바로 이전 시리즈에서 공공 자전거 수요 예측이라는 주제로 머신러닝을 통해 회귀 문제를 풀어보았다. 이번 시리즈에서는 분류 문제를 다룰 것이고 데이터는 kaggle에서 분류 문제로 유명한 타이타닉 데이터를 사용해 타이타닉호의 생존자를 예측하는 문제를 풀어볼 것이다.
이 포스트에서는 2개의 클래스(생존/생존불가)가 있는 이진 분류(Binary classification) 문제를 다룬다.
1. 데이터 소개
이 데이터에는 타이타닉호에 탑승한 승객들의 정보(성별, 나이, 함께 탑승한 가족, 승선 위치, 티켓 정보 등)가 들어있다. 문제를 풀어가는 과정은 다음과 같다.
- 타이타닉호에서 살아남은 혹은 그렇지 못한 사람들의 데이터를 학습시켜 분류 모델을 만든다.
- 학습 시키지 않은 새로운 승객의 정보를 입력했을 때 승객이 살아남을 것인지 예측한다(생존한다/생존하지 못한다).
먼저 학습 데이터(train.csv)는 승객의 생존 여부 정보가 포함된 데이터이고, 테스트 데이터(test.csv)에는 승객의 생존 여부 정보가 없다. 그래서 이 정보가 빠진 테스트 데이터를 통해 승객의 생존 여부를 예측하는 것이 이번 시리즈에서 해결할 과제이다.
- train.csv

- test.csv
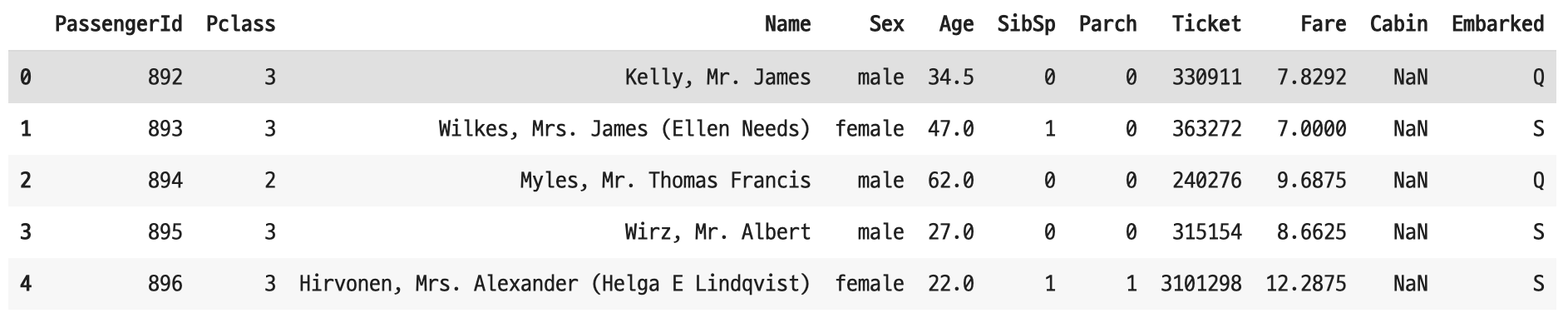
- gender_submission.csv
2. EDA(탐색적 데이터 분석)
2-1. 결측치
결측치를 비율과 수로 시각화하여 나타냈더니 나이, 객실 정보, 탑승한 항구 데이터에 결측치가 존재한다.
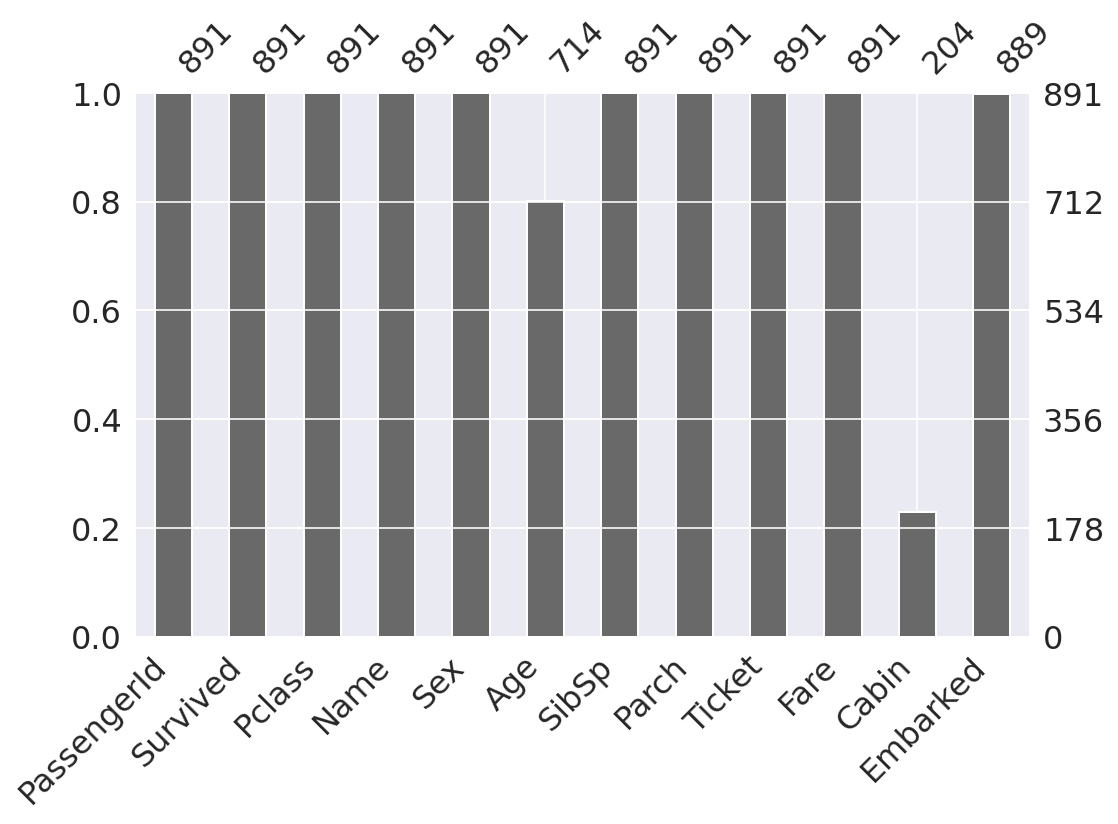
- 전체 데이터의 대부분이 결측치인 객실 정보 특성은 제거하기로 한다.
- 탑승 항구 데이터에는 단 2개의 결측치가 존재함으로 그냥 제거하기로 한다.
- 나이 데이터는 머신러닝 라이브러리의 imputer 패키지를 활용해 결측치를 채우기로 한다.
2-2. 베이스라인 모델
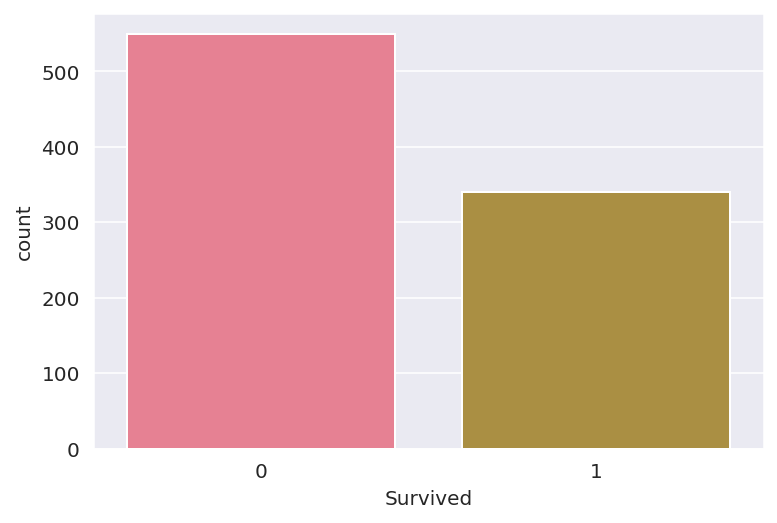
분류 문제에서 기준 모델은 가장 빈번하게 일어나는 클래스를 기준(정확도: 0.6175)으로 만들기 때문에 타겟(생존자 수)는 모든 승객이 생존하지 못할 것이라고 예측하는 모델을 베이스라인으로 정했다.
2-3. 생존과 관계 있는 특성
1. 티켓 클래스와 생존과의 관계
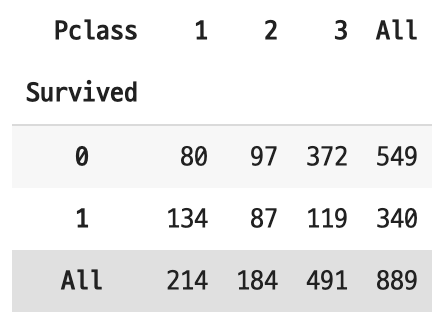
티켓 클래스는 1, 2, 3 순으로 높은 등급인데 티켓 클래스가 가장 낮을 때(3rd class), 생존자 수가 가장 적었다.
2. 성별과 생존과의 관계
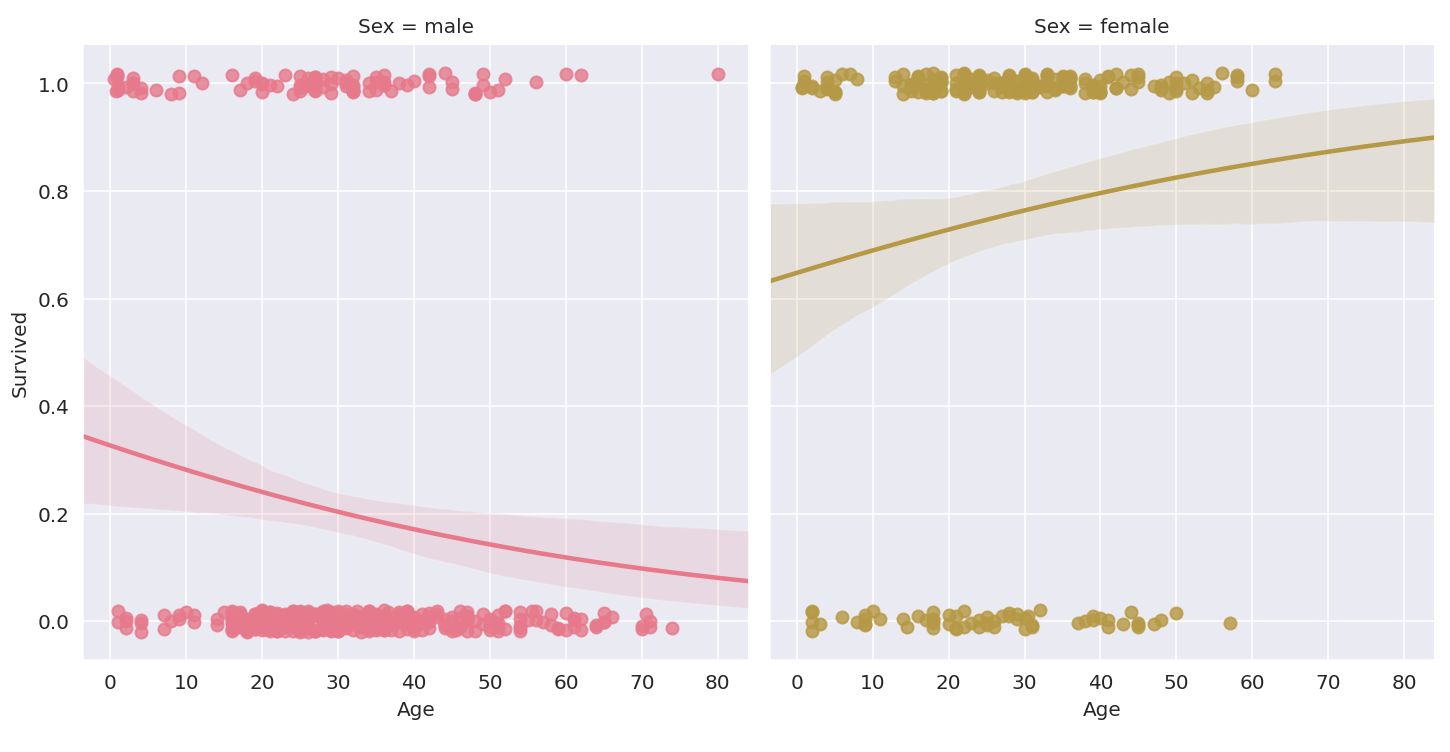
남성은 생존자보다 비생존자가 여성은 비생존자보다 생존자의 수가 더 많은 것을 확인할 수 있다.
3. 나이와 생존과의 관계
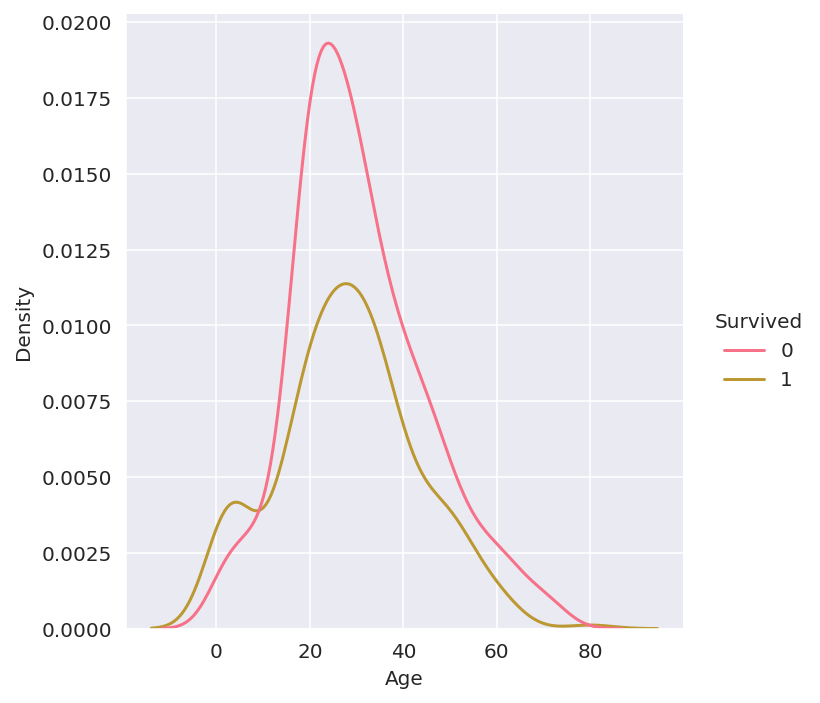
생존자와 비생존자의 나이 분포를 비교하니 생존자의 나이가 전체적으로 적은 것 같다.
4. 탑승 항구와 생존과의 관계
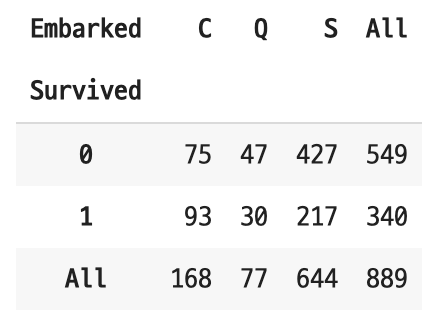
비율로 봤을 때 'Southampton' 항구에서 탑승한 승객의 생존자 수가 가장 낮은 것 같다. 하지만 Southampton 항구에서 탑승한 승객의 정확한 정보를 확인할 필요가 있다고 판단해 탑승 항구별 성비와 티켓 클래스 비율도 함께 확인했다.

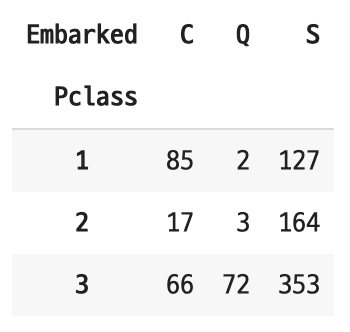
분석 결과는 다음과 같다.
- 'Southampton' 항구가 다른 항구보다 탑승한 승객의 수가 많다.
- 승객중 3등급 티켓 클래스를 가진 탑승객이 많았다.
- 위에서 티켓 클래스와 생존과의 관계에서 3등급 티켓 클래스를 가진 승객의 생존자수가 가장 낮은 것을 확인했다.
- 단순히 어느 항구에서 탑승했는지가 생존 여부를 결정짓는 것은 아니라고 판단했다.
2-4. 데이터 불균형

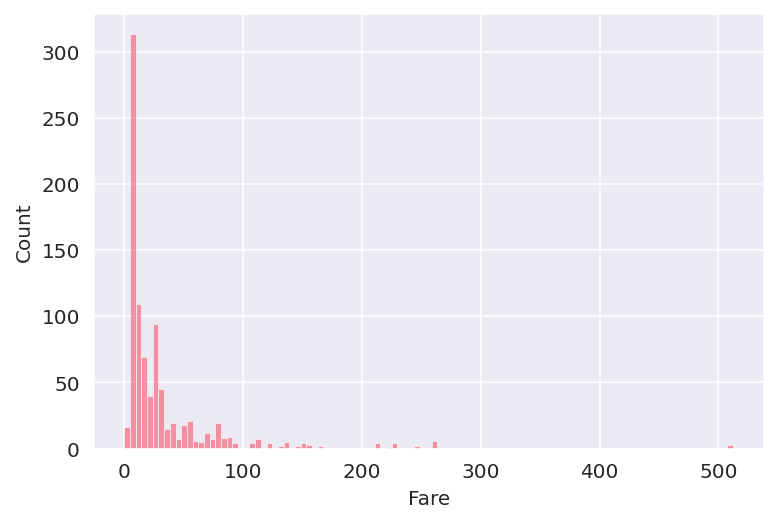
데이터에서 값의 불균형 정도를 확인했더니 그 정도가 가장 심한 것은 Fare 데이터였다. 데이터의 분산 정도를 그래프를 확인했더니 long-tail 그래프 형태가 나왔다.
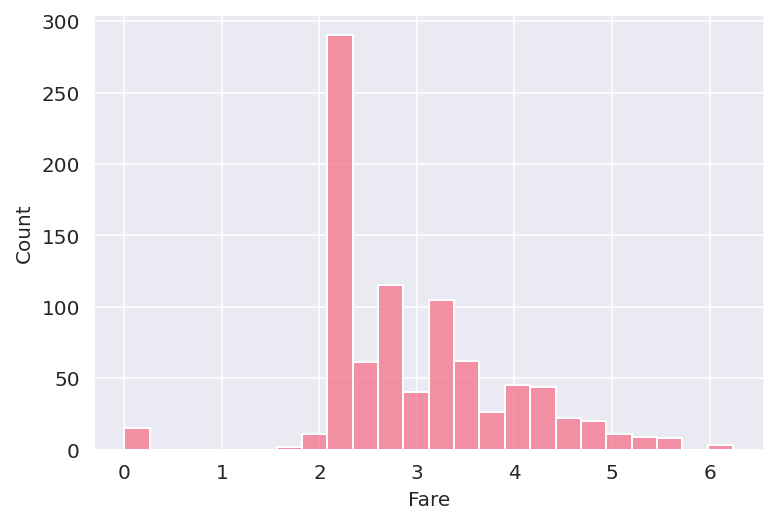
분산 정도를 완화하기 위해 값에 로그를 취해 데이터가 정규 분포 형태를 띄게 해주었다.
2-5. 특성 공학
1. 이름에서 타이틀 정보를 추출해 'Title' feature 추가
import re
unique = 'Mrs|Miss|Master|Mr'
def apply_title(name):
if re.search(unique, name) is not None:
title = re.search(unique, name)[0]
else:
title = 'Other'
return title
train_sub['Title'] = train_sub.apply(lambda x: apply_title(x['Name']), axis=1)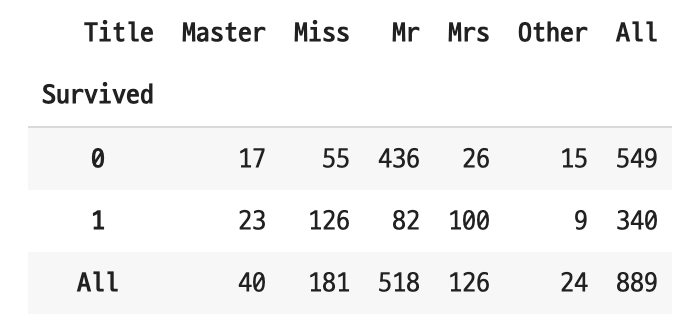
남성(Mr)의 경우 생존하지 못한 승객의 수가 확연히 많다(436).
2. SibSp와 Parch를 활용해 가족 구성원 수를 의미하는 'Family_size' feature 추가
train_sub['Family_size'] = train_sub['SibSp'] + train_sub['Parch'] + 1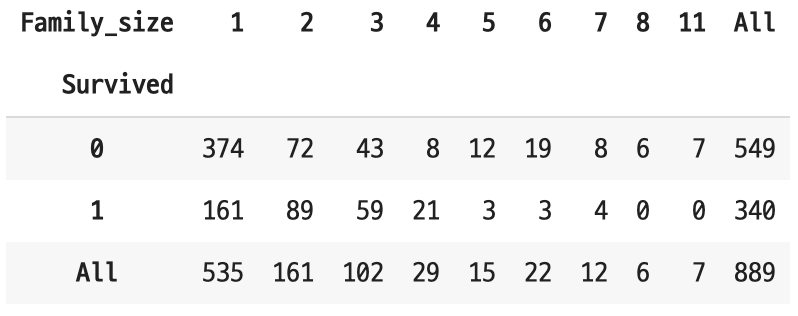
가족 구성원이 6명일 때보다 4명일 때 생존할 확률이 높아 보인다. 사이즈가 큰 경우(5명 이상) 거의 살아남지 못했다.
3. 범주형 데이터 처리 - Sex, Age, Embarked, Title, Family_size
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
label_encoded = train_sub[['Sex', 'Embarked', 'Title']].apply(label_encoder.fit_transform)
label_encoded.head()
train_sub['Sex_cat'] = label_encoded['Sex']
train_sub['Embarked_cat'] = label_encoded['Embarked']
train_sub['Title_cat'] = label_encoded['Title']
4. 타겟과 관련성이 없는/결측치가 대부분인/정보 누수 방지를 위해 새로운 feature 생성에 활용된 feature 제거 - PassengerId, Ticket, Cabin, Name, Age, SibSp, Parch
del_features = ['PassengerId', 'Name', 'Sex', 'SibSp', 'Parch', 'Ticket', 'Embarked', 'Title']
train_clean = train_sub[train_sub.columns.drop(del_features)]
train_clean.head(3)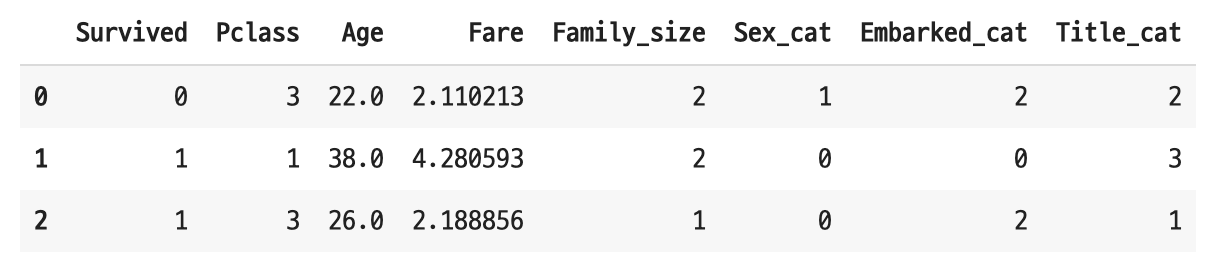
학습에 사용될 데이터가 만들어졌다.
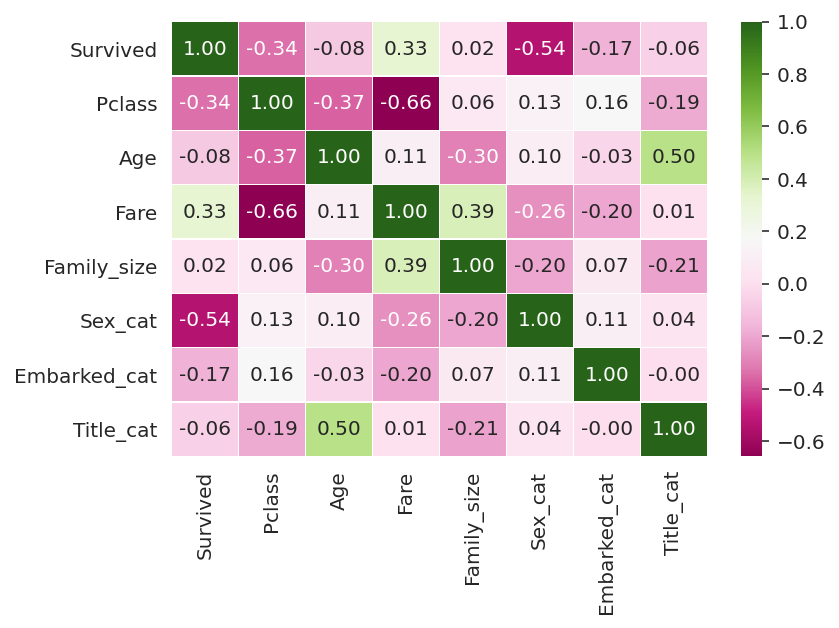
3. 상관 관계
특성들 간의 상관 관계를 확인해 보니 모든 특성이 타겟과 상관 관계가 있는 것 같다. EDA 과정에서도 확인했지만 특히 성별과 티켓 클래스가 생존과 가장 상관 관계가 높아 보인다.
4. 데이터셋 분리
테스트 데이터셋도 학습 데이터셋와 같이 feature engineering 작업을 진행하여 모양(feature 수)을 똑같이 만들어 준다.
target = 'Survived'
features = train_clean.columns.drop(target)
X = train_clean[features]
y = train_clean[target]
X_test = test_clean학습 데이터에서 검증 데이터셋을 분리하여 모델 검증에 활용한다.
from sklearn.model_selection import train_test_split
# 학습 데이터와 검증 데이터 비율은 75%, 25%
X_train, X_val, y_train, y_val = train_test_split(X, y, train_size=.75, random_state=100)5. 모델링
연속된 변환을 순차적으로 처리하도록
Pipeline래퍼 클래스(wrapper class)를 사용했다.결측치는
SimpleImputer를 활용해 처리하였다.분류 모델은 트리 앙상블 분류기
RandomForestClassifier를 활용해 만들었다.하이퍼파라미터 최적화는
RandomizedSearchCV를 활용했다.
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
estimators = [('imputer', SimpleImputer()), ('rf_cls', RandomForestClassifier(n_jobs=-1))]
# 파이프라인 선언
pipe = Pipeline(estimators)
# 튜닝할 파라미터 종류 및 범위
dists = {
"imputer__strategy": ['mean', 'median'],
"rf_cls__class_weight": ['balanced', 'balanced_subsample', None],
"rf_cls__n_estimators": range(100, 200, 10),
"rf_cls__max_features": range(1, 8),
"rf_cls__criterion": ['entropy', 'gini']
}
# 랜덤 조합으로 최적의 하이퍼파라미터 찾아주는 RandomizedSearchCV
clf = RandomizedSearchCV(pipe, param_distributions=dists, n_iter=50, cv=3, scoring='accuracy', verbose=1, n_jobs=-1)
# 학습
clf.fit(X_train, y_train)
# 최적의 하이퍼파라미터 조합
best_fit = clf.best_estimator_
# 모델 성능 평가 - accuracy score
print(f'accuracy score: {clf.best_score_}\n')6. 맺음말
모델 성능 평가로 accuracy score를 선택한 이유는 아래 이미지와 같이 '타이타닉 생존자수 예측' 대회에서 평가 기준으로 accuracy score가 사용되기 때문이다.

EDA를 하면서 생각났지만 미처 추가하지 못했던 것을 보충하고, 다른 모델도 사용해 재제출하면 더 높은 점수를 기대할 수 있을듯 하다.
