여러 DataFrame의 Join
- inner
- left outer join
- right outer join
- outer join
.png)
pd.merge의 구조
pd.merge(left, right, how, on, left_on, right_on, left_index, right_index)
- left : 왼쪽 DataFrame
- right : 오른쪽 DataFrame
- how : inner, left, right, outer
- on : 두 DataFrame을 Join할 기준 컬럼명(컬럼명이 동일할 경우)
- left_on : 왼쪽 DataFrame의 Join할 기준 컬럼
- right_on : 오른쪽 DataFrame의 Join할 기준 컬럼
- left_index : 왼쪽 DataFrame index로 Join할 경우 True
- right_index : 오른쪽 DataFrame index로 Join할 경우 True
on = "공통 Column"
data에는
짱구 철수 훈이
adddata에는
짱구 철수 유리
가 포함되어 있다.
how = "inner"
inner join을 할 경우, 공통되는 짱구, 철수만 출력이 된다.
data = DataFrame([["짱구", 180, 70], ["철수", 170, 65], [
"훈이", 160, 75]], columns=["이름", "키", "몸무게"])
adddata = DataFrame([["짱구", 80], ["철수", 100], ["유리", 100]], columns=["이름", "점수"])
print(pd.merge(left = data, right = adddata, how = "inner", on = "이름"))
how = "left"
left join을 할 경우, 왼쪽 DataFrame에 포함되는 짱구, 철수, 훈이가 출력된다.
data = DataFrame([["짱구", 180, 70], ["철수", 170, 65], [
"훈이", 160, 75]], columns=["이름", "키", "몸무게"])
adddata = DataFrame([["짱구", 80], ["철수", 100], ["유리", 100]], columns=["이름", "점수"])
print(pd.merge(left = data, right = adddata, how = "left", on = "이름"))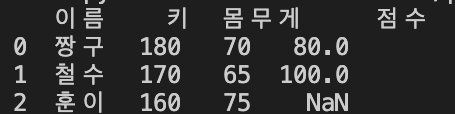
훈이의 경우 right DataFrame에 포함되지 않으므로, "점수" 값이 NaN으로 표시된다.
how = "outer"
outer join을 할 경우, left DataFrame과 Right DataFrame에 해당하는 모든 값을 불러온다.
data = DataFrame([["짱구", 180, 70], ["철수", 170, 65], [
"훈이", 160, 75]], columns=["이름", "키", "몸무게"])
adddata = DataFrame([["짱구", 80], ["철수", 100], ["유리", 100]], columns=["이름", "점수"])
print(pd.merge(left = data, right = adddata, how = "outer", on = "이름"))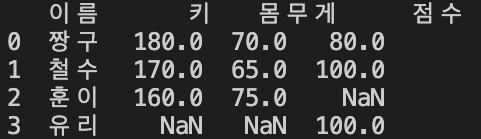
같은 index로 합치기
# "이름" 컬럼을 index로 설정
data = data.set_index("이름")
adddata = adddata.set_index("이름")
print(pd.merge(left=data, right=adddata,
left_index=True, right_index=True, how="inner"))