
문제 정의
고객 여정의 페이지를 분석하여 고객 이탈 및 종료를 줄이고 잔존율을 높여야 한다.
데이터 확인
데이터 및 소스코드 : GitHub
- 데이터 상세
-
Administrative Administrative_Duration Informational Informational_Duration ProductRelated ProductRelated_Duration 관리페이지 ID 관리페이지 체류시간 정보페이지 ID 정보페이지 체류시간 제품페이지 ID 제품페이지 체류시간 -
BounceRates ExitRates PageValues SpecialDay Month OperatingSystems 이탈률 종료율 페이지클릭수 기념일여부 월 운영시스템 -
Browser Region TrafficType VisitorType Weekend Revenue 브라우저 지역 트래픽 타입 방문타입 주말 손익
데이터 EDA & 전처리
기본 데이터 확인
데이터의 특징에 비해서 샘플수는 적다.
df.shape
>
(12330, 18)대부분의 데이터는 수치화 되어 있다.
# 대부분의 데이터는 수치형
df.info()
>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12330 entries, 0 to 12329
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Administrative 12330 non-null int64
1 Administrative_Duration 12330 non-null float64
2 Informational 12330 non-null int64
3 Informational_Duration 12330 non-null float64
4 ProductRelated 12330 non-null int64
5 ProductRelated_Duration 12330 non-null float64
6 BounceRates 12330 non-null float64
7 ExitRates 12330 non-null float64
8 PageValues 12330 non-null float64
9 SpecialDay 12330 non-null float64
10 Month 12330 non-null object
11 OperatingSystems 12330 non-null int64
12 Browser 12330 non-null int64
13 Region 12330 non-null int64
14 TrafficType 12330 non-null int64
15 VisitorType 12330 non-null object
16 Weekend 12330 non-null bool
17 Revenue 12330 non-null bool
dtypes: bool(2), float64(7), int64(7), object(2)
memory usage: 1.5+ MB결측치는 없는 것으로 확인 된다.
df.isnull().sum()
>
Administrative 0
Administrative_Duration 0
Informational 0
Informational_Duration 0
ProductRelated 0
ProductRelated_Duration 0
BounceRates 0
ExitRates 0
PageValues 0
SpecialDay 0
Month 0
OperatingSystems 0
Browser 0
Region 0
TrafficType 0
VisitorType 0
Weekend 0
Revenue 0
dtype: int64describe()로 간단히 이상치를 살펴보면, 최대값에 비해 평균이나 IQR 75%에 비해 큰 값들이 존재한다. 그리고 특징별 상세 데이터를 살펴본다.
한 page에 머무른 시간이 지나치게 높은 값들은 노이즈나 페이지를 클릭 후 자리를 비우는 등의 값들일 수 있다. 이런 것들은 분석을 해가면서 좀 더 상세히 살펴보기로 한다.
df.describe()
# 컬럼별 상세 확인
for col in df.columns:
print(f'feature num : {df[col].nunique()}')
print(f'feature unique : {df[col].unique()}')Page 데이터 탐색
월 별
특정 월의 고객수가 많고 1, 4월이 빠진 총 10개월의 데이터로 특정 월에 접속하여 판매가 되는 물품일 수도 있다.
# 월별로 정렬 : 1년이 아닌 2월부터 12월까지 4월읠 제외한 총 10개월의 데이터
pd.DataFrame(df['Month'].value_counts(), index=['Feb', 'Mar', 'May', 'June', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'])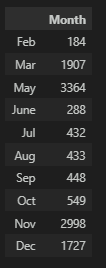
관리/정보/제품 페이지 별
관리/정보/제품 페이지 별 고객 여정에서 가장 클릭수가 많았던 여정을 살펴보면 고객의 페이지 여정이 나타나고 이탈률이나 종료율이 확인이 된다.
df_page_filter = df[['Administrative', 'Informational', 'ProductRelated', 'BounceRates', 'ExitRates', 'PageValues']]
df_page_filter
# 관리/정보/제품 페이지별 ID 여정 : 총 3131개별 이탈률, 종료율, 페이지클릭수 평균
df_page_filter = df_page_filter.groupby(['Administrative', 'Informational', 'ProductRelated'], as_index=False).mean()
df_page_filter['Administrative'].nunique()
df_page_filter.sort_values(by='PageValues', ascending=False)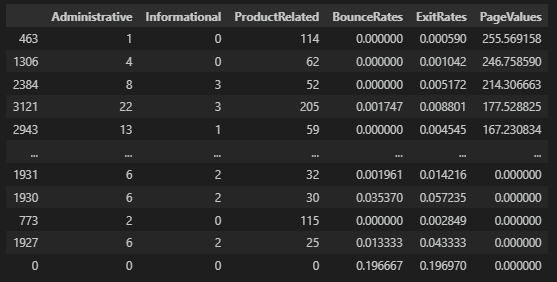
구매 여정 분석
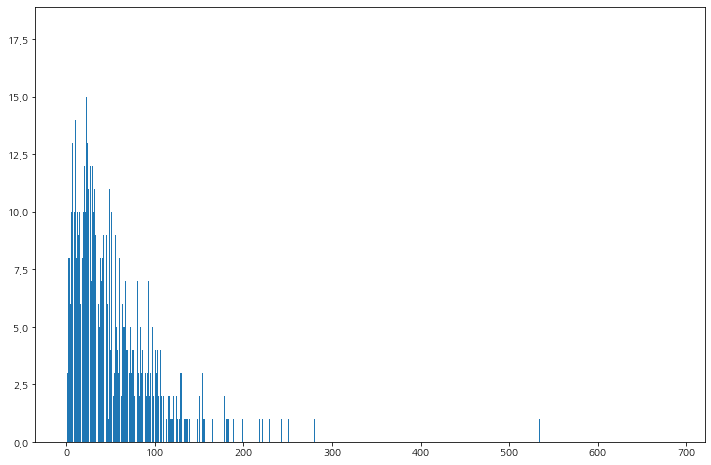
페이지 뷰 별
페이지 뷰의 클릭의 수를 확인해보면, 0에서 50까지의 데이터가 대부분을 차지하고 있고 페이지에 들어와 아무런 액션을 취하지 않고 종료하거나 이탈하는 고객수가 매우 많음을 알 수 있다.
plt.figure(figsize=(12, 8))
sns.distplot(df_page_filter['PageValues'])
plt.show()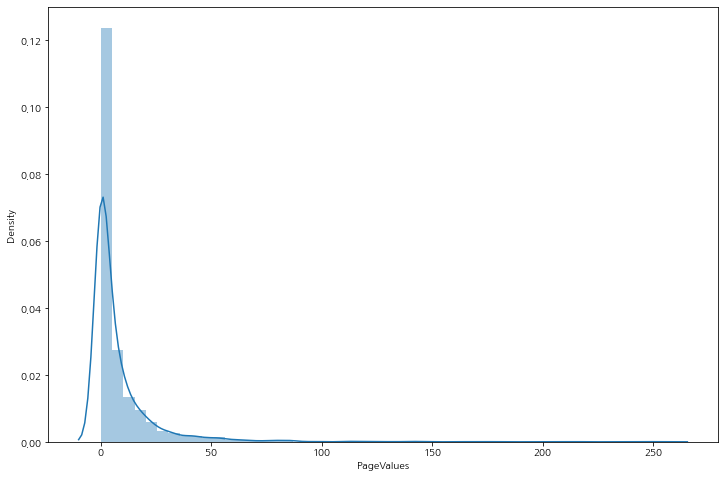
전체 여정에서 아무런 액션을 취하지 않고 이탈/종료 혹은 다른 페이지로 넘어갔던 여정이 반에 해당된다.
# 반에 해당하는 여정이 아무런 액션을 취하지 않았다. 다른 페이지로 넘어갔을 수도 있으니 더 살펴볼 필요성이 있다.
df_page_filter[df_page_filter['PageValues']==0]
>
len => 1417이탈률 페이지 탐색
페이지별 이탈율을 그래프로 살펴본다. 평균 이탈율에 비해서 이탈율이 높은 데이터를 중심으로 살펴볼 필요성이 있다.
# 평균 이탈율 : 0.7%
df_page_filter['BounceRates'].mean()
>
0.00746099327081189
# 이탈율별
df_page_filter.sort_values(by='BounceRates', ascending=False)
# 그래프
sns.displot(df_page_filter, x='BounceRates')
plt.gcf().set_size_inches(25, 8)
plt.show()

IQR 3분위수를 기준으로 그 보다 높은 이탈율을 좀 더 자세하게 살펴본다. IQR 3분위수 보다 높은 이탈율은 문제가 있다고 판단하고 진행한다.
df_page_filter['BounceRates'].describe()
>
count 3131.000000
mean 0.007461
std 0.011096
min 0.000000
25% 0.001362
50% 0.005000
75% 0.009804
max 0.200000
Name: BounceRates, dtype: float64
# 3분위수 보다 높은 이탈율 수
len(df_page_filter[df_page_filter['BounceRates']>0.009804])
>
781Administrative
시작 페이지인 관리 페이지(Administrative)별로 이탈율을 확인해보자.
페이지의 번호가 작을수록 이탈율의 비율이 높은 경향이 있음을 확인할 수 있다.
관리 페이지의 메인 페이지에서 이탈율이 높은 것으로 보아서 메인 페이지의 변화가 필요해 보인다.
df_admin = df_page_filter[df_page_filter['BounceRates']>0.009804].groupby('Administrative', as_index=False)['Informational'].count().sort_values(by='Informational', ascending=False).set_index(keys='Administrative')
df_admin.columns = ['count']
df_admin
# 그래프
plt.figure(figsize=(12, 8))
plt.bar(df_admin.index, df_admin['count'])
plt.show()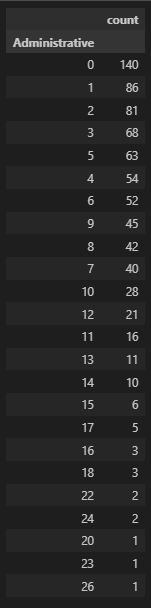
Informational
정보 페이지(Informational)별로 이탈율을 확인해보자.
정보 페이지도 ID가 낮을수록 이탈률이 높다.
df_info = df_page_filter[df_page_filter['BounceRates']>0.009804].groupby('Informational', as_index=False)['ProductRelated'].count().sort_values(by='ProductRelated', ascending=False).set_index(keys='Informational')
df_info.columns = ['count']
df_info
# 그래프
plt.figure(figsize=(12, 8))
plt.bar(df_info.index, df_info['count'])
plt.show()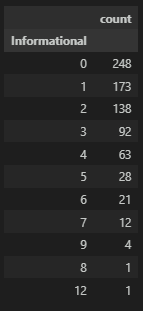
ProductRelated
제품 페이지(ProductRelated)별로 이탈율을 확인해보자.
제품 페이지는 제품의 수 만큼 많기에 특정한 제품의 숫자보다는 어떤 제품인지의 정보를 더 살펴봐야 하는데, 그 정보가 없어서 정확한 분석을 하기에는 용이하지 않다. 하지만 ID의 번호가 작을수록 이탈률이 높은 경향이 있다.
df_prod = df_page_filter[df_page_filter['BounceRates']>0.009804].groupby('ProductRelated', as_index=False)['BounceRates'].count().sort_values(by='BounceRates', ascending=False).set_index(keys='ProductRelated')
df_prod.columns = ['count']
df_prod
# 그래프
plt.figure(figsize=(12, 8))
plt.bar(df_prod.index, df_prod['count'])
plt.show()
종료율 페이지 탐색
종료율도 이탈률과 같은 방법으로 탐색을 한다.
# 평균 종료율 : 2.1%
df_page_filter['ExitRates'].mean()
df_page_filter.sort_values(by='ExitRates', ascending=False)
# 그래프
sns.displot(df_page_filter, x='ExitRates')
plt.gcf().set_size_inches(25, 8)
plt.show()

IQR 3분위수를 기준으로 그 보다 높은 종료율 좀 더 자세하게 살펴본다. IQR 3분위수 보다 높은 종료율은 문제가 있다고 판단하고 진행한다.
df_page_filter['ExitRates'].describe()
>
count 3131.000000
mean 0.021915
std 0.014863
min 0.000000
25% 0.013098
50% 0.019235
75% 0.027327
max 0.200000
Name: ExitRates, dtype: float64
df_page_filter[df_page_filter['ExitRates']>0.027327]
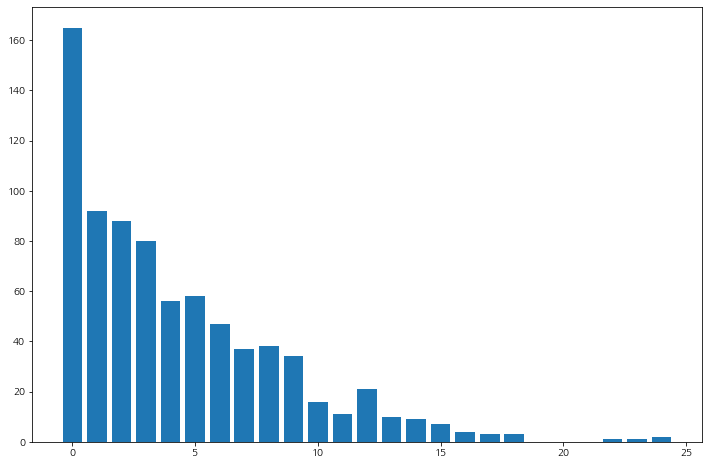
Administrative
시작 페이지인 관리 페이지(Administrative)별로 종료율 확인해보자.
df_admin = df_page_filter[df_page_filter['ExitRates']>0.027327].groupby('Administrative', as_index=False)['Informational'].count().sort_values(by='Informational', ascending=False).set_index(keys='Administrative')
df_admin.columns = ['count']
df_admin
# 그래프
plt.figure(figsize=(12, 8))
plt.bar(df_admin.index, df_admin['count'])
plt.show()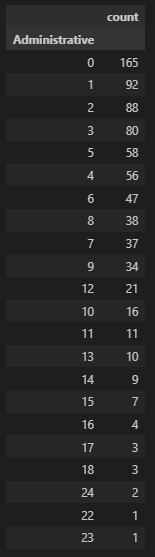
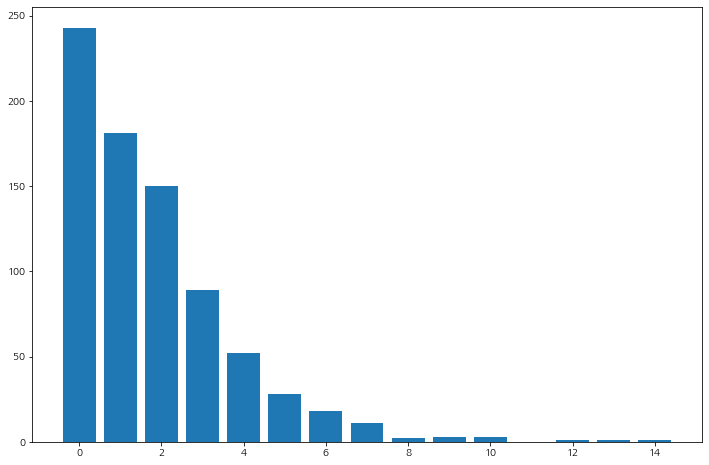
Informational
정보 페이지(Informational)별로 종료율 확인해보자.
df_info = df_page_filter[df_page_filter['ExitRates']>0.027327].groupby('Informational', as_index=False)['Administrative'].count().sort_values(by='Administrative', ascending=False).set_index(keys='Informational')
df_info.columns = ['count']
df_info
# 그래프
plt.figure(figsize=(12, 8))
plt.bar(df_info.index, df_info['count'])
plt.show()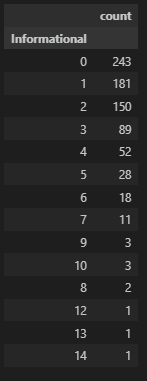
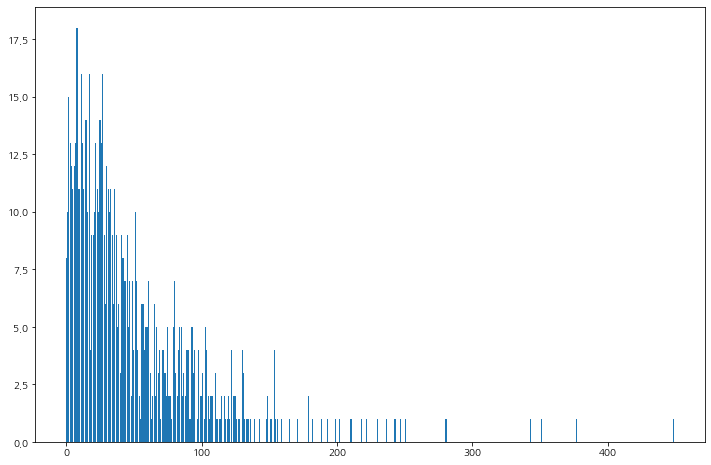
ProductRelated
제품 페이지(ProductRelated)별로 종료율 확인해보자.
df_prod = df_page_filter[df_page_filter['ExitRates']>0.027327].groupby('ProductRelated', as_index=False)['Informational'].count().sort_values(by='Informational', ascending=False).set_index(keys='ProductRelated')
df_prod.columns = ['count']
df_prod
# 그래프
plt.figure(figsize=(12, 8))
plt.bar(df_prod.index, df_prod['count'])
plt.show()
개선 페이지
이탈률과 종료율이 IQR 3분위수를 넘어가는 페이지를 확인해본다.
3분위수를 넘어가는 페이지 별로 이탈률과 종료율을 구하고 합쳐서 가장 개선이 시급한 페이지라고 판단할 수 있도록 한다.
그리고 가장 많이 검출되는 ID가 개선이 시급한 페이지라고 할 수 있다.
Administrative
# 이탈률 3 분위수 이상
df_admin_B = df_page_filter[df_page_filter['BounceRates']>0.009804].groupby('Administrative', as_index=False)['Administrative'].count()
df_admin_B = df_admin_B.reset_index()
df_admin_B.columns = ['ID', 'BounceRates_cnt']
df_admin_B
# # 종료율 3 분위수 이상
df_admin_E = df_page_filter[df_page_filter['ExitRates']>0.027327].groupby('Administrative', as_index=False)['Administrative'].count()
df_admin_E = df_admin_E.reset_index()
df_admin_E.columns = ['ID', 'ExitRates_cnt']
df_admin_E
# merge
df_admin_merge = pd.merge(df_admin_B, df_admin_E, how='left', on='ID')
df_admin_merge['total'] = df_admin_merge['BounceRates_cnt'] + df_admin_merge['ExitRates_cnt']
df_admin_merge.sort_values(by='total', ascending=False)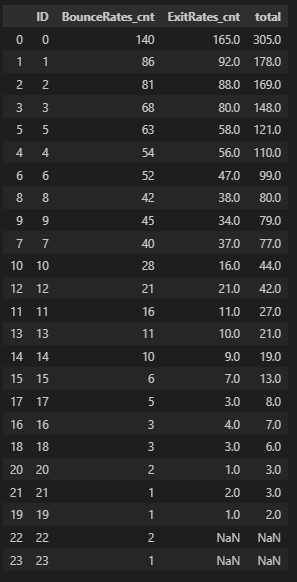
Informational
# 이탈률 3 분위수 이상
df_info_B = df_page_filter[df_page_filter['BounceRates']>0.009804].groupby('Informational', as_index=False)['Informational'].count()
df_info_B = df_info_B.reset_index()
df_info_B.columns = ['ID', 'BounceRates_cnt']
df_info_B
# # 종료율 3 분위수 이상
df_info_E = df_page_filter[df_page_filter['ExitRates']>0.027327].groupby('Informational', as_index=False)['Informational'].count()
df_info_E = df_info_E.reset_index()
df_info_E.columns = ['ID', 'ExitRates_cnt']
df_info_E
# merge
df_info_merge = pd.merge(df_info_B, df_info_E, how='left', on='ID')
df_info_merge['total'] = df_info_merge['BounceRates_cnt'] + df_info_merge['ExitRates_cnt']
df_info_merge.sort_values(by='total', ascending=False)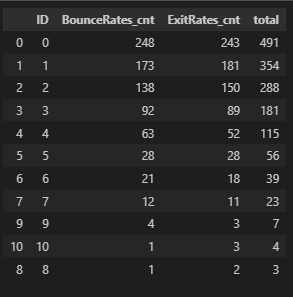
ProductRelated
# 이탈률 3 분위수 이상
df_prod_B = df_page_filter[df_page_filter['BounceRates']>0.009804].groupby('ProductRelated', as_index=False)['ProductRelated'].count()
df_prod_B = df_prod_B.reset_index()
df_prod_B.columns = ['ID', 'BounceRates_cnt']
df_prod_B
# # 종료율 3 분위수 이상
df_prod_E = df_page_filter[df_page_filter['ExitRates']>0.027327].groupby('ProductRelated', as_index=False)['ProductRelated'].count()
df_prod_E = df_prod_E.reset_index()
df_prod_E.columns = ['ID', 'ExitRates_cnt']
df_prod_E
# merge
df_prod_merge = pd.merge(df_prod_B, df_prod_E, how='left', on='ID')
df_prod_merge['total'] = df_prod_merge['BounceRates_cnt'] + df_prod_merge['ExitRates_cnt']
df_prod_merge.sort_values(by='total', ascending=False)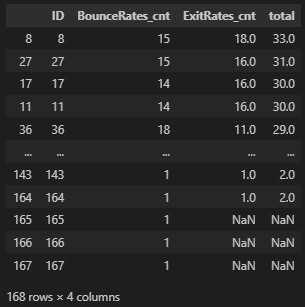
여정 개선점
고객 여정 중에서 경험/클릭수가 높으면서도 이탈률과 종료율이 높은 페이지들을 살펴보자.
경험/클릭수가 낮으면서 이탈률과 종료율이 높은 것은 당장 시급한 개선이 필요한 페이지는 아니라고 볼 수 있다.
관리/정보/제품 페이지별로 이탈률과 종료율의 데이터만 가져와서 연산한다.
df_jny = df.groupby(['Administrative', 'Informational', 'ProductRelated'], as_index=False)[['BounceRates', 'ExitRates']].agg(['count', 'mean']).reset_index()
df_jny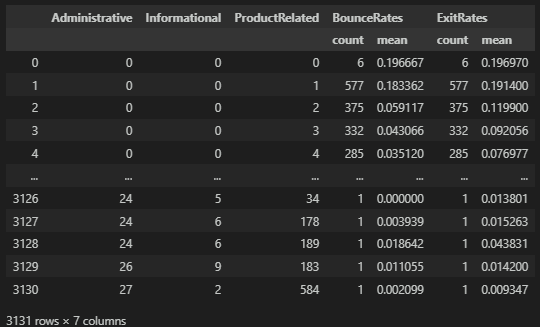
그리고 이탈률과 종료율별로 경험/클릭이 높고 이탈률과 종료율이 높은 순으로 살펴보면 개선이 필요한 페이지를 선정할 수 있다.
관리-0, 1, 2, 3, 정보-0, 1, 2, 3, 5 제품-1, 2, 3, 4, 5 순으로 고객이 많이 클릭하여 보는 페이지인 동시에 이탈률과 종료율도 높다.
어떻게 페이지를 개선하여 다른 페이지로 이어서 고객의 잔존률을 높일지 고민해야 하는 부분이다.
# 0, 0, 1 의 경로가 사용자가 많이 클릭하는 경로인 동시에 이탈률도 높다
df_jny.sort_values(by=[('BounceRates', 'count'), ('BounceRates', 'mean')], ascending=False)
# 0, 0, 1 의 경로가 사용자가 많이 클릭하는 경로인 동시에 종료율도 높다
df_jny.sort_values(by=[('ExitRates', 'count'), ('ExitRates', 'mean')], ascending=False)기대효과
MAU(Monthly Active User) 증가, 이탈 고객 감소를 통한 영업 이익 증대
