sangyun.log
로그인
sangyun.log
로그인
NLP 기초(한글) - modeling
김상윤
·
2022년 8월 28일
팔로우
0
AI이모저모
목록 보기
11/13
Embedding
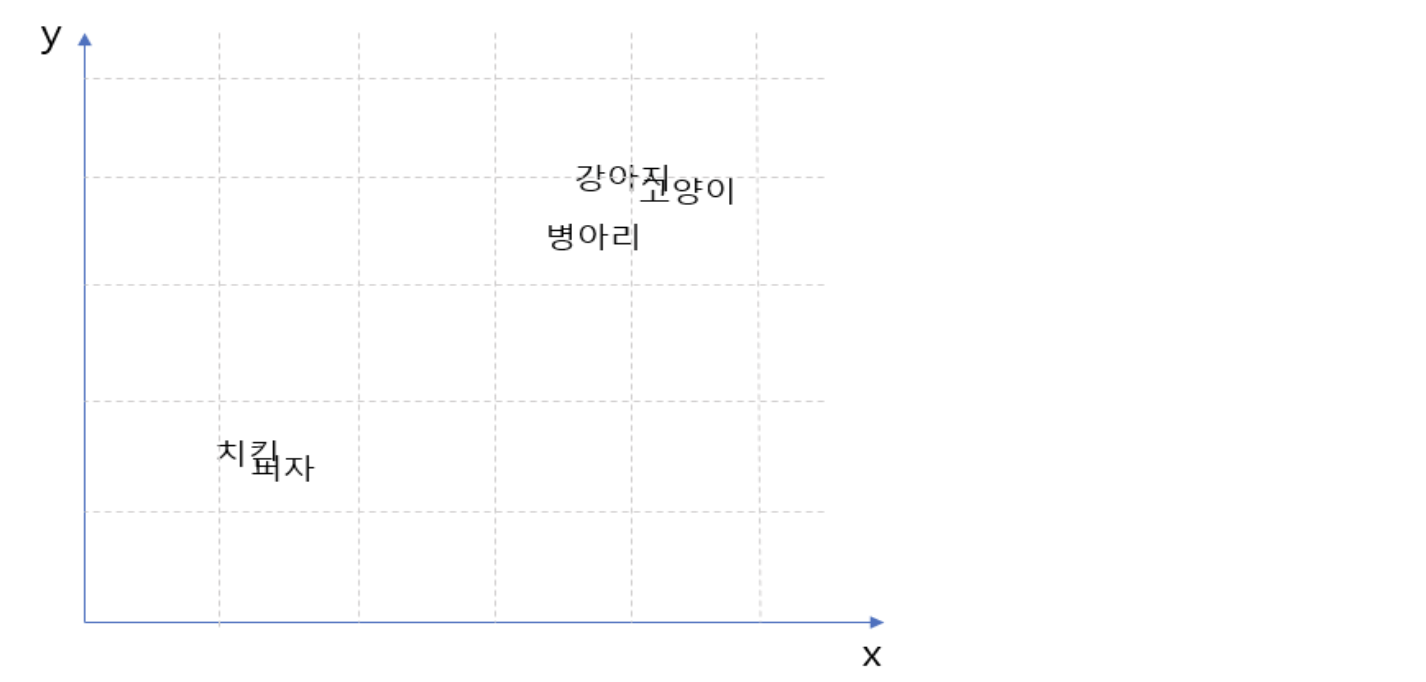
word 토큰 벡터에서 단어간 유사도 정보의 설명성을 위해
유사도가 높은 토큰일수록 벡터공간에서 가깝게 위치시킨다.
임베딩도 모델링이다.
데이터와 목적 특화된 임베딩 모델을 학습에 많은 양의 데이터와 시간이 필요하므로, pre-trained model을 가져와서 사용한다.
word2vec
glove
fasttext
Modeling
RNN
LSTM
GRU
Attention
김상윤
팔로우
이전 포스트
NLP 기초(한글) - 표제어추출, Vectorization
다음 포스트
Word2Vec
0개의 댓글
댓글 작성