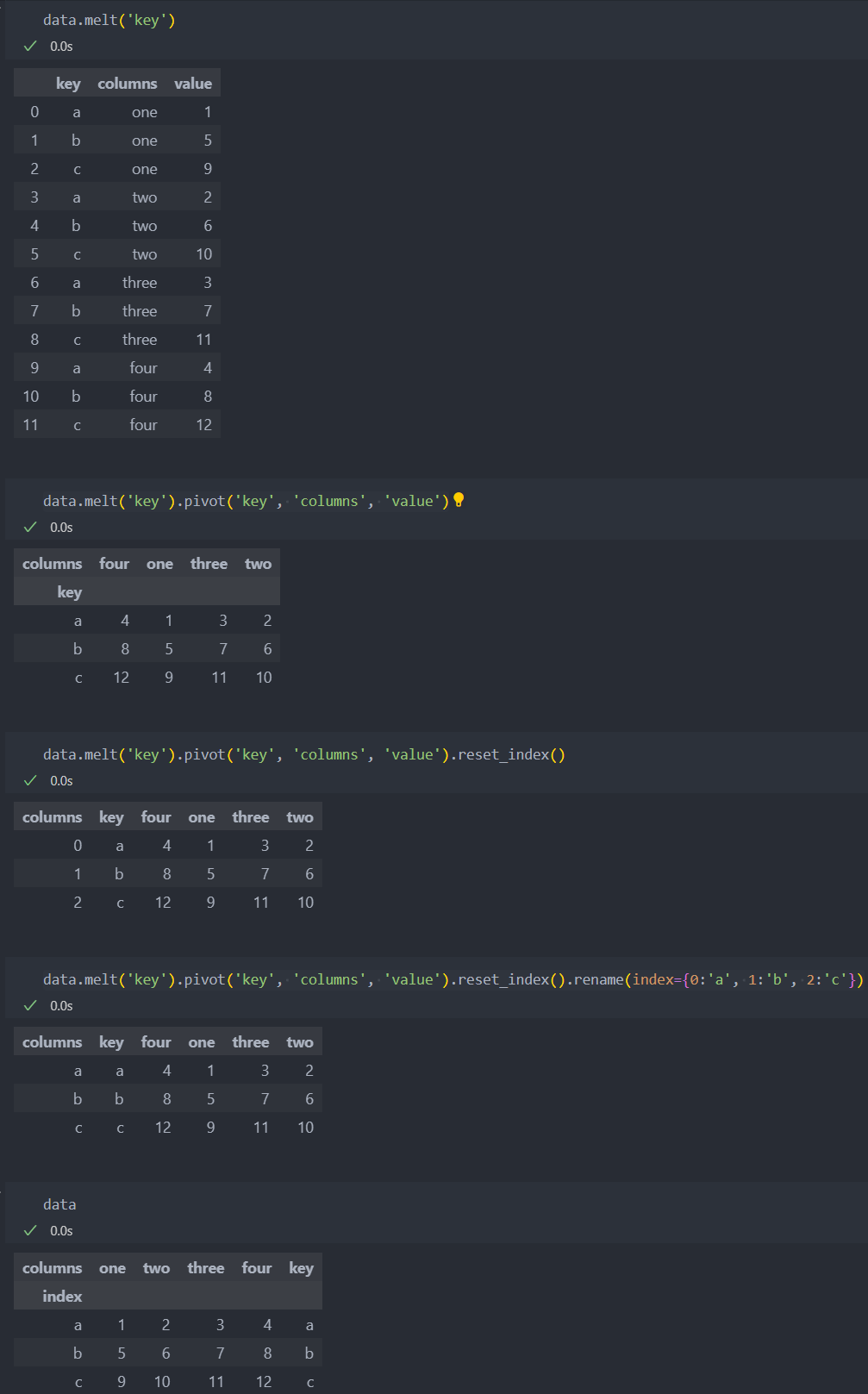
표 형식의 DataFrame 형식의 로우와 컬럼을 재배치 할 수 있도록 해주는 기본 연산에는 stack과 pivot이 있다.
stack
임의의 데이터프레임을 생성하고 로우와 컬럼에 이름까지 지정한다.
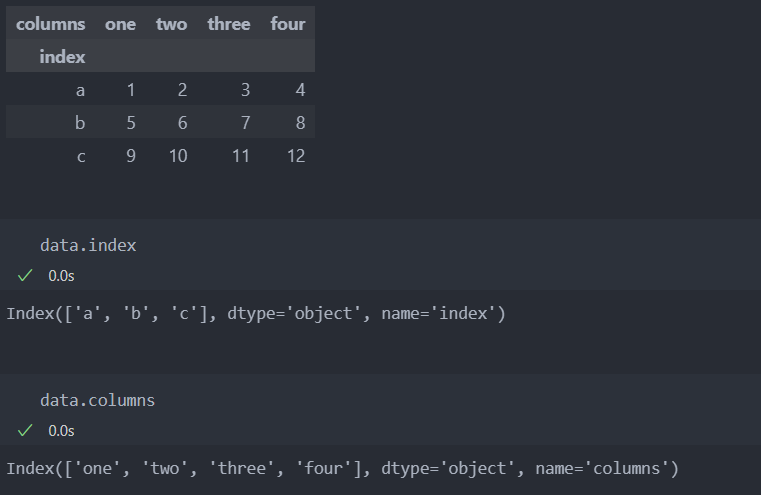
stack은 데이터의 컬럼을 로우로 피벗시키며, unstack은 로우를 컬럼으로 피벗시킨다.
stack
아래와 같이 컬럼 one, two, three, four이 인덱스에 피벗이 되는 것을 볼 수 있다.
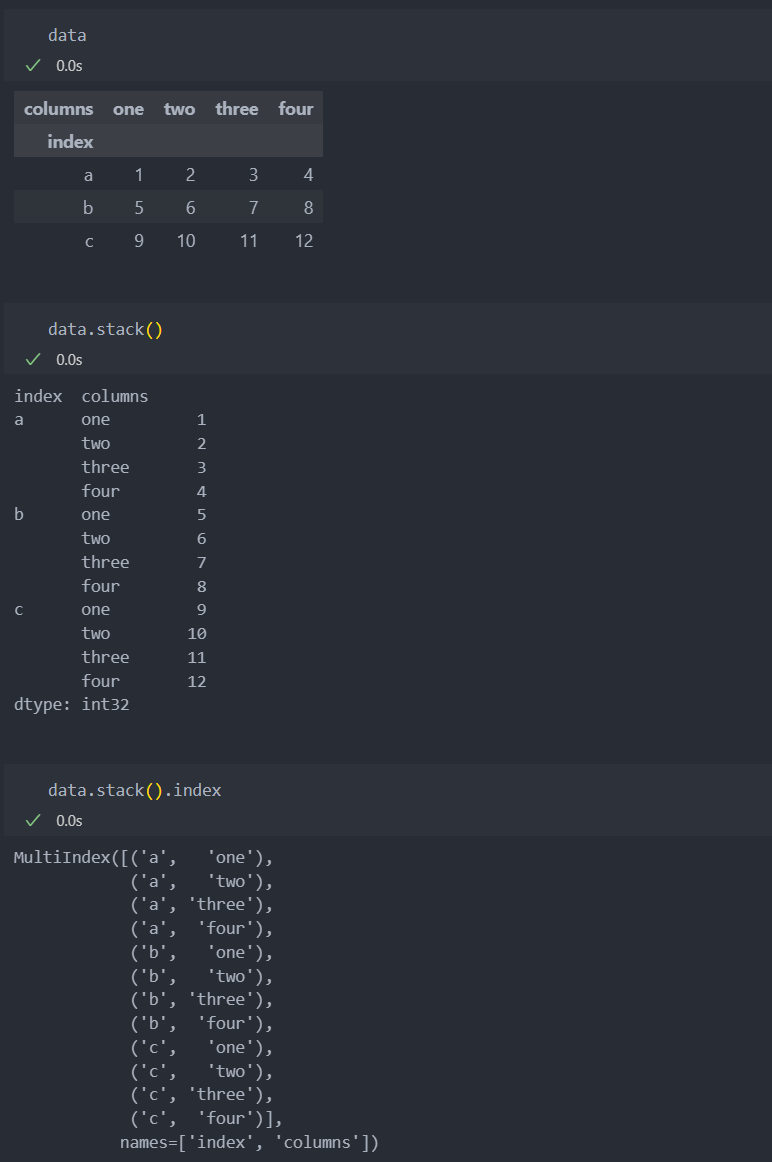
unstack
반대로 인덱스 a, b, c가 컬럼에 피벗이 된다.
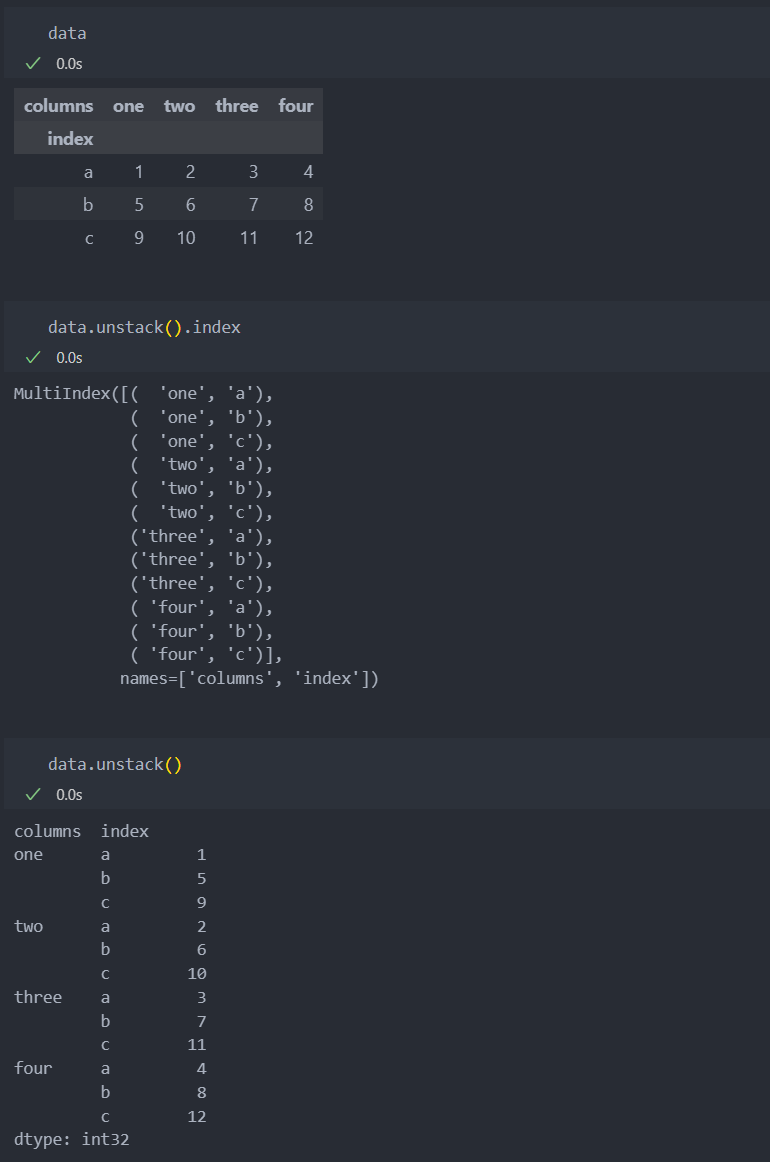
pivot
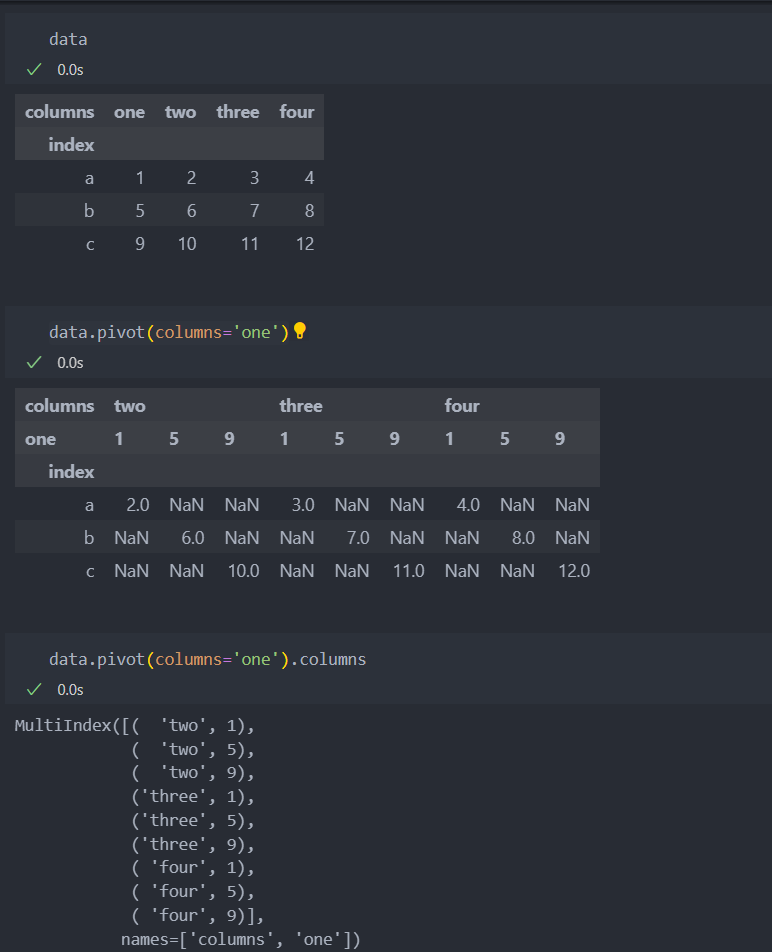
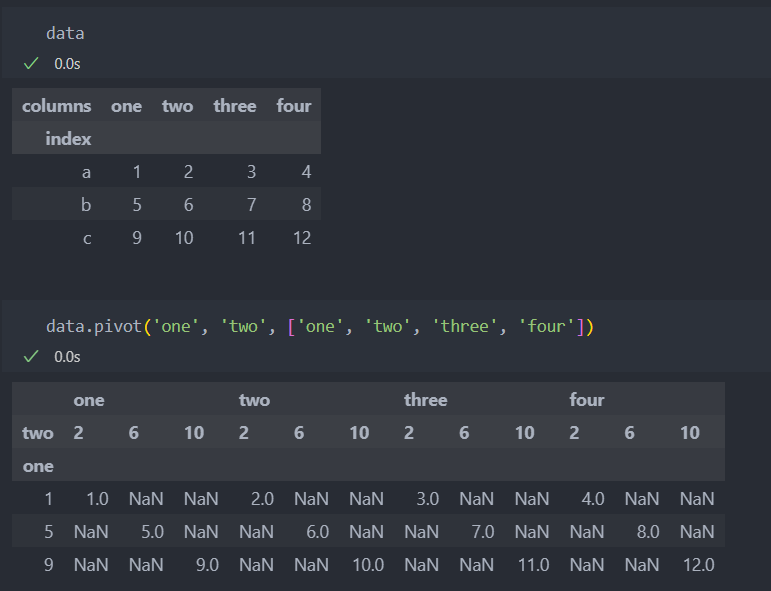
컬럼값을 기준으로 멀티인덱스 컬럼을 생성한다.
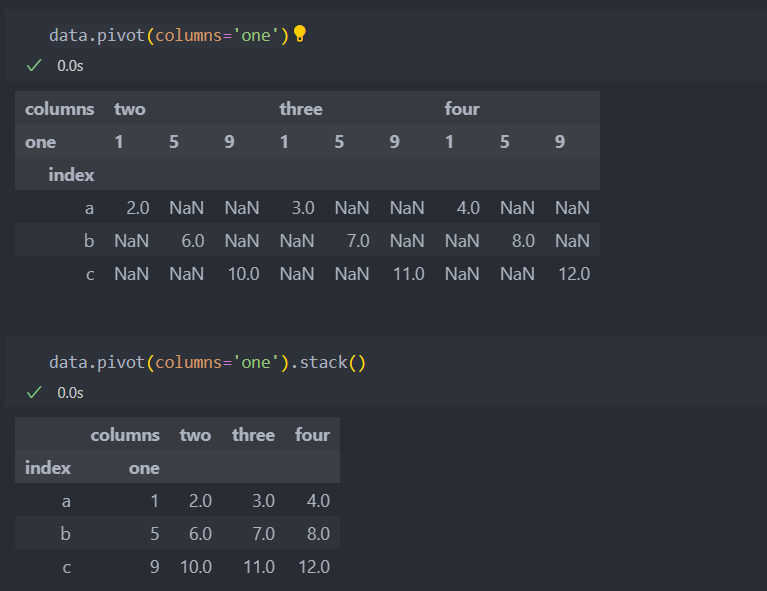
NaN값을 재정렬하여 없앨 때에는 stack를 사용하면 된다.
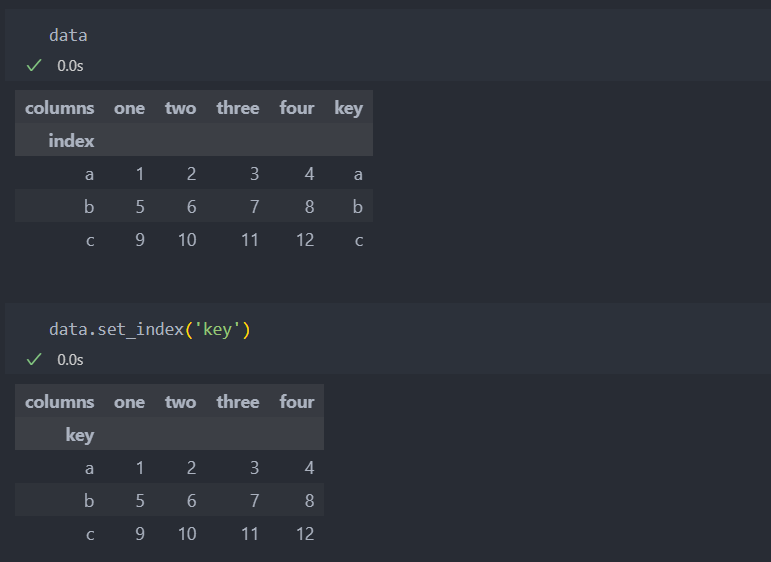
컬럼값을 인덱스로 설정할 수 있다.
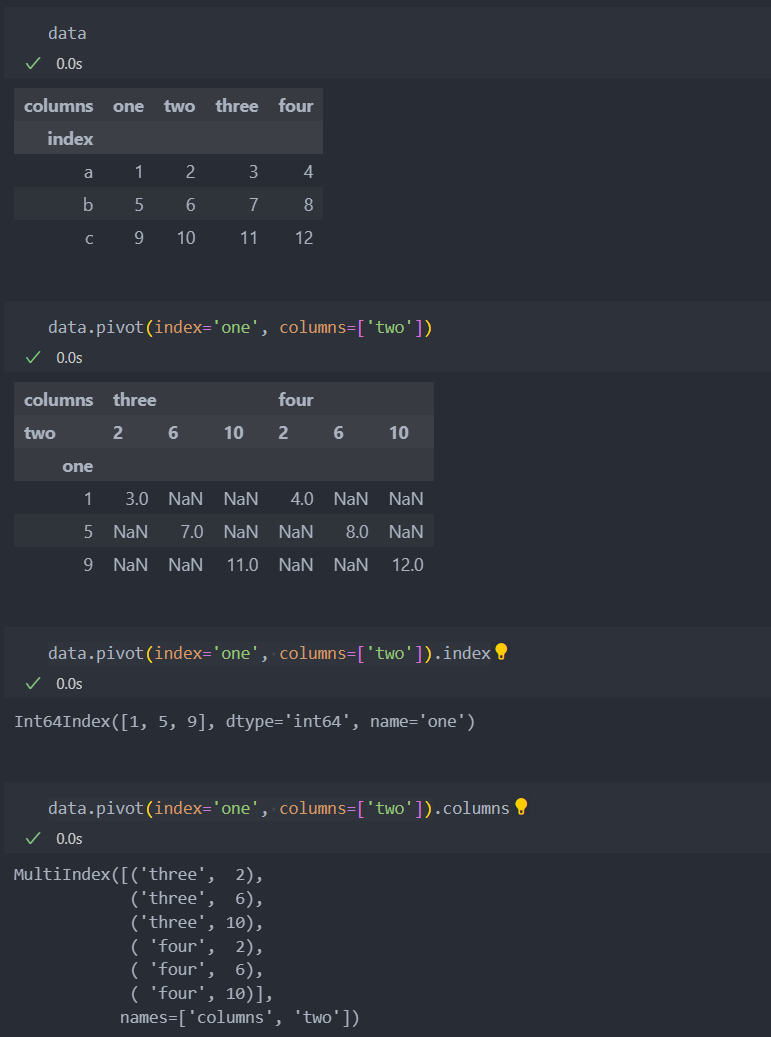
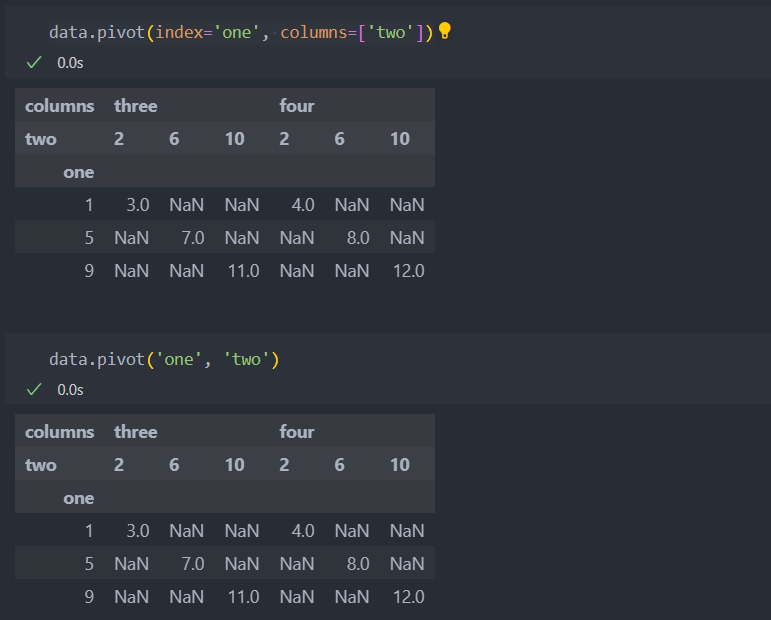
pivot 인자를 설정하지 않는다면, 첫 번째 인자는 인덱스로 두 번째 인자는 컬럼으로 지정된다.
그리고 세번째 인자를 지정하여 DataFrame에 채워질 값을 지정할 수도 있다.
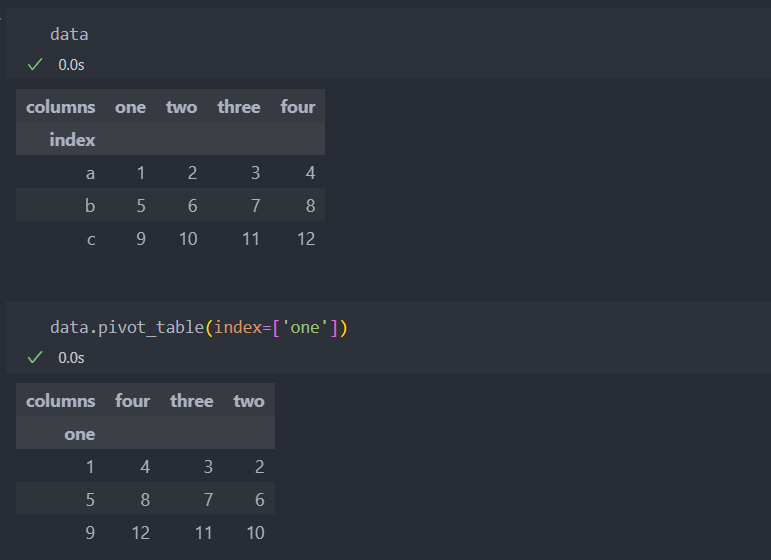
단순히 컬럼을 인덱스로 지정하려면 pivot_table 메서드를 사용하면 된다.
set_index를 사용하여 컬럼을 인덱스로 지정할 수도 있다.
pivot는 계층을 생성하여 테이블을 변형할 수 있도록 해준다.
melt
pivot과 반대되는 연산을 한다.
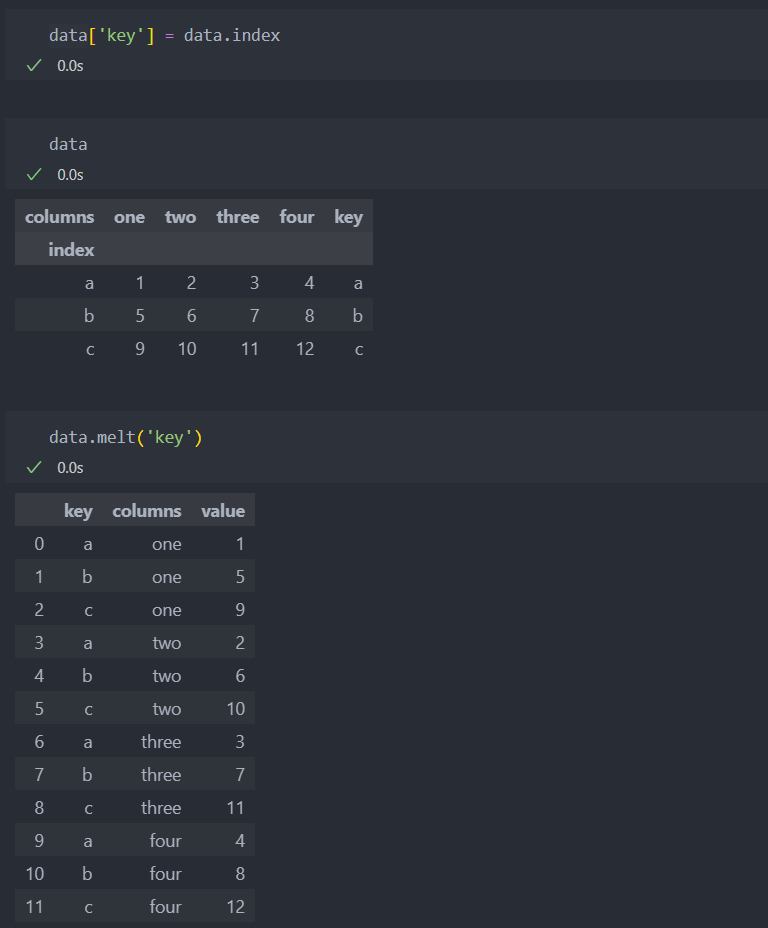
인덱스로 지정할 'key' 컬럼을 하나 생성하고 melt에 'key'값을 던저주면 컬럼쪽으로 붙어 넓은 형식의 데이터프레임에서 밑으로 긴 형식의 데이터프레임 형식으로 생성된다.
melt는 pivot의 반대되는 연산이기에 pivot를 해주면 원래대로 돌아간다. 'key'값을 인덱스로 기존의 컬럼을 columns로 값을 value로 던져주면 된다. 그리고 인덱스 key를 다시 컬럼 값으로 돌리기 위해 reset_index 사용한다. 인덱스 이름까지 원래대로 돌리려면 rename을 적용시킨다.