정말 놀랍게도 이전 편이 존재하는 글이다. 블로그의 첫 글에 어떻게 1편이 존재할 수 있는지 궁금하시리라 믿고 확인하실 수 있게 링크를 걸어두도록 하겠다.
지난편에서 마저 다루지 못 한 나머지 라이브러리인 seaborn 에 대해서 다뤄보도록 하겠다. 우리가 화려해지기 위해선 갈 길이 멀기에 라이브러리 사용법은 빠르게 정리하고 넘어가야만 한다. 고로 최대한 기본만, 우리가 자주 사용할 만큼만 알고 넘어가려 한다. 더 심화적인 내용은 필요할 때마다 찾아보면서 진행하기로 하자. 라이브러리들을 파고 들기 시작하면 그것만으로도 논문 한 편을 쓸 수 있을테니 말이다...
seaborn (API 레퍼런스)
seaborn 은 matplotlib 을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능이 추가된 라이브러리이다. 기본적인 시각화 기능은 matplotlib 라이브러리에 의존하며 통계 기능은 statsmodels 라이브러리에 의존한다. 코드를 보면 아실텐데 그림을 seaborn 으로 그리 후, 그 외에 메소드는 matplotlib 의 메소드를 사용한다. 따라서 반복되고 지엽적인 내용들은 최대한 건너뛰도록 하겠다.
먼저 임포트를 하겠다. 역시나 킹갓 colab 에서는 별도의 설치가 필요없다.
import seaborn as sns요 녀석은 모두들 sns 라고 축약해서 쓴다. 생각해보니 왜 sns 일까? 전혀 매칭이 안 되는 느낌이라 한번 찾아보았지만 시원한 답변은 찾지 못 했다. 혹여 아는 분이 계시다면 알려주시기 바란다.
먼저 앞서 실습해 본 선 그래프와 막대 그래프는 각각 lineplot 메소드와 barplot 메소드로 대체된다.
선 그래프 (공식문서)
sns.lineplot([4,2,2,3,3],[1,2,4,2,4])
plt.show()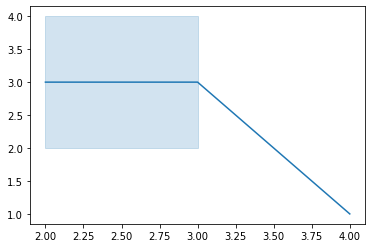
조금 특이한 점은 인덱스가 중복되는 값들의 평균을 선으로 표시하고 값의 범위를 다른 색으로 보여준다.
막대 그래프 (공식문서)
막대 그래프의 경우도 비슷하다.
sns.barplot([4,2,2,3,3],[1,2,4,2,4])
plt.show()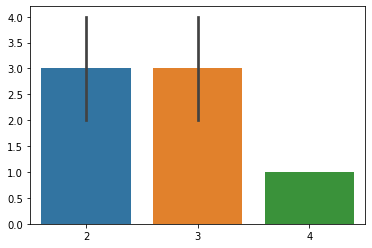
대신 요 녀석은 값의 범위를 세로선으로 표시해준다.
샘플 데이터셋
요 기특한 녀석은 필자와 같은 데(데이터분석)린이들이 편하게 실습해 볼 수 있는 샘플 데이터셋을 제공한다. 불러오는 코드는 다음과 같다.
titanic = sns.load_dataset('titanic')
titanic.head()
"짹..."을 기리며 타이타닉 데이터를 불러와서 다른 코드에 사용하도록 하겠다.
heatmap (공식문서)
heatmap 은 x축과 y축을 지정해주고 우리가 보고 싶은 데이터를 선택하면, 선택한 데이터가 어떤 x, y 에 분포하는지 볼 수 있다.
import numpy as np
data = np.random.rand(10, 12)
sns.heatmap(data, annot=True)
plt.show()
랜덤 데이터를 생성해 그려보았다. annot 옵션은 그림 위에 수치를 표시해준다. 샘플 데이터를 활용해 그려보겠다.
sns.heatmap(data, annot=True, fmt='d', cmap=sns.light_palette('blue'))
plt.show()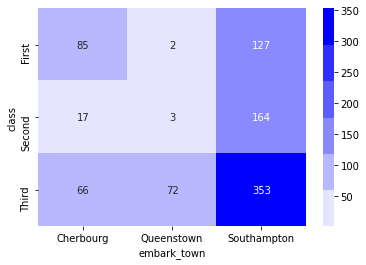
이런 형태로 색상이나 스타일도 적용 가능하다. 참고로 fmt 옵션은 히트맵 위에 표기되는 숫자의 형태를 지정해준다.(ex. '0.2f'->소수둘째자리까지, 'd'->정수자리만)
hue
제공되는 옵션 중 카테고리형 데이터에 유용하게 쓸 수 있는 hue 라는 옵션이 있다.
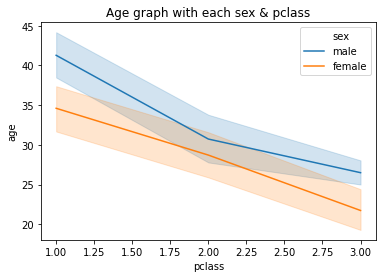
sns.lineplot(x='pclass', y='age', data=titanic, hue='sex')
# 위의 한 줄이 아래 주석과 완전히 같은 의미
# sns.lineplot(x=titanic.query('sex=="male"')['pclass'],
# y=titanic.query('sex=="male"')['age'])
# sns.lineplot(x=titanic.query('sex=="female"')['pclass'],
# y=titanic.query('sex=="female"')['age'])
plt.show()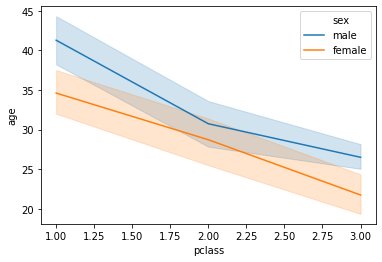
이렇게 hue 옵션을 이용하게 되면 기존에 여러번 그래프를 중첩해서 그리던 과정을 훨씬 편하게 수행할 수 있게 된다.
countplot
seaborn 의 장점 중 하나는 간단한 통계 도구를 포함한다는 점이다. EDA 를 진행하다 보시면 차차 알겠지만 야생의 데이터에서 의미있는 인자들을 찾아내고 연결시키려면 모공 하나하나까지 온갖 통계를 들여다봐야 하므로 알아두시면 충분히 유용할 것이다. 그 중에서도 이 countplot 이라는 녀석은 우리가 지정해 준 컬럼에서 카테고리 별로 데이터를 카운트해주는 아주 심플한 녀석이다.
sns.countplot(x='pclass', data=titanic, hue='sex')
plt.show()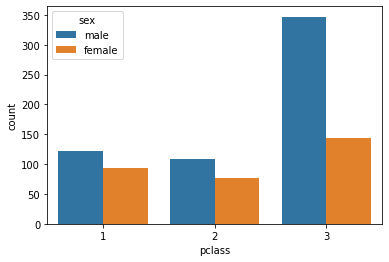
요렇게 우리는 타이타닉의 각 객실의 성별에 따른 탑승객 수를 그래프로 확인할 수 있다. 이 때도 hue 속성을 통해 너무나 간단하게 이중그래프를 그릴 수 있다. pyplot 에서는 눈물의 똥꼬쑈를 하며 그렸던 그래프지만 이렇게나 편리하다니 라떼는 생각할 수도 없던 일이다.
sns.countplot(x='sex', data=titanic, hue='pclass')
plt.show()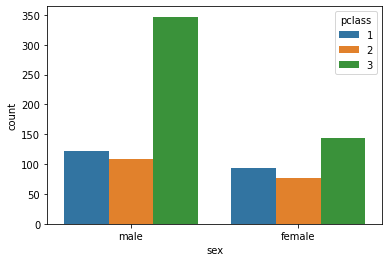
요렇게 x축과 hue 옵션의 인자를 바꿔주면 삼중막대를 확인하실 수 있다. 적소에 사용한다면 굉장히 편리한 친구다. x축 기준으로 그리던 녀석을 y 로만 변경해주면 가로로 막대그래프를 그릴 수도 있으니 한번 시도해보시면 좋겠다.
heatmap 응용(feat. pandas.DataFrame.corr())
pandas.DataFrame.corr() 메소드는 각 컬럼 간의 상관계수를 보여준다. 보아하니 옵션으로 상관계수 도출식을 선택(참고)해 줄 수 있는 모양이다. 하지만 통계학에 문외한인 필자는 피어슨 형님의 공식이 최고라 믿고 별도로 옵션 설정은 하지 않겠다. 굉장히 무식하고 비권장되는 방법이니 현명한 독자들께서는 때에 따라 도출식옵션을 변경해주는 지혜를 발휘하도록 하자. 이 메소드를 사용하면 다음과 같은 표를 확인할 수 있다.
titanic.corr()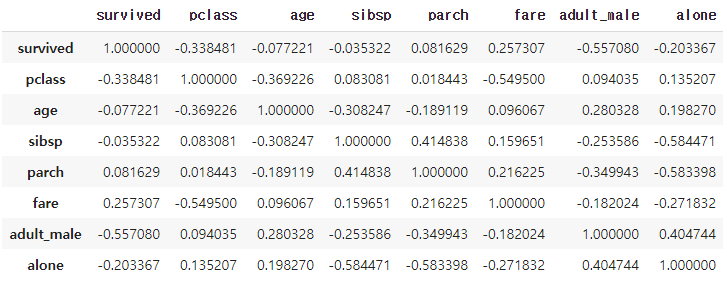
이렇게 각 컬럼 간의 상관계수를 -1부터 1 사이의 숫자로 보여주게 된다. 눈치 빠른 분은 파악하셨을텐데 기존 데이터에서 몇몇 빠진 컬럼이 보인다. 해당 메소드는 수치형 데이터만을 다루므로 카테고리형 컬럼들은 빠지게 된다. 계수의 해석은 eagle 을 참고하시고 필자는 요 메소드를 활용해 heatmap 을 그려보겠다.
sns.heatmap(titanic.corr())
plt.show()
굉장히 간단한 방법으로 기존에 보여주던 표를 heatmap 의 형태로 확인할 수 있다. 때로는 수치로 확인하는 것이 때로는 직관적으로 보는 것이 유리하니 경우에 따라 잘 활용하시기 바란다.
공식 문서에서 corr 메소드를 활용한 heatmap 을 보다 직관적으로 볼 수 있는 예제가 있어 공유한다. 해당 예제를 활용하여 타이타닉 데이터에 적용한 코드는 아래와 같다.
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(titanic.corr()))
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(230, 20, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(titanic.corr(), mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
plt.yticks(rotation=0)
plt.show()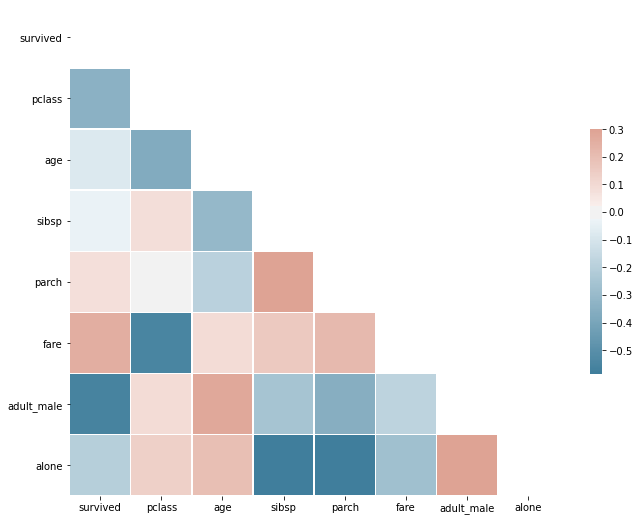
pairplot
요 친구는 앞서 소개한 corr 메소드의 그래프화라고 생각하시면 된다. 각 인자간의 상관계수 수치로 보여주는 것이 아니라 산점도로 나타내준다.
sns.pairplot(data=titanic[['pclass','age','fare']])
# bool 자료형의 경우 에러가 발생하므로 Numeric 컬럼만 인자로 주었음
plt.show()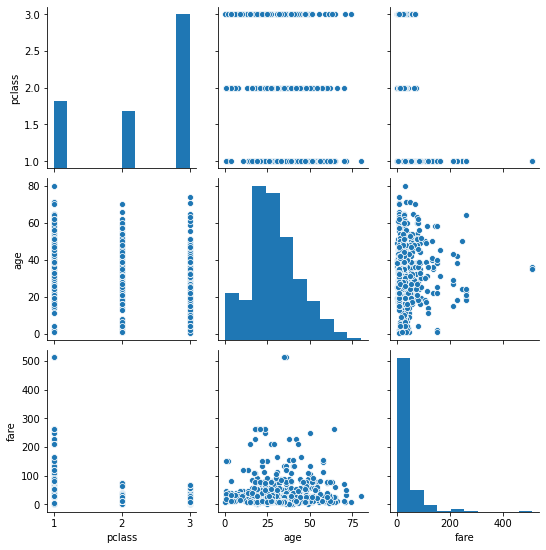
산점도와 히스토그램이 마음에 들지 않으면 위, 아래, 가운데 모두 원하는 형태의 그래프를 선택할 수도 있다.
# pairgrid 활용 pairplot 그리기
grid = sns.PairGrid(titanic[['pclass','age','fare']])
grid.map_upper(sns.regplot)
grid.map_lower(sns.lineplot)
grid.map_diag(sns.violinplot)
plt.show()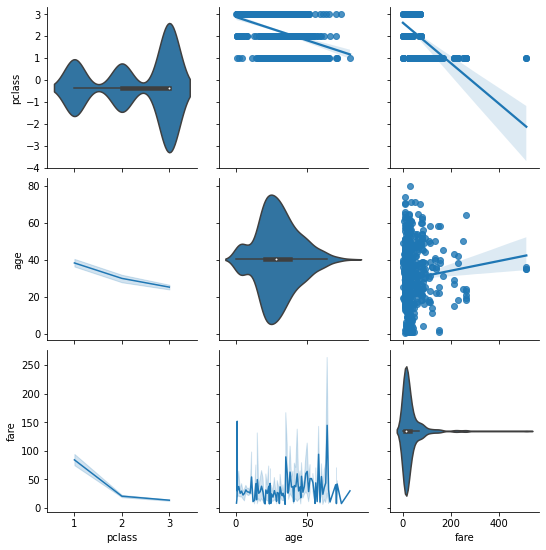
위와 같은 코드로 PairGrid 에서 호출하는 세가지 메소드를 통해 원하는 그래프의 종류를 지정해줄 수 있다. 그래프의 종류는 너무 다양하니 API 레퍼런스를 확인하고 필요한 그래프를 그릴 수 있는 데린이가 되어보자.
seaborn 에서 사용할 수 있는 시각화와 통계 기능을 간략히 살펴보았다. 사실 folium 과 plotly 까지 다뤄보려 했지만 글 하나에 여러 패키지를 다루자니 분량 조절이 안 되는 관계상 역시나 이 글에서도 다루지 못 했다. 다음 시리즈까지 라이브러리 사용법을 다루기에는 천리길을 나선 우리에게는 너무나도 사치라고 생각한다. 고로 추후에 데이터를 다루는 과정에서 필요한 상황이 생길 때에 해당 글에서 혹은 부록 등으로 다루도록 하겠다. 다음 글에서는 본격적인 EDA 에 앞서 데이터를 전처리하는 과정에 대해 다뤄보려고 한다. 부족한 글을 읽어준 독자 여러분 안구에게 심심한 위로의 말씀을 전하며 마지막으로 데이터 시각화에 대한 통찰력을 제시하는 좋은 글이 있어 공유한다.
