Model Train Job API 개발 - Kubernetes 환경
1. 배경
쿠버네티스가 컨테이너 오케스트레이션 도구로 각광을 받은 이유 중 AI 환경에서의 편의성이 높은 점도 있다고 생각합니다. ML Pipeline 환경을 쿠버네티스에서 운영했을 때 학습,관리,배포를 모두 운영 할 수 있습니다. 이러한 각각의 오픈소스(Notebooks, Katilb 등)를 조합해 플랫폼화 한것이 Kubeflow 입니다. 하지만 Kubeflow는 아직 많은 사례가 없고 사용이 어렵다는 단점이 있습니다(일반적인 AI 엔지니어 입장에서). 또한 Job을 관리하는 기능이 없기 때문에 이번에 Kubernetes를 통해 Job을 생성하는 API를 만드는 작업을 진행하였습니다. 현재 글에서 작성하는 Job은 AI pipeline에서 Model Training 부분에 속합니다. 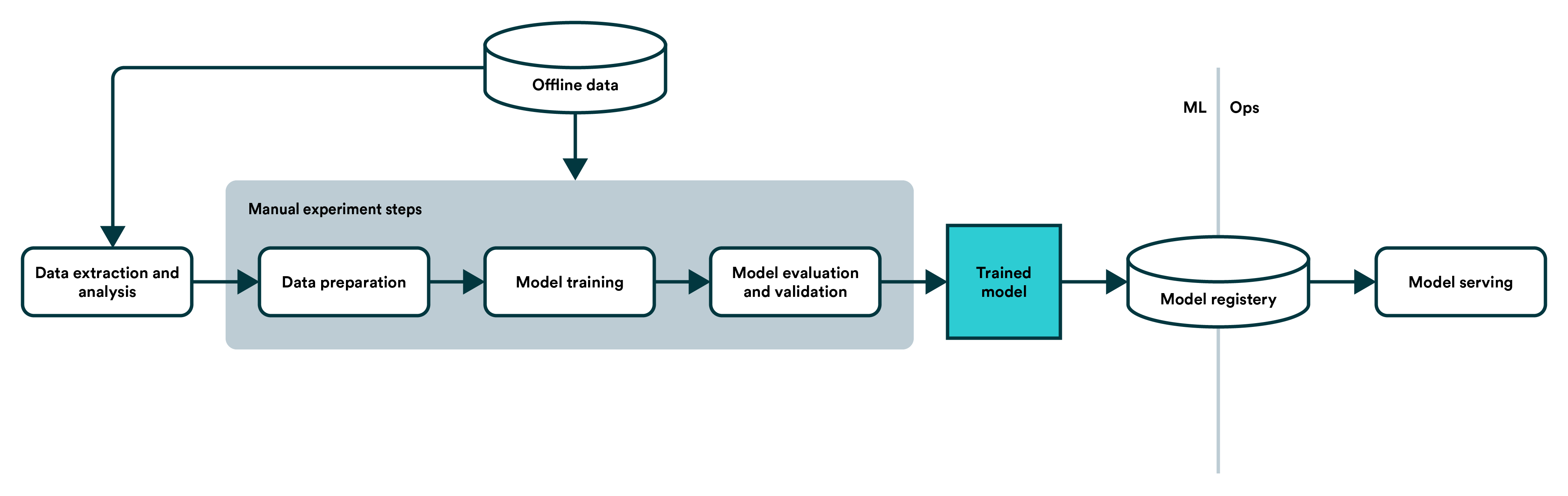
일반적으로 이러한 Model 학습을 하기 위해 노트북을 통해 코드를 실행하거나 도커 컨테이너를 이용해 학습 하는데 실행이 완료되기 까지 많은 시간이 필요합니다. 또한 GPU를 이용하여 학습하기 때문에 자원 관리 등의 스케줄링(대표적인 툴:Slurm)이 필요합니다. 그렇기 때문에 Job을 이용해 실행하여 학습이 완료되면 Output(Checkpoint, output, log 등) 만 저장하고 Resource를 반납하는 방법을 사용합니다.
하지만 AI 엔지니어 입장에서 Kubernetes 환경에서 Job을 수행하기 어렵기 때문에 API를 통해 쉽게 학습을 할 수 있도록 하는 것이 목표였습니다.
2. Architecutre
현재 쿠버네티스 클러스터는 다음과 같이 구성되어있습니다.(GPU 워커는 Nvida driver,nvidia docker 등 설치하기 귀찮아서 구성된 AMI을 사용하여 OS가 다름)
- Master 3대 : rhel7.9 (AWS t2:xlarge)
- Worker 2대 : rhel 7.9 (aws t2:xlarge)
- GPU Worker 2개: Ubuntu 18.04 (AWS p2 instance)
사용자는 API 서버를 통해 아래 그림과 쿠버네티스를 통해 Job을 배포합니다. 현재는 데모로 만들었기 때문에 설정이 부족한 부분도 있습니다. NFS에 HostPath를 생성하여 데이터를 저장하는 방법과 NodePort를 통해 Inference를 연결 하는 방법은 실제 운영에서는 좋지 않은 방법입니다.
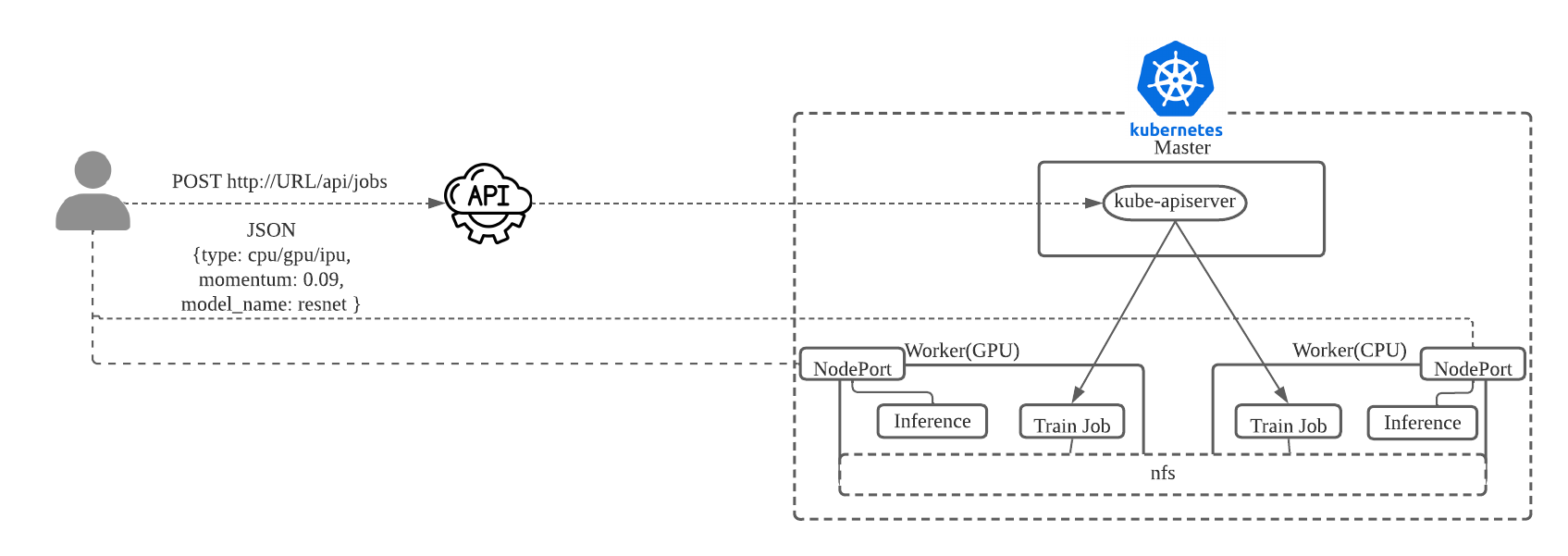
이러한 구조를 통해 사용자는 Model 명과 학습에 필요한 HyperParameter를 Json 형식으로 API Server에 전달합니다.
3.API Server 개발
API 개발은 Flask를 통해 개발하였고 Python kubernetes client 라이브러리를 사용해 개발하였습니다. 해당 API 를 사용하여 Job을 배포하기 위해서 사용자가 학습을 위한 코드를 이미지로 만들어야합니다. 또한 코드마다 Output과 파라미터 등이 다르기 떄문에 이에 대한 조율이 필요합니다. 학습 파일은 train.py 로 가정하고 Json으로 받은 파라미터를 추가해 학습시키는 커맨드를 생성합니다.
def post(self):
# API Json Parameter Parsing
now = datetime.now()
now = now.strftime("%Y%m%d_%H%M")
params = request.get_json()
name = params['model_name']
type = params['type']
hw_num = params['hw_num']
cmd_args = 'python train.py --checkpoint-path /worker/checkpoint --use-tensorboard --log-path logs/train.log'
#이미지명 생성
image = 'matilda/' + name + '-train-' + type + ':latest'
# HyperParameter 추가
for key in params.keys():
if key not in ('type','model_name'):
cmd_args = cmd_args + " --" + key + ' ' + params[key] 이후 Output file을 저장하기 위한 volume을 셋팅합니다.
# Volume Set
output_path = '/share/'+ USER_ID + '/'+ type+ '/' + name
cpt_volume = dict()
cpt_volume['name'] = 'checkpoint'
cpt_volume['hostPath'] = {'path': output_path + '/' +now + '/checkpoint'}
log_volume = dict()
log_volume['name'] = 'logs'
log_volume['hostPath'] = {'path': output_path + '/' + now + '/' +'logs'}이후 생성한 정보를 이용하여 yaml 파일을 생성합니다. cpu-job.yaml과 같이 일반적인 job yaml을 미리 생성한 후 템플릿을 불러와 생성한 데이터로 변경하는 방식입니다.
if type == 'gpu' or type == 'cpu':
if type =='gpu':
with open('./gpu-job.yaml') as f:
job_spec = yaml.full_load(f)
job_spec['spec']['template']['spec']['containers'][0]['resources'] = {'limits': {'nvidia.com/gpu' : hw_num}}
else:
with open('./cpu-job.yaml') as f:
job_spec = yaml.full_load(f)
job_spec['spec']['template']['spec']['containers'][0]['args'] = [cmd_args]
job_spec['spec']['template']['spec']['containers'][0]['image'] = image
job_spec['metadata']['name'] = name + '-' + 'training' + '-' + type + '-' + str(random.randrange(1,100))
job_spec['spec']['template']['spec']['volumes'].append(cpt_volume)
job_spec['spec']['template']['spec']['volumes'].append(tensorbaord_volume)
job_spec['spec']['template']['spec']['volumes'].append(log_volume)
v1 = client.BatchV1Api()
try:
print("Type : " + type + " Model : " +name + " job Creating....")
batch_job = v1.create_namespaced_job(namespace='default',body=job_spec)
return Response(status=200)
except ApiException as e:
print(e)
return Response(status=401)
pass 4. Job 생성하기
위의 코드를 바탕으로 실행한 API를 통해 Job을 생성해봅니다. postman을 이용해 API 주소로 다음과 같이 전송합니다.GPU를 사용하여 Resnet모델을 학습시킵니다. hw_num을 통해 GPU 갯수를 지정합니다.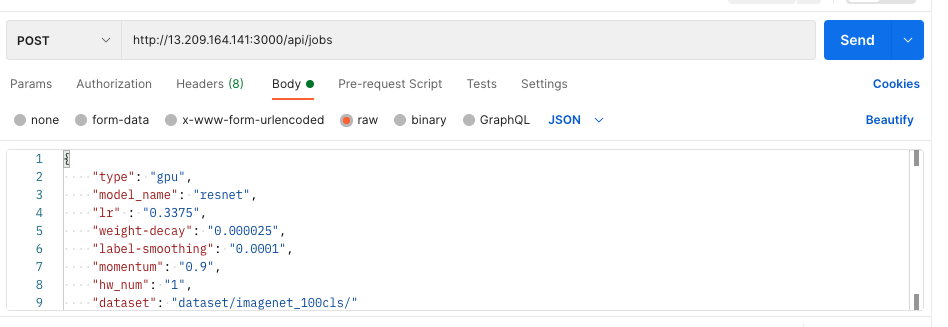
이후 확인하면 정상적으로 API로 request가 오고 JOb이 실행 되었습니다. 또한 생성된 GPU Worker에서 확인하면 GPU를 이용해 학습 하고 있는 것을 확인 할 수 있습니다.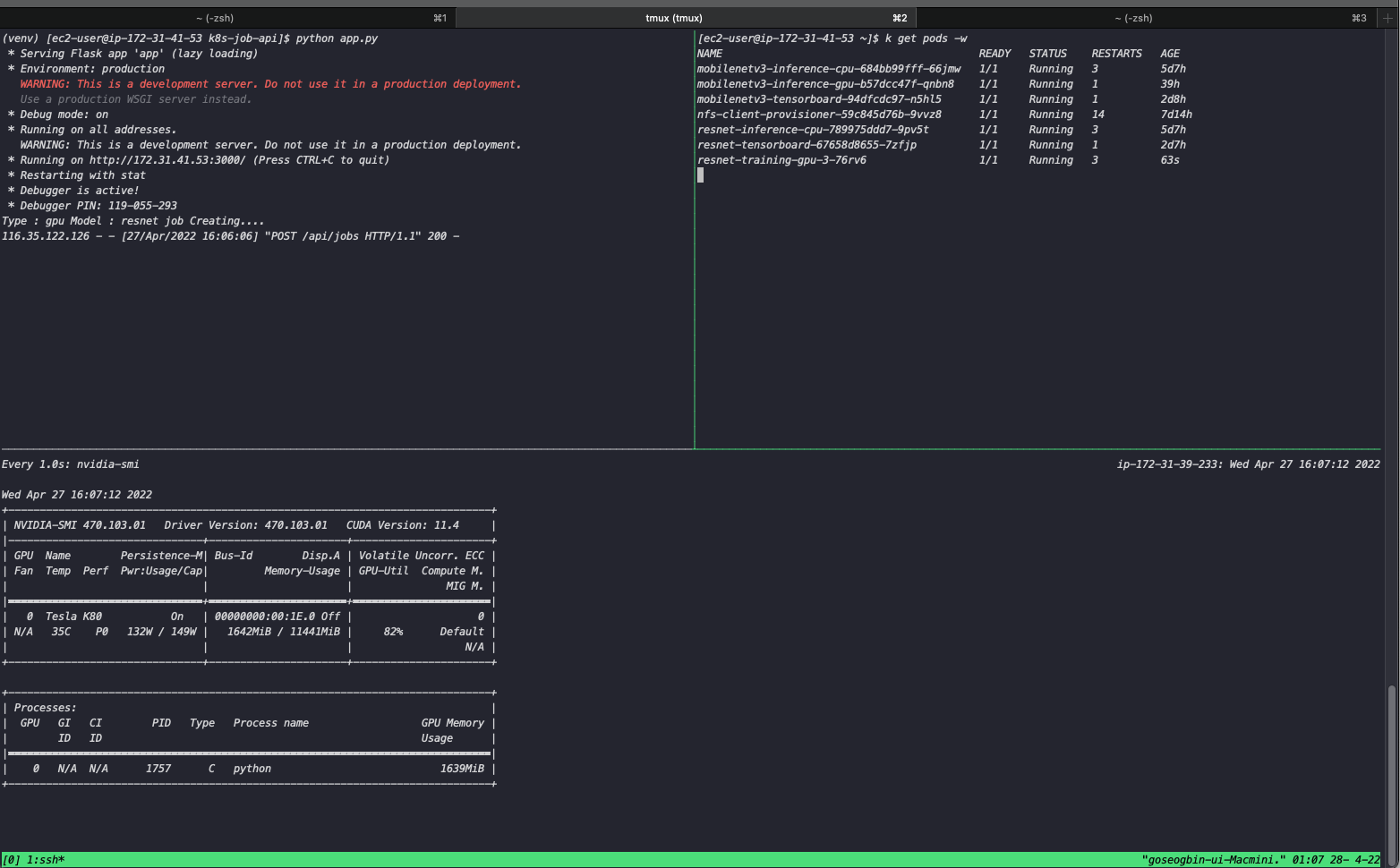
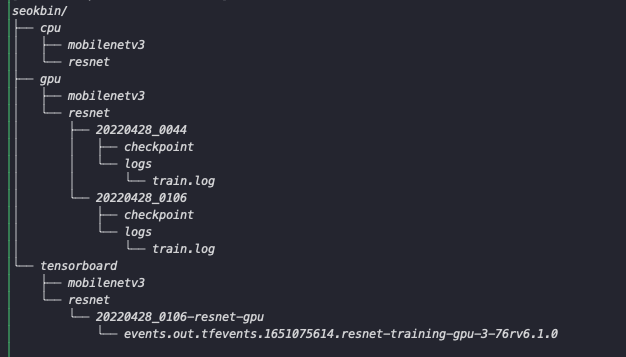
현재 output file의 구조는 다음과 같습니다. UserID를 통해 사용자를 식별한 후 학습한 Resource를 기준으로 나눕니다. 이후 Model 명으로 폴더를 생성해 datetime을 기준으로 Output을 저장합니다. tensorboard의 경우 logdir의 설정을 여러개를 지정할 수 없기 떄문에 Model 마다 텐서보드를 실행해 모델과 일치하는 폴더를 지정하도록 설정하였습니다.
위와 같이 Job을 생성하는 API 개발을 테스트하면서 가장 중요한 부분은 AI 엔지니어와의 조율입니다. Parameter 세팅, datset의 위치, image 명의 형식 등을 맞춰야됩니다. 향후 개발이 본격적으로 시작되고 고도화 되면 좋은 기능이 될 수 있을거 같습니다.
