병합
- merge: 하나 이상의 키를 기준으로 DataFrame의 로우를 합친다.
- concat: 하나의 축을 기준으로 합친다.
- combile_first: 두 객체를 포개서 한 객체에서 누락된 데이터를 다른 객체의 데이터로 합친다.
merge
SQL과 같은 관계형 데이터베이스의 join과 비슷하게 작동하는데, 하나 이상의 키를 중심으로 데이터 집합의 로우를 합친다.
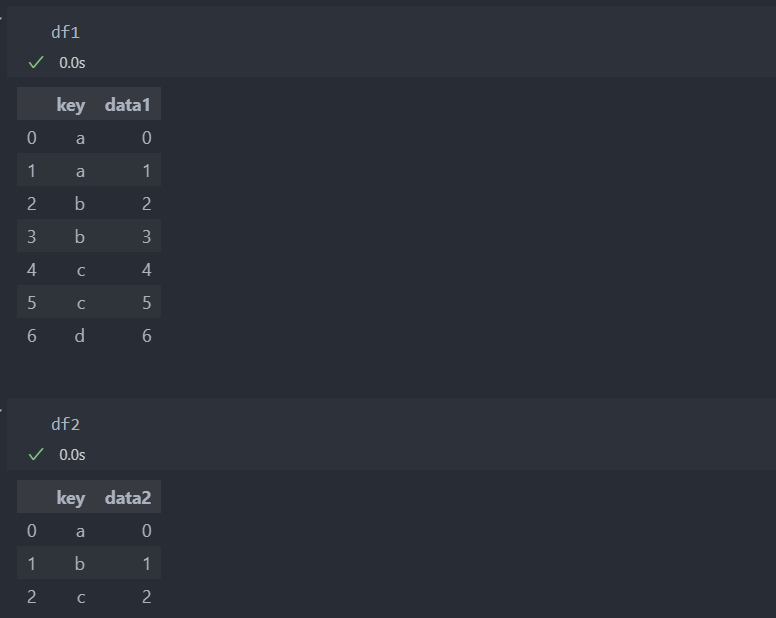
일단 두 개의 데이터를 간단히 합친다.
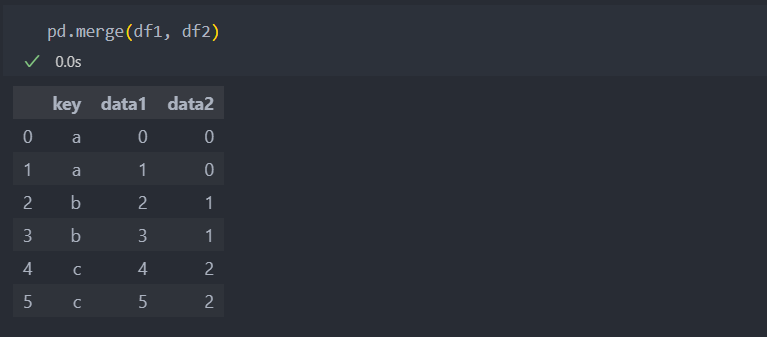
판다스는 데이터들의 중복되는 컬럼을 자동으로 확인하여 합치는 작업을 하지만, 조금 더 복잡하게 합쳐야 하는 상황이 되면 인자를 던져야 하는데 이 때는 인자들을 명시적으로 지정하는 것이 좋다.
on
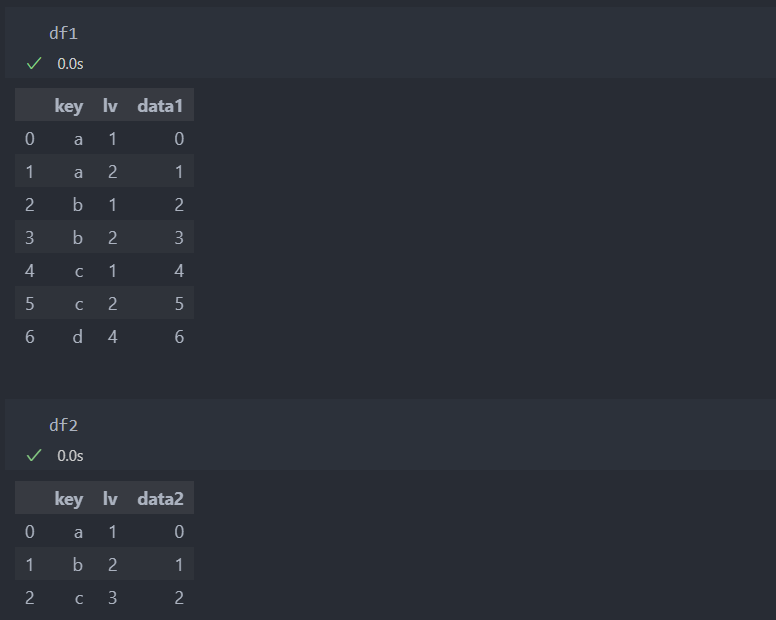
인자 on은 합치는 컬럼을 지정해주는 역할을 한다. on='컬럼'을 주면 '컬럼'을 기준으로 데이터를 합친다.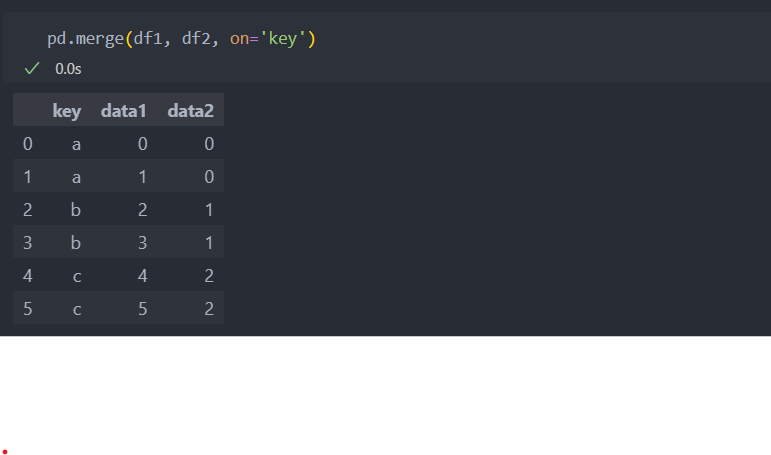
여러 개의 컬럼을 키로 줄 수도 있다.
how
how는 합치려는 데이터의 기준이 되는 방향을 설정한다.
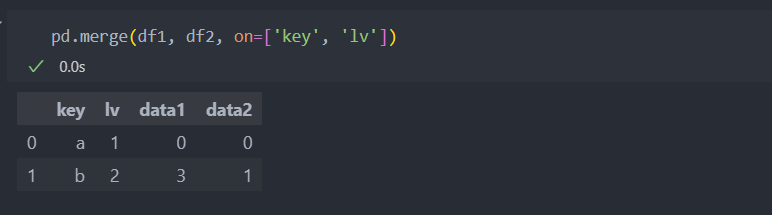
default 값은 how='inner'로 합치려는 데이터들의 교집합인 결과를 반환한다. 위의 예시와 같이 df1의 key 'd'는 df2에 없는 값이므로 제외되어서 나타난다. 'outer'은 합집합 'left'는 왼쪽 데이터를 'right'는 오른쪽 데이터를 기준으로 합친다.
쉽게 벤다이어그램을 연상하면 쉽게 이해할 수 있다.
1. inner : 교집합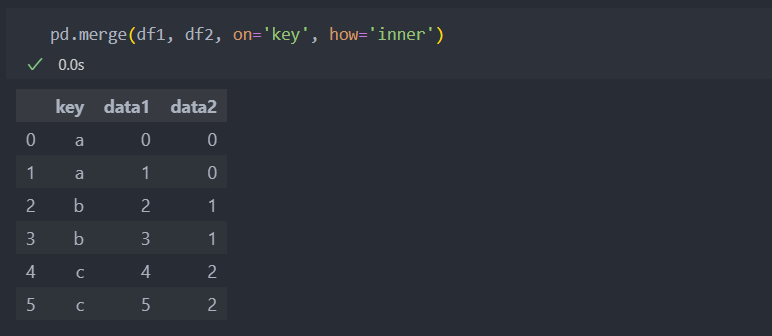
2. outer : 합집합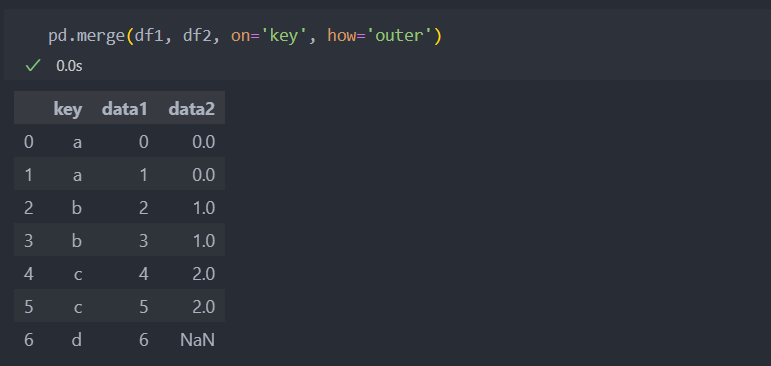
3. left : 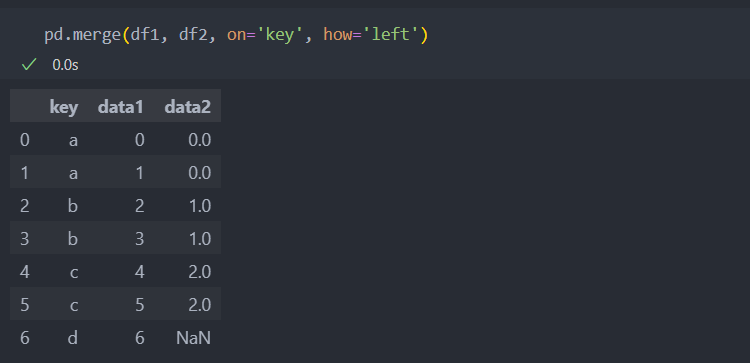
4. right : 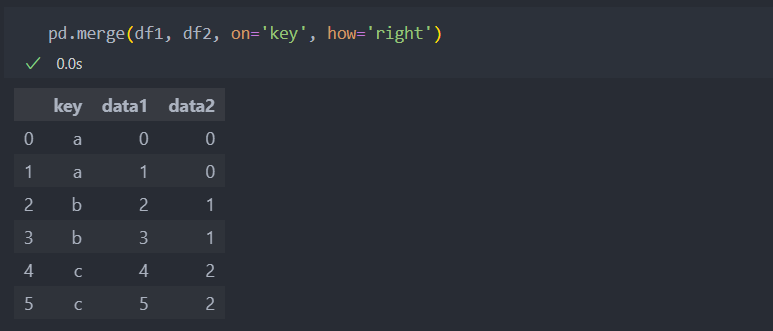
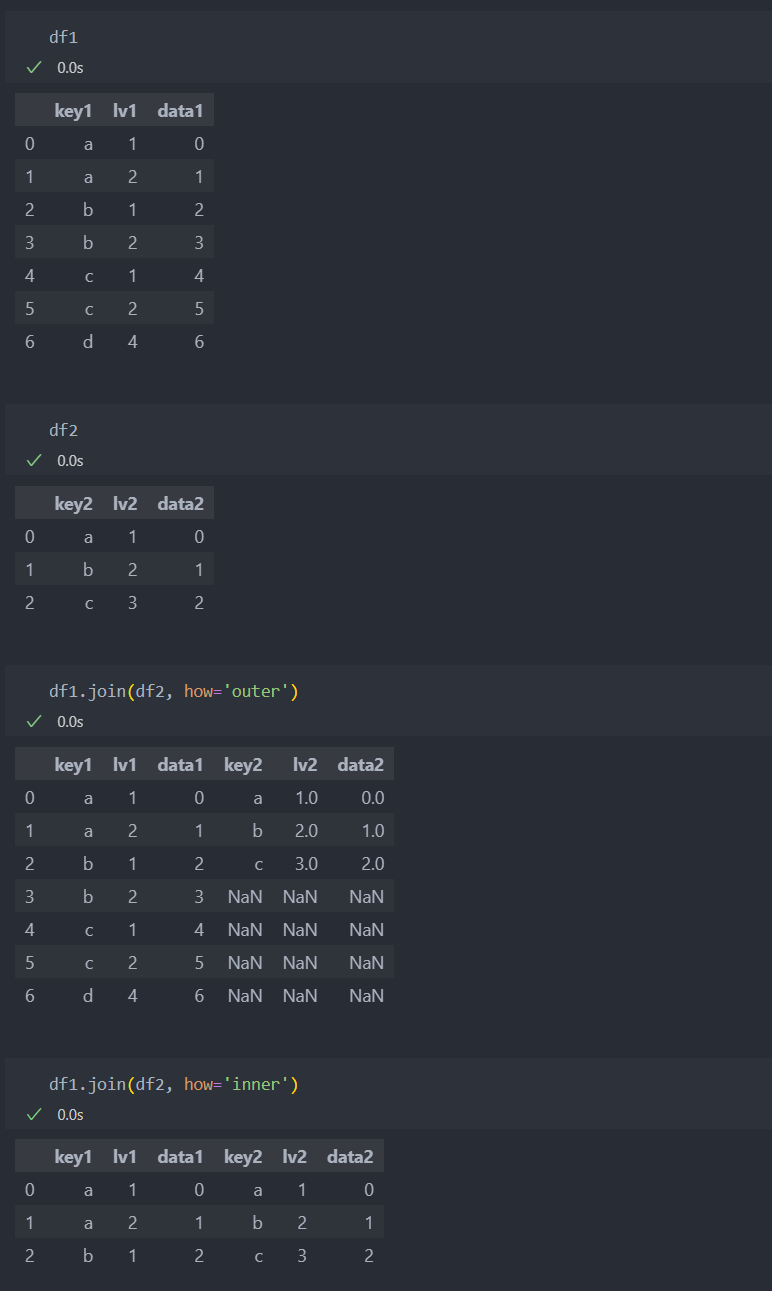
join
공통된 컬럼이 없이 인덱스를 기준으로 병합할 때는 'join'을 써도 된다.
join도 how 인자를 던져서 원하는 데이터를 기준으로 병합할 수 있다.
concat
축을 기준으로 이어 붙이는 방법이다.
default 값은 axis=0으로 로우 방향으로 병합이 된다.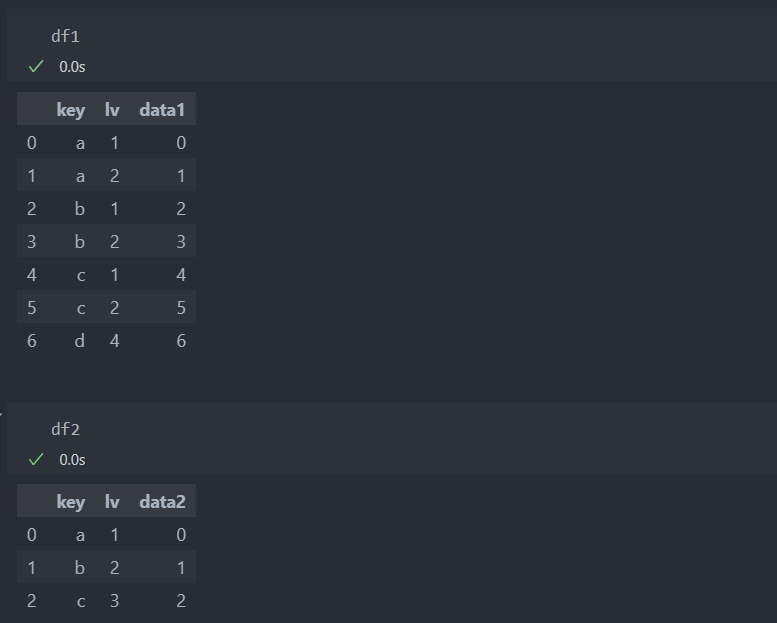
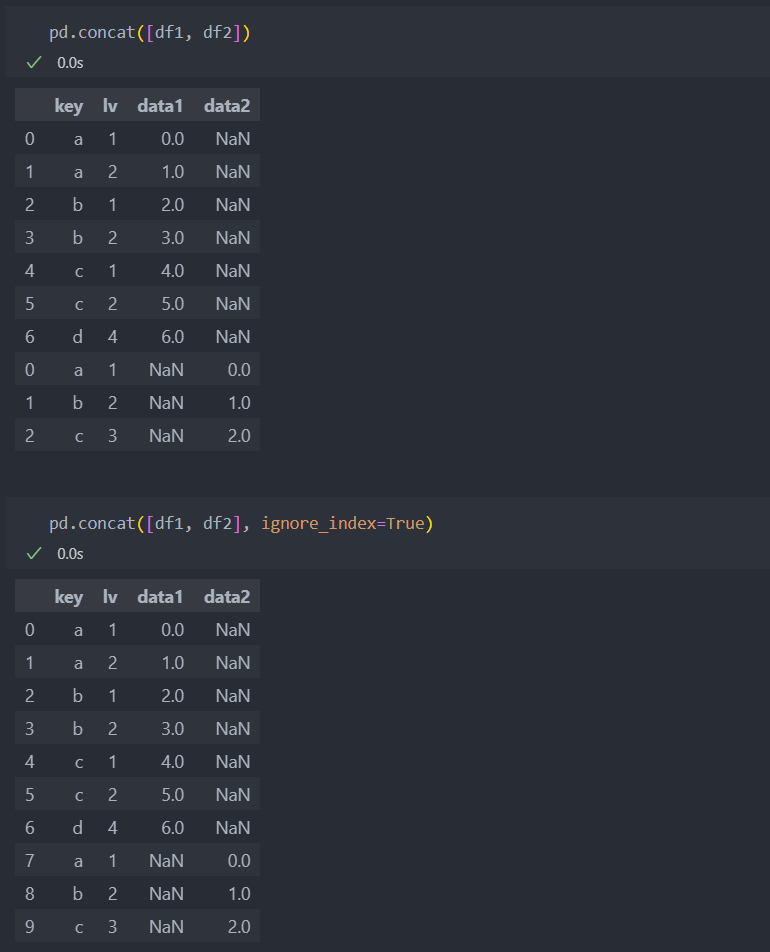
공통된 컬럼이 있을 경우 컬럼을 공유하여 이어붙이며, 공유되는 컬럼이 없을 경우 outer의 경우와 같이 NaN값이 주어진다.
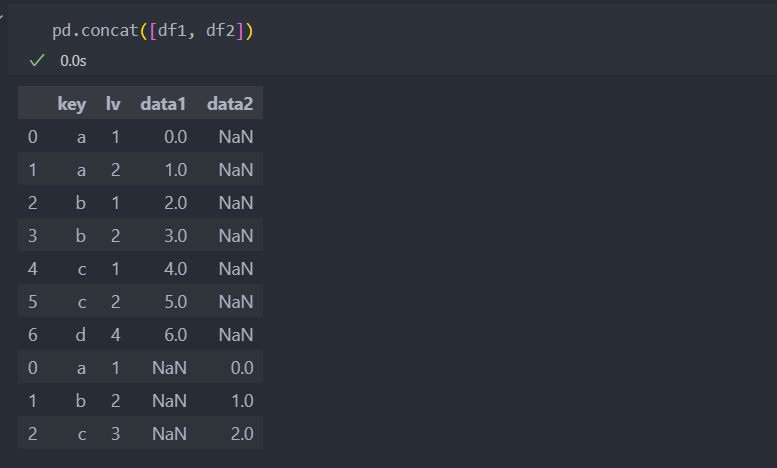
축의 방향을 axis로 변경하여 옆으로 이어붙일 수도 있다.
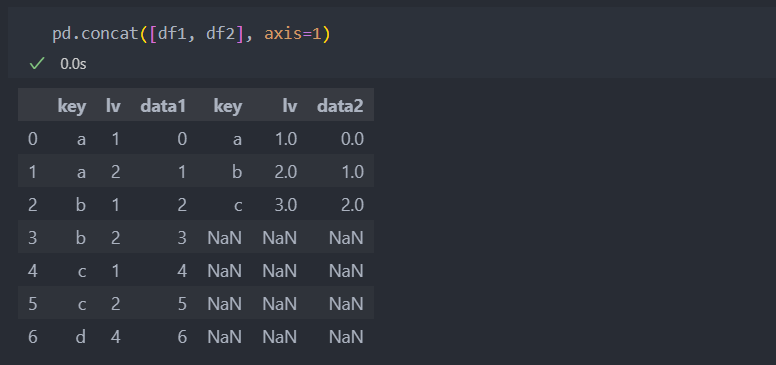
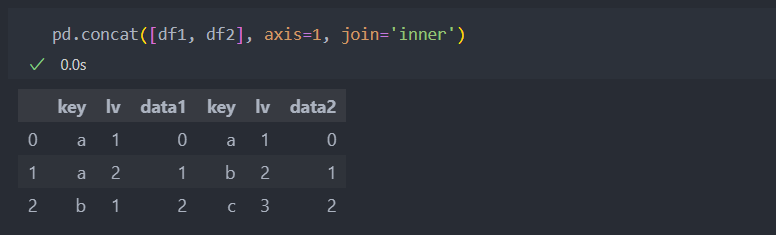
옆으로 이어붙일 경우 inner, outer(default=outer)로 교집합 또는 합집합으로 합칠 수도 있다.
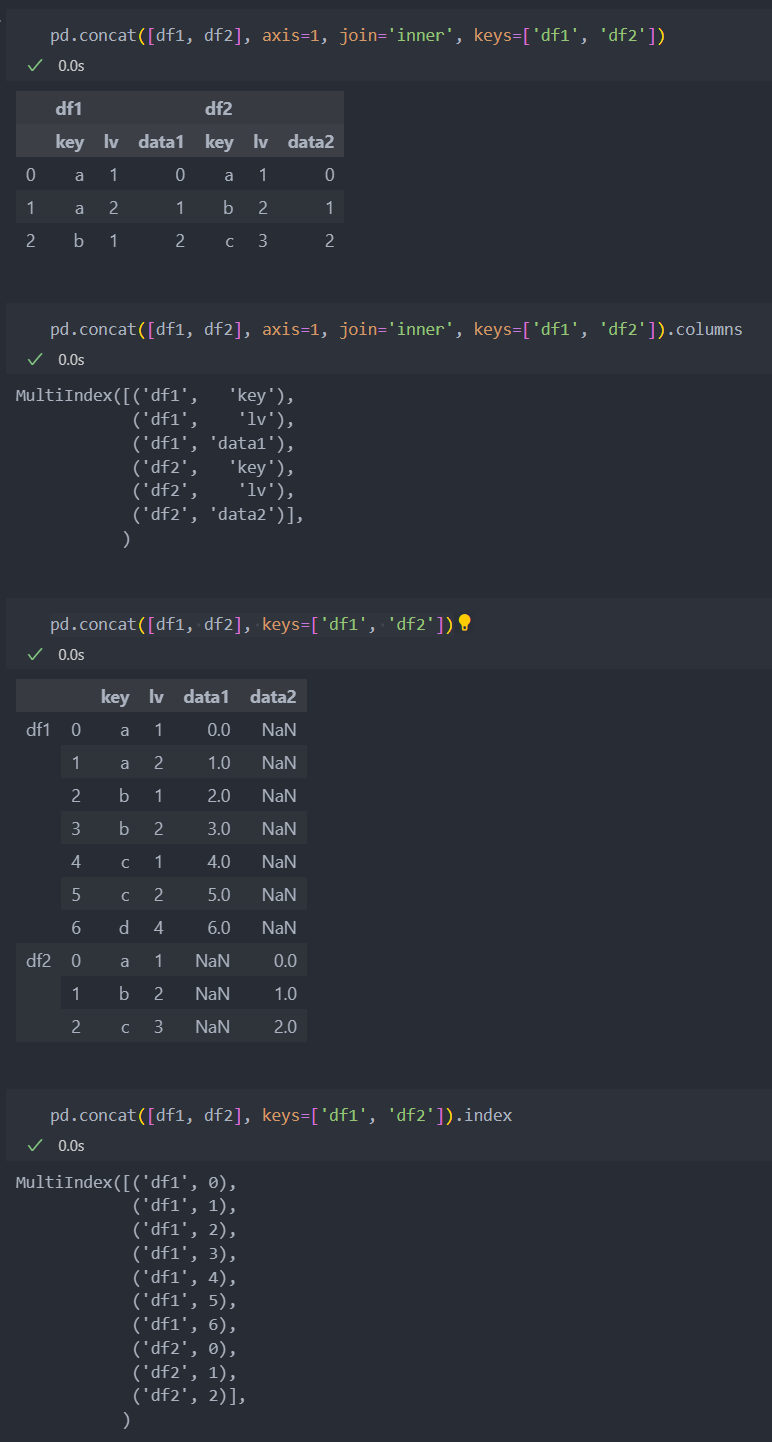
keys 인자를 던저 컬럼의 이름이나 멀티인덱스를 설정할 수 있다.
concat으로 이어붙일 경우 인덱스 번호를 정렬 할 수 있다.(default는 False)
데이터가 이어지는 순서대로 정수 0부터 오름차순으로 인덱스가 부여된다.
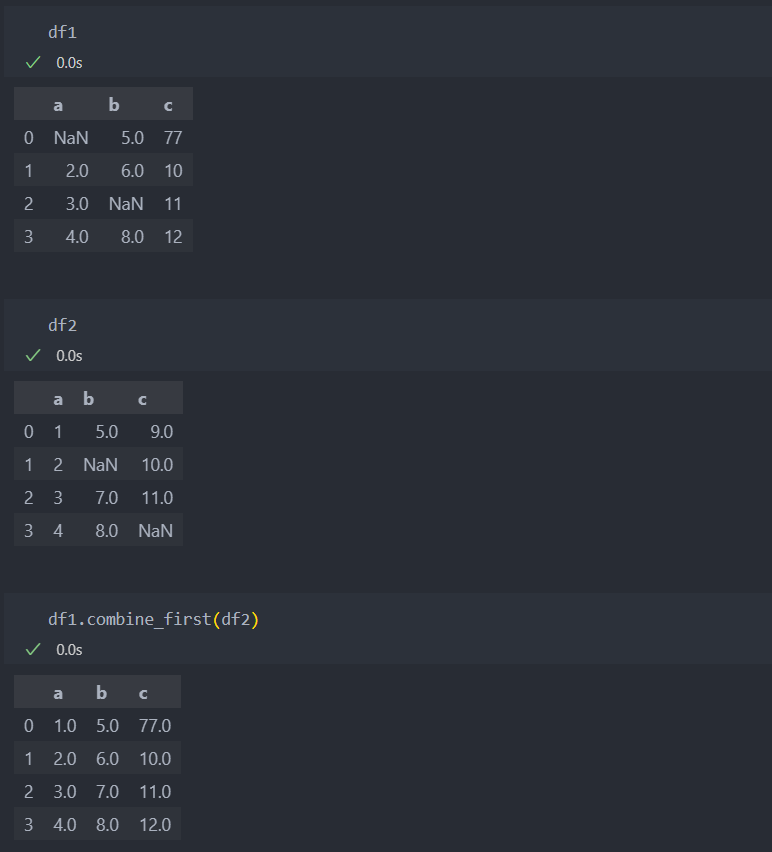
combine_first
데이터를 합칠 때 뒤에 인자로 주어지는 데이터에 있는 값으로 앞에 있는 데이터의 NaN값을 채운다.