1.Attention Mechanism의 직관적 이해 및 등장 배경
1.1 직관적 이해
다음와 같은 문장이 있습니다.
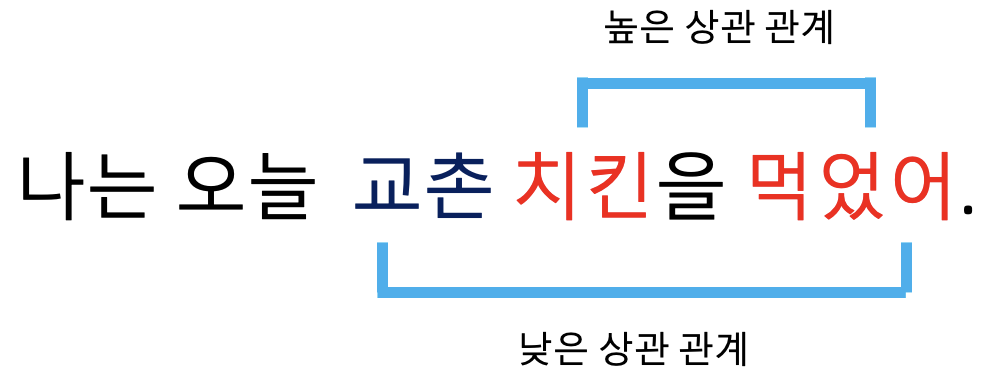
단순히 이 문장만을 본다고 가정했을떄 우리의 인지 시스템은 '먹었어'라는 동사와 무엇을 먹었는지에 대한 명사 여기서는 '치킨'에 일반적으로 주의를 가질 것으로 쉽게 예상 가능합니다. 이와 반대로 '먹었어'라는 동사와 어떤 치킨 인지를 나타내는 '교촌'이라는 단어는 '치킨'에 비해 상대적으로 덜 집중 할 것입니다.
Attention이라는 개념도 위와 같이 이해 할 수 있습니다. 딥러닝에서의 Attention은 어떤한 정보가 중요한지를 판단하기 위해서 가중치들의 합의 벡터로 넓게 해석될 수 있습니다. 이미지의 픽셀이나 문장의 단어와 같은 한 요소를 예측하거나 추론하기 위해, Attention 벡터를 사용하여 그것이 다른 요소들과 얼마나 강하게 상관되어 있는지 추정하는 것입니다. 어찌보면 이 단순하고도 간단한 개념이 현재까지 강력하게 이어져오고 있으니 말 그대로 이 개념을 "Attention"해야합니다.
1.2 등장 배경
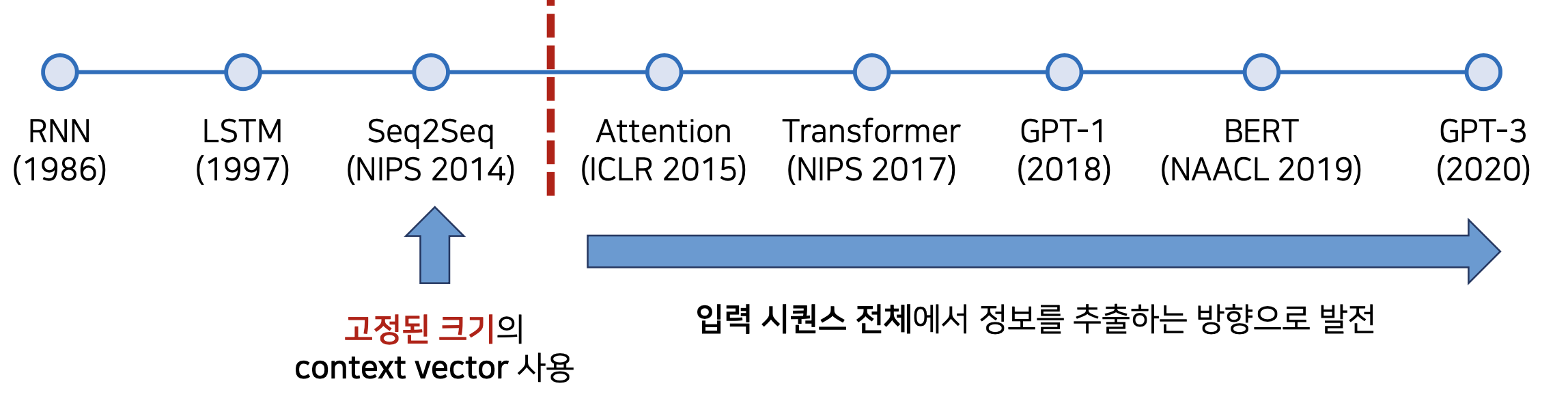
[출처] : https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/Transformer.pdf
위의 그림 처럼 Attention의 개념이 등장하기전 자연어 처리 분야에서는 RNN(Recurrent Neural Network), LSTM(Long short-term memory), Seq2Seq Model 등과 같은 모델들이 존재했습니다.
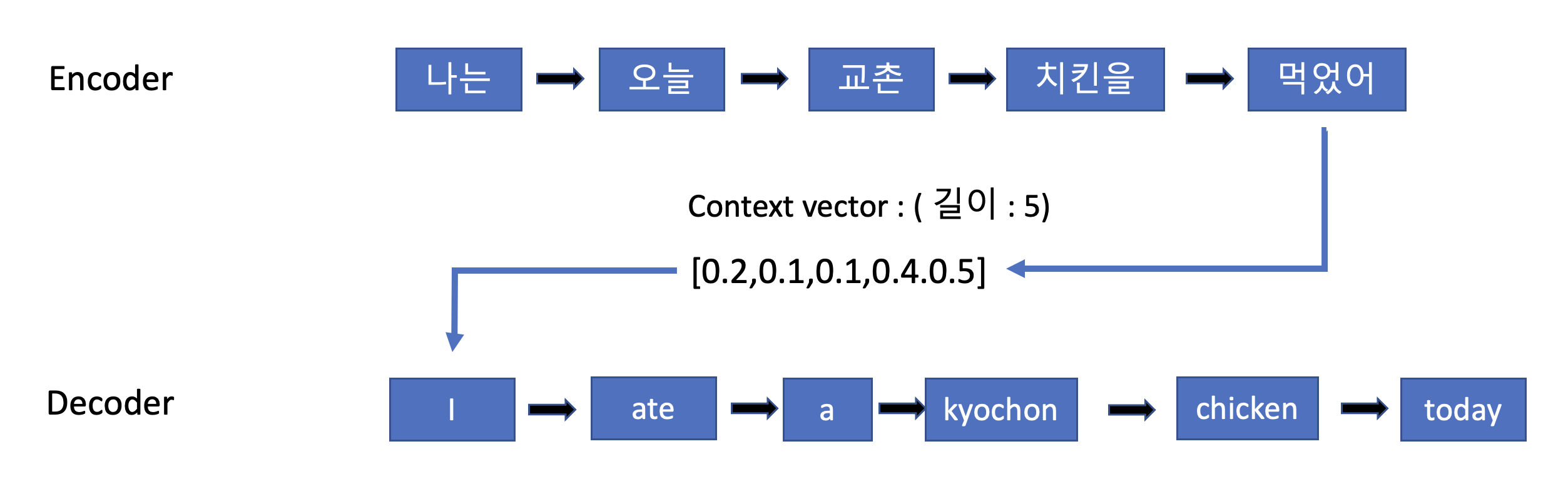
하지만 위와 같은 모델들은 고정 길이의 Context vector(문맥 벡터)를 사용한 나머지 긴 문장을 기억할 수 없다는 치명적인 단점이 있었습니다. 즉 전체 문장의 대한 정보를 고정된 크기의 하나의 벡터로 압축하다보니 시계열 데이터의 특성상 앞에 위치한 데이터의 정보는 잊어 버리는 경우가 많다는 것입니다.이러한 이유로 Attention Mechanism은 이 문제를 해결하기 위해 등장하였습니다.(Bahdanau 등, 2015).
2.Attention Mechanism의 정의
Attention Mechanism은 기계 번역 분야에서 긴 입력 시퀀스의 기억을 잘 유지하기 위해 탄생하였습니다. 기존 Seq2Seq모델에서 인코더의 마지막 hidden state에서 단일 context vector를 구축하는 기존 방법과는 달리 아래 그림과 같이 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 것입니다.
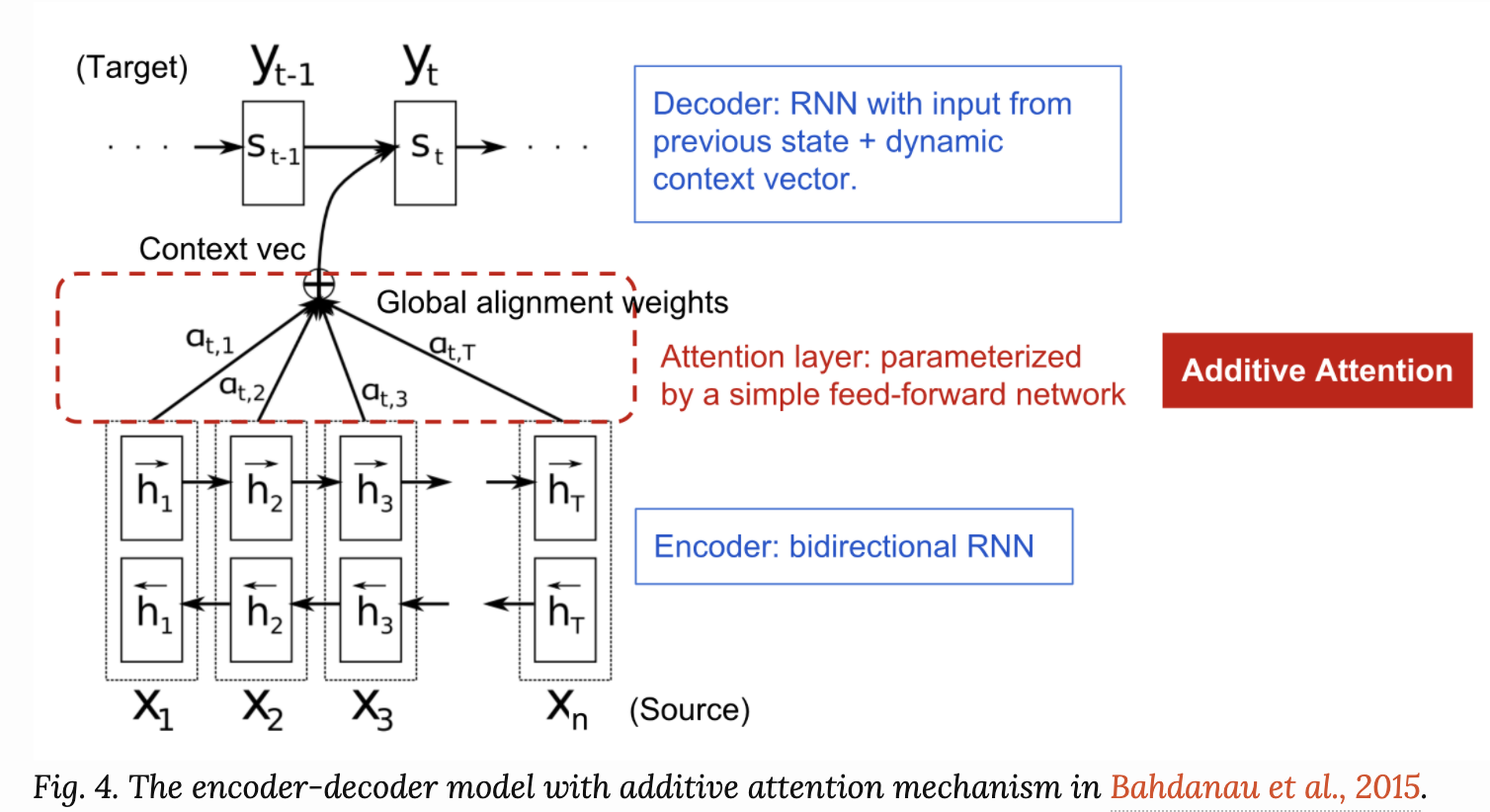
[출처] : https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
그렇다면 본격적으로 어떻게 예측 해야할 단어와 연관이 있는 단어들을 집중(attentnion)하는지 그 구체적인 방법을 알아보겠습니다.
실제로 다음과 같이 Attention Mechanism은 다양한 방식들이 존재합니다.
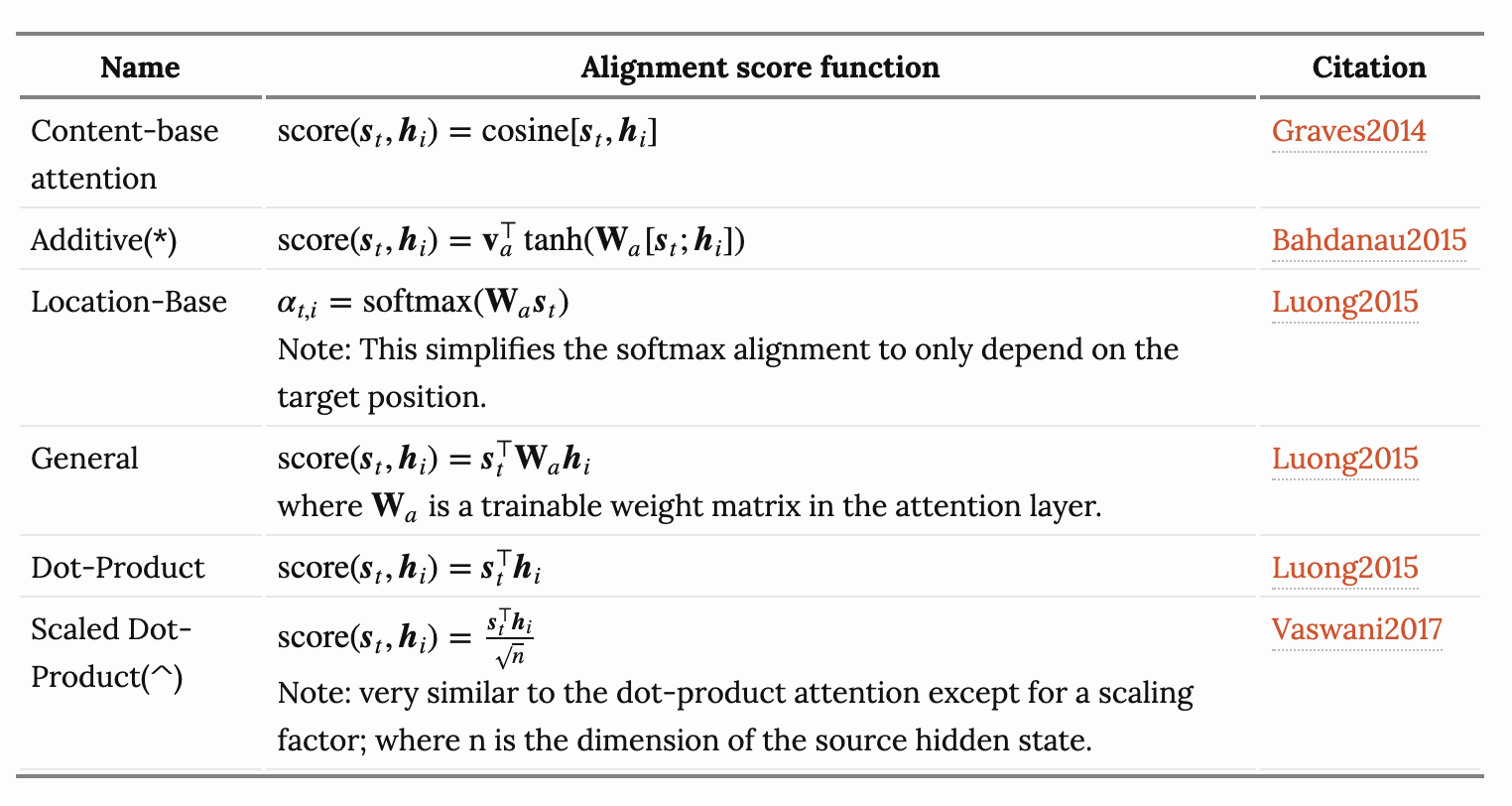
[출처]: https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
여기에서는 Bahdanau,2015를 살펴보고 이후에 Transformer에서 사용된 Self-attention의 개념에 대해서 설명하겠습니다.
Bahdanau Attention
Bahdanau paper에서 아래 그림을 다시 상기시켜보자.
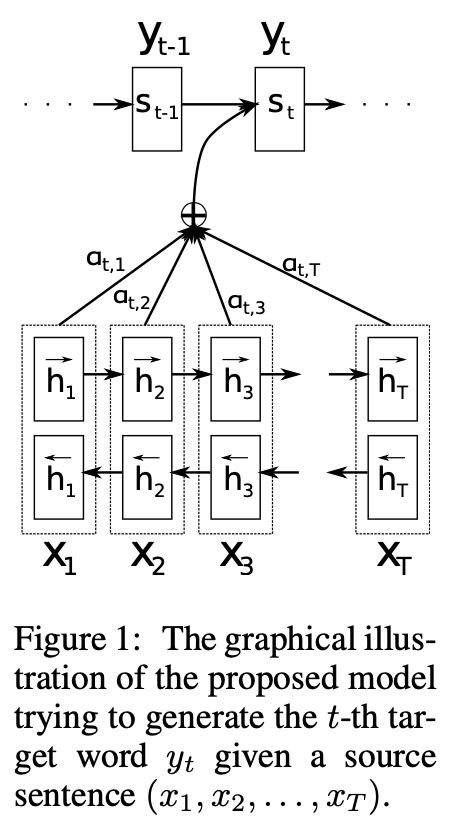
[출처] : https://arxiv.org/pdf/1409.0473.pdf
: time t에서 Decoder의 target word
: Encoder에서의 input word
: j번째 위치까지의 inputs들에 대한 encoder의 hidden state
: time t에서 Decoder의 hidden state를 의미한다.
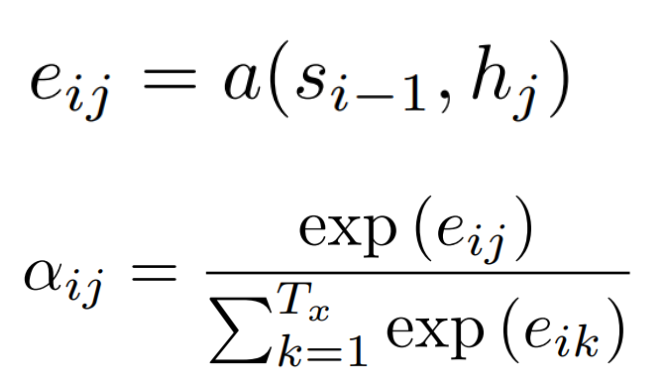
수식이 등장하는데 수식 하나하나를 그림과 연결지어서 살펴보자
i : 현재의 디코더가 처리중인 인덱스
j : 각각의 인코더 출력 인덱스
먼저 는 encoder의 j번째 위치까지의의 모든 출력 값과 decoder의 i-1번째의 hiddenstates 간의 attention score를 구하는 것이다. 이렇게 구함으로서 encoder의 어느 위치의 값과 가장 큰 상관 관계를 가지는지 구하는 것이다. 밑의 는 이를 softmax를 취함으로써 확률값으로 표현한 것이다.
그럼 여기서 핵심은 이다. 이것이 Bahdanau Attention가 제안한 방식인데 구체적인 수식은 다음과 같다.
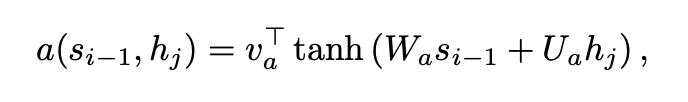
단순히 activation function으로 tanh을 사용하고 와 는 가중치 행렬이다. 각각 가중치 행렬을 곱한 것에 '덧셈'을 해서 라는 parameter와 곱해서 최종 attention score를 구하는 것이다.
그렇게 구한 각각의 attenton score를 와 같이 확률값으로 변환한 후에 아래의 식과 같이 context vector를 구한다.
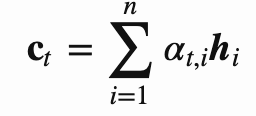
이렇게 함으로서 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, context vector를 얻어서 인코더에서의 전체 입력 문장을 다시 한 번 참고하게 되는 것이다.
코드로 표현하면 다음과 같다
class BahdanauAttention(Attention):
"""
Attention > Additive Attention > Bahdanau approach
Inputs:
query_vector: (hidden_size)
multiple_items: (batch_size, num_of_items, hidden_size)
Returns:
blendded_vector: (batch_size, item_vector hidden_size)
attention_scores: (batch_size, num_of_items)
"""
def __init__(self, item_dim, query_dim, attention_dim):
super(BahdanauAttention, self).__init__(item_dim, query_dim, attention_dim)
print("Attention > Additive > Bahdanau")
# parameter definition
# W is used for project query to the attention dimension
# U is used for project each item to the attention dimension
self.W = nn.Linear(self.query_dim, self.attention_dim, bias=False)
self.U = nn.Linear(self.item_dim, self.attention_dim, bias=False)
# v is used for calculating attention score which is scalar value
self.v = nn.Parameter(torch.randn(1, attention_dim, dtype=torch.float))
def _calculate_reactivity(self, query_vector, multiple_items):
B, N, H = multiple_items.shape # [B,N,H]
# linear projection is applied to the last dimension
s = query_vector.unsqueeze(1)
sum = F.tanh(self.W(s) + self.U(multiple_items))
# note that broadcasting is performed when adding different shape
batch_v = self.v.transpose(0,1).expand(B,self.attention_dim,1)
reactivity_scores = torch.bmm(sum,batch_v).squeeze(-1)
return reactivity_scoresSelf-attention
의미 그대로 자기 자신을 attention하겠다는 것인데 즉 동일한 문장내에 있는 단어와 단어 사이의 관계성을 파악하겠다는 의미를 받아들이면 쉽다. 이는 Transformer에서 더 자세히 다루겠습니다. 아래 그림은 Self-attention을 표현한 것입니다.

[출처] : https://arxiv.org/pdf/1601.06733.pdf
실습 코드 링크
Bahdanau Attention을 활용한 실습 코드는 아래의 Colab에서 확인 해 볼 수 있습니다.
https://colab.research.google.com/drive/1ye0XZGTXI78xn30yRUn5-nv8Mu1mSIUW?usp=sharing
참고 자료
https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
https://arxiv.org/pdf/1601.06733.pdf
https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice
