
도커 컨테이너 환경에서의 Multi Node 학습
도커 컨테이너 환경에서 Pytorch 기반 Multi Node 학습 코드는 다음과 같다.
import torch
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
import os
import random
import numpy as np
def accuracy(model, device, test_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
return accuracy
def parse():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--local_rank", type=int,
help="Local rank. Necessary for using the torch.distributed.launch utility.")
parser.add_argument("--num_epochs", type=int,
help="Number of training epochs.", default=100)
parser.add_argument("--batch_size", type=int,
help="Training batch size for one process.", default=64)
parser.add_argument("--learning_rate", type=float,
help="Learning rate.", default=1e-2)
parser.add_argument("--random_seed", type=int,
help="Random seed.", default=0)
parser.add_argument("--model_dir", type=str,
help="Directory for saving models.", default="../saved_models")
parser.add_argument("--model_filename", type=str,
help="Model filename.", default="resnet_distributed.pth")
return parser.parse_args()
def set_random_seeds(random_seed=0):
torch.manual_seed(random_seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(random_seed)
random.seed(random_seed)
def set_device(local_rank=None):
"""The operation for set torch device.
Args:
local_rank (int): The local rank. Defaults to None.
Returns:
torch.device: The torch device.
"""
device = None
if torch.cuda.is_available():
if local_rank is not None:
device = torch.device('cuda:{}'.format(local_rank))
else:
device = torch.device('cuda')
elif torch.backends.mps.is_available():
device = torch.device('mps')
else:
device = torch.device('cpu')
return device
def set_model(model, device, distributed=False):
"""The operation for set model's distribution mode.
Args:
model (nn.Module): The model.
device (torch.device): The torch device.
distributed (bool, optional): The option for distributed. Defaults to False.
Raises:
ValueError: If distributed gpu option is true, the gpu device should cuda.
Returns:
nn.Module: The model.
"""
is_cuda = torch.cuda.is_available()
if distributed:
if is_cuda:
model.to(device)
model = nn.parallel.DistributedDataParallel(model,device_ids=[device],output_device=[device])
else:
raise ValueError(
'If in cpu or mps mode, distributed option should be False.')
else:
model = model.to(device)
if is_cuda and torch.cuda.device_count()>1:
model = nn.parallel.DataParallel(model)
return model
def main():
# Each process runs on 1 GPU device specified by the local_rank argument.
argv = parse()
# get model path
model_filepath = os.path.join(argv.model_dir, argv.model_filename)
# We need to use seeds to make sure that the models initialized in different processes are the same
set_random_seeds(random_seed=argv.random_seed)
# Initializes the distributed backend which will take care of sychronizing nodes/GPUs
distributed = False
if 'WORLD_SIZE' in os.environ and int(os.environ['WORLD_SIZE']) > 1:
distributed = True
print('This is {} rank of {} process'.format(
os.environ['RANK'], os.environ['WORLD_SIZE']))
if distributed:
torch.distributed.init_process_group(backend="nccl", init_method='env://', rank=int(
os.environ['RANK']), world_size=int(os.environ['WORLD_SIZE']))
device = set_device(argv.local_rank if distributed else None)
model = torchvision.models.resnet18(pretrained=False)
model = set_model(model,device,distributed=distributed)
# Prepare dataset and dataloader
transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)),
])
# Data should be prefetched
# Download should be set to be False, because it is not multiprocess safe
train_set = torchvision.datasets.CIFAR10(
root="../data", train=True, download=False, transform=transform)
test_set = torchvision.datasets.CIFAR10(
root="../data", train=False, download=False, transform=transform)
# Restricts data loading to a subset of the dataset exclusive to the current process
train_sampler = None
if distributed:
train_sampler = DistributedSampler(dataset=train_set)
train_loader = DataLoader(
dataset=train_set, batch_size=argv.batch_size, sampler=train_sampler, num_workers=8)
# Test loader does not have to follow distributed sampling strategy
test_loader = DataLoader(
dataset=test_set, batch_size=argv.batch_size, shuffle=False, num_workers=8)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),
lr=argv.learning_rate, momentum=0.9, weight_decay=1e-5)
# Loop over the dataset multiple times
for epoch in range(argv.num_epochs):
print("Local Rank: {}, Epoch: {}, Training ...".format(
argv.local_rank, epoch))
# Save and evaluate model routinely
if epoch % 10 == 0:
if argv.local_rank == 0:
acc = accuracy(
model=model, device=device, test_loader=test_loader)
torch.save(model.state_dict(), model_filepath)
print("-" * 75)
print("Epoch: {}, Accuracy: {}".format(epoch, acc))
print("-" * 75)
model.train()
early_stop = 10
for idx, data in enumerate(train_loader):
if idx == early_stop:
break
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if __name__ == "__main__":
main()실행 코드
Master Node
export NCCL_SOCKET_IFNAME=enp5s0 #NCCL_SOCKET of master node host
export NCCL_DEBUG=INFO #DEBUG
NNODES=2 #Number of total node
NODE_RANK=0 #Rank of total node
NPROC_PER_NODE=2 #Process number of this node
MASTER_ADDR='127.0.0.1'
MASTER_PORT='12345'
python -m torch.distributed.launch --nnodes=${NNODES} --node_rank=${NODE_RANK} --nproc_per_node=${NPROC_PER_NODE} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} ../distributed_train.pyWorker Node
export NCCL_SOCKET_IFNAME=enp5s0 #NCCL_SOCKET of worker node host
export NCCL_DEBUG=INFO #DEBUG
NNODES=2 #Number of total node
NODE_RANK=1 #Rank of total node
NPROC_PER_NODE=2 #Process number of this node
MASTER_ADDR='192.168.0.76' #Master IP ADDR
MASTER_PORT='12345' #MASTER PORT
python -m torch.distributed.launch --nnodes=${NNODES} --node_rank=${NODE_RANK} --nproc_per_node=${NPROC_PER_NODE} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} ../distributed_train.py실행 결과
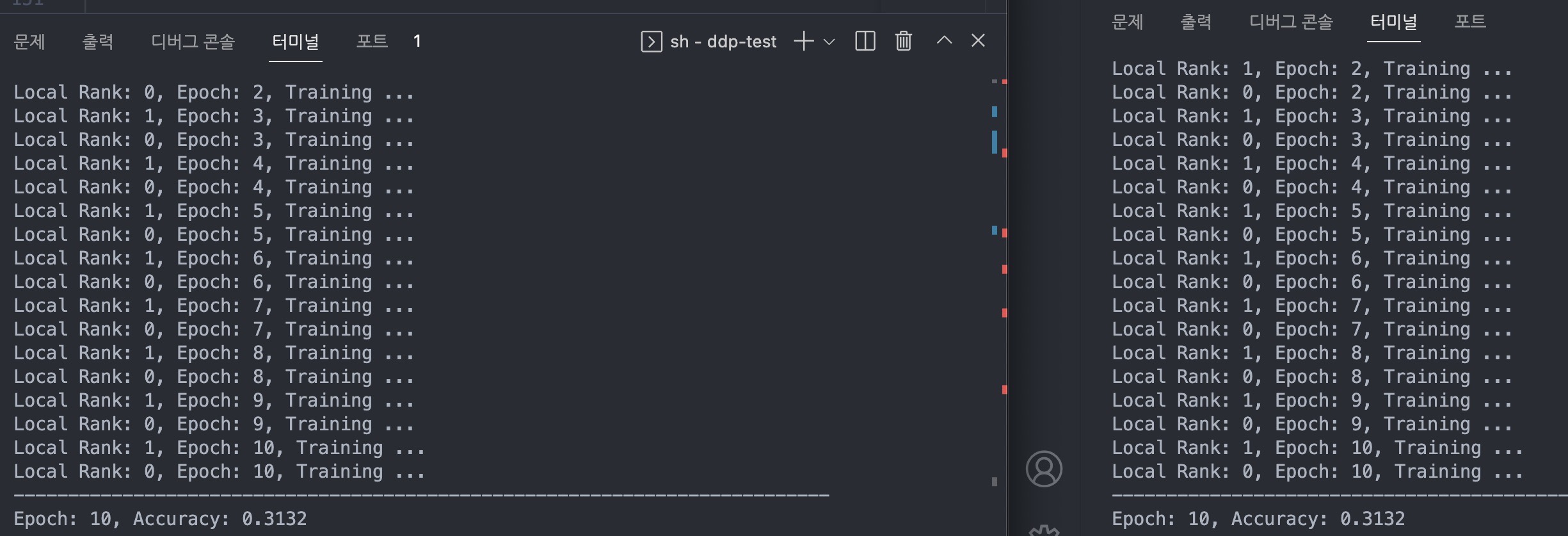

Vision AI Engineer