
도커 컨테이너 생성
마스터 노드인 도커 컨테이너 환경에서 워커 노드에서 실행되는 컨테이너와 통신하기 위해서는 기본으로 생성되는 '172.x.x.x'와 같은 가상 IP가 아닌 실제 IP를 사용해야 한다.
이를 위해 다음과 같이 --network host 옵션을 도커 컨테이너 생성 시에 추가한다
$ docker run --gpus all --network host --ipc host [-it] [--name NAME] [--shm-size SHARED_MEMORY_SIZE] [-v HOST_PATH:DOCKER_PATH] image_name /bin/bash
Pytorch 기반 Multi Process 통신
기존 Pytorch는 torch.distributed.launch를 통해 multi process 환경으로 script를 실행할 수 있도록 도와준다. 참고로 최근에는 torchrun으로 변경되었다.
그리고 Multi Process간 통신을 위해 torch.distributed.init_process_group을 지원한다. 이를 이용한 분산 처리 확인 코드는 다음과 같다.
import os
import argparse
import torch
import torch.nn as nn
import torch.distributed as dist
import torchvision
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int)
args = parser.parse_args()
return args
def set_device(local_rank=None):
"""The operation for set torch device.
Args:
local_rank (int): The local rank. Defaults to None.
Returns:
torch.device: The torch device.
"""
device = None
if torch.cuda.is_available():
if local_rank is not None:
device = torch.device('cuda:{}'.format(local_rank))
else:
device = torch.device('cuda')
elif torch.backends.mps.is_available():
device = torch.device('mps')
else:
device = torch.device('cpu')
return device
def set_model(model, device, distributed=False):
"""The operation for set model's distribution mode.
Args:
model (nn.Module): The model.
device (torch.device): The torch device.
distributed (bool, optional): The option for distributed. Defaults to False.
Raises:
ValueError: If distributed gpu option is true, the gpu device should cuda.
Returns:
nn.Module: The model.
"""
is_cuda = torch.cuda.is_available()
if distributed:
if is_cuda:
model.to(device)
model = nn.parallel.DistributedDataParallel(model,device_ids=[device],output_device=[device])
else:
raise ValueError(
'If in cpu or mps mode, distributed option should be False.')
else:
model = model.to(device)
if is_cuda and torch.cuda.device_count()>1:
model = nn.parallel.DataParallel(model)
return model
def main():
args = parse_args()
distributed = False
if 'WORLD_SIZE' in os.environ and int(os.environ['WORLD_SIZE']) > 1:
distributed = True
print('This is {} rank of {} process'.format(
os.environ['RANK'], os.environ['WORLD_SIZE']))
device = set_device(args.local_rank if distributed else None)
if distributed:
dist.init_process_group(backend='nccl', init_method='env://', world_size=int(
os.environ['WORLD_SIZE']), rank=int(os.environ['RANK']))
if torch.distributed.is_initialized():
print('Distribution is initalized.')
else:
print('Distirbution is not initalized.')
model = torchvision.models.resnet18(pretrained=False)
model = set_model(model,device,distributed=distributed)
print('Get model.')
if __name__ == "__main__":
main()실행 코드
Multi Process를 실행하기 위한 실행 코드는 다음과 같다.
Master Node
export NCCL_SOCKET_IFNAME=enp5s0 #NCCL_SOCKET of master node host
export NCCL_DEBUG=INFO #DEBUG
NNODES=2 #Number of total node
NODE_RANK=0 #Rank of total node
NPROC_PER_NODE=2 #Process number of this node
MASTER_ADDR='127.0.0.1'
MASTER_PORT='12345'
python -m torch.distributed.launch --nnodes=${NNODES} --node_rank=${NODE_RANK} --nproc_per_node=${NPROC_PER_NODE} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} ../distributed_check.pyWorker Node
export NCCL_SOCKET_IFNAME=enp5s0 #NCCL_SOCKET of worker node host
export NCCL_DEBUG=INFO #DEBUG
NNODES=2 #Number of total node
NODE_RANK=1 #Rank of total node
NPROC_PER_NODE=2 #Process number of this node
MASTER_ADDR='192.168.0.76' #Master IP ADDR
MASTER_PORT='12345' #MASTER PORT
python -m torch.distributed.launch --nnodes=${NNODES} --node_rank=${NODE_RANK} --nproc_per_node=${NPROC_PER_NODE} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} ../distributed_check.py실행 결과
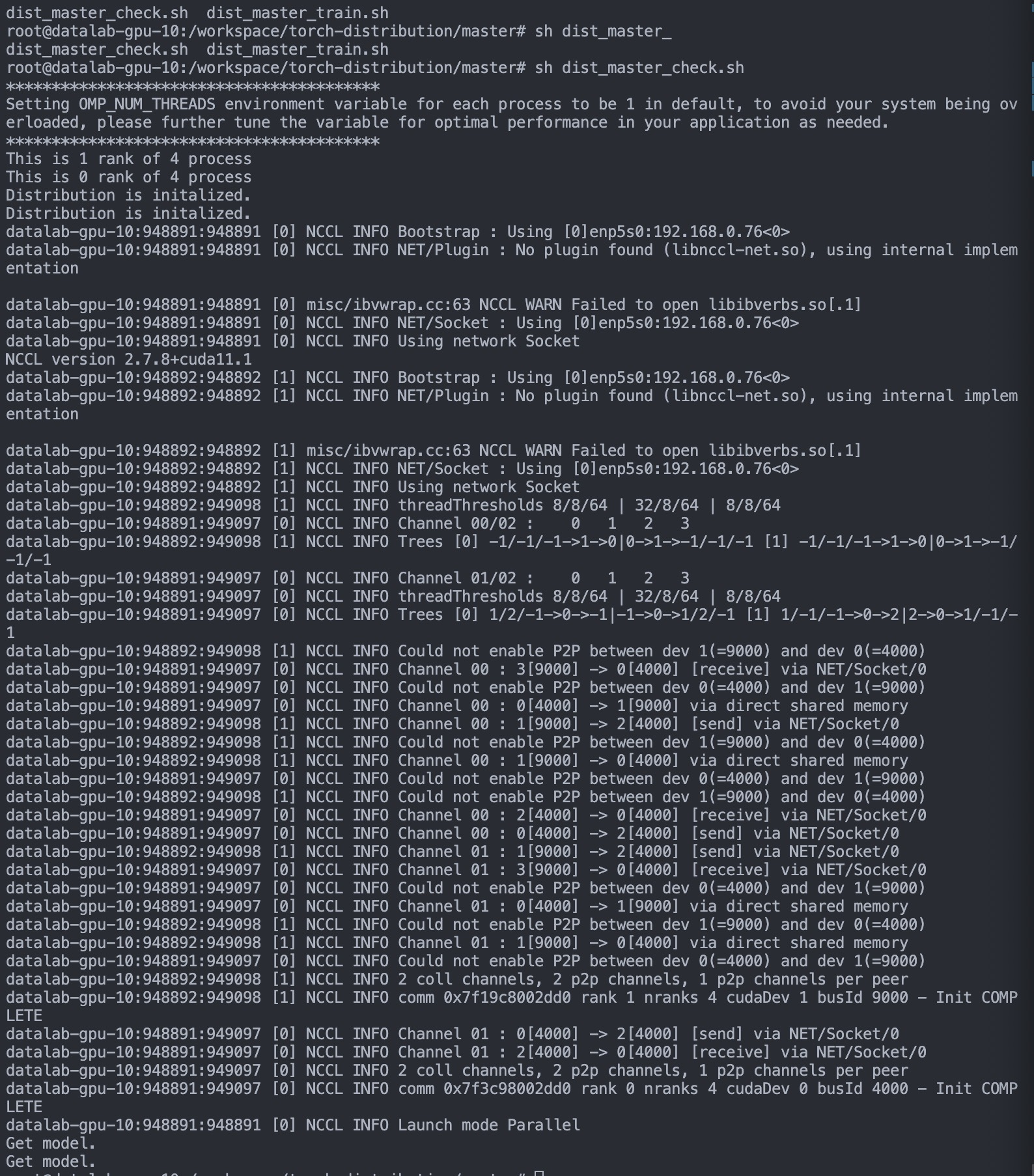

Vision AI Engineer