NLP Processing
형태소 분석
형태소

- 용언 : 어간(stem) + 어미(ending)
koNLPy : 한글 형태소 분석
- Mecab: 굉장히 속도가 빠르면서도 좋은 분석 결과를 보여준다.
- Komoran: 댓글과 같이 정제되지 않은 글에 대해서 먼저 사용해보면 좋다.(오탈자를 어느정도 고려해준다.)
- Kkma: 분석 시간이 오래걸리기 때문에 잘 이용하지 않게 된다.
- Okt: 품사 태깅 결과를 Noun, Verb등 알아보기 쉽게 반환해준다.
- khaiii: 카카오에서 가장 최근에 공개한 분석기, 성능이 좋다고 알려져 있으며 다양한 실험이 필요하다.

from konlpy.tag import Mecab
from konlpy.tag import *
Mecab = Mecab()
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
mecab = Mecab()
okt = Okt()
sentence = '데이콘에서 다양한 컴피티션을 즐기면서 실력있는 데이터 분석가로 성장하세요!!.'
print("형태소 단위로 문장 분리")
print(Mecab.morphs(sentence))
print("문장에서 명사 추출")
print(Mecab.nouns(sentence))
print("품사 태킹(PoS)")
print(Mecab.pos(sentence))
영어 : stemming, lemmatization
- Stemming : 어간 추출
- am → am
- the going → the go
- having → hav
- Lemmatization : 표제어 추출 (기본형)
- am → be
- the going → the going
- having → have
불용어 제거(Stopwords removing)
- stopwords 초기화(설정) - list에 해결할 문제에 알맞은 불용어 지정
- 조건에 맞는 글자만 추출
- tokenize
- stopwords 제거
import re
def text_preprocessing(text_list):
stopwords = ['을', '를', '이', '가', '은', '는', 'null']
tokenizer = Okt()
token_list = []
for text in text_list:
txt = re.sub('[^가-힣a-z]', ' ', text)
token = tokenizer.morphs(txt)
token = [t for t in token if t not in stopwords or type(t) != float]
token_list.append(token)
return token_list, tokenizer
train['new_article'], okt = text_preprocessing(train['content'])
Vectorization
- 자연어를 컴퓨터가 다룰 수 (이해 할 수) 있도록 하기위한 과정.
- 토큰화된 단어들을 벡터로 변환하여 수치화해서 전달한다.
- vocabulary : 벡터로 변환된 고유의 토큰들이 모인 집합
- 전처리 : Tokenize (형태소분석)
from konlpy.tag import Okt
import re
Okt = Okt()
sentences = ['자연어 처리는 정말 정말 즐거워.', '즐거운 자연어 처리 다같이 해보자.']
tokens = []
for sentence in sentences:
sentence = re.sub('[^가-힣a-z]', ' ', sentence)
token = (Okt.morphs(sentence))
tokens.append(' '.join(token))
print(tokens)
One-hot Encoding
- sparse data이기에 공간 부담이 크다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
t = Tokenizer()
t.fit_on_texts(tokens)
print("각 토큰에게 고유의 정수 부여")
print(t.word_index)
s1=t.texts_to_sequences(tokens)[0]
print("부여된 정수로 표시된 문장1")
print(s1)
s1_one_hot = to_categorical(s1)
print("문장1의 one-hot-encoding")
print(s1_one_hot)
Count Vectorization
- vocabulary를 기반으로 각 토큰들에 벡터 성분을 부여해놓고
- 각 문장에 대해 토큰 등장 횟수를 기반으로 벡터화
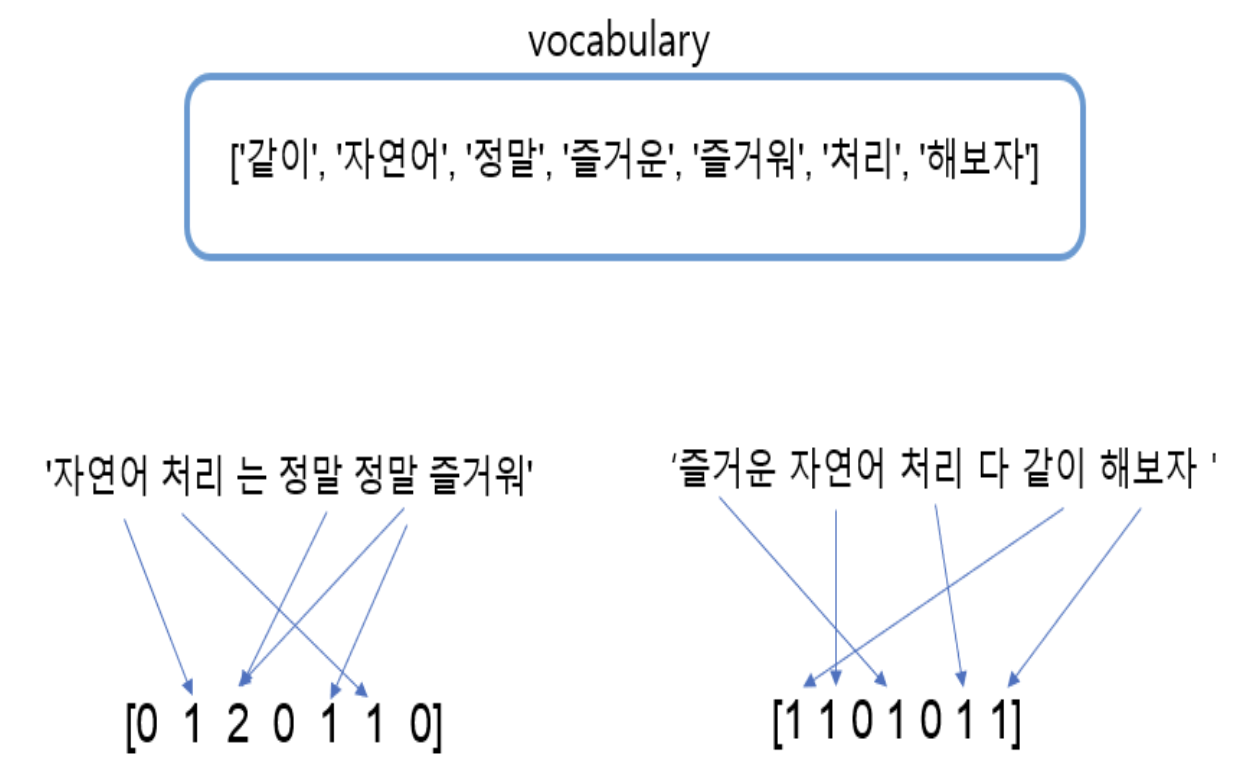
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
vectors = vectorizer.fit_transform(tokens)
print(vectorizer.get_feature_names())
print(vectors.toarray())
TF-IDF
- 단어가 가지는 문서 중요도 기반으로 vectorization
- 단어의 등장 횟수가 많을 수록 (TF)
- 단어를 포함하는 문서가 적을 수록 (IDF)
- 문서에서 해당 단어의 중요도가 높다
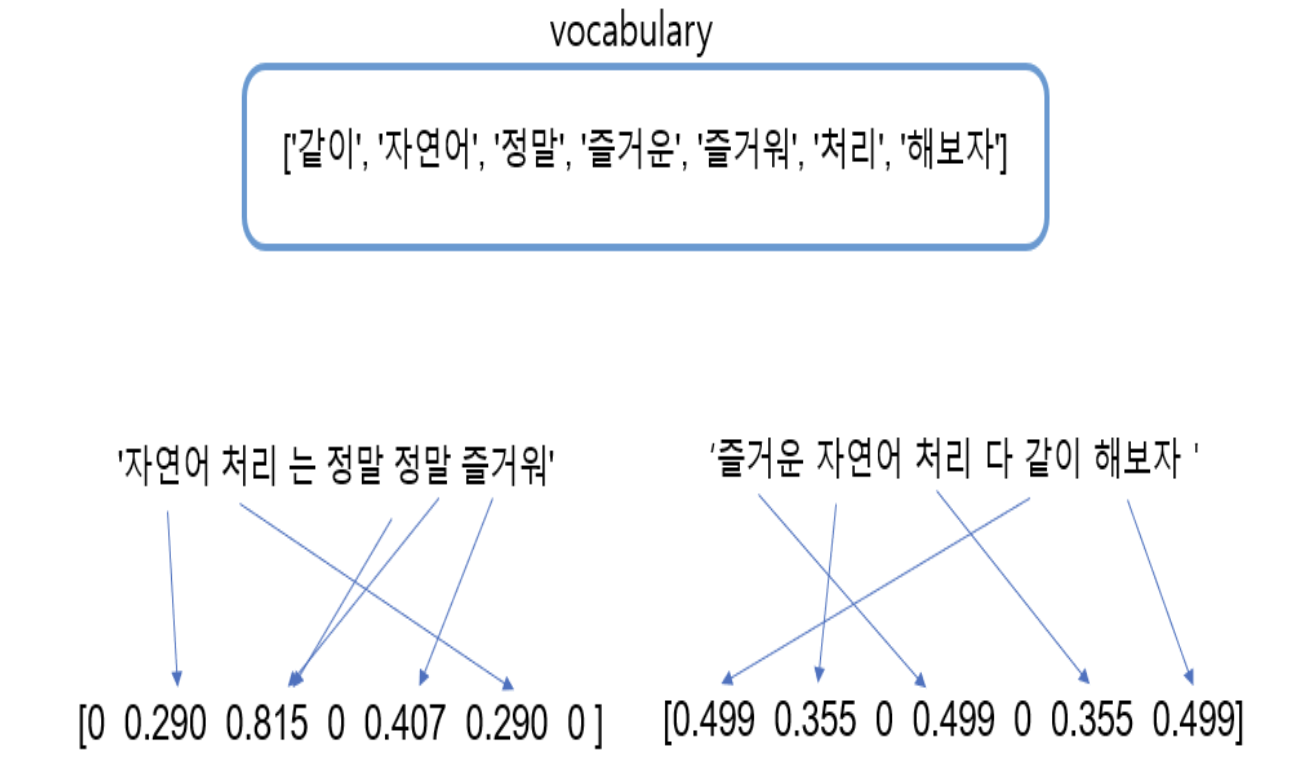
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(min_df=0)
tfidf_vectorizer = tfidf.fit_transform(tokens)
tfidf_dict = tfidf.get_feature_names()
print(tfidf_dict)
print(tfidf_vectorizer.toarray())
Padding
- 문장마다 토큰의 개수가 다를 때
- 통일시키기 위해 부족한 토큰 개수를 0으로 채운다
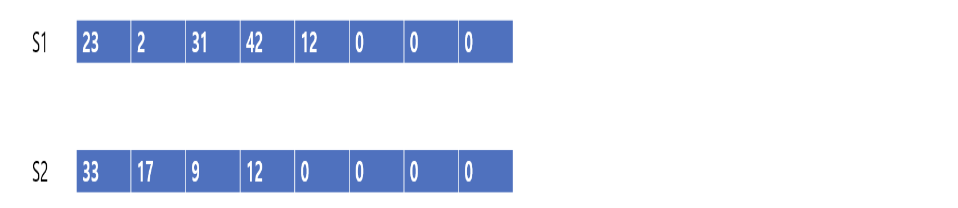
from tensorflow.keras.preprocessing.sequence import pad_sequences
X_train = pad_sequences(train_X_seq, maxlen = max_len)
단점
- 단어의 중요도까지 표현 할 수 있지만, 단어간 관계(유사도)에 대해 설명하지 못 한다.
-> Word Embedding 사용
reference
