에 집중되었는지
- 모델이 noisy한 데이터셋에 훈련되어 양질의 임베딩 벡터를 생산하는 데 지장이 있는지
위와 같이 데이터셋의 특성을 고려하여 OOV 처리에 고려해야 하는 요소들을 잘 파악하고 DL 모델 구조를 설계해야 한다.
