선형회귀가 숫자를 통한 분석이었다면, 이번엔 범주형 자료를 분석하는 로지스틱회귀를 배웠다.
로지스틱회귀는 Accuracy(정확도)와 F1-score를 통해서 정확도와 설명력을 확인할 수 있었다.
데이터 분석의 업무에서 모델링은 사실 일부이고, 단순하다고 한다. 진짜는 데이터 전처리와 EDA를 통한 모델링에 적합한 데이터를 만들어 내는 것이다.
데이터 전처리 작업이 주로 이루어지며 반복과정이라는 것으로 이해했다.
오늘 로지스틱회귀는 kaggle 데이터셋(타이타닉 생존현황)을 활용해서 해보았다.
일련의 과정들을 손코딩하면서 머리로 이해하려고 노력했다.
로지스틱 회귀
손코딩 과정과 해설 정리
# 필요한 라이브러리 호출
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
titanic_df = pd.read_csv('csv파일경로', encoding='utf-8')
titanic_df.head(5)
가설을 설정
: 비상상황 특성상 여성을 배려해서 많이 생존
확인방법 두가지
1. pivot table
2. 그래프
# pivot table을 활용
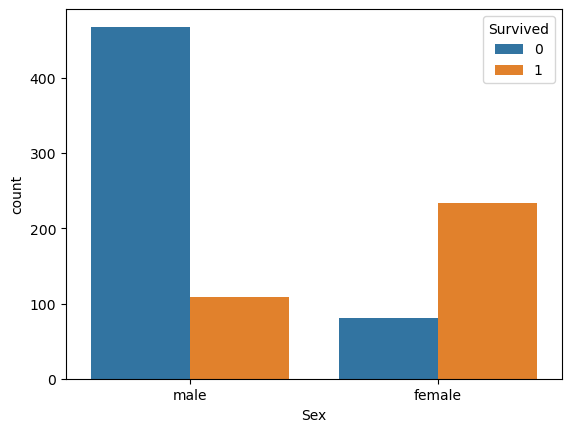
pd.pivot_table(data= titanic_df, index = 'Sex', columns= 'Survived', aggfunc='size')
# seaborn 그래프를 활용
import seaborn as sns
sns.countplot(titanic_df, x = 'Sex', hue = 'Survived')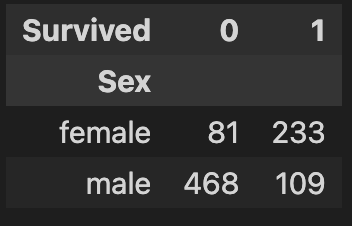
데이터 결측치 확인
titanic_df.info()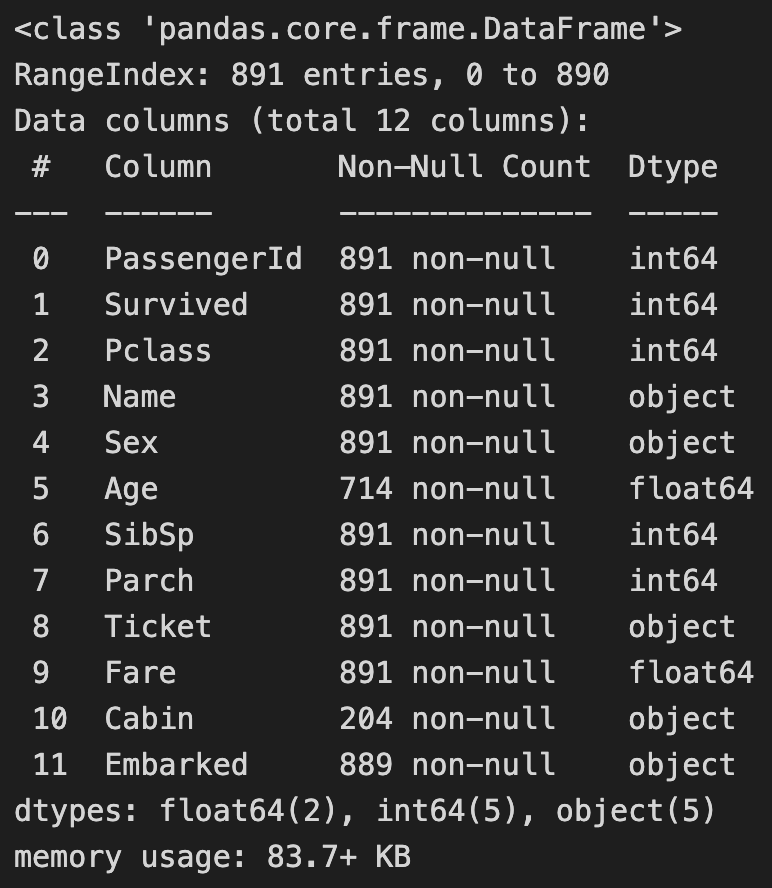
요금과 생존과의 관계
# X변수: Fare, Y변수: Survived
X_1 = titanic_df[['Fare']]
y_true = titanic_df[['Survived']]
# 산점도
sns.scatterplot(titanic_df,x = 'Fare', y = 'Survived')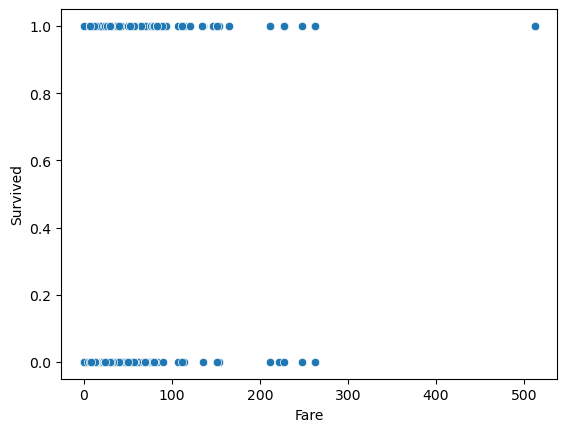
# 요금에 따른 사람 수 분포
sns.histplot(titanic_df, x = 'Fare')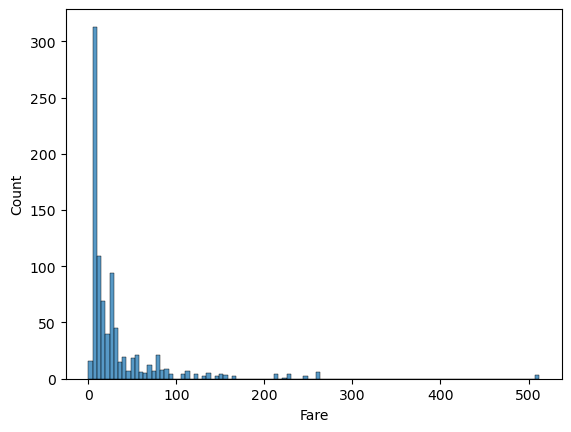
단순 로지스틱 회귀
from sklearn.linear_model import LogisticRegression
# X_1 = titanic_df[['Fare']]
# y_true = titanic_df[['Survived']]
# 회귀모델을 설정하고 fit함수로 모델을 돌림
model_lor = LogisticRegression()
model_lor.fit(X_1, y_true)회귀모델의 값들을 확인하는 함수를 설정
# 함수 설정
def get_att(x):
#x에 모델(모델링한 변수)을 넣기
print('클래스 종류', x.classes_)
print('독립변수 갯수', x.n_features_in_)
print('들어간 독립변수(x)의 이름', x.feature_names_in_)
print('가중치', x.coef_)
print('바이어스', x.intercept_)
# 함수실행
get_att(model_lor)
정확도 & F1 - score
# 라이브러리 함수로 결과를 볼 수 있게 함수 설정
from sklearn.metrics import accuracy_score, f1_score
def get_metrics(true, pred):
print('정확도', accuracy_score(true, pred))
print('f1-score', f1_score(true, pred))# 예측값을 predict 함수로 변수 지정
y_pred_1 = model_lor.predict(X_1)
# 실제값과 예측값으로 결과 보여주는 함수 실행
get_metrics(y_true, y_pred_1)
-> 요금과 생존과의 관계가 좋지 않다.(정확도는 %, F1-score는 0~1, 1과 가까울수록 설명력이 높음)
범주형 자료를 활용한 로지스틱 회귀
- Y(Survived): 사망
- X(수치형) : Fare
- X(범주형): Pclass(좌석등급), Sex
범주 데이터(성별)를 함수를 이용하여 0(사망)과 1(생존)으로 구분
def get_sex(x):
if x == 'female':
return 0
else:
return 1
# apply함수로 'Sex'를 get_sex함수로 돌린 결과를 'Sex_en'으로 컬럼 생성
titanic_df['Sex_en'] = titanic_df['Sex'].apply(get_sex)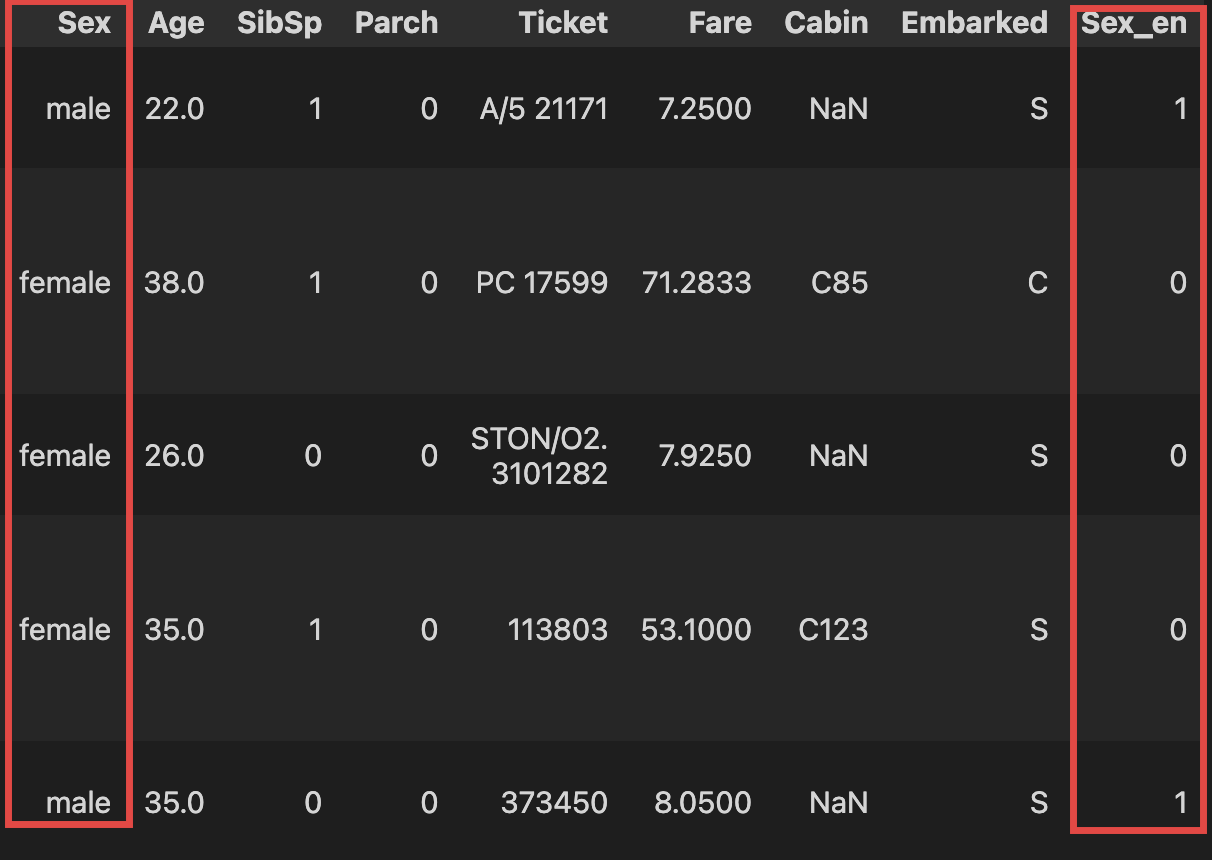
# X_2 에 실제값(Pclass, 성별, 요금)을 할당
X_2 = titanic_df[['Pclass', 'Sex_en', 'Fare']]
# y_true 에 생존 여부 할당
y_true = titanic_df[['Survived']]
# 새로운 모델 생성
model_lor_2 = LogisticRegression()
# X_2와 y_true의 모델링
model_lor_2.fit(X_2, y_true)# 모델링 결과 보기
get_att(model_lor_2)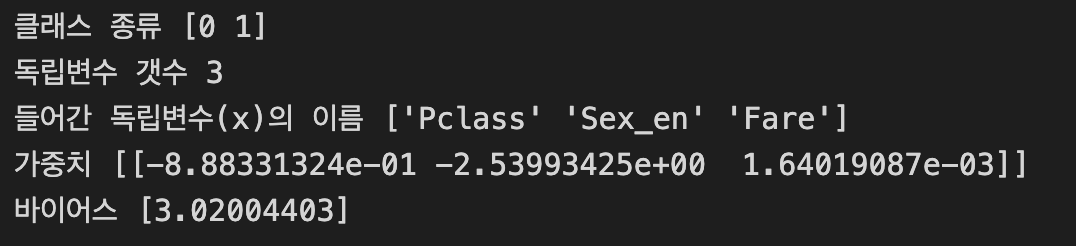
예측치 확인
y_pred_2 = model_lor_2.predict(X_2) y_pred_2[:10]
-> 독립변수 3개로 돌린 로지스틱회귀모델의 생존 여부 예측값

** 비교(단순로지스틱회귀모델)
y_pred_1[:10]
-> 독립변수의 차이로도 모델링 예측결과값이 차이가 상당히 많이 난다.

독립변수 차이의 의한 결과 차이
# X변수가 Fare
get_metrics(y_true, y_pred_1)
# X변수가 Pclass, Sex, Fare
get_metrics(y_true, y_pred_2)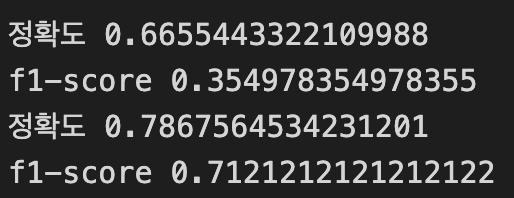
예측 확률 보기(생존 여부)
- predict_proba()
# 각 데이터 Y(Survived)=1(생존)인 확률 뽑아내기(생존할 확률)
model_lor_2.predict_proba(X_2)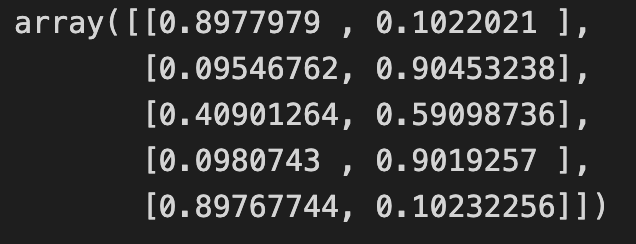
# 예측값
y_pred_2[:5]
-> 왼쪽 값이 Y=0 즉, 사망할 확률 / 오른쪽 값 Y=1, 생존할 확률을 보여준다.

Data analyst를 향해 도전하는 이야기