모자딥 스터디 34,38,39장
34장 - 이터러블
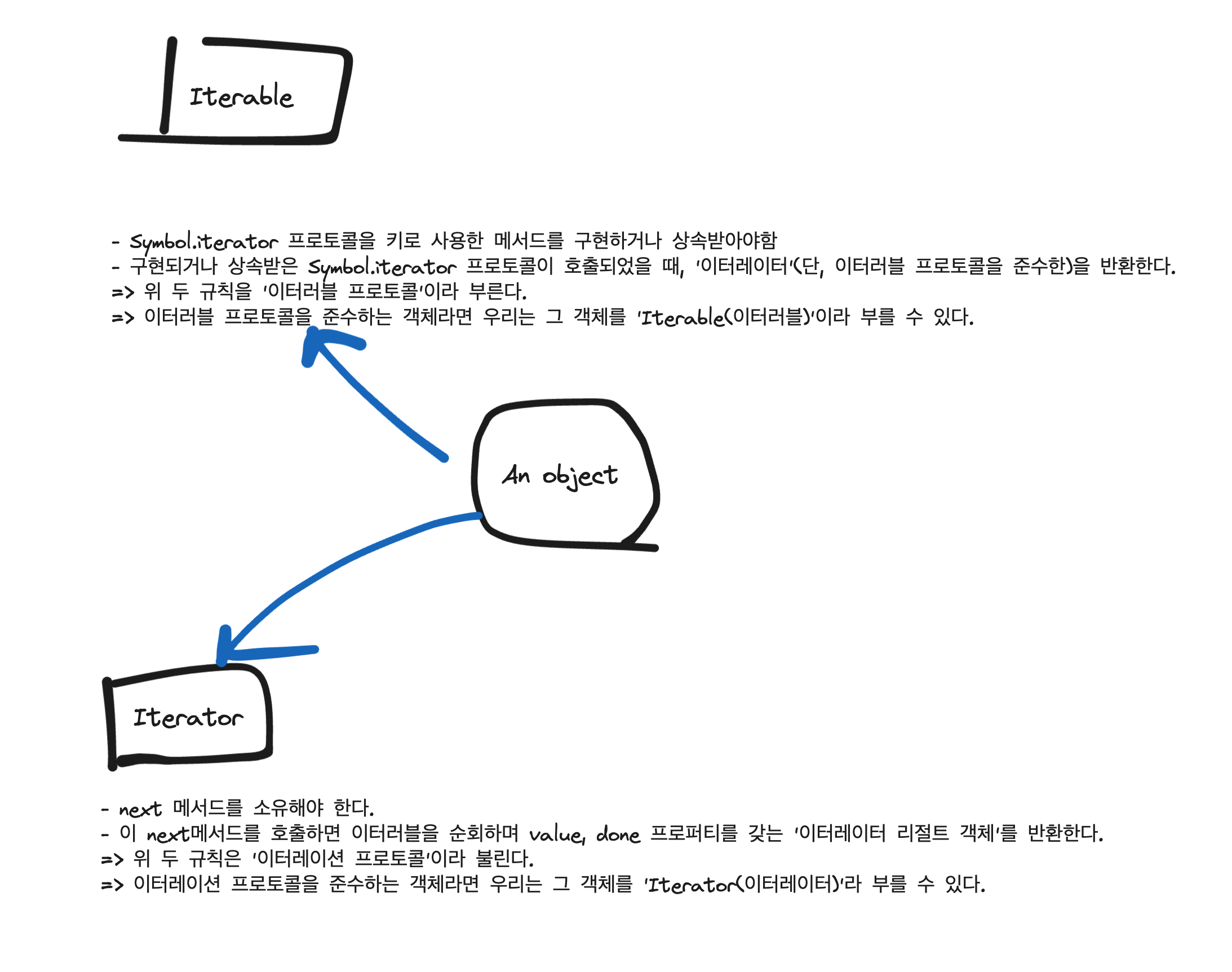
이터러블이란?
Symbol.iterator 키를 가지고 있는(구현, 상속) 객체라면 이터러블이다.
이터러블은 for문, for...of, 문, forEach메서드 등으로 순회 가능하며, 스프레드 문법, 디스트럭처링 문법을 사용할 수 있다.
//Map의 예시;
const map = new Map()
console.log(Symbol.iterator in map)//true
map.set(1,'one')
const arr = [...map]
console.log(typeof arr)//object
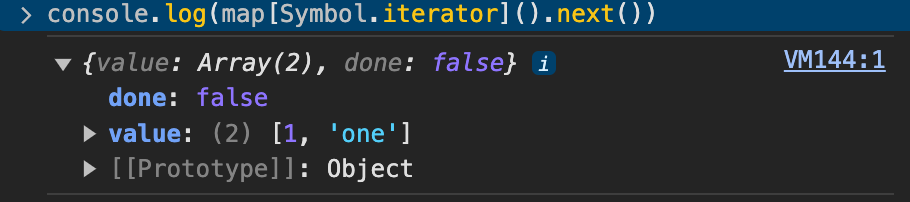
console.log(map[Symbol.iterator].next())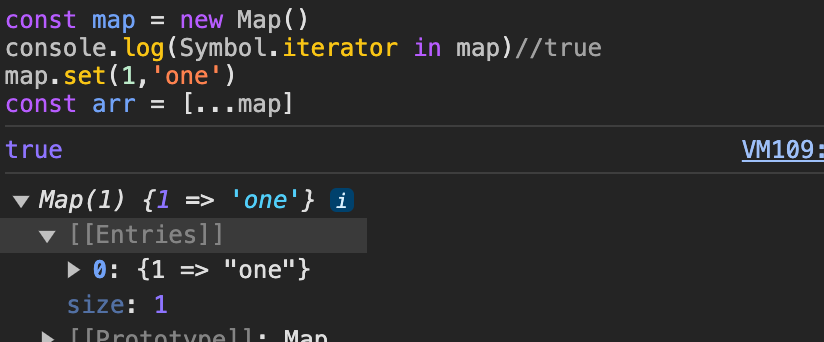
for...of
내부적으로 이터레이터의 next 메서드를 호출하여 이터러블을 순회. next메서드가 반환한 이터레이터 리절트 객체의 value 프로퍼티 값을 for...of문의 변수에 할당한다.
만약 done값이 true이면 이터러블의 순회를 중단한다.
const iterable = [1,2,3]
const iterator = iterable[Symbol.iterator]()
for(;;){
const res = iterator.next()//{value, done}
if(res.done) break
const item = res.value
console.log(item)
}
//1
//2
//3반면 for...in문은 프로퍼티 어트리뷰트의 [[Enumerable]] 값이 true인 프로퍼티를 순회하면서 열거한다. 단, 프로퍼티 키가 심벌인 경우에는 열거하지 않는다.
이터러블과 유사 배열 객체의 차이
이터러블과 유사 배열 객체의 차이점을 살펴보자.
유사 배열 객체는, 분명히 length를 가지고 있고, 인덱스로 프로퍼티 값에 접근할 수 있는 객체이다.
유사 배열 객체는 for문으로 순회할 수 있다. 그렇다면 for...of문으로 순회할 수 있을까? 힌트:
const arrayLike = {0:1,1:2,2:3,length:3}
console.log(Symbol.iterator in arrayLike) //falseconst arrayLike = {0:1,1:2,2:3,length:3}
const arr = Array.from(arrayLike)이터레이터 프로토콜
이터러블은 Symbol.iterator메서드를 가지고 있고, 해당 함수가 호출되었을 때 이터레이션 프로토콜을 준수하는 이터레이터 객체를 반환한다고 했다. 그러면 이터레이션 프로토콜은 왜 필요한가?
이터레이터 프로토콜은 Array, String, Map, Set, DOM 컬렉션(NodeList, HTMLCollection), arguments 등 다양한 이터러블 데이터 소스를 순회할 때 순회방식을 통일해준다.
데이터 소비자는 덕분에 효율적으로 다양한 데이터 공급자 객체에서 일관된 방식으로 순회를 사용할 수 있게된다. 즉, 이터레이터 프로토콜은 데이터 소바자와 공급자의 인터페이스 역할을 해준다!
사용자 정의 이터러블
이터레이션 프로토콜을 준수하지 않는 일반 객체는 이터러블이 될 수 없다.
하지만, 이터레이션 프로토콜을 준수하도록 구현하면 이터러블이 될 수 있다. (이 객체는 이터레이터객체는 아님에 주의하자!)
const fibonacci = {
[Symbol.iterator]() {
let [pre, cur] = [0, 1]
const max = 10
return {
next() {
;[pre, cur] = [cur, pre + cur]
return { value: cur, done: cur >= max }
},
}
},
}
for (const num of fibonacci) {
console.log(num)
}
=> 이 함수는 최대값이 고정되어 있어서 아쉽다. fibonacci를 함수로 바꿔서, 최대값을 인수로 받는 이터러블 객체를 리턴하도록 만들어보자.
이터러블이면서 + 이터레이터인 객체
이터러블은 Symbol.iterator 키가 구현되어 있고, 호출되었을 때 리턴으로 next()를 가지고 리절트 객체를 반환하는 객체를 리턴하는 객체를 말한다.
이터레이터는 next()를 가지고, 리절트 객체를 반환하는 객체이다.
이터러블이면서 이터레이터려면 어떻게 해야할까?
const fibonacciFunc = function (max) {
let [pre, cur] = [0, 1]
return {
//리턴되는 객체는 이터러블이면서
[Symbol.iterator]() {
return this
},
//이터레이션 프로토콜을 준수하는 이터레이터이다
next() {
;[pre, cur] = [cur, pre + cur]
return { value: pre, done: cur >= max }
},
}
}
퀴즈
이터러블, 이터레이션 프로토콜을 활용하여, 객체가 끊임없이 피보나치 수를 리터하는 '무한 이터러블' 사용자 정의 이터러블 객체를 만들어보라.
const fibonacciFunc = function () {
let [pre, cur] = [0, 1];
return {
//리턴되는 객체는 이터러블이면서
[Symbol.iterator]() {
return this;
},
//이터레이션 프로토콜을 준수하는 이터레이터이다
next() {
[pre, cur] = [cur, pre + cur];
return { value: pre, done: false };
},
};
};38장 - 브라우저 동작 원리
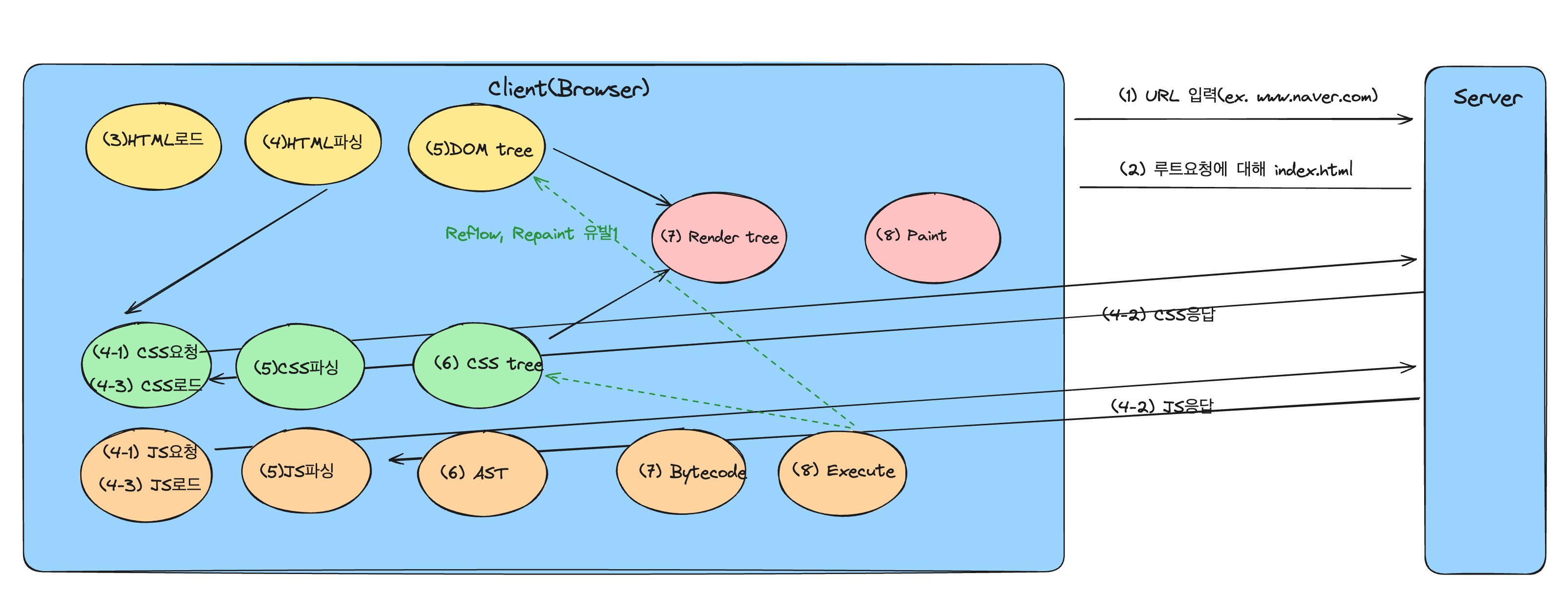
DOM 생성생성 by 렌더링 엔진
브라우저의 렌더링 엔진은
바이트 -> 문자로->토큰(문법적 의미를 가지는 최소 단위)으로 분해 -> 토큰들을 객체로 변환하여 노드를 행성. 문서노드, 요소 노드, 오트리뷰트 노드 등등등... -> 노드를 기본요소로 하여 DOM을 만든다.
HTML요소는 부자 관계를 형성하는데, 이 관계를 반영해 트리 자료구조로 노드들을 재구성한다.
이 트리 자료구조를 DOM이라 한다.
DOM API
DOM 노드들의 정보 뿐 아니라, 프로그래밍 인터페이스로서 DOM API를 지원해서, DOM을 자바스크립트로 조작할 수 있도록 해준다.
CSSOM 생성 by 렌더링 엔진
DOM을 생성하다가 link 태그, style태그를 만나면 잠시 중지하고 CSS파일을 요청한다.
위와 동일한 과정으로 CSSOM을 생성하고, 다시 DOM생성을 재개한다.
CSSOM 은 CSS의 상속을 반영하여 생성된다.
렌더트리 생성
DOM, CSSOM이 완성되면, 렌더트리로 결합된다.
화면에 보일(렌더링될) 노드만 렌더트리에 구성된다.(meta tag, script태그, display:none은 렌더트리에 포함되지 않는다.)
렌더트리는 HTML요소의 레이아웃(위치와 크기)를 계산하는데 쓰이고, 실제로 픽셀을 렌더링하는 페인팅(painting)처리에 입력된다.
자바스크립트에 의해 노드를 추가, 삭제
브라우저 창의 리사이징에 의한 뷰포트 크기 변경
width, height, margin, padding 등등 레이아웃을 변경하는 스타일변경
위 명령들은 엔진으로 하여금 레이아웃 계산과 페인팅을 재차 실행하게 만드는 리렌더링을 야기한다. 리렌더링은 성능에 좋지 않으니 되도록 줄여야겠다.
자바스크립트 AST생성 by 자바스크립트 엔진
CSS처럼 도중에 script 태그의 src어트리뷰트에 정의된 자바스크립트 파일을 서버에 요청하여 자바스크립트 파일을 로드한다.
이후, 자바스크립트 코드를 파싱하기 위해 DOM생성을 멈췄다가, 파싱이 끝나면 다시 돌아와서 DOM생성을 재개한다.(그래서 스크립트 태그를 밑에다 위치시키는게 바람직하다고 하는 것인가?)
자바스크립트 코드는 => 토크나이징 => 파싱을 통해 AST(추상적 구문 트리)를 생성한다. 이것 또한 토큰에 문법적 의미와 구조를 반영햔 트리 구조의 자료구조이다.
39장 - DOM

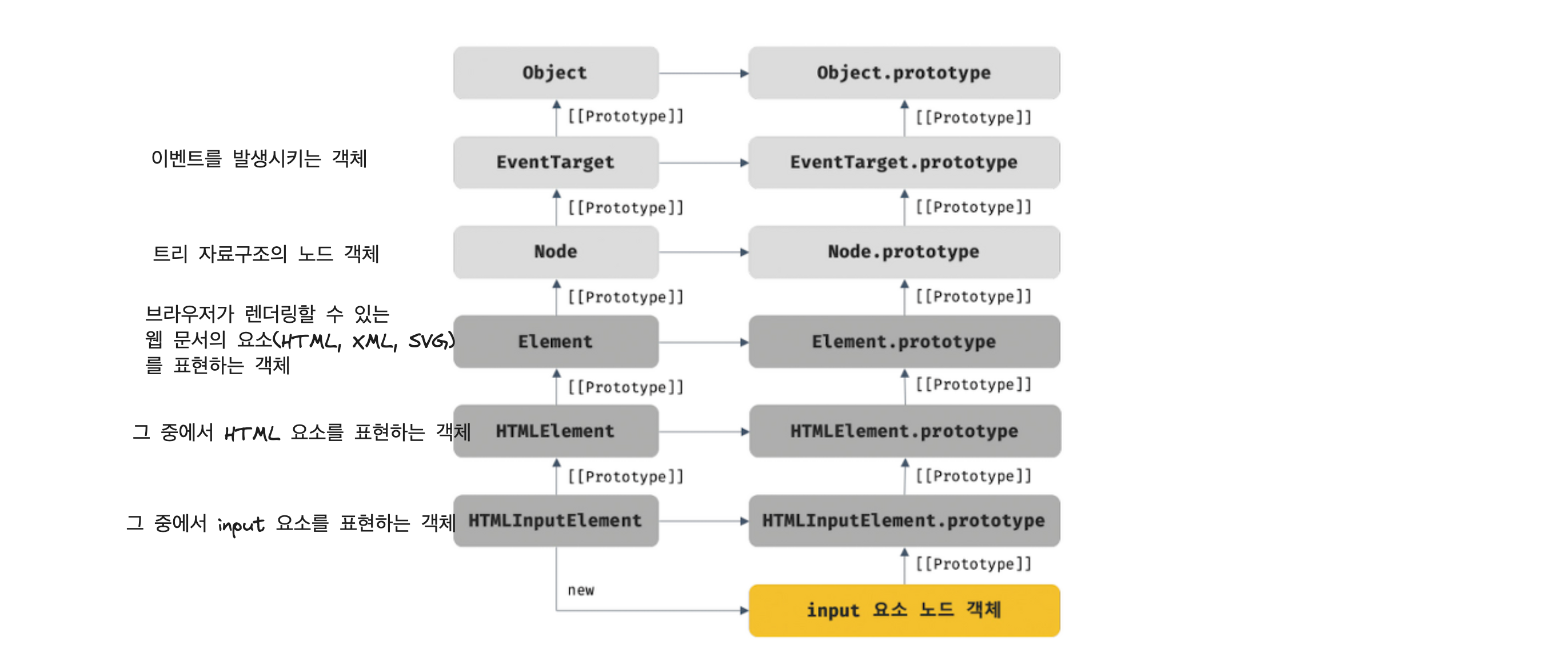
노드 객체의 상속구조
DOM 노드객체는 브라우저에서 추가로 제공하는 호스트 객체이다.

input 요소 노드 객체의 프로토타입 체인을 보면, 아래와 같다.
실습은 다음 주에...
이터러블이 너무 어려웠어요...ㄸㄹㄹ
