1.1 기본 컨셉
- 전문 검색이 가능하며 다양한 쿼리, 어널라이저를 적용하여 원하는 형태로 검색을 유도할 수 있음
- 분산 처리 : 데이터를 여러 노드에 분산
- 고가용성 제공 : 일부 노드에 장애가 발생해도 레플리카를 통해 장애 없이 서비스를 지속시킬 수 있음. 이를 자동으로 수행함
- 수평적 확장성 : 트래픽, 데이터 증가와같은 더 많은 처리능력이 요구되면 쉽게 클러스터 확장이 가능
- json 기반 rest api 제공
- 데이터 안정성 : 색인 요청 후 200 OK를 받았다면 확실히 디스크에 기록됨
- 다양한 플러그인을 통한 기능 확장 지원
- 준실시간 검색 가능
- 트랜잭션 지원X
- 조인 불가능
1.2 라이선스 관련
aws와 분쟁으로 elastic 라이선스를 따름
7.1 이전 버전은 sspl 라이선스로 오픈소스로 사용가능
Summary
2021년 오픈소스를 상용화하여 상품형태로 제공하는일로 라이선스 변경이 생겼다.
현재는 ①Elastic 라이선스, ②SSPL중 원하는 라이선스를 선택할 수 있다.
대부분의 경우 소스코드를 직접 빌드하는 형태가 아니기에, Elastic Liense 2.0(ELv2) 라이선스가 채택될(할) 것이다.
해당 라이선스는 aws의 elasticsearch처럼 오픈소스를 상용화하여 상품 형태로 제공할 수 없으며, 라이선스 키 변경을 통한 유료 기능 사용 행위는 라이선스에 위배된다.
그 외에는 사용,수정,파생 작품 생성 및 재배포 등 자유롭다.
2.1.4 문서 검색
텍스트와 매칭되는 문서를 찾는 것이 아니라 문서를 분석해서 역색인을 만들어 두고 검색어를 분석해서 둘 사이의 유사도가 높은 문서를 찾는 것이다.
2.3.1 루씬 Flush (ES Refresh에 해당)
- 문서 색인 요청이 오면 루씬은 문서를 분석하여 역색인을 생성
- 이 역색인은 처음에 메모리 버퍼에 저장
- 메모리 버퍼에 들고있다가 주기적으로 디스크에 flush
- 메모리 버퍼의 내용을 시스템의 페이지 캐시로 쓰는 작업을 Flush라고함
- Flush 후에는 새로운 세그먼트가 생성되어 검색이 가능
- 하지만 이 단계에서는 아직 데이터가 물리적 디스크에 완전히 저장된 것은 아님
❖ 메모리 버퍼
임시 저장 공간...
디스크의 입출력 효율을 높이기 위한 것
쓰기 성능이 빠르며, 문서를 모아서 한 번에 처리
❖ 시스템의 페이지 캐시
남는 메인메모리 공간을 이용해 사용된 파일들을 캐싱해놓는데, 이를 page cache라고 한다.
물리 디스크에 바로 쓰는 것보다 비교적 비용이 적고 세그먼트가 생성되었으므로 검색이 가능한 상태가 된다. 검색은 가능하지만 캐시기때문에 데이터 유실 위험이 있다.
❖ flush 트리거 조건
a) 메모리 버퍼가 가득 찼을 때
b) 일정 시간이 경과했을 때
c) 특정 수의 문서가 추가되었을 때
d) 명시적으로 flush()를 호출했을 때
❖ default refresh interval 값
1s
2.3.2 루씬 Commit (ES Flush에 해당)
Commit은 페이지 캐시의 데이터를 실제 물리적 디스크에 안전하게 저장하는 작업이다.
이 과정에서 fsync 시스템 콜을 사용하여 페이지 캐시와 디스크의 내용을 동기화한다(싱크를 맞춤).
Commit은 Flush보다 비용이 많이 드는 작업이지만, 데이터의 영구성을 보장한다.
엘라스틱서치의 flush 작업은 내부적으로 이 루씬 commit을 거친다. 비용이 많이 들기에 적절한 주기로 수행된다.
Lucene은 색인된 문서가 운영체제의 페이지 캐시에 저장되었을 뿐만 아니라 디스크에 영구적으로 저장되었음을 보장하고, 데이터 손실을 방지한다.
❖ 흐름
메모리 버퍼 → 시스템 캐시 → 물리적 디스크 순으로 데이터가 이동
❖ fsync 시스템 콜이란?
파일의 내용을 디스크에 영구적으로 기록하는데 사용되는 시스템 콜
파일의 내용을 운영체제의 페이지 캐시에서 디스크로 복사하고, 디스크에 데이터를 기록후 디스크의 헤더(파일의 크기,내용,형식,생성,수정 날짜, 권한에 대한 정보)를 업데이트한다.
❖ default flush_threshold_size 설정 값
512mb. translog가 이 크기에 도달하면 flush 발생

2.3.5 translog(작업로그)
es flush는 루씬 commit을 수행하고, 새로운 translog를 만드는 작업이다.
trnaslog에 기록까지 끝난 이후에야 작업 요청이 성공으로 승인된다.
백그라운드에서 주기적으로 수행되며 translog의 크기를 적절한 수준으로 유지한다.
(크기가 너무 커지면 샤드 복구에 시간이 오래 걸리기 때문이다.)
❖ translog 사용 이유
데이터 안정성 때문이다.
메모리 캐시에만 기록한 상태이기 때문에 서버가 다운되거나 장애가 나면 데이터가 그대로 유실된다.
그래서 만약 유실됐다면 기록해뒀던 translog를 보고 데이터를 복구한다.
이것이 es가 고가용성을 내세우는 이유 중 하나다.
2.3.3 세그먼트
-
루씬의 flush, commit 작업을 거치면, 디스크에 기록된 파일들이 모이면 세그먼트라는 단위가 된다.
-
세그먼트 자체는 불변인 데이터로 구성돼 있다.
-
새로운 문서가 들어오면 새 세그먼트를 생성한다. 기존 문서를 삭제하는 경우 삭제 플래그만 표시해 둔다.
-
업데이트가 발생하면 삭제 플래그를 표시하고 새 세그먼트를 생성한다.
-
불변인 세그먼트의 개수를 무작정 늘려갈 수 없기에 루씬은 중간중간 적당히 세그먼트의 병합을 수행한다. 이때 삭제 플래그가 표시된 데이터를 실제로 삭제하는 작업도 수행한다.
-
세그먼트 병합은 비싼 작업이지만 일단 병합을 하고 나면 검색 성능의 향상을 기대할 수 있다.
-
forcemerge API를 통해 명시적으로 세그먼트 병합을 수행할 수도 있다. 다만 명시적인 세그먼트 병합은 더 이상 추가 데이터 색인이 없을 것이 보장될 때 수행해야 좋다.
- 크기가 큰 세그먼트가 이미 존재하는 상황에서 데이터 변경으로 작은 세그먼트가 발생하면 병합 대상 선정에서 영원히 누락될 수도 있기 때문이다.
- 병합 정책은 비슷한 크기의 세그먼트를 우선적으로 병합
3.1.1 number_of_shards
클러스터에 샤드 숫자가 너무 많아지면 클러스터 성능이 떨어진다. 특히 색인 성능이 감소한다.
그러나 인덱스당 샤드 숫자를 적게 지정하면 샤드 하나의 크기가 커진다.
각 샤드의 크기가 지나치게 커지면 이 역시 문제가 된다. 장애 상황 등에서 샤드 복구에 너무 많은 시간이 소요되고 특히 클러스터 안정성이 떨어진다.
3.1.2 number_of_replicas
0으로 설정하면 레플리카 샤드를 생성하지 않고 프라이머리 샤드만 생성한다.
대용량 데이터 색인 작업 완료 후 레플리카 생성하는 순서가 좋을 것 같다. 쓰기성능을 올릴 수 있음.
3.2.2 필드 타입
nested 타입
nested 타입은 object 타입과는 다르게 배열 내 각 객체를 독립적으로 취급한다.
object 필드 값들은 실제로 하나의 도큐먼트 안에 전부 포함되어 있다.
객체 배열의 각 객체를 내부적으로 별도의 루씬 문서로 분리해 저장한다.
배열의 원소가 100개라면 부모 문서까지 101개의 문서가 내부적으로 생성된다.
특수하기에 전용 쿼리를 사용해야한다.
query:{nested:spec,query....
상세한 예제와 설명 : https://esbook.kimjmin.net/07-settings-and-mappings/7.2-mappings/7.2.5-object-nested
3.2.3 doc_values
keyword 타입은 doc_values vs text 타입은 fielddata
검색은 역색인을 기반으로 한 색인을 이용한다. 텀을 보고 역색인에서 문서를 찾는 방식이다.
그러나 정렬,집계,스크립트 작업 시에는 접근법이 다르다. 문서를 보고 필드 내의 텀을 찾는다.
디스크를 기반으로 한 자료 구조로 파일 시스템 캐시를 통해 효율적으로 정렬,집계,스크립트 작업을 수행할 수 있게 설계됐다.
3.2.4 fielddata
text필드를 대상으로 정렬,집계,스크립트 작업을 수행할 때 fielddata라는 캐시를 이용한다.
정렬과 집계, 스크립트 작업을 수행할 때 doc_values와 동작 차이가 있다.
역색인 전체를 읽어 힙 메모리에 올린다. 때문에 oom 문제를 발생시킬 수 있다.
기본으로 비활성화 상태다.
위 작업의 대상이라면 text타입보다 keyword필드를 쓰는게 낫다.
doc_values vs fielddata
docvalues : 디스크 기반이며 파일 시스템 캐시를 활용. 기본적으로 활성화
fielddata : 메모리에 역색인 내용 전체를 올린다. oom 유의. 기본적으로 비활성화
3.2.5 _source
문서 색인 시점에 es에 전달된 원본 json 문서를 저장하는 메타데이터 필드다.
디스크를 많이 사용하기에 비활성화할 수 있다.
그러나 이러면 많은 문제가 발생한다.
색인 업데이트 과정에서 기존 문서의 내용을 확인하는데 이 필드를 본다. 그래서 비활성화 시 reindex api도 사용할 수 없다.
인덱스 코덱 변경
다른 성능을 휘생해 디스크 공간을 절약해야만 하는 상황이라면 _source의 비활성화보다는 차라리 인덱스 데이터 압축률을 높이는 편이 낫다고 공식문서에서 가이드한다.
codec : best_compression
3.3.2 캐릭터 필터
텍스트에 특정한 문자를 추가, 변경, 삭제
ex. html strip, mapping, pattern replace
3.3.3 토크나이저
ngram 토크나이저
텍스트를 min_gram 값 이상 max_gram 값 이하의 단위로 쪼갠다.
token_chars라는 속성을 통해 토큰에 포함시킬 타입의 문자를 지정할 수 있다.
- Letter : 언어의 글자로 분류되는 문자
- Digit : 숫자로 분류되는 문자
3.3.4 토큰 필터
토큰 스트림을 받아서 토큰을 추가 변경 삭제한다.
- lowercase/uppercase
- stop : 불용어를 지정하여 제거
- synonym : 유사아ㅓ 사전 파일을 지정하여 지정된 유의어를 치환한다.
- stemmer : 어간 추출. 한국어는 지원 X
3.3.9 노멀라이저
어널라이저와 비슷한 역할을 하나 적용 대상이 text 타입이 아닌 keyword 타입의 필드라는 차이다. 단일 토큰을 생성한다.
노멀라이저는 토크나이저 없이 캐릭터 필터, 토큰 필터로 구성된다.
빌트읜 노멀라이저는 lowercase밖에 없다.
3.4.2 컴포넌트 템플릿
인덱스 템플릿을 많이 만들어 사용하다 보면 템플릿 간 중복되는 부분이 생긴다.
이런 중복 부분을 재사용할 수 있는 작은 템플릿 블록으로 쪼갠 것이 컴포넌트 템플릿이다.
ex. mapping, setting 분리
composed_of:[세팅, 매핑]
3.4.4 동적 템플릿
인덱스 템플릿과 다르게 매핑 안에 정의한다.
ex. *_text 필드 이름에 따라서 다르게 정의
3.5 라우팅
인덱스를 구성하는 샤드 중 몇 번 샤드를 대상으로 작업을 수행할지 지정하기 위해 사용하는 값이다.
es는 검색할 때 라우팅 값을 기입하지 않으면 전체 샤드를 대상으로 검색을 수행하고, 라우팅 값을 명시하면 단일 샤드를 대상으로 검색한다.
많은 데이터가 저장된 실제 운영 환경에서 검색을 수행한다면 라우팅 값을 지정했을 때와 안했을 때의 성능 차이는 매우 크다.
❖ 사용 예제
고객 ID를 라우팅 키로 사용하여 같은 고객의 데이터를 동일한 샤드에 저장
4.1.3 업데이트 api
detect_noop
변경이 필요하지 않은 변경 요청은 noop처리한다. result : noop
이유는 변경 요청에의해 새로운 세그먼트를 생성되는것을 막고자함
일반적인 상황에서 활성화하는 것이 좋다.
doc_as_upsert
upsert 진행하는 설정
4.3.10 bool 쿼리
filter context : 조건 만족여부만 판단. 쿼리 캐시 저장
query context : 유사도 산정 검색
search_type
유사도 점수를 계산할 때 각 샤드 레벨에서 계산을 끝낼지 여부를 선택
1. query_then_fetch : 기본 설정. 각 샤드 레벨에서 유사도 점수 계산을 끝냄. 점수 계산이 약간 부정확할 수 있지만 검색 성능의 차이가 크기 때문에 사용 추천
2. dfs_query_then_fetch : 모든 샤드로부터 정보를 모아 유사도 점수를 글로벌하게 계산. 유사도 점수 정확도가 올라가지만 검색 성능이 떨어진다.
원인
opensearch의 _expain api를통해 확인해보니 idf,tf이 다른 값으로 산정되었다.
ㄴ idf에서는 N, total number of documents with field( 213<->206 ) 값이 다르며
ㄴ tf에서는 avgdl, average length of field (2.3802817 vs 2.4320388)값이 다르다.
동일한 index임에도 다른 값을 가지는 이유는 각 샤드별로 스코어링하고 결과를 취합하는 방식으로 위와같은 이슈가 있다.
_explain api를 통해 검색하면 어떤 노드, 어떤 샤드의 검색인지 알 수 있다.
ex1. "_shard": "[couponad_brand-1718346491703][1]"
ex2. "_shard": "[couponad_brand-1718346491703][0]"
근거
[1] https://www.elastic.co/kr/blog/understanding-query-then-fetch-vs-dfs-query-then-fetch
[2] https://www.elastic.co/kr/blog/practical-bm25-part-1-how-shards-affect-relevance-scoring-in-elasticsearch
[3] https://cjwoov.tistory.com/38
[1]
Elasticsearch faces an interesting dilemma when you execute a search. Your query needs to find all the relevant documents…but these documents are scattered around any number of shards in your cluster.
elasticsearch는 검색을할 때 딜레마가 있음. 검색 요청은 모든 연관 문서를 찾아야하는데, 이 문서들은 클러스터 내 샤드에 분산되어있다.
Each shard is basically a Lucene index, which maintains its own TF and DF statistics. A shard only knows how many times “pineapple” appears within the shard, not the entire cluster.
각 샤드는 자체 TF,DF 통계를하는 "루씬 인덱스"다. 샤드는 전체 클러스터가 아닌 각 샤드 내에 단어가 몇번 나타나는지 알 수 있다.
결론
대부분의 경우에는 문서가 충분하기 때문에 충분히 좋은 결과를 가진다. 하지만 드믈게 정확하지 않은 결과를 가질 수 있다.
Of course, better accuracy doesn’t come for free.
당연히 정확성은 무료가 아니다.
The prequery causes an extra round-trip between the shards, which could cause a performance hit depending on size of the index, number of shards, query rate, etc etc.
prequery는 샤드간 방문을 추가적으로 야기시키고, 이는 성능 문제를 야기시킬 수 있다.(ex. index 사이즈, 샤드 수, 질의율 등에 따라)
And in most cases, it is totally unnecessary…having “enough” data solves the problem for you.
하지만 대부분의 케이스에서 불필요하며, 충분한 데이터는 이 문제를 해결해준다.
But sometimes you’ll run into strange scoring situations, and in those cases, it’s useful to know how to tweak the search execution plan with DFS Query then Fetch.
하지만 가끔 이상한 스코어링 상황에 닥친다면, DFS쿼리를 사용하라.
대안
그럼에도 브랜드의 문서양이 많지않은 점
통합검색은 각 컬렉션별로 병렬로 실행되는 점
상품검색이 볼륨도 크고 2회이상 검색을 수행하기에 더 오래 소요되는 점
>> 즉, 브랜드 검색 수행시간이 늘어나도 크게 통합검색에 영향을 주지 않는다.
을 고려하여 브랜드 검색에만 해당 옵션을 적용 검토
또한 해당 옵션 적용을 검토하는 이유는 0.01단위로 정확한 랭킹 핸들링이 필요한 상황에서 다른 대안이 떠오르지 않음...
4.4.1 집계
집계는 크게 메트릭, 버킷, 파이프라인 집계로 분류된다.
4.4.2 메트릭 집계
- avg,max,min,sum 집계
- stats 집계
- cardinality 집계 : 지정필드가 가진 고유한 값의 개수
4.4.3 버킷 집계
- range 집계
- data_range 집계 : range와 유사하나 date 타입 필드를 대상으로 사용
- histogram 집계 : 버켓 간격을 지정하여 경계를 나눔
- date_histogram 집계
- terms 집계 : 각 샤드에서 size 개수만큼 term을 뽑아 결과가 정확하지 않음
- doc_count_error_upper_bound 필드는 오차 상한선을 의미
- sum_other_doc_count 필드는 최종적으로 버킷에 포함되지 않은 문서 수를 나타냄
- composite 집계 : sources로 지정된 하위 집계의 버킷 전부를 페이지네이션을 이용해서 순회하는 집계
4.4.4 파이프라인 집계
문서나 필드의 내용이 아니라 다른 집계 결과를 집계 대상으로 한다.
4.5 java client의 한계점
java client는 개발 초기 단계이며 지원하지 않는 기능이 많아 아직은 고수준 rest 클라이언트와 새 java client를 혼용해 사용하기도 한다.
미지원 기능 사례
json 파싱 및 indext 생성 부분. setting 설정 누락됨
5.2 클러스터 구성 전략
5.1.1 노드 설정과 노드 역할
❖ 현재 설정
cluster_manager,data,ingest,remote_cluster_client
- 마스터 후보 노드 : master를 지정하면 마스터 후보 노드가 된다. 후보 중 선거를 통해 마스터 노드가 선출된다. 인덱스 생성,삭제,샤드할당 등을 수행
- 데이터 노드 : 실제 데이터를 들고 있는 노드. 검색, 집계와 같이 데이터와 관련된 작업을 수행
- 인제스트 : 색인되기 전에 전처리를 수행하는 인제스트 파이프라인을 수행하는 노드
- (ingest 파이프라인을 사용하지 않더라도 시스템 인덱스가 사용하는 경우가 있어서 왠만하면 같이 설정 하는것이 좋음)
- 조정 노드 : 클라이언트의 요청을 받아서 다른 노드에 요청을 분배하고 최종 응답을 돌려주는 노드. 기본적으로 모든 노드가 조정 역할을 수행한다.
- 요청 라우팅 : 사용자의 요청을 받아 적절한 노드에 분배
- 쿼리 조정 : 검색 쿼리와 집계 요청을 조정하고 최정화 된 방식으로 분배
- 결과 병합 : 여러 데이터 노드에서 온 검색 결과를 병합하여 최종 결과 반환
- 기본적으로 모든 노드가 rest api 요청을 처리한다. 하지만 대규모 클러스터의 경우 마스터 또는 데이터 노드가 각자의 일을 하기도 바쁜데 rest api까지 처리하게 될 경우 과부하가 될 수 있으므로 rest api만 따로 처리하는 노드를 둔다.
- 로드밸런싱, 요청 라우팅, 요청 캐싱, 각 노드에서 계산된 결과에 대한 취합에 집중한다.
- 데이터 노드의 부하를 줄이고 검색 효율성을 높일 수 있다.
- 원경 클러스터 클라이언트 : 다른 es 클러스터에 클라이언트로 붙을 수 있는 노드. 다른 클러스터를 구축해 해당 클러스터를 모니터링하거나 클러스터간 검색을 할 때.
- 데이터 티어 : 데이터 노드를 용도/성능별로 hot-warm-cold-frozen티어로 구분해 저장하는 데이터 티어 구조 채택 시 사용하는 역할.
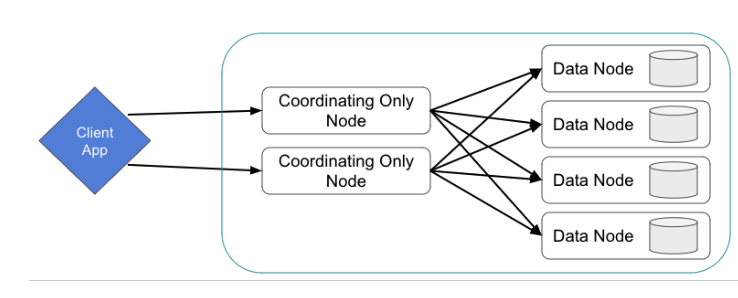
가이드 구조
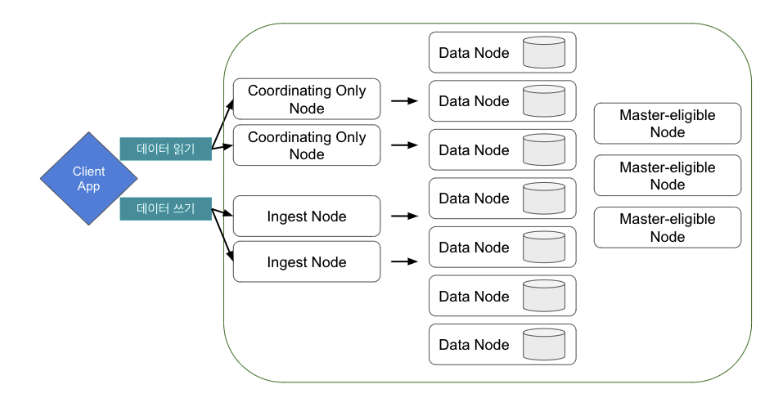
5.1.2 필요한 주요 설정
힙 크기
첫 번째로 최소한 시스템 메모리의 절반 이하로 지정해야 한다는 것이다.
시스템 메모리의 절반은 운영체제가 캐시로 쓰도록 놔두는 것이 좋다.
루씬이 커널 시스템 캐시를 많이 사용하기 때문이다.
두 번째로 힙 크기를 32gb 이상 지정하지 않아야 한다.
es에서는 512gb 이상의 고용량 메모리를 갖춘 서버를 사용하더라도 힙 크기는 32gb 아래로 설정하라고 가이드한다.
jvm이 힙 영역에 생성된 객체에 접근하기 위한 포인터를 ordinary object pointer라고 한다. 이 oop는 메모리 주소를 직접 가리킨다.
JVM은 32비트 JVM과 64비트 JVM이 별도로 제공됩니다. 하지만 32비트 JVM과 64비트 JVM 모두 기본적으로 32비트 주소값을 가지고 동작합니다. 그 이유는 모든 JVM이 기본적으로 32비트 Object Pointer를 사용하고 있기 때문입니다.
32비트 환경에서는 포인터 1개를 32비트로, 64비트 환경에서는 포인터 1개를 64비트로 표현한다.
32비트 환경에서는 4gb(2^32바이트)까지의 힙 영역을 사용할 수 있다.
4gb를 넘어서는 힙을 사용해야 한다면 32비트 oop로는 불가능하다. 64비트 oop를 사용해야 한다.
그러나 32gb 이내의 힙 영역에만 접근한다면 compressed oops라는 기능을 적용해 포인터를 32비트로 유지할 수 있다. 자바는 기본적으로 힙 영역에 저장하는 객체를 8바이트 단위로 정렬해 할당하기 때문에 객체 간의 주소는 항상 8바이트의 배수만큼 차이가 난다.
따라서 포인터가 메모리의 주소를 직접 가리키도록 하지않고 객체의 상대적인 위치 차이를 나타내도록 하면 포인터의 1비트가 1바이트 단위의 메모리 주소가 아니라 8바이트 단위의 메모리 주소를 가리키도록 할 수 있다. 이렇게 포인터를 인코딩하면 4gb가 아닌 8배인 32gb까지의 힙 메모리를 사용할 수 있다.
따라서 실제로 compressed oops 기능이 적용되는 힙 크기의 경곗값은 32gb보다 살짝 아래다.
jvm이 compressed oops를 사용할 수 있도록 해야 한다.
compressed oops를 사용하지 못하면 성능차이가 크다. 시스템 환경마다 다르기에 꼭 직접 확인해야 한다.
최신 JDK에서는 Compressed OOP가 기본 설정으로 동작하기 때문에 힙 크기를 32GB 이하로 설정하기만 하면 된다.
ex. 128gb 서버가 있다면, 2원칙에 의해 32gb 메모리를 설정하고 나머지는 루씬이 사용하도록 둬도 큰 낭비가 아니다.
참고 : https://icarus8050.tistory.com/53
스와핑
es는 스와핑을 사용하지 않도록 강력히 권고한다. 성능과 노드 안정성에 큰 영향을준다.
ms로 끝내야 할 gc를 분 단위까지 걸리게 만들기도 한다.
bootstrap.memory_lock 설정
true설정 지정한다.
프로세스의 주소 공간을 메모리로 제한시키고 스와핑되는 것을 막아준다.
vm.max_map_count
프로세스가 최대 몇 개까지 메모리 맵 영역을 가질 수 있는지를 지정한다.
file descriptor
이 값을 최소 65535 이상으로 지정하도록 가이드한다.
jvm 지정과 설정
내장 jdk를 사용하는것이 좋으며 힙 크기 외의 설정 변경은 지향
5.2.1 마스터 후보 노드와 데이터 노드 분리
상대적으로 데이터 노드가 죽을 확률이 높다.
만약 분리하지 않으면 마스터 역할이 제대로 수행되지 않아 클러스터 안정성이 매우 크게 떨어진다. 일부 데이터 노드에만 문제가 생기는것으로 끝날 수 있었을 상황이 클러스터 전체 장애 상황으로 커지게 된다.
서버를 매우 적게 써야 하는 상황이 아니라면 마스터 후보 노드와 데이터 노드를 분리하는 것이 낫다.
마스터 후보 노드는 데이터 노드보다 상대적으로 성능이 많이 낮은 서버를 사용해도 괜찮다.
데이터 노드처럼 디스크를 많이 사용하거나 메모리를 많이 필요로 하지 않는다.
6.1 클러스터 설정 API
GET _cluster/settings 을 통해 클러스터와 관련된 설정을 확인 및 변경할 수 있다.
{
"persistent":{}, // 클러스터를 전체 재시작해도 유지
"transient":{} // 클러스터 전체 재시작 시 사라짐
}
persistent 내용은 path.data 경로 내 파일로 저장된다.
6.3 인덱스 운영 전략
- 템플릿과 명시적 매핑 활용
- 라우팅 활용 : 서비스 요건과 데이터 특성 등을 면밀히 파악하고 어떤 값을 라우팅으로 지정해야 효율적일지 분석. 인덱스 매핑에서 라우팅을 강제할 수 있음
- 시계열 인덱스 이름 : 오래된 데이터를 백업하고 삭제하는 것이 편하다.
6.3.4 alias
한 alias가 하나 이상의 인덱스를 가리키도록 지정할 수 있다.
다만 여러 인덱스를 가리키는 alias는 단건 문서 조회 작업의 대상이 될 수 없다. 단일 인덱스를 가리키는 alias여야 한다.
업데이트,삭제 등 쓰기 작업의 경우 is_write_index를 true로 지정한 인덱스를 대상으로 작업한다.
만약 여러 인덱스를 가리키는 alias안에 해당 설정이 없다면 쓰기 작업을 할 수 없다.
6.3.5 롤오버
쓰기를 담당하는 인덱스 내 샤드의 크기가 너무 커지면 새로운 인덱스를 생성해서 같은 alias 안에 묶은 뒤 is_write_true를 새 인덱스로 옮기는 방식으로 운영한다.
롤오버는 이러한 작업을 한번에 묶어서 수행하는 기능이다.
롤오버를 수행할 alias 내 is_write_true 인덱스의 이름은 반드시 ^.*-\ㅇ+$ 패턴을 따라야 한다. ex) test-index-00001 가능하나 test-index 불가능
롤오버를 수행하면 test-index-00001->test-index-00002
6.3.6 데이터스트림
내부적으로 여러 개의 인덱스로 구성되어 있다.
검색을 수행할 때는 해당 데이터스트림에 포함된 모든 인덱스를 대상으로 검색을 수행하고, 문서를 추가 색인할 때는 가장 최근에 생성된 단일 인덱스에 새 문서가 들어간다.
반드시 인덱스 템플릿과 연계해서 생성해야 한다.
문서 추가는 가능하지만 업데이트 작업은 불가능하다.
6.3.7 reindex
원본 인덱스 내 문서의 _source를 읽어서 대상 인덱스에 새로 색인하는 작업이다.
만약 작업 도중 버전 충돌이 발생하면 해당 부분까지만 진행되고 취소된다.
이를 원치 않으면 conflicts값을 proceed로 지정해야 한다. (충돌 문서를 건너뛰고 다음 작업을 진행)
reindex vs shrink
reindex는 새 인덱스에 문서를 다시 새로 색인하는 과정이다.
shrink는 기존 인덱스의 세그먼트를 새 인덱스로 하드링크한다. 때문에 reindex에 비해 제약이 많다.
6.3.9 split으로 샤드 개수 늘리기
샤드 개수를 늘리면서 인덱스를 새로 생성하는 작업이다.
split역시 하드링크하는 방식으로 제약 사항이 많다.
6.3.10 다중필드
서비스중인 필드가 다른 타입의 필드형태로 추가가 필요할 때 유용하다.
6.3.13 대량 색인이 필요할 때
색인 도중 데이터를 조회할 필요가 없다.
refresh_interval : -1, number_of_replicas : 0
6.4.1 샤드의 크기와 개수 조정
샤드 숫자가 많아지면 클러스터 성능이 떨어진다.
샤드 숫자를 줄이면 샤드 하나당 크기가 커진다.
재기동이나 장애 상황 등에서 샤드 복구, 복제본 샤드 생성에 너무 많은 시간이 소요된다.
결국 밸런스가 중요하다.
샤드 하나의 크기를 일정 기준 이하로 유지해야 한다.
전체 샤드의 수를 체크하는 것은 그 다음이다.
샤드의 크기를 기준 크기 이하로 유지하는 선에서 전체 샤드 개수를 최대한 줄이는 방향으로 접근해야 한다.
샤드 하나당 20~40gb크기가 적절하다. 그러나 운영에서는 샤드 크기가 20gb만 되어도 느리고 꽤 무겁다.
get _cat/shards?v&s=store:desc
또한 힙 1gb당 20개 이하의 샤드를 들고있는 것이 적절하다.
ex. 32gb 힙 기준으로 노드당 640 샤드 이하다.
6.5 롤링 리스타트
운영중에 롤링 리스타트를 수행할 일이 많다. ex. 버전업, 플러그인 설치/삭제, 장애노드 복구 등
순서 : 샤드 할당 비활성화 -> flush -> 노드 재구동 -> 할동 재활성화 -> green 확인
6.6 스냅샷과 복구
단순 파일 시스템 자체 복제는 마지막 발버둥이다.
데이터를 백업하고 복구하는 데에는 공식 기능인 스냅샷을 사용하는것이 좋다.
6.7 명시적으로 segment 병합하기
세그먼트 병합으로 검색 성능 향상, 디스크나 메모리 절약등을 기대할 수 있다.
POST [인덱스명]/_forcemerge?max_num_segments=1
관리적인 목적으로 수행할 때는 대부분 1로 지정하면 된다.
더이상 세그먼트에 변경(추가/삭제/변경)이 없을때 수행하는것이 좋으며, 단일 세그먼트를 유지하는 것이 가장 좋다.
6.8 샤드 할당 필터링과 데이터 티어 구조
hw 특성이나 서버 물리적위치 이슈 등으로 샤드 할당 배분을 제어해야할 때가 있다.
각 노드별로 속성을 지정하여 원하는 속성에만 샤드를 할당하도록 설정할 수 있다.
그 외 클러스터 역할, 인덱스 단위로도 가능하다.
6.9 인덱스 생명 주기 관리
인덱스를 hot-warm-cold-frozen-delete 페이즈로 구분해서 지정한 기간이 지나면 인덱스를 다음 페이즈로 전환시키고 이때 지정한 작업을 수행하도록 하는 기능이다.
ex. 인덱스가 생성되어 hot 페이즈에서 매일 롤오버를 수행하고, 사이즈가 8g를 넘으면 롤오버를 수행한다.
생성된지 3일이 지나면 warm 페이즈로 전환하고 읽기 전용으로 바꾸고 단일 세그먼트로 강제 병합한다.
7일이 지나면 cold 페이즈로 전환한다. 상대적으로 성능이 떨어지는 노드로 이동시킨 다음 샤드 복구 우선순위를 낮춘다.
생성된지 30일이 지나면 delete 페이즈로 이동한다. 지정한 스냅샷 생명 주기 정책에서 스냅샷으로 백업될 때까지 기다렸다가 완료되면 삭제한다.
- hot : 읽기, 쓰기가 많음
- warm : 읽기 수행
- cold : 읽기가 가끔씩만 수행됨. 검색 속도 느림
- frozen : 읽기가 거의 수행되지 않음. 검색 속도 매우 느려도 됨
- delete : 삭제되어도 무방
6.10 서킷 브레이커
es는 과도한 요청이 들어왔을 때 이를 최대한 처리하다 죽는 정책이 아니라 처음부터 과도한 요청은 거부하는 정책을 채택했다.
노드가 중단되는 사태를 방지하는 것이 더 중요하다고 판단.
요청이 어느 정도의 메모리를 사용할지 예상하는 방법과 현재 노드가 사용중인 메모리를 체크하는 방법을 사용한다.
종류
- 필드 데이터 서킷 브레이커 : fielddata가 메모리에 올라갈 때 얼만큼의 메모리를 사용할지 예상한다. 기본값은 힙의 40%다. indices.breaker.fielddata.limit으로 경곗값을 넘기는 요청은 거부한다.
- 요청 서킷 브레이커 : 요청 하나의 데이터 구조가 메모리를 과하게 사용하는지 계산한다. 힙의 60%
- 실행 중 요청 서킷 브레이커 : 노드에 transport나 http를 통해 들어오는 모든 요청의 길이를 기반으로 메모리 사용량을 계산한다.힙의 100%
- 부모 서킷 브레이커 : 전체 메모리의 실제 사용량을 기준으로 동작한다.또한 다른 서킷브레이커가 산정한 예상 메모리 사용량의 총합도 체크한다.힙의 95%
- 스크립트 컴파일 서킷 브레이커 : 그 외에 스크립트 컴파일을 제한하는 브레이커
이 가운데 특히 실제 메모리를 체크하는 부모 서킷 브레이커의 효과가 좋다.
6.11 슬로우 로그 설정
검색이나 색인 작업 . 시너무 오랜 시간이 소요되면 별도로 로그를 남기도록 설정할 수 있다.
이 로그는 샤드 레벨에서 측정된다. 검색 요청 전체에 소요된 시간을 측정해 로깅하는 것이 아니다.
6.12 버전 업그레이드
es는 버전업이 상당히 빠르다.
때문에 메이저 버전을 놓치기 쉽다.
차이가 많이 벌어지면 운영에 참고할만한 레퍼런스,문서에 뒤쳐진다. 버그 수정, 성능 안정성 등의 혜택을 보지 못한다.
방법(롤링 리스타트 vs 풀 리스타트)
당연히 롤링 리스타트가 좋은 선택이다.
같은 메이저 버전끼리는 롤링 업그레이드를 할 수 있다.
메이저 버전 2개 이상 차이나면 풀 리스타트도 불가능한 경우가 많다.
천천히 중간 버전으로 업그레이드해가며 올리는 것이 안전하다.
6.12.2 롤링 업그레이드
마스터 후보 노드보다 데이터 노드부터 업그레이드를 수행하는 것이 좋다.
일반적으로 상위 버전의 노드는 하위 버전의 마스터 후보 노드에 붙을 수 있지만, 반대의 경우는 그렇지 않을 수 있다.
롤링 업그레이드는 롤링 리스타트의 흐름에서 노드 종료 후 업그레이드 진행 후 재가동이 이뤄진다고 보면된다.
버전 업그레이드는 실행할 바이너리를 교체하는 작업이다.
6.12.3 풀 리스타트 업그레이드
한대씩 수행하지 않고 일괄적으로 수행하는 것을 제외하면 롤링 업그레이드와 거의 같다.
7.3 자주 발생하는 장애 유형
7.3.1 키바나에서 과도한 요청 인입
키바나 사용자들은 집계나 정렬 등 무거운 요청을 판단할 수 없기에 사용자를 통제한다.
이런 무거운 쿼리를 요청하면 노드에 full gc가 일어나면서 stw 타임이 길어진다.
7.3.2 gc로 인한 stw 상황
fielddata 집계나 정렬, 키바나에서 인입되는 무거운 집계 작업 등을 수행하면 full gc가 일어나면서 stw 타임이 길어진다.
노드가 oom으로 죽거나 stw상태인 노드가 클러스터에서 제외되면 복제본 샤드를 새로 할당하며 부하가 가중되고 연쇄적인 장애가 발생할 수 있다.
최대한 빠르게 샤드 할당을 비활성화하고 -> 트래픽 유입을 막고 -> 노드 재가동
7버전 이상에서부터 이 문제가 크게 개선되었다. by 서킷 브레이커
7.3.3 디스크 풀 상황
비교적 사전 모니터링으로 회피하기 쉽다. 디스크 사용량이 높아지면 알람을 보내도록 설정한다.
기본적으로 95%가 넘으면 더이상 색인할 수 없게 설정되어있따.
7.3.4 미할당 샤드가 남았는데 샤드 할당이 더 이상 진행되지 않는 상황
장애 상황 처리, 설정 변경 등으로 노드를 재기동한 뒤 샤드 복구 단계에서 클러스터가 green으로 돌아오는 것을 기다릴 때가 있다.
그러나 미할당 샤드가 남아있음에도 불구하고 샤드 할당이 . 더이상 진행되지 않고 클러스터가 yellow 혹은 red 상태로 남아있을 때가 있다.
아래 명령어로 확인한다.
GET _cluster/allocation/explian?pretty
원인 해결 후 샤드 재할당을 요청한다.
POST _cluster/reroute?retry_failed=true
발생케이스로는 단순 최대 재시도 횟수가 다 찬 경우, 서킷 브레이커 등이 있다.
7.3.5 댕글링 인덱스
클러스터의 메타데이터에는 해당 인덱스와 샤드 정보가 없다면 es는 이들을 댕글링 인덱스와 샤드로 취급한다.
발생하는 가장 흔한 사례로는 특정 노드가 클러스터에서 제외된 이후 클러스터에서 많은 인덱스를 삭제했다.
그 뒤 해당 노드가 클러스터에 합류하면 클러스터 메타데이터에는 더이상 남아있지 않은 인덱스인데 노드의 로컬에는 인덱스의 데이터가 남아 있다. 이런경우 로컬 샤드 데이터와 클러스터 메타데이터가 불일치하므로 댕글링 인덱스가 발생한다.
-> 큰 이슈가 아니기에 삭제만 해주면된다.
7.4.2 샤드 복구 진행 상황 확인
# human 매개변수 : 가독성 올려줌
GET {인덱스 명}/_recovery?human
GET _recovery?human샤드 복구 단계
- init : 시작 전
- index : 루씬 파일 복구 중
- verify_index : 색인을 검증하는 단계
- translog : translog에서 작업을 재처리하는 단계
- finalize : translog 작업이 끝난 이후 최종 작업을 수행하는 단계
- done : 복구 완료
7.4.3 샤드 복구 속도 조정
일시적으로 샤드 복구 작업의 속도를 조정할 수 있다.
cluster.routing.allocation.node_concurrent_recoveries
노드 하나가 너트워크를 통해 동시에 수행하는 샤드 복구 작업의 수를 조정한다. (default 2)
여기서 복구 작업이란 다른 노드에 샤드를 복제해 주는 작업과, 다른 노드로부터 샤드를 복제받는 작업이다.
cluster.routing.allocation.node_initial_primaries_recoveries
한 노드가 동시에 몇 개의 주 샤드를 복구할지 지정한다. (default 4)
indices.recovery.max_bytes_per_sec
노드당 복구에 사용할 네트워크 트래픽의 속도를 제한하는 설정이다. (default 40mb)
7.4.4 샤드 복구 우선순위 조정
장애 복구에도 우선순위를 정할 수 있다. 값이 높을수록 먼저 복구한다.
index.priority : 10 //default 1
7.5 원활한 장애 복구를 위한 서비스 구조 설계
7.5.1 앞쪽에 메시지 큐를 둔다.
서비스가 es에 직접 색인 요청을 하는 것보다 앞쪽에 메시지 큐를 두는 것이 좋다.
색인할 데이터가 발생하면 메시지 큐에 데이터를 넣는다.
그리고 별도의 시스템이 메시지 큐에서 데이터를 꺼내서 es에 색인하도록 구축한다.
서비스 클라이언트와 es의 결합이 느슨해진다.
카프카를 추천한다. 사용자가 많아 커뮤니티도 발달된 편이다.
장애 상황이 종료된 후 일부 데이터를 재처리하고 싶을 때도 메시지 큐를 활용할 수 있다.
카프카의 경우 컨슈머 그룹의 오프셋을 되감을 수 있다.
오프셋을 원하는 시간대로 되감은 뒤 메시지 큐에서 데이터를 다시 꺼내면서 색인 작업을 재처리하면 여러 상황에서 깔끔한 재처리를 할 수 있다.
카프카에서 메시지를 꺼내서 es에 색인하는 솔루션도 여러 종류가 있다.
logstash, fluentd 등이 있다.
7.5.3 용도나 중요도별로 클러스터를 분리해야 한다.
8.1.1 쓰기 작업 시 es동작과 동시성 제어
쓰기 작업은 조정 단계(coordination stage), 주 샤드 단계(primary stage), 복제 단계(replica stage)의 3단계로 수행된다.
1. 조정 단계
es 클러스터에 쓰기 요청이 들어오면 먼저 라우팅을 통해 어느 샤드에 작업을 해야 할지를 파악한다.
몇번 샤드에 작업해야 하는지가 확인되면 해당 번호의 샤드 중에서 현재 주 샤드를 찾아 작업을 넘겨준다.
이후 주 샤드로부터 작업 완료 결과를 받으면 클라이언트에게 응답을 돌려준다.
2. 주 샤드 단계
주 샤드가 요청을 넘겨받은 이후 수행하는 작업들을 주 샤드 단계라고 한다.
해당 단계는 요청에 문제가 있는지 검증하고, 쓰기작업을 수행한다.
3. 복제본 단계
작업이 완료되면 각 복제본 샤드로 요청을 넘긴다.
마스터 노드는 복제받을 샤드 목록을 관리하고 있는데 이 목록을 in-sync 복제본이라고 한다.
주 샤드는 in-sync 복제본에 병렬적으로 요청을 넘긴다.
이후 모든 복제본이 작업을 성공적으로 수행하고 주 샤드에 응답을 돌려주면 주 샤드가 작업 완료 응답을 보낸다.
각 in-sync 복제본 샤드는 주 샤드에게 받은 요청을 로컬에서 수행하고 주 샤드에게 작업이 완료됐음을 보고한다.
이를 복제 단계라고 한다.
조정 단계, 주 샤드 단계, 복제 단계는 이 순서대로 실행되지만 종료는 역순이다.
각 복제 단계가 완료되어 주 샤드에게 응답을 모두 보내야 주 샤드 단계가 종료된다.
주 샤드 단계에서 최초 요청을 받아 전달했던 노드에게 작업 완료 결과를 보내야 조정 단계가 종료된다.
주 샤드 단계에서는 작업을 각 복제본 샤드에 병렬적으로 보낸다고 했다.
그런데 분산 환경에서 여러 작업을 병렬적으로 보내면 메시지 순서의 역전이 일어날 수 있다.
낙관적 동시성 제어
주 샤드의 변경 내용은 복제본 샤드로 복제된다.
예를들어, 한 문서의 views 필드 값을 1로 색인했다면 잠시 후 복제본에도 이 내용이 적용된다.
그런데 이 변경 내용이 복제본 샤드에 완전히 적용되기 전에 다른 클라이언트로부터 주 샤드에 같은 문서의 views 필드 값을 2로 색인하는 변경이 발생했다고 가정하자.
이 변경 요청도 복제본 샤드에 복제될 것이다.
분산시스템 특성상 두 요청 중 어떤 요청이 먼저 복제본 샤드로 들어올지는 보장할 수 없다.
views를 2로 색인하는 요청이 먼저 들어온 뒤에 views를 1로 색인하는 요청이 나중에 들어온다면 복제본에서는 최종값이 1로 역전될 수 있다.
이러한 상황을 막기위해 _seq_no가 존재한다.
_seq_no는 각 주 샤드마다 들고 있는 시퀀스 숫자값이며 매 작업마다 1씩 증가한다.
es는 문서를 색인할 때 이 값을 함께 저장한다.
es는 _seq_no 값을 역전시키는 변경을 허용하지 않음으로써 요청 순서의 역전 적용을 방지한다.
앞에서 들었던 예의 경우 views 필드의 값을 1로 색인하는 작업은 새 _seq_no를 할당받는다.
이 값을 n이라고 해보자. es는 이 문서의 views 필드 값을 1로 색인함과 동시에 문서에 _seq_no 값 n을 함께 저장한다.
나중에 views 필드 값을 2로 색인하는 요청이 주 샤드에 들어온다면 이 요청은 n보다 높은 _seq_no값을 받게 된다.
n+3값을 받았다고하자.
주 샤드에 들어온 변경 내용이 복제본 샤드로 전송될 때는 분산 네트워크 환경 특성상 요청이 역전될 수 있다.
복제 요청이 역전되어 들어왔다면 복제본 샤드는 _seq_no 값이 n+3인 문서가 색인된 상태에서 _id 값은 같은데 _seq_no 값은 더 작은 n인 색인 요청을 받는다.
es는 이 경우 이전 버전의 요청을 늦게 들어온 것으로 판단하고 작업을 수행하지 않는다.
더 쉽게 정리 : https://m.blog.naver.com/fbfbf1/223268576768
- primary term: failover 과정에서 특정 shard 가 primary 가 되면 증가하는 값(이전 샤드에서의 작업과 현재 샤드에서의 작업을 구분하기위함)
- seq no: 인덱스에 이뤄진 오퍼레이션의 횟수를 기록한 시퀸스 값
- version: doc에 이뤄진 업데이트 횟수를 기록한 시퀸스 값(seq와 다르게 클라이언트가 직접 값을 지정할 수 있음)
8.1.2 읽기 작업 시 es 동작
쓰기작업과 다르게 조정노드에서 주 샤드가 아니라 레플리카로 요청이 넘어갈 수 있다.
검색 요청을 받은 노드는 로컬에서 읽기 작업을 수행하고 조정 노드에 결과를 넘겨준다.
조정 노드는 이를 모아서 응답한다.
단 특정 복제본에는 반영이 안된 상태의 데이터를 읽을 수도 있다.
8.1.2 체크포인트와 샤드 복구 과정
노드가 재기동되면 그 노드가 들고있던 샤드에 복구 작업이 진행된다.
그 과정에서 복구 중인 샤드가 현재 주 샤드의 내용과 일치하는지 파악할 필요가 있다.
재기동중에 주 샤드에 추가로 색인이 들어왔으면 그 내용을 복구 중인 샤드에도 반영해야한다.
반대로 주 샤드를 들고 있던 노드에 문제가 생기면 새 주 샤드가 미쳐 반영하지 못한 작업 내용이 복구 중인 샤드에 포함돼 있을 수 있다.
_primary_term과 _seq_no를 조합하면 샤드간 반영 차이점을 알 수 있다.
각 샤드는 로컬에 작업을 수행하고 몇 번 작업까지 순차적으로 빠짐없이 수행을 완료했는지를 로컬 체크포인트로 기록한다.
ex. _seq_no가 1,3,5,7인 작업이 있고 3번까지 수행해 로컬 체크포인트값이 3으로 갱신된다. 3번까지는 빠짐없이 반영됐다는 뜻이다.
복제본 샤드는 로컬 체크포인트가 갱신되면 주 샤드에 보고한다.
이후 복제본 샤드가 이후 요청을 반영하면 로컬 체크포인트를 5로 갱신한다.
주 샤드는 각 복제본 샤드로부터 받은 로컬 체크포인트를 비교하여 가장 낮은 값을 글로벌 체크포인트값으로 기록한다.
해당 작업까지는 모든 샤드에 반영됐다는 뜻이다.
글로벌 체크포인트가 갱신되면 다음 색인 작업 시 그 내용을 주 샤드가 복제본 샤드로 전달한다.
문제가 발생해 샤드를 복구해야할 때 샤드간 글로벌 체크포인트를 비교한다. 주 샤드와 복제 샤드의 글로벌 체크포인트가 같다면 이 샤드는 추가 작업이 필요없다.
차이나면 필요한 작업만 재처리하여 복구한다.
이러한 방식은 세그먼트를 통째로 전송하는것보다 훨씬 효율적이다.
색인은 재처리에 필요한 모든 정보를 들고있기에 문제되지 않지만 삭제 작업은 그렇지 않기에 논리적 삭제를 도입했다.
최근 삭제한 문서를 일정 기간 보존해 두고 작업 재처리에 활용한다.
샤드 이력 보존(shard history retention leases)라고 부른다.
세그먼트 병합중에도 샤드 이력은 보존된다. 기본값은 12시간이다.
경과된 복구 작업에는 작업 재처리를 이용하지 않는다. 세그먼트 파일을 통째로 복사하는 방법을 사용한다.
참고 : https://mystudylab.tistory.com/160
bm25
쿼리 컨텍스트를 사용하여 질의어와 연관성이 높은 문서들을 찾음
tf-idf 개념에 문서길이를 고려한 알고리즘
IDF(inverse document frequency)
문서 빈도는 특정 용어가 얼마나 자주 등장했는지를 의미
자주 등장하는 용어는 중요하지 않을 확률이 높음
그렇기에 Document 내에서 발생 빈도가 적을수록 가중치를 높게 줌
- n, term에 매칭된 document 수
- N, 필드를 포함한 document 수
TF(Term Frequency)
특정 용어가 하나의 document에 얼마나 많이 등장했는지를 의미
하나의 Document에서 특정 용어가 많이 나오면 중요한 용어로 인식하고 가중치를 높인다.
필드 길이가 짧을수록 가중치를 높임
힙 크기는 최대 30~31GB 수준을 넘지 말자
자바에서는 힙 메모리를 좀 더 빠르고 효율적으로 활용할 수 있게 Compressed Ordinary Object Pointers 기술이 적용되어 있는데 힙 메모리가 최대 32GB를 넘기면 비활성화가 된다.
물리 메모리가 32GB 장비면 16GB 힙 크기 할당
64GB 면 30 ~ 31GB 수준의 힙 크기를 할당하는 것이 권장
물리 장비에 128GB 이상의 메모리를 확보해 적정 수준 이상의 힙 메모리를 할당하는 경우에 힙 크기가 아무리 커져도 성능상 이점이 없다.
cache
node query cache : 쿼리에 의해 각 노드에 캐싱 되는 영역(Filter Context에 의해 검색된 문서의 결과가 캐싱 되는 영역. 여러번 검색해야 캐시)
Shard Request Cache : 쿼리에 의해 각 샤드에 캐싱 되는 영역(집계 쿼리 또는 size 0인 쿼리)
Field data cache : 쿼리에 의해 필드를 대상으로 각 노드에 캐싱 하는 영역
