앞서 1-1에서 하나의 라우터에서의 지연 시간을 확인했다.
이번 글에서는 좀 더 트래픽이 몰리는 복잡한 상황에서 처리 과정을 알아보자
큐잉 지연
앞서 살펴본 4가지 지연 중 큐잉 지연을 다시 살펴보자.
앞서 깔대기의 넓은 부분을 라우터 큐로, 담긴 각각의 색의 물을 패킷으로 비유했다.
해당 그림에서 각각의 패킷들의 큐잉 지연은 서로 다르다.
가장 먼저 라우터에 도착한 노랑 패킷은 큐잉 지연없이 처리를 시작할 것이다.
하지만 가장 늦게 도착한 빨강 패킷은 앞에 있는 모든 패킷들이 처리될 때까지 기다릴 것이다.
트래픽 강도
큐잉 지연 시간은 트래픽 강도에 따라 결정된다.
패킷이 큐에 평균 a개 도착한다고 가정해보자.
모든 패킷의 크기는 (편의상) L비트이고, 전송률은 Rbps이다.
그러면 트래픽 강도는 La/R이 된다.
상황 1. 평균 5개 패킷 도착, 패킷 크기 100비트, 1000bps 전송률
트래픽 강도 :5 * 100 / 1000 = 0.5
상황 2. 평균 10개 패킷 도착, 패킷 크기 100비트, 1000bps 전송률
트래픽 강도 :10 * 100 / 1000 = 1
상황 3. 평균 11개 패킷 도착, 패킷 크기 100비트, 1000bps 전송률
트래픽 강도 :11 * 100 / 1000 = 1.1
여기서 큐는 얼마나 많은 패킷이 들어와도 모든 패킷을 받는 무한대의 큐라고 가정하자.
상황 1에서는 트래픽 강도가 0.5로 평균적으로 도착하는 패킷을 지연없이 처리할 수 있다.
상황 2에서도 트래픽 강도가 1로 평균적으로 도착하는 패킷을 간신히 지연없이 처리할 수 있다.
상황 3은 좀 문제가 생긴다. 10개의 패킷까지는 바로바로 처리될 수 있지만 1개의 패킷이 점점 쌓이며 큐잉 지연이 커지기 시작한다.
따라서 트래픽 공학의 주요 규칙 중 하나는 트래픽 강도가 1보다 크지 않게 시스템을 설계하라는 것이다.
너무 이론적이다.
트래픽이 몰리는 상황은 고정된 패턴이 없고 랜덤하다.
트래픽은 랜덤하게 몰릴 것이고 랜덤하게 널널할 것이다.
앞서 살펴본 상황은 너무 이론적인 상황이다.
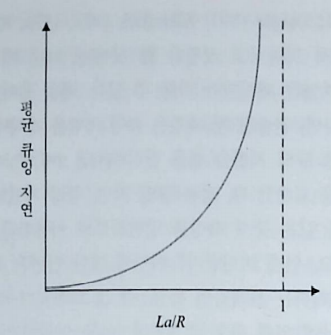
트래픽 강도 <= 1일 때 패킷이 주기적으로 도착한다면 큐잉 지연은 없다.
하지만 패킷이 몰려서(버스트) 도착한다면 상당한 큐잉 지연이 생기게 된다.
중요한 사실은 트래픽 강도가 1에 접근할수록 평균 큐잉 지연이 급속히 증가한다는 사실이다.
패킷 손실
앞서 트래픽 강도에서는 무한대의 큐를 가정했지만
현실에서 큐의 용량은 스위치 설계와 비용에 크게 의존하며 유한하다.

깔대기의 크기는 다음 그림과 같이 유한하다.
패킷 손실도 이 예시와 같다.
패킷이 라우터에 도착했는데 큐에서는 더 이상 패킷을 받을 수 없는 상황이다.
이 경우 라우터는 그 패킷을 버린다(drop).(= 잃어버린다(lost))
패킷 손실의 8~90%는 여기서 발생한다
버린 패킷은 어떻게?
버린 패킷은 종단 간에 재전송될 수 있다.
자세한 내용은 3장에서 배울 것이다.
트랜스포트 계층의 신뢰적인 데이터 전송을 보장하는 TCP를 사용하면 재전송 될 수 있다.
패킷은 여러 라우터를 거친다.
지금까지 글에서는 각 노드의 지연, 즉 한 라우터에서의 지연을 살펴봤다.
하지만 패킷이 전송될 때는 여러 라우터를 거치게 된다.
혼잡하지 않은 네트워크에서(= 큐잉 지연을 무시할 수 있다)
송수신자(호스트) 사이에 N-1개의 라우터가 있다면 다음과 같은 식을 세울 수 있다.
종단 간 지연 = N(처리지연 + 전송지연 + 전파지연)
참고 및 출처
책 - 컴퓨터 네트워킹 하향식 접근
컴퓨터네트워크 - 한양대학교 | KOCW 공개 강의
gif 출처 : https://domos.ai/latency-explained