
DDL
- SQL 구문은 DCL, DDL, DML로 구분.
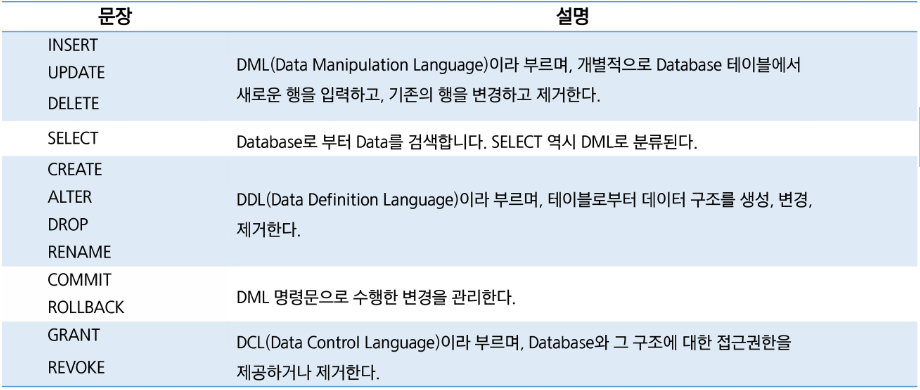
SQL 종류
- DDL (Data Definition Language) : 데이터 정의어.
- 데이터 베이스 객체(table, view, index, …)의 구조를 정의.
- 테이블 생성, 컬럼 추가, 타입변경, 제약조건 지정, 수정 등.

데이터 베이스
데이터 베이스 생성

- Character set은 각 문자가 컴퓨터에 저장될 때 어떠한 ‘코드’로 저장될지에 대한 규칙의 집합.
- show character set; : MySQL이 제공하는 character 값을 볼 수 있음.
- Collation은 특정 문자 셋에 의해 데이터베이스에 저장된 값들을 비교 검색하거나 정렬 등의 작업을 위해 문자들을 서로 ‘비교’할 때 사용하는 규칙의 집합.
- 다국어 처리(utf8mb3)

- 이모지 문자까지 처리

데이터베이스 변경
- alter database 데이터베이스명
default character set 값 collate 값;

데이터베이스 삭제
- drop database 데이터베이스명;

table 생성
table 생성

- optional attributes (제약 조건)
- NOT NULL : 각 행은 해당 열의 값을 포함해야 하며 null 값을 허용하지 않음.
- DEFAULT value : 값이 전달되지 않을 때 추가되는 기본값 설정.
- UNSIGNED : Type이 숫자인 경우만 해당되며 숫자가 0 또는 양수로 제한됨.
- AUTO INCREMENT : 새 레코드가 추가될 때마다 필드 값을 자동으로 1 증가시킴.
- PRIMARY KEY : 테이블에서 행을 고유하게 식별하기 위해 사용. PRIMARY KEY 설정이 있는 열은 일반적으로 ID번호이며 AUTO INCREMENT와 같이 사용되는 경우가 많음.
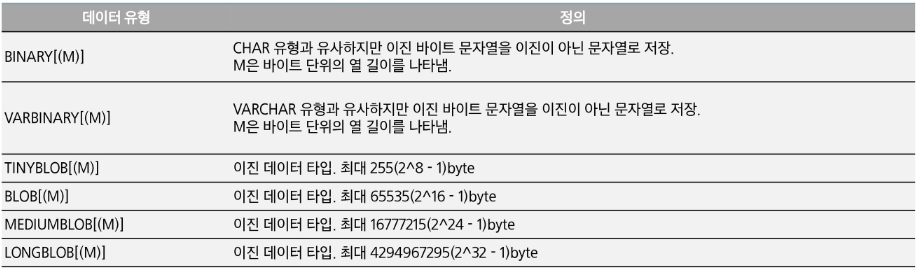
Data Type
- 문자형 데이터 타입
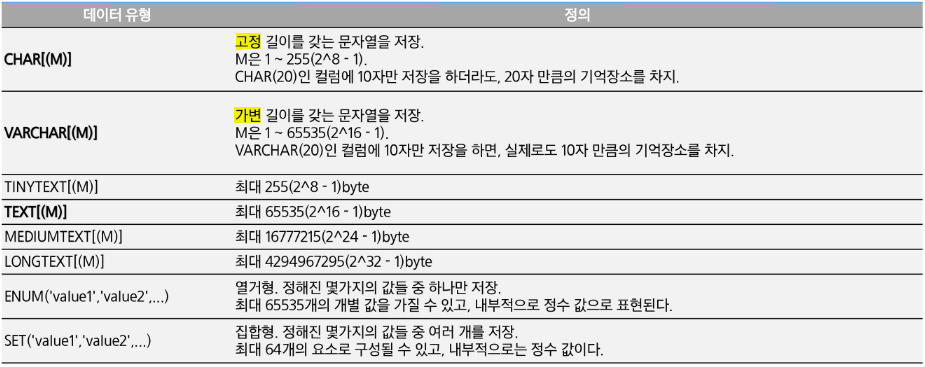
- varchar이 좀 더 효율적이지만 글자수가 고정적인 경우에는 char가 효율적.
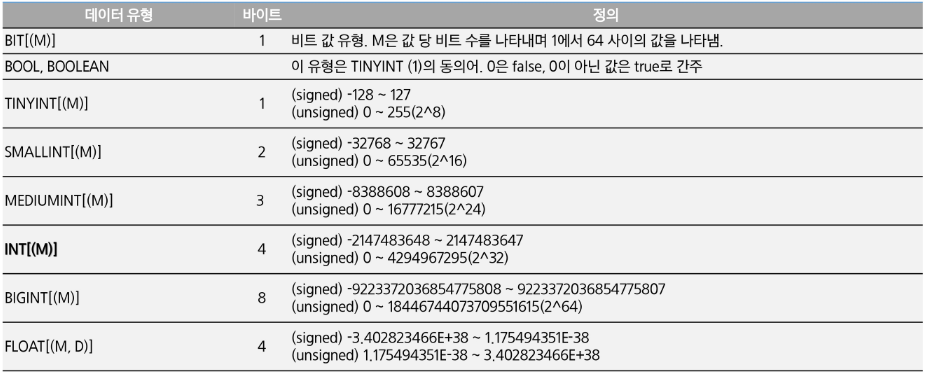
- 숫자형 데이터 타입

- 날짜형 데이터 타입
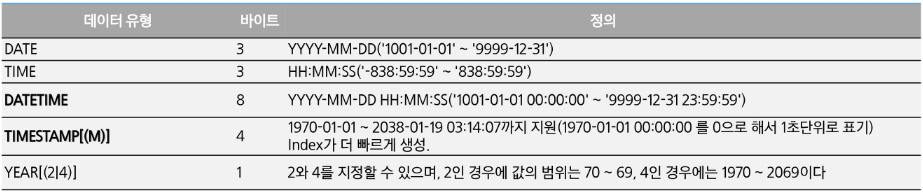 - DATETIME : 문자열
- TIMESTAMP : 숫자, 타임존이 같이 저장.(타임존을 바꾸면 다른 나라의 시간으로 바꿀 수 있음.)
- DATETIME : 문자열
- TIMESTAMP : 숫자, 타임존이 같이 저장.(타임존을 바꾸면 다른 나라의 시간으로 바꿀 수 있음.)
- 이진 데이터 타입
제약 조건
- 컬럼에 저장될 데이터의 조건을 설정하는 것.
- 제약 조건을 설정하면 조건에 위배되는 데이터는 저장 불가.
- 테이블 생성 시 컬럼에 직접 지정하거나 constraint로 지정, 또는 ALTER를 이용하여 설정 가능.

- UNIQUE : primary key와 비슷하지만 NULL값을 허용.
- FOREIGN KEY : NULL 가능.
table 생성 예시
CREATE TABLE db_member (
idx INT NOT NULL AUTO_INCREMENT,
userid VARCHAR(16) NOT NULL,
username VARCHAR(20),
userpwd VARCHAR(16),
emailid VARCHAR(20),
emaildomain VARCHAR(50),
joindate TIMESTAMP NOT NULL DEFAULT current_timestamp,
PRIMARY KEY (idx)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;- idx를 primary key로 사용하고 joindate는 입력하지 않을 경우, 기본값으로 현재 시간이 들어감.

Index
Index
-
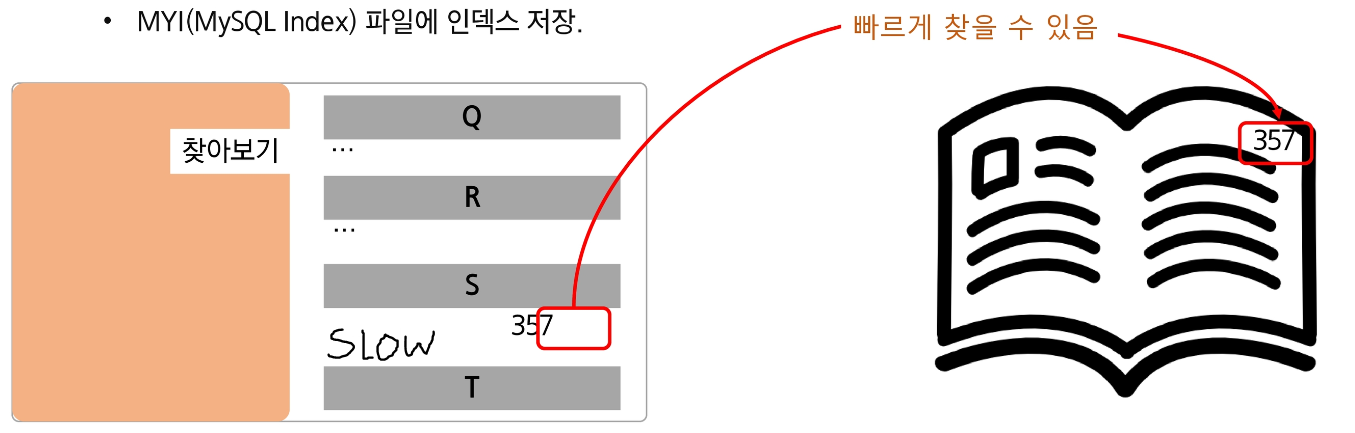
데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조.
-
원하는 내용을 바로 찾을 수 있도록 지원.
-
데이터의 위치를 빠르게 찾아주는 역할.
-
컬럼의 값과 레코드가 저장된 주소를 키와 값의 쌍으로 인덱스를 만들어 둠.
-
MYI 파일에 인덱스 저장.(물리적인 공간을 차지)
Index의 문제점
- 물리적인 추가 공간을 차지함.
- 필요 없는 index를 만들면 데이터베이스가 차지하는 공간만 늘어나고 index를 이용하여 데이터를 찾는 것이 전체 테이블을 찾는 것 보다 느려짐.
- 처음 index를 생성하는데 많은 시간이 소요.(데이터를 각각 보고 인덱스를 부여해야 하기 때문)
- 데이터의 변경 작업(insert, update, delete)이 자주 일어나는 경우 오히려 성능 저하. (인덱스 변경해줘야 하기 때문)
Index 종류
클러스터형 인덱스 (clustered index)
- 특정 나열된 데이터들을 일정 기준으로 정렬해 주는 인덱스.
- 데이터 자체가 정렬되어 저장.
- 클러스터형 인덱스 생성 시 데이터 페이지 전체가 다시 정렬. → 이미 대용량의 데이터가 입력된 상태라면 클러스터형 인덱스 생성 시 심각한 부하가 발생.
- 테이블당 하나면 생성 가능하고 어느 열에 클러스터형 인덱스를 생성하는지에 따라 시스템의 성능이 달라짐.
- 보조 인덱스보다 검색 속도는 빠르지만 입력/수정/삭제가 느림.
- PRIMARY KEY가 있다면 PK를 클러스터형 인덱스로, 없다면 UNIQUE하면서 NOT NULL인 컬럼을, 그것도 없으면 임의로 보이지 않는 컬럼을 만들어서 클러스터형 인덱스로 지정.
보조 인덱스 (secondary index)
- 개념적으로 후보키에만 부여 가능한 index.
- 후보키 : 주민 번호와 같이 각 데이터를 인식할 수 있는 최소한의 고유 식별 속성 집합)
- 보조 인덱스 생성 시 데이터 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 생성. (자동 정렬 되지 않음)
- 데이터가 위치하는 주소값(RID)
- 클러스형 인덱스보다 검색 속도는 느리지만 데이터 입력/수정/삭제의 성능 부하가 적음.
- 보조 인덱스는 테이블당 여러 개 생성 가능, 너무 많이 생성하면 성능 저하
Index 생성 전략
- 인덱스는 열 단위에 생성.
- where 절에서 사용되는 열에 생성.
- where 절에 사용되는 열이라도 자주 사용해야 가치가 있음.
- 데이터 중복도가 높은 열에는 인덱스를 만들어도 효과가 없음. (중복도가 낮은 열에 생성)
- 외래키를 설정한 열에는 자동으로 외래키 인덱스가 생성됨.
- 조인에 자주 사용되는 열에는 인덱스를 생성하는 것이 좋음.
- 데이터 변경(삽입, 수정, 삭제) 작업이 얼마나 자주 일어나는지를 고려해야 함.
- 클러스터형 인덱스는 테이블당 하나만 생성할 수 있음.
- 사용하지 않는 인덱스는 제거.
자동 생성 Index
자동으로 생성되는 Index
-
클러스터형 인덱스
- Primary Key를 설정하면 자동으로 해당 열에 클러스터형 인덱스가 생성.
- 기본적으로 오름차순 정렬.
create table test_tbl1 ( a int primary key, b int, c int ); -- test_tbl1의 index를 보여줌. show index from test_tbl1;

-
기본키와 unique 제약 조건 설정.
create table test_tbl2 ( a int primary key, b int unique, c int unique ); show index from test_tbl2;

- primary key는 클러스터형 인덱스가 되고 unique를 조건으로 걸어준 컬럼은 보조키가 됨.
-
기본키없이 unique 제약 조건만 설정.
create table test_tbl3 ( a int unique, b int unique, c int unique ); show index from test_tbl3;

- 클러스터형 인덱스는 생성되지 않고 모두 보조키가 됨.
-
unique이 제약 조건에 not null을 설정하고 기본키 설정.
create table test_tbl4 ( a int unique not null, b int unique, c int unique, d int primary key ); show index from test_tbl4;

Index 활용
Index 생성
create index key_name 값
on 테이블명(컬럼명[, 컬럼명, ...]);- create index 문으로 인덱스를 만들면 보조 인덱스가 생성.
- create index 문으로는 클러스터형 인덱스를 만들 수 없으며 클러스터형 인덱스를 만들려면 alter table을 사용해야 함.
- create index 문의 unique 옵션은 고유한 인덱스를 만들 때 사용.
- ASC, DESC로 정렬 방식 지정.
- index_type은 생략 가능하며 생략할 경우 기본 값인 B-Tree 형식 사용.
- unique하지 않은 컬럼으로 unique index를 만들 수 없음.
- 여러 열을 조합하여 인덱스 생성 가능.
인덱스를 통한 select
- Full Table Scan : 테이블의 모든 행을 찾아봄. (인덱스를 지정하지 않은 컬럼을 조건으로 select할 경우)
- Single Row : 클러스터형 인덱스를 통한 select를 할 경우 하나의 행을 바로 가져옴.
- Non-Unique Key Lookup : 보조 인덱스를 통해 select를 할 경우.
Index 삭제
drop index 인덱스이름 on 테이블 이름;- 인덱스를 모두 삭제할 때는 보조 인덱스부터 삭제.
- 인덱스를 많이 생성 해 놓은 테이블의 경우, 각 인덱스의 용도를 확인한 후 활용도가 떨어지는 인덱스를 삭제.
alter index 테이블 이름 drop primary key;- 자동으로 생성된 클러스터형 인덱스 삭제.
View
- 데이터베이스에 존재하는 ‘가상의 테이블’.
- 실제 행과 열을 가지고 있지만 데이터를 저장하고 있지는 않음.
- join이나 subquery와 같이 여러 개의 테이블을 참조하여 데이터를 조회할 때 번거로움을 줄일 수 있음.
- 단, MySQL에서 View는 단지 다른 테이블이나 View에 있는 데이터를 보여주는 역할만 수행.
- View와 Table의 차이점은 Table은 실질적인 데이터가 있지만 View는 데이터가 없고 SQL만 저장.
View 장점
- 특정 사용자에게 테이블 전체가 아닌 필요한 필드만 보여줄 수 있음.(보안성) → DBMS의 사용자별 권한 관리 기능을 통해 사용자가 테이블에 직접적인 접근을 하지 못하도록 막을 수 있음.
- 복잡한 쿼리를 단순화해서 사용 가능.
- 쿼리 재사용.
- 여러 방법의 데이터 조회에 알맞은 다양한 구조의 데이터 분석 기반을 구축 할 수 있음. → 기존 테이블 구조를 변경하지 않음.
View 단점
- 삽입, 삭제, 갱신 작업에 많은 제한 사항을 가짐.
- View는 자신만의 인덱스를 가질 수 없음.
View에서의 데이터 변경
- View를 생성한 기존 테이블의 데이터를 업데이트하면 View도 업데이트.
- View를 조회하게 되면 옵티마이저에서 View를 생성할 때 저장해 놓은 Select문이 실행되는 것이기 때문에 View의 데이터도 업데이트 된 것 처럼 보임.
View의 종류
단순 뷰 (Simple View)
- 하나의 테이블로 생성.
- 그룹 함수의 사용이 불가능.
- distinct 사용 불가능.
- DML 사용 가능.
- 단순 뷰에서 DML 명령어 사용이 불가능한 경우.
- View 정의 시 포함되지 않은 컬럼 중 not null 제약 조건이 지정되어 있는 경우.
- 산술 표현식을 포함한 컬럼이 포함되어 있는 경우.
- distinct를 포함한 경우.
- 그룹 함수나 group by 절을 포함한 경우.
- 단순 뷰에서 DML 명령어 사용이 불가능한 경우.
복합 뷰 (Complex View)
- 여러 개의 테이블로 생성.(JOIN)
- 그룹 함수의 사용이 가능.
- distinct 사용 가능.
- DML 사용 불가능.
인라인 뷰 (Inline View)
- 일반적으로 가장 많이 사용.
- from 절 안에 SQL 문장이 들어가는 것을 인라인 뷰라 볼 수 있음.
View의 생성
create view 뷰이름
as
select 필드 이름1, 필드 이름2, ...
from 테이블 이름
where 조건;- create 문 사용.
- select 문에서 선택된 필드를 이용하여 새로운 View 생성.
- View는 원본 테이블의 이름과 같은 이름은 사용할 수 없음.
View의 대체
create or replace view 뷰이름
as
select 필드 이름1, 필드 이름2, ...
from 테이블 이름
where 조건;- 설정한 필드를 대체하기 위해 새로운 View로 대체
- 뷰이름에 해당하는 View가 있다면 대체하고 없다면 생성.
View의 수정
alter view 뷰이름
as
select 필드 이름1, 필드 이름2, ...
from 테이블 이름;View의 삭제
drop view 뷰이름
안녕하세요 :)