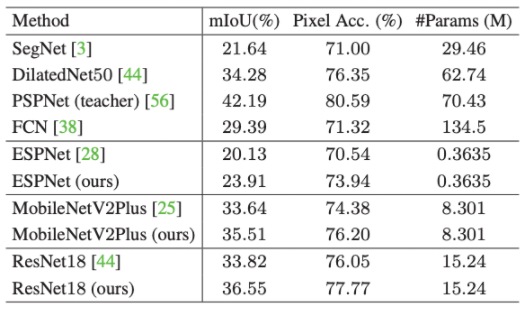
이 논문은 semantic segmentation 분야에 있어서 지식증류 기법(Knowledge Distillation)을 이용하였다.
Main Contribution
- Knowledge Distillation을 Semantic Segmentation 분야에 이용하였다.
- GAN 구조를 이용하였다.
Distillation Framework
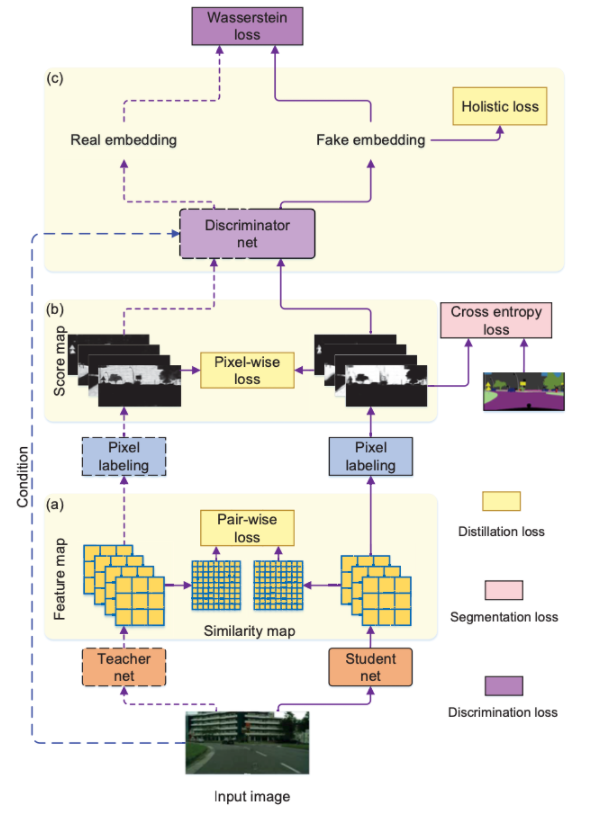
Knowledge Distillation
이 논문에서 제시하고 있는 Knowledge Distillation은 총 3가지 loss를 이용한다. Pixel-wise distillation, Pair-wise distillation, Holistic dilstillation 이 3가지 loss를 이용해 지식 증류를 진행한다.
Pair-wise distillation
이 과정에서는 teacher network에서 나온 feature map과 student network에서 나온 feature map을 비교하여 loss를 구한다. 이때의 feature map은 segmentation head의 직전 feature를 추출하여 비교한다.
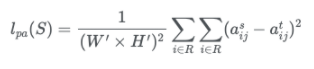
Pixel-wise distillation
복잡한 teacher network에서 생성된 pixel에 해당하는 class probability를 student network에 transfer한다. 이때 각각의 probability를 transfer 해야하므로 두 확률분포의 차이를 계산하는데 사용하는 쿨백-라이블러(Kullback-Leibler divergence, KLD)를 사용하여 loss를 계산한다.
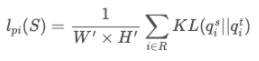
Holistic distillation
holistic distillation은 conditional generative adversarial learning의 개념이 들어오게 된다. 하나의 인풋 이미지를 가지고 teacher network에서 나온 output을 real로 student network에서 나온 output을 fake로 하여 두개를 discriminator가 얼마나 잘 매칭하는지를 판단하게 된다.
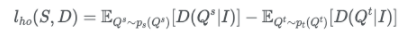
최종적인 loss는 다음과 같다.
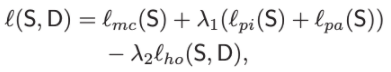
일반적인 cross entropy loss와 각각의 distillation에서 나온 loss들을 계산하여 최종 Loss를 구한다.
Experiments
이 논문에서 사용한 데이터셋은 Cityscapes, CamVid, ADE20K 데이터셋을 이용했다.
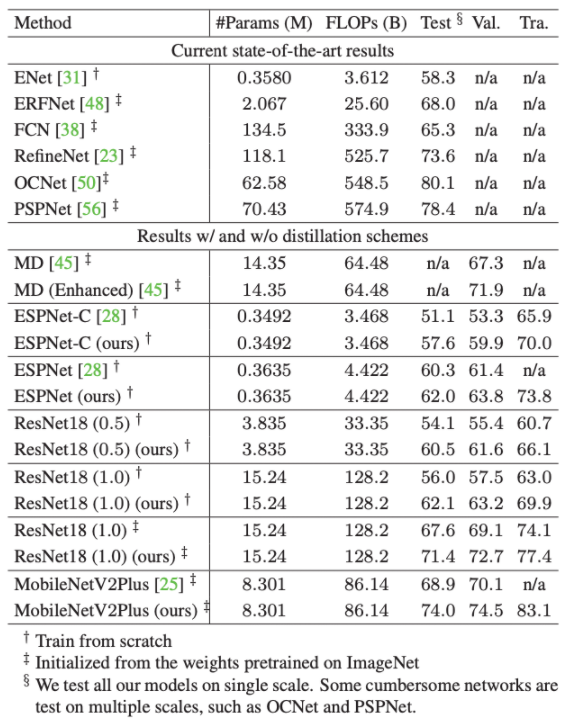
Cityscpaes
Camvid
ImN : imageNet, unl : unlabeled street scene dataset sampled from Cityscapes
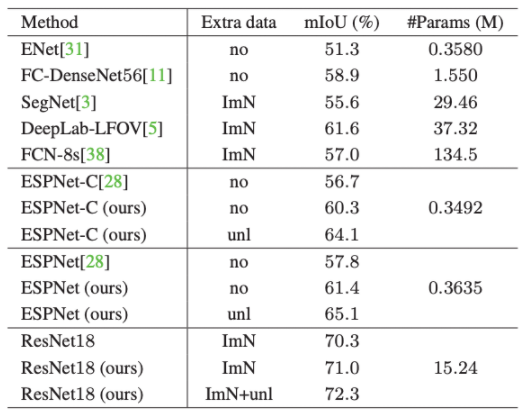
ADE20K