앞으로 진행하는 내용은 pandas 라이브러리를 이용합니다.
Pandas
데이터 불러오기 실패
import requests
from bs4 import BeautifulSoup
def get_url(code):
url = 'http://finance.naver.com/item/sise_day.nhn?code={code}'.format(
code=code)
return url
def main():
code = '035720' # kakao
req = requests.get(get_url(code))
html = req.content.decode('euc-kr', 'replace')
bsObject = BeautifulSoup(html, "html.parser")
bsSelect = bsObject.select('td>span')
print(bsSelect)
return
if __name__ == '__main__':
main()위의 코드를 실행시켰더니..

아무것도 없다..
bsObject를 출력하도록 해봤더니
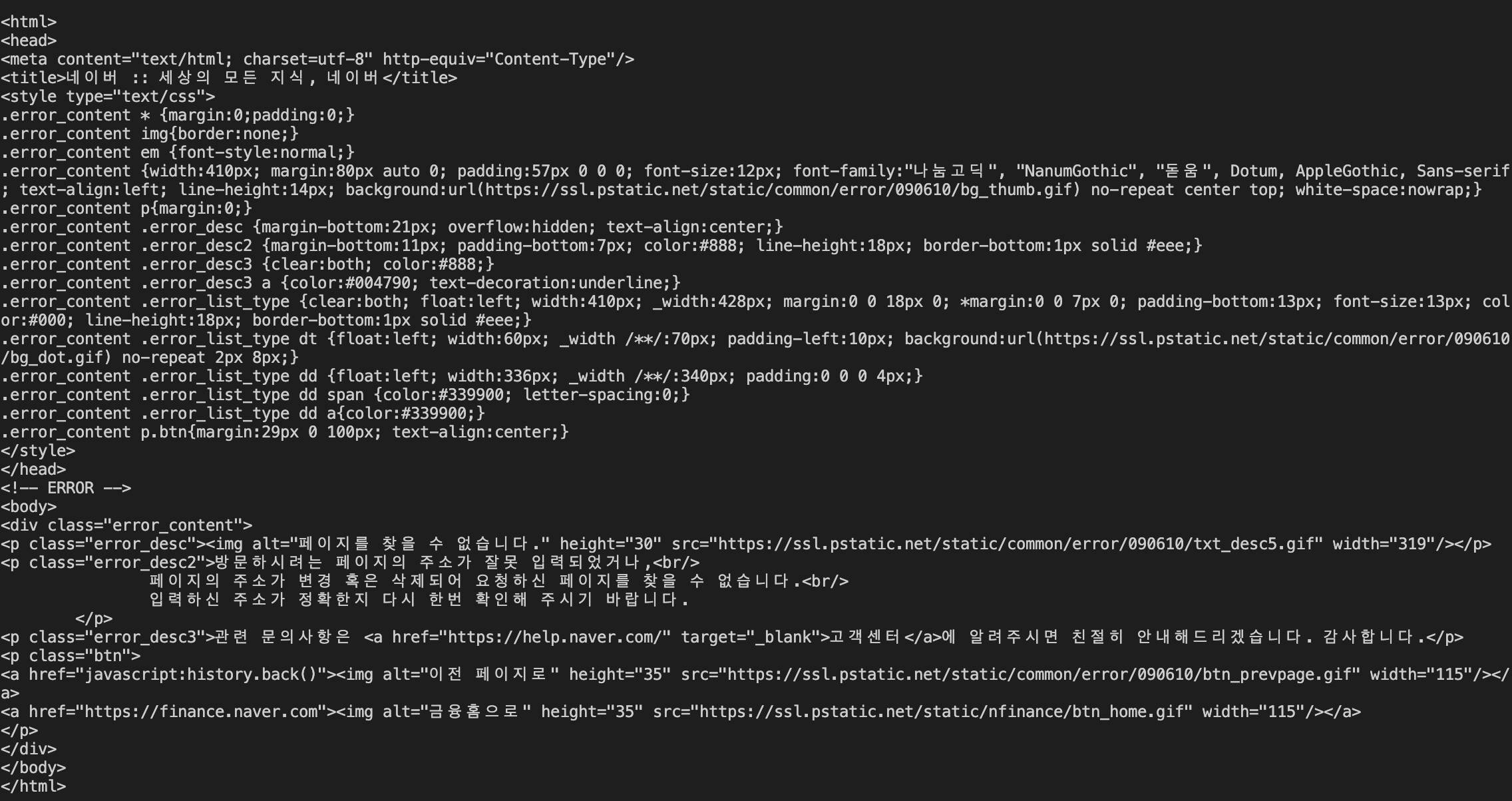
아무래도 크롤링을 할 수 없도록 되어있는 것 같다.
Selenium 셀레니움
pip install seleniumselenium 라이브러리를 설치합니다.
위의 링크에서 크롬 버전에 맞는 WebDriver를 설치합니다.
from selenium import webdriver원하는 데이터 불러오기
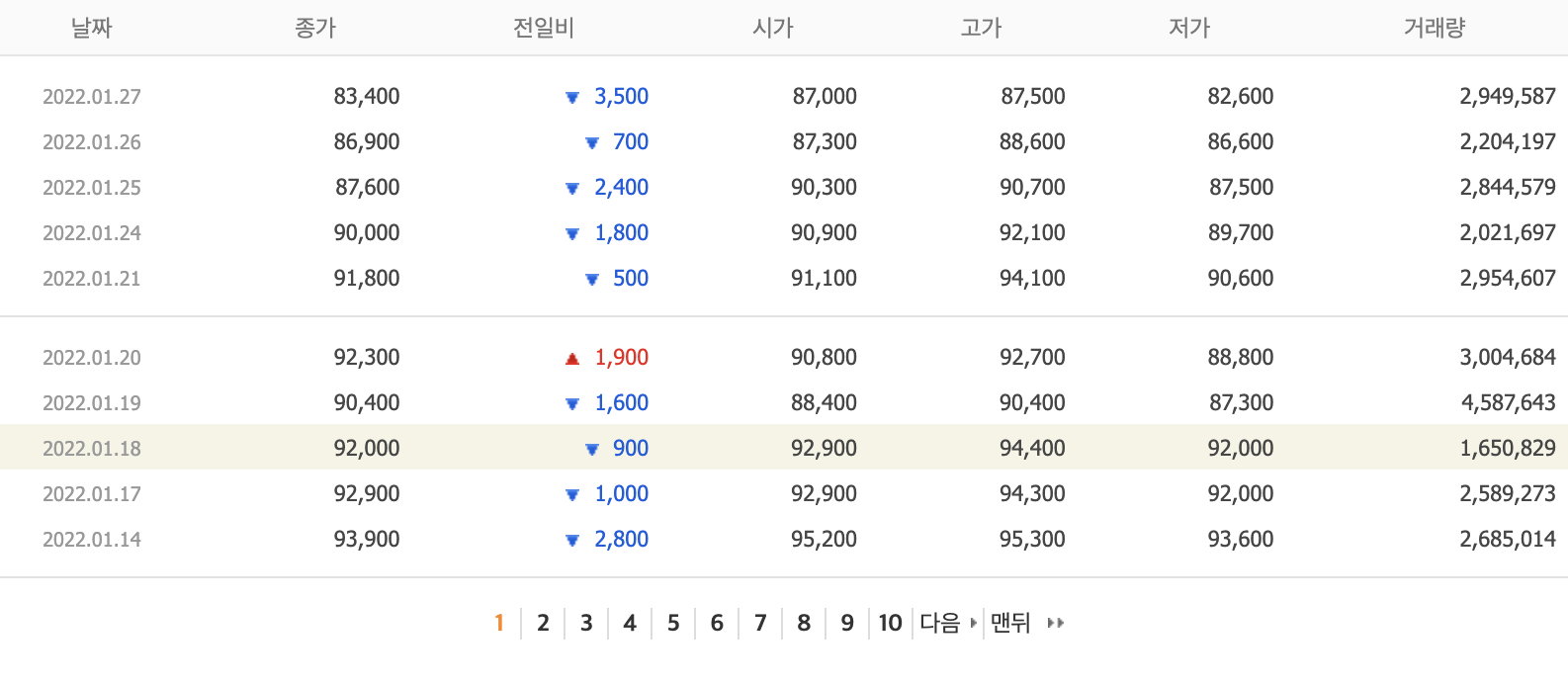
홈페이지 형식
우리가 불러오고자 하는 홈페이지는
'http://finance.naver.com/item/sise_day.nhn?code={code}&page={page}'
과 같은 형식을 가지고 있습니다.
get_url(code, page)
def get_url(code, page):
url = 'http://finance.naver.com/item/sise_day.nhn?code={code}&page={page}'.format(
code=code, page=page)
return urlBeautifulSoup 객체로 변환
driver.get(get_url(code, page))
bsObject = BeautifulSoup(driver.page_source, "html.parser")크롬 드라이버로 url에 접근하고 BeautifulSoup객체로 불러옵니다.
HTM형식 확인하기
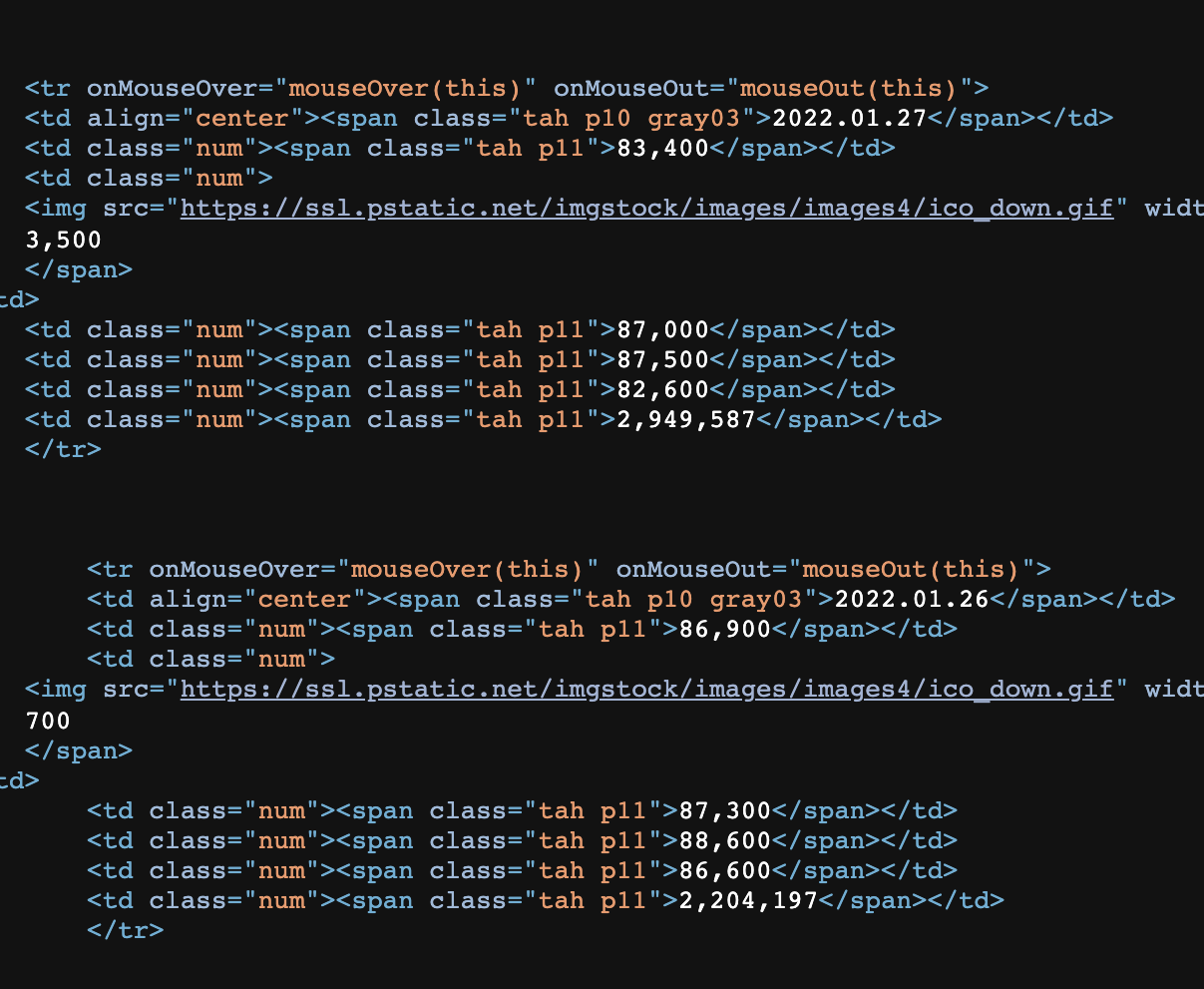
불러오고자 하는 데이터는 td tag 아래에 있는 span 태그에 있습니다.
bsSelect = bsObject.select('td>span')select함수를 이용해서 불러옵니다.
DataFrame 생성
from pandas import DataFrame, Seriespandas 라이브러리를 호출하고
data = DataFrame(columns=['날짜', '종가', '전일비', '시가', '고가', '저가', '거래량'])
for i in range(0, min(day, 10)):
a = []
for j in bsSelect[7*i:7*(i+1)]:
val = re.sub('\s', '', j.get_text()) # 공백 제거
a.append(val)
data = data.append([Series(a, index=data.columns)])
data = data.set_index("날짜")위와 같이 [날짜, 종가, 전일비, 시가, 고가, 저가, 거래량]을 한 세트로 묶어 DataFrame에 추가합니다.
파일(excel)로 출력
폴더 접근(생성)
if os.path.exists("./StockDataSet"):
output_dir = "./StockDataSet"
else:
os.mkdir("./StockDataSet")
output_dir = "./StockDataSet"같은 디렉토리에 StockDataSet이란 폴더가 존재하지 않으면 생성합니다.
파일 생성
filename = "{}_data_save.xlsx".format(code)
path = os.path.join(output_dir, filename)
data.to_excel(path, index=True)[code]_data_save란 이름을 가진 엑셀파일을 생성하고 DataFrame을 저장합니다.
소스코드
아래의 깃허브 링크로 코드를 볼 수 있습니다.
from selenium import webdriver
from bs4 import BeautifulSoup
import re
from pandas import DataFrame, Series
import os
def get_url(code, page):
url = 'http://finance.naver.com/item/sise_day.nhn?code={code}&page={page}'.format(
code=code, page=page)
return url
def data_save(code, data):
if os.path.exists("./StockDataSet"):
output_dir = "./StockDataSet"
else:
os.mkdir("./StockDataSet")
output_dir = "./StockDataSet"
filename = "{}_data_save.xlsx".format(code)
path = os.path.join(output_dir, filename)
data.to_excel(path, index=True)
return
def get_data(code, day, page):
if day <= 0:
return
driver = webdriver.Chrome('./chromedriver')
driver.get(get_url(code, page))
bsObject = BeautifulSoup(driver.page_source, "html.parser")
bsSelect = bsObject.select('td>span')
data = DataFrame(columns=['날짜', '종가', '전일비', '시가', '고가', '저가', '거래량'])
for i in range(0, min(day, 10)):
a = []
for j in bsSelect[7*i:7*(i+1)]:
val = re.sub('\s', '', j.get_text()) # 공백 제거
a.append(val)
data = data.append([Series(a, index=data.columns)])
data = data.set_index("날짜")
return data.append(get_data(code, day-10, page+1))
def main():
code = input('코드를 입력하세요: ')
day = int(input('최근 N 일의 data를 불러옵니다: '))
data = get_data(code, day, 1)
data_save(code, data)
return
if __name__ == '__main__':
main()