#55.TIL | Redis
https://slender-danger-059.notion.site/Redis-faa4acc3f64e4b1d9ab02eef6dd671f6
Redis란?
Remote(외부) dictionary(Key-Value) server(서버)
외부 딕셔너리 서버
RDB
- 오라클, MySQL 등
- 테이블 형식의 구조 (엑셀 시트와 같은..)
Redis란
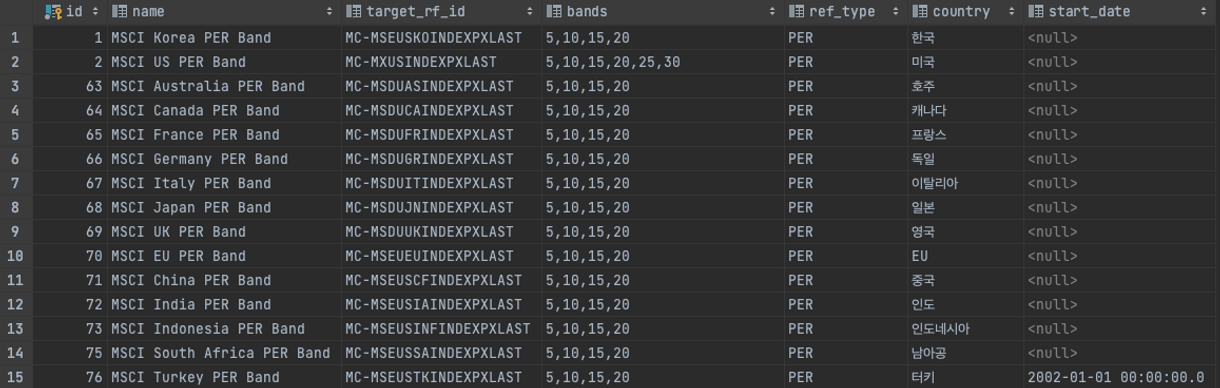
- Key-Value 형식의 구조
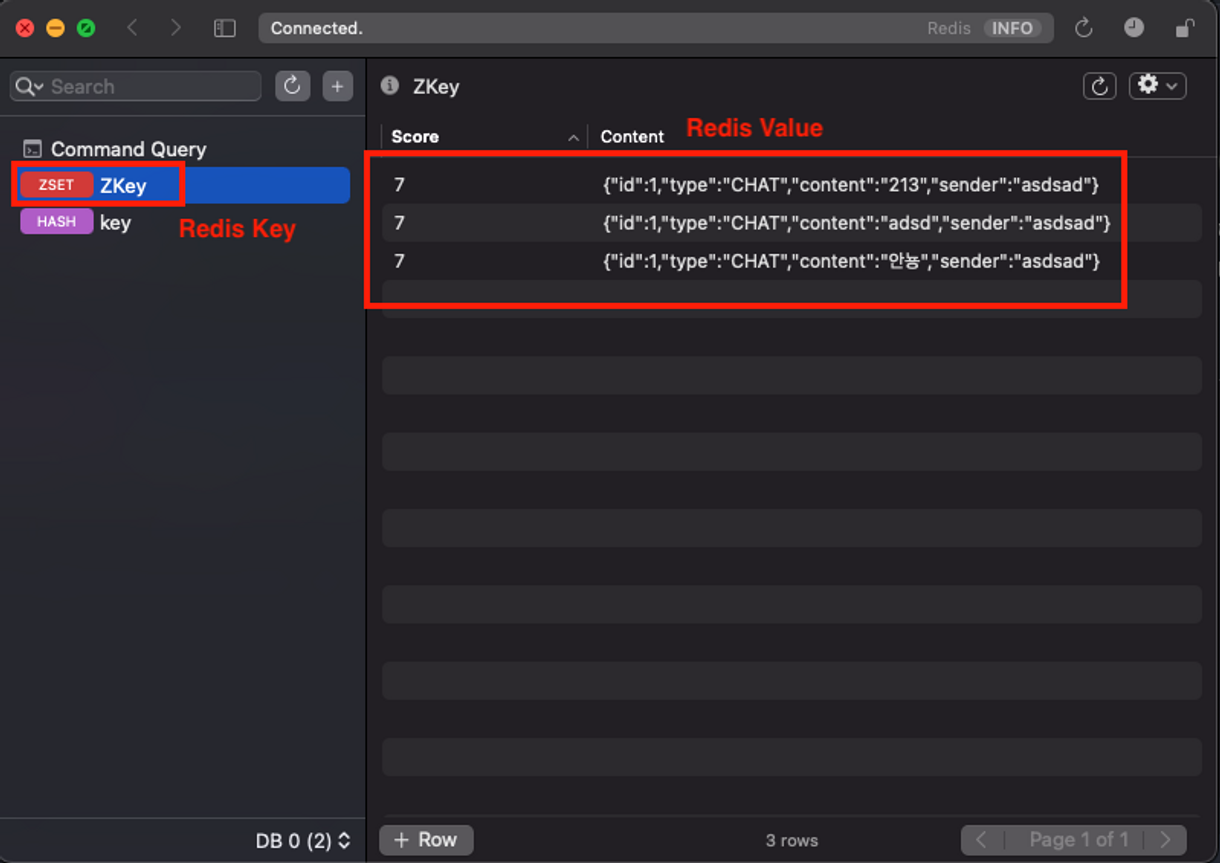
- 빠른 성능
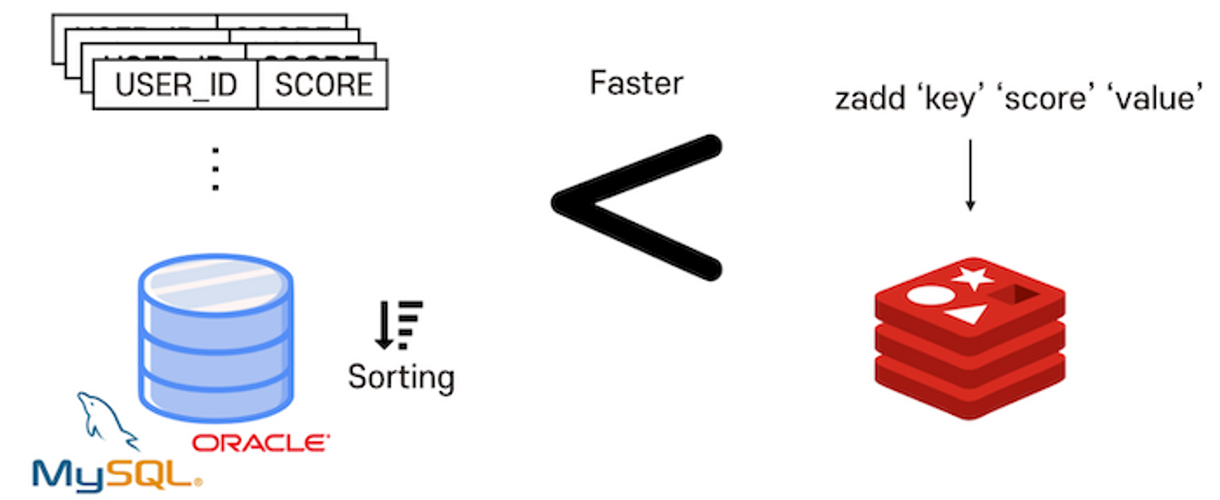
- 평균 작업속도 < 1ms
- 초당 수백만 건의 작업- In-memory 데이터 저장소
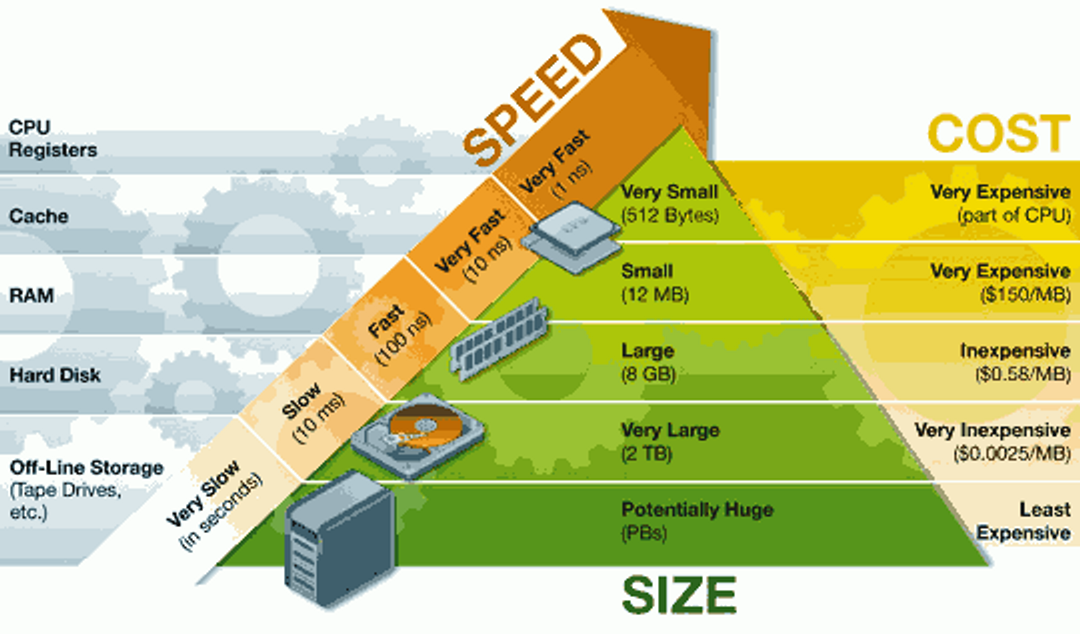
- 다양한 자료구조를 지원
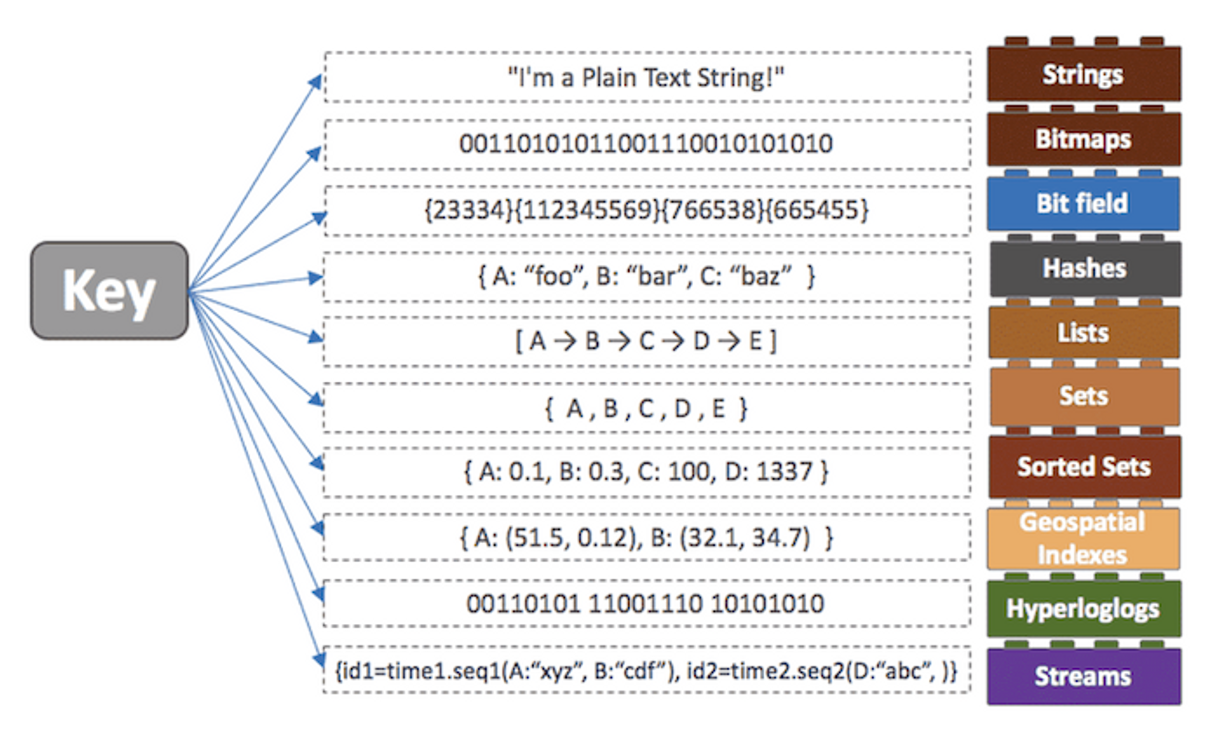
Redis 사용
세션 스토어로서의 활용
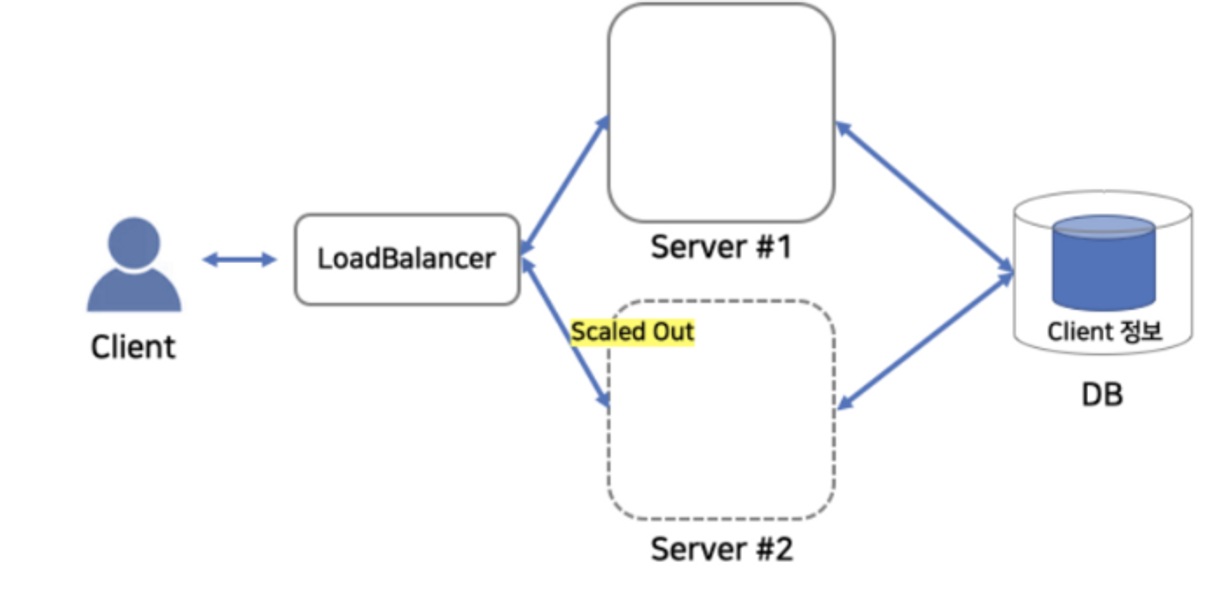
클라이언트에서 Server#1에 로그인 요청을 함.
Server#1에서 클라이언트 정보를 세션에 저장.
트래픽이 많아져서 서버가 스케일아웃(수평 확장)됨.
로드밸런서가 클라이언트의 요청을 Server#2로 보냄.
Server#2에는 클라이언트의 정보가 세션에 없음.
Redis를 세션 스토어로써 활용 가능.
물론, DB를 세션 스토어로 사용이 가능하겠지만 속도측면에서 많은 차이.
데이터 캐시로서의 활용
1) Redis 없을때

클라이언트 - 웹서버 - 데이터베이스
데이터를 캐시할 수 없을까
2) Redis 있을때
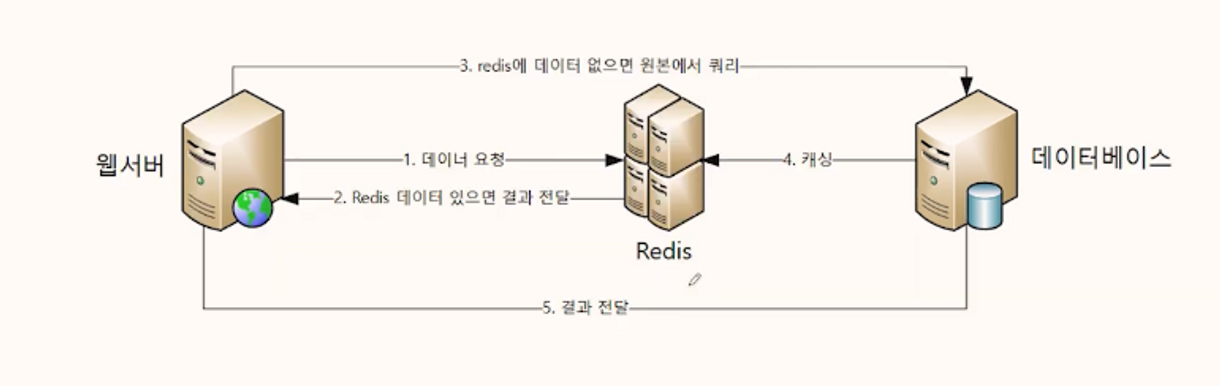
클라이언트 - 웹서버 - Redis - 데이터베이스
클라이언트에서 웹서버에 데이터 요청
- redis 데이터가 있으면
- 저장된 value 전달
- redis 데이터 없으면
- 데이터베이스에 쿼리를 날리고 Redis에 캐싱 후, 결과 전달
문제점
쿼리중 UPDATE.. 등은 해당사항이 없으며 조회성(SELECT)만 가능.
그리고, 데이터베이스에 있는 데이터가 바뀌게 되면 싱크가 안맞게 됨.(상품 가격 바뀐거 반영 못한다던가 등)
따라서, 주로 사용하지만 거의 바뀌지 않는 데이터(config, 결과값 등)
- 기본적으로 RAM의 용량이 작기 때문에 데이터를 모두 캐시에 저장해버리면 용량 부족. 효율적으로 사용할 필요가 있음 (얼마나 저장할지, 어떻게 캐시를 배치할지 등..)
1) 용량 등 효율적인 면에서

2) 성능 측면에서
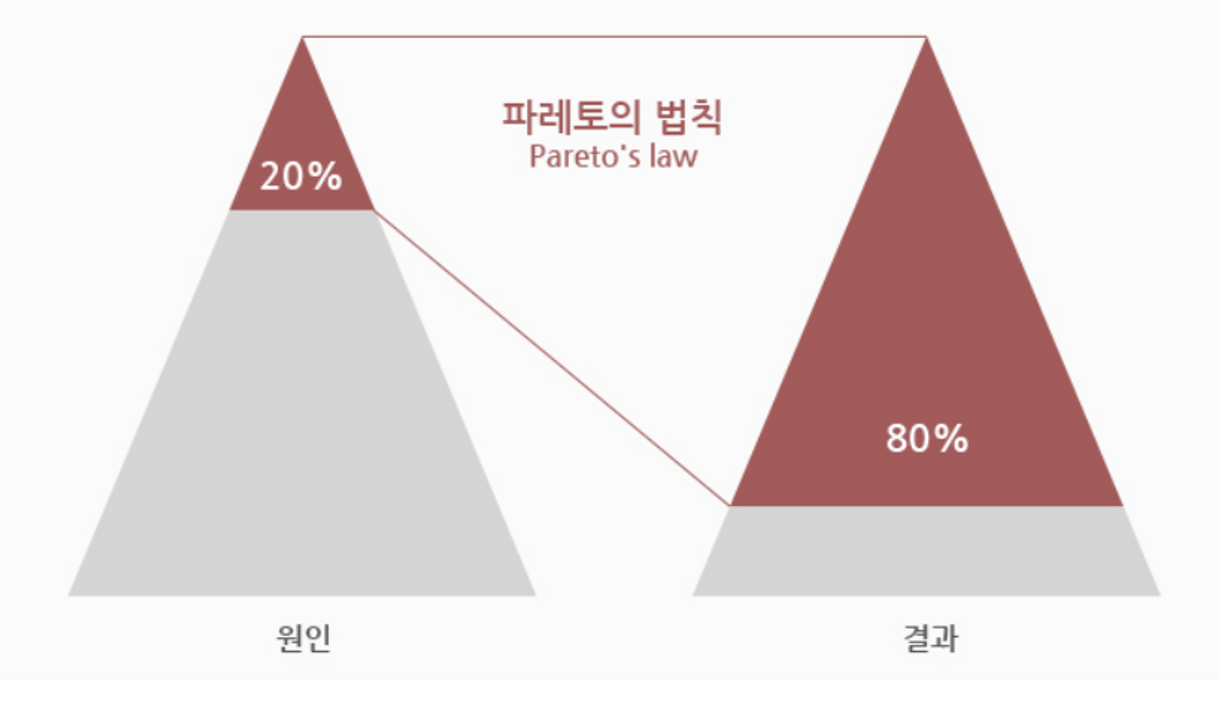
- 파레토 법칙
- 80퍼센트의 결과는 20퍼센트의 원인으로 인해 발생한다는 말.
- ex) 20퍼센트의 고객이 백화점 전체 매출의 80퍼센트의 결과를 일으킨다..
- 이를 DB 혹은 서버로 들고오면, 성능 문제를 일으키는 것은 20퍼센트의 자주 쓰이는 쿼리들
- 20퍼센트 캐싱을 통해 전체적으로 영향을 줄 수 있음.
캐싱 전략
읽기 - Read-Through패턴
캐시에서만 데이터를 읽어오는 전략
<단점>
단건 조회가 많을 경우 그래서 데이터를 조회하는데 있어 속도가 느림.
데이터 조회를 전적으로 캐시에만 의지해서 redis가 다운될 경우 서비스 이용에 차질이 생김.
<장점>
캐시와 DB간 동기화가 항상 이루어져 데이터 정합성 문제는 없음.
읽기가 많은 프로젝트에 적합
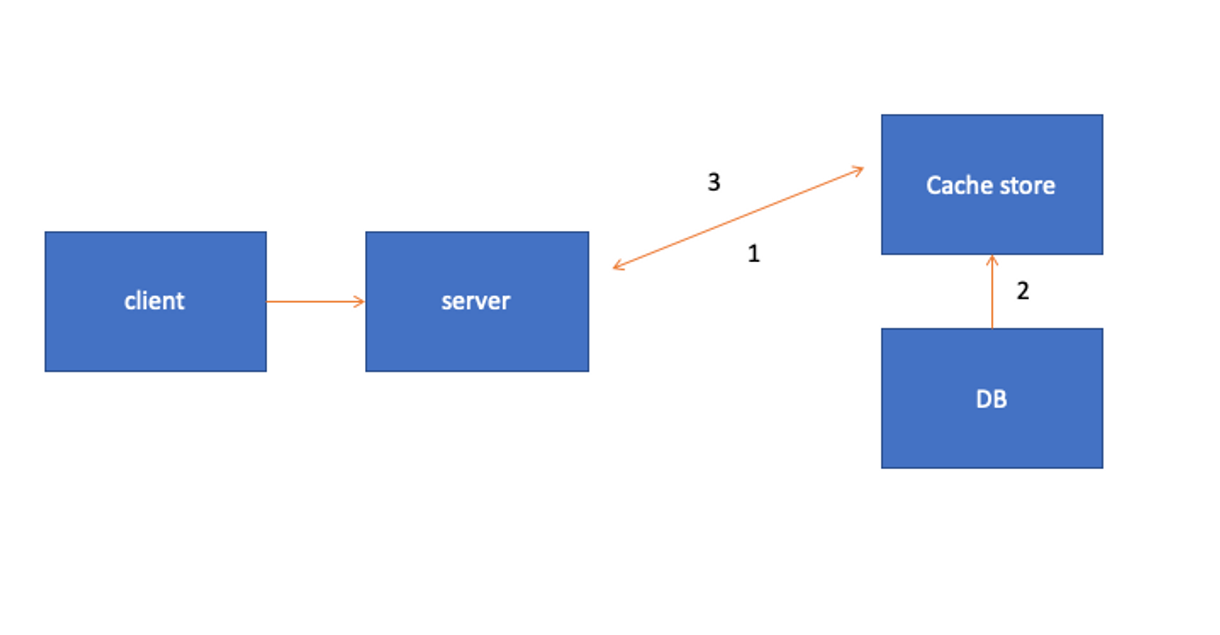
cache hit → cache store에 데이터가 있을 경우 바로 가져옴
cache miss → cache store에 데이터가 없을 경우 DB에서 가져옴
<순서>
클라이언트가 서버에 데이터 요청
- Cache Store에 검색하는 데이터가 있는지 확인 (cache hit)
- Cache Store에 없으면 캐시에서 DB에 데이터를 조회하여 자체 업데이트 (cache hit) (DB에서)
- Cache stor에서 데이터를 가져옴
이 방식은 직접적인 DB 접근과 읽기에 소모되는 자원을 최소화할 수 있음. 하지만 캐시에 문제가 생길 경우 서비스 전체가 중단 됨. 그렇기 때문에 Replication(복제) , Cluster(수평 확장, 백업 등)로 구성해야 됨.
읽기 - Look Aside 패턴
데이터를 찾을때 우선 캐시에 저장된 데이터가 있는지 우선적으로 확인. 만일 캐시에 데이터가 없으면 DB에서 조회하는 전략
<단점>
캐시에 커넥션이 많아져서 redis가 다운되면 DB로 몰려서 부하 발생
<장점>
캐시와 DB가 분리되어 원하는 데이터만 별도로 구성하여 캐시에 저장
캐시 장애 대비 구성이 되어 있음.
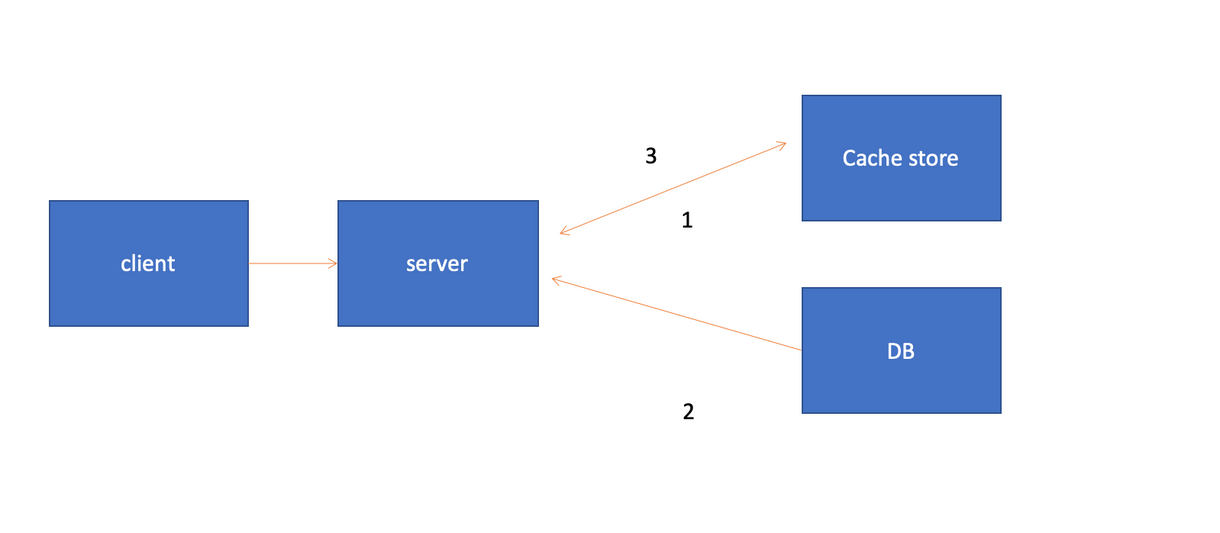
<순서>
클라이언트가 서버에 데이터 요청
- Cache Store에 검색하는 데이터가 있는지 확인 (cache hit)
- Cache Store에 없으면 DB에 데이터를 조회 (cache miss)
- DB에서 조회해온 데이터를 cache store에 업데이트 (서버에서)
이 방식은 캐시에 장애가 발생하더라도 DB에 요청을 전달하여 캐시 장애로 인한 서비스 문제는 대비할 수 있지만, 캐시와 DB간 정합성 유지 문제가 발생할 수 있음. 단건 호출 빈도가 높은 서비스에 적합하지 않음.
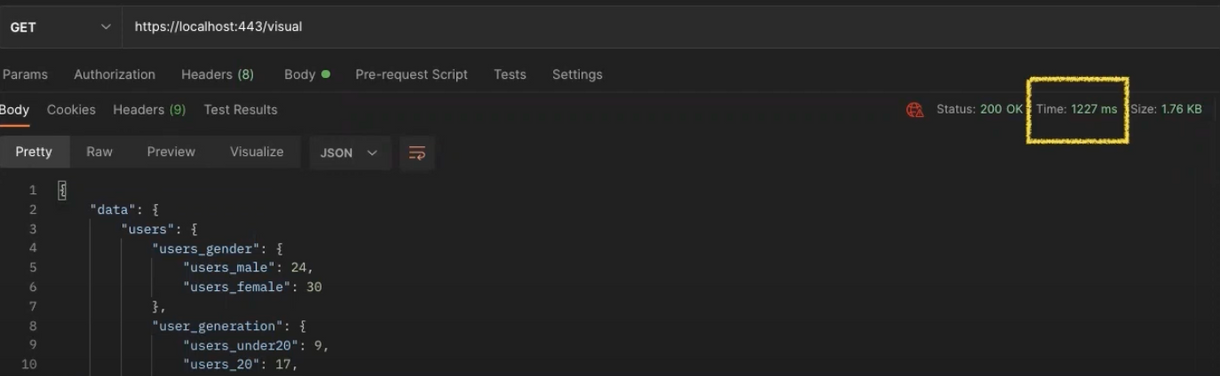
성능개선
<전>
<후>
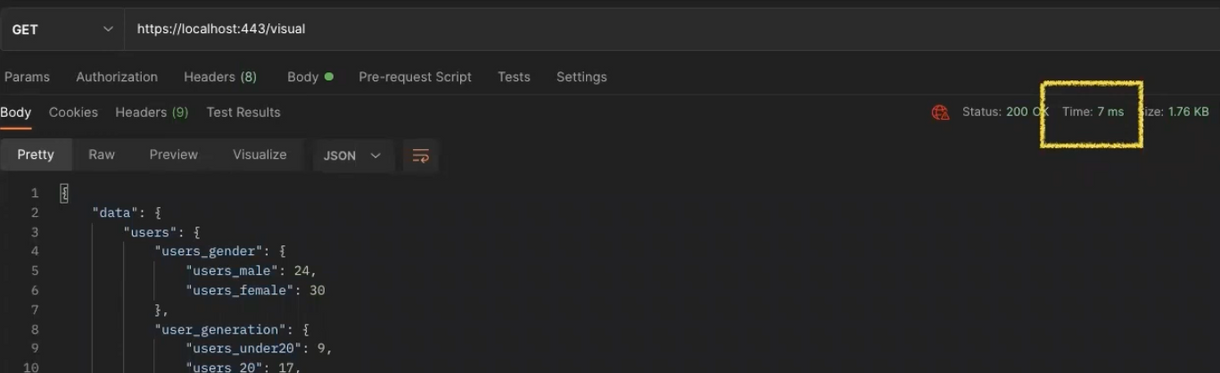
저번에 알아봤던 ETag같은 경우는 네트워크 통신간 Size가 줄어 들어 비용을 아끼고 성능을 개선하는 효과를 얻을 수 있었고, Redis를 통한 캐싱전략은 성능개선의 효과가 큰것을 알 수 있었음.
