
Introduction
- 현대 소비자에게는 너무 많은 선택권이 제공 됨
- 소비자의 니즈를 충족할 아이템을 제공하는 것은 유저 만족도와 직결됨
- 따라서 Netflix, Amazon 등 많은 E-commerce Leader들은 추천 시스템에 주목함
Recommender System Strategies
-
추천 시스템은 크게 content-based filtering 과 collaborative filtering으로 나뉨
-
content-based filtering은 아이템 자체의 information (genre, actors, box office popularity) 과 유저 자체의 demographic information 을 사용하는 것
- 외부 정보가 필요하기에 접근, 수집이 쉽지 않음
- Pandora.com에서 사용한 Music Genome Project가 대표적인 content-based 방법론의 예시
-
Collaborative Filtering은 이와 대비해 유저의 행동을 추천에 활용하는 방법론(product score, 거래 이력 등)
- Tapestry의 개발자가 처음으로 명명함 (첫 추천시스템)
- Domain-Free
- side-information을 활용하기에는 힘드나, 대부분의 content-based 기반 방법론보다 좋은 성능을 보임
- Cold - Start Issue가 대부분 존재 (새로운 상품, 새로운 유저)
-
collaborative filtering은 또 다시 두 가지 갈래로 나뉨 - Neighborhood method와 latent factor models
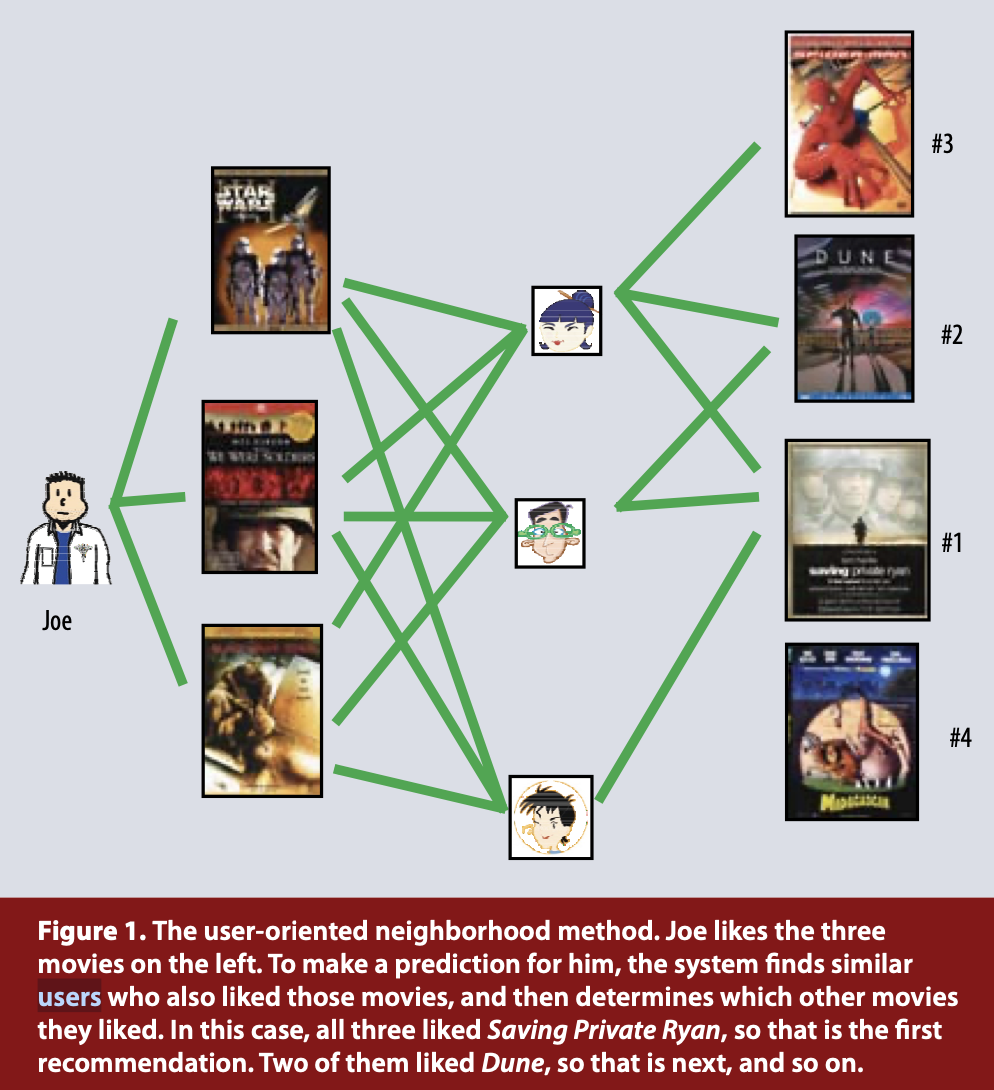
- Neighborhood methods는 아이템과 유저 관계를 계산하는 것이 목적
- Item 기반 이웃 방법론은 이웃 아이템을 기준으로 유저의 선호도를 평가
- 상품 이웃들 (유저들이 비슷하게 평가한 상품들) 에 포함된 상품을 유사하게 매기는 것
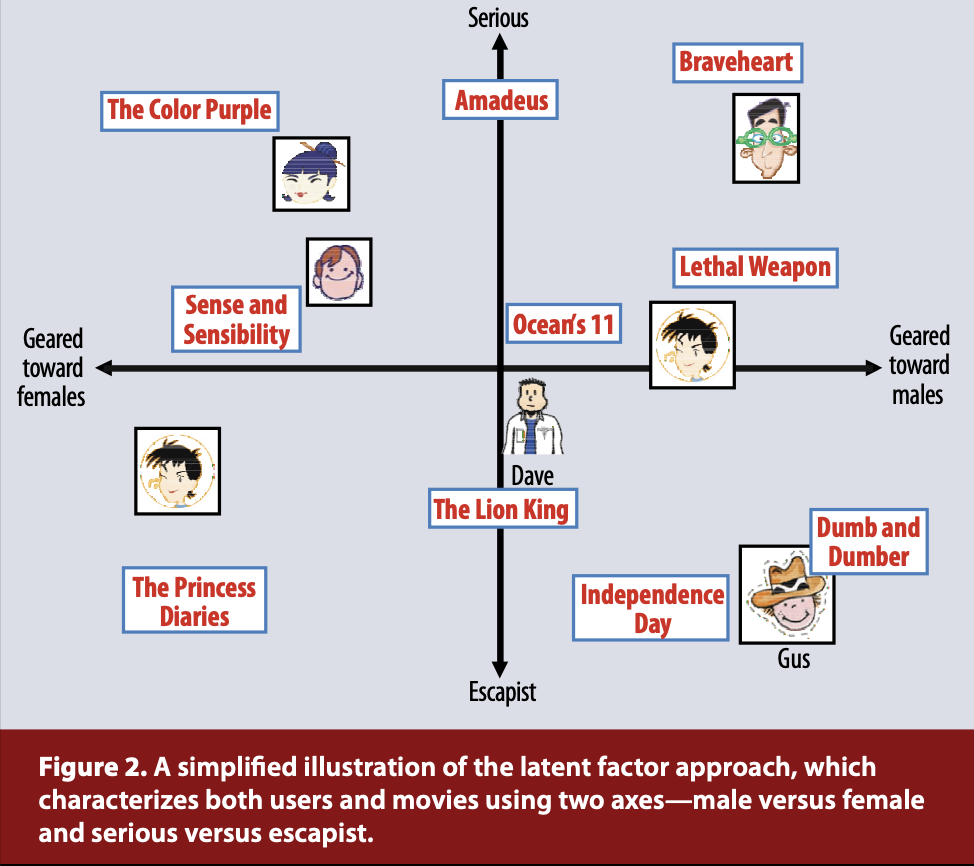
- Latent Factor Models는 유저와 아이템을 잠재 벡터로 매핑하여 선호도를 측정하는 것
- 아이템 벡터와 유저 벡터의 Dot Product를 통해 선호도를 구할 수 있음
Matrix Factorization Methods
- 대부분의 성공적인 잠재 요인 모델은 바로 Matrix Factorization
- 확장 가능성, 높은 성능과 현실 문제에 적용 가능한 유연성 덕에 많은 이들이 사용
- 추천 시스템은 다양한 Data에 의존
- 최고는 유저의 선호를 수치로 평가한 Explicit Feedback
- Netflix의 별점, TiVo의 Thumbs Up-Down 등
- 그러나 유저는 적은 아이템만 평가하기에 Rating Matrix가 매우 Sparse
- Implicit Feedback은 구매 이력, 검색 이력, 마우스 움직임 등의 데이터
- 이는 Presence, Absence로 denote되며, 비교적으로 dense matrix를 구성가능케 함
A Basic Matrix Factorization Model

- u 번째 유저 벡터 Pu와 i 번째 아이템 벡터 qi를 dot한 predict rating rui
- 어떻게 유저 벡터와 아이템 벡터를 계산하느냐가 관건 (두 벡터는 동일한 차원)
- 기존 방법인 SVD는 결측치에 취약해 사용하지 못함 (채우기도 힘들고, 데이터 왜곡 가능성 존재)
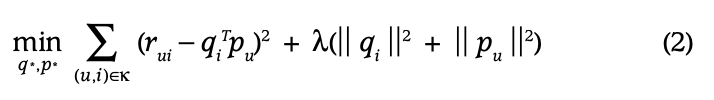
- 따라서 관측된 항만을 학습에 사용하고, 정규화 term을 추가해 overfitting을 보완한 식이 도입 (k는 실제 Interaction된 (u,i) 쌍)
- Lambda는 overfitting을 조절하는 HyperParameter
- PMF에서 regularization의 probabilistic foundation이 제공됨
Learning Algorithms
- 위 수식을 최소화 하기 위해서는 SGD, ALS 두 가지 방법이 존재
Stochastic gradient descent (SGD)
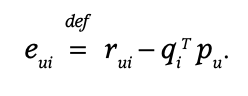
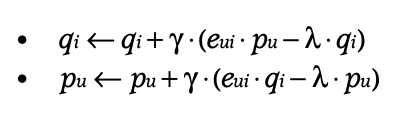
- prediction loss를 구해준 뒤, 학습률 만큼 경사하강 시키는 것
Alternation Least Squares
-
pu와 qi는 Unknown, so convex하지 않음
-
그러나 하나를 고정한다면? 최적화 식은 convex해져 closed form으로 정리 가능
-
따라서 그 최적화 식을 closed form으로 번갈아 update하여 수렴할 때 까지 학습하면 됨
-
보통 SGD가 ALS에 비해 쉽고 빠름, 그러나 두 가지 상황에서 ALS가 장점을 가짐
- 독립적으로 학습할 수 있어, 병렬화가 필요할 때
- Implicit Data를 사용할 때
- matrix가 dense하기에, SGD를 사용한 training loop은 너무 길어짐
Adding Biases
- MF를 통한 Collaborative Filtering의 장점은 다양한 데이터 관점을 반영하고, 요구를 수용할 수 있는 유연성
- 수식 (1)은 유저와 아이템의 관계만으로 rating을 결정, 그러나 대부분의 상황에서 user와 Item 자체도 별점에 영향을 미칠 것임
- 따라서 모든 rating을 유저와 아이템의 관계만으로 결정하는 것은 현명하지 않은 것으로, user와 item bias를 추가해 주는 것이 유용할 것

- bui는 전체 평점 평균과 아이템 bias, user bias를 추가한 bias

- 최종적으로는 다음과 같이 예측값 생성 (global average, item bias, user bias, user-item interaction 총 4가지로 분할 됨)
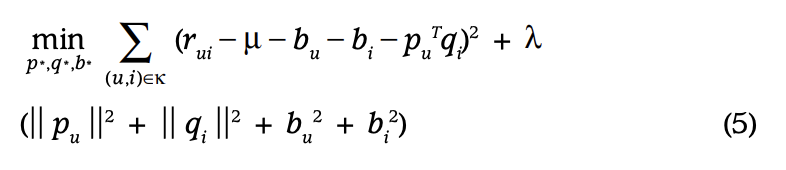
- 최종적으로 다음과 같은 수식이 완성
Additional Input Sources
-
매우 적은 interaction의 유저는 채 cold start problem에 시달림
-
이를 해결하기 위한 Implicit Feedback (browsing history 등)
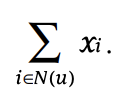
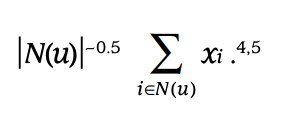
-
N(u)는 Implicitly preffered data이고, xi는 그 잠재 벡터에 해당
-
Normalizing 하는 것이 유용
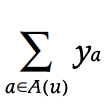
- 또한 user의 demographic 정보도 사용할 수 있음
- A(u)는 user의 demographic attribute이며, ya는 그 잠재벡터에 해당
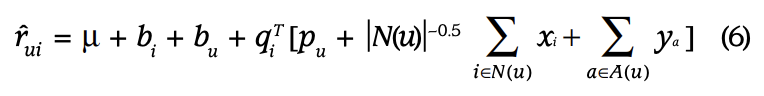
- 최종적으로 다음과 같은 식을 구성할 수 있음
Temporal Dynamics
- 지금까지 모델은 static 하지만, real world에서 선호는 변함!
- 이 Temporal effect를 모델에 반영할 필요가 있음
- 총 3가지가 term이 변화
- bi(t) : item biases
- bu(t) : user biases
- pu(t) : user preference
- 영화의 주인공이 추후에 인기가 많아지면 기존 영화의 선호도도 증가할 것
- 후하게 점수를 매기던 사람은 점수를 낮게 주는 사람으로 변할 수 있음
- 좋아하던 배우나 감독이 바뀔 수 있으며, thiller movie에서 crime movie로 취향이 바뀔 수 있음
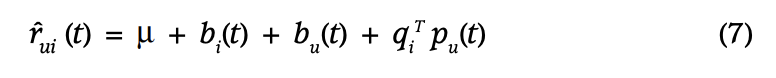
Input With Varying Confidence Levels
- 모든 값이 같은 신뢰도를 갖는 것은 아님
- 어떤 사용자는 별 생각 없이 낮은 별점을 매길수도 있음
- 따라서 추천 시스템의 robustness를 위해 선호도에 신뢰도를 붙여야 함
- 신뢰도는 action의 빈도를 설명하는 실수 값으로, 특정 show를 얼마나 자주 보았는지, 길게 보았는지 등으로 정의할 수 있음 (이에 대한 정보를 더 얻고 싶으면 "Collaborative Filtering for Implicit Feedback Datasets'를 참고)
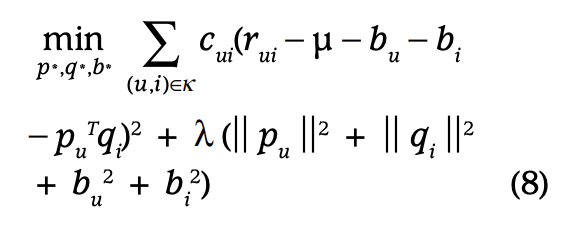
- cui가 신뢰도에 해당(confidence)
Netflix Prize Competition
- 2006년 Netflix의 SOTA Recsys model 개발 대회
- 100 million rating
- 500,000 customer
- 17,000 movie
- Explicit 1-5 rating
- RMSE
- 48,000 team from 182 countries
- 현 넷플릭스 알고리즘보다 10%가량 발전한 알고리즘을 만든 1등 팀에게는 $1 million
- 당시엔 이정도 규모의 데이터 셋과 상금이 존재 X
- 논문 저자는 상기된 방법론을 사용해 기존 알고리즘 대비 9.46%의 성능 향상 달성
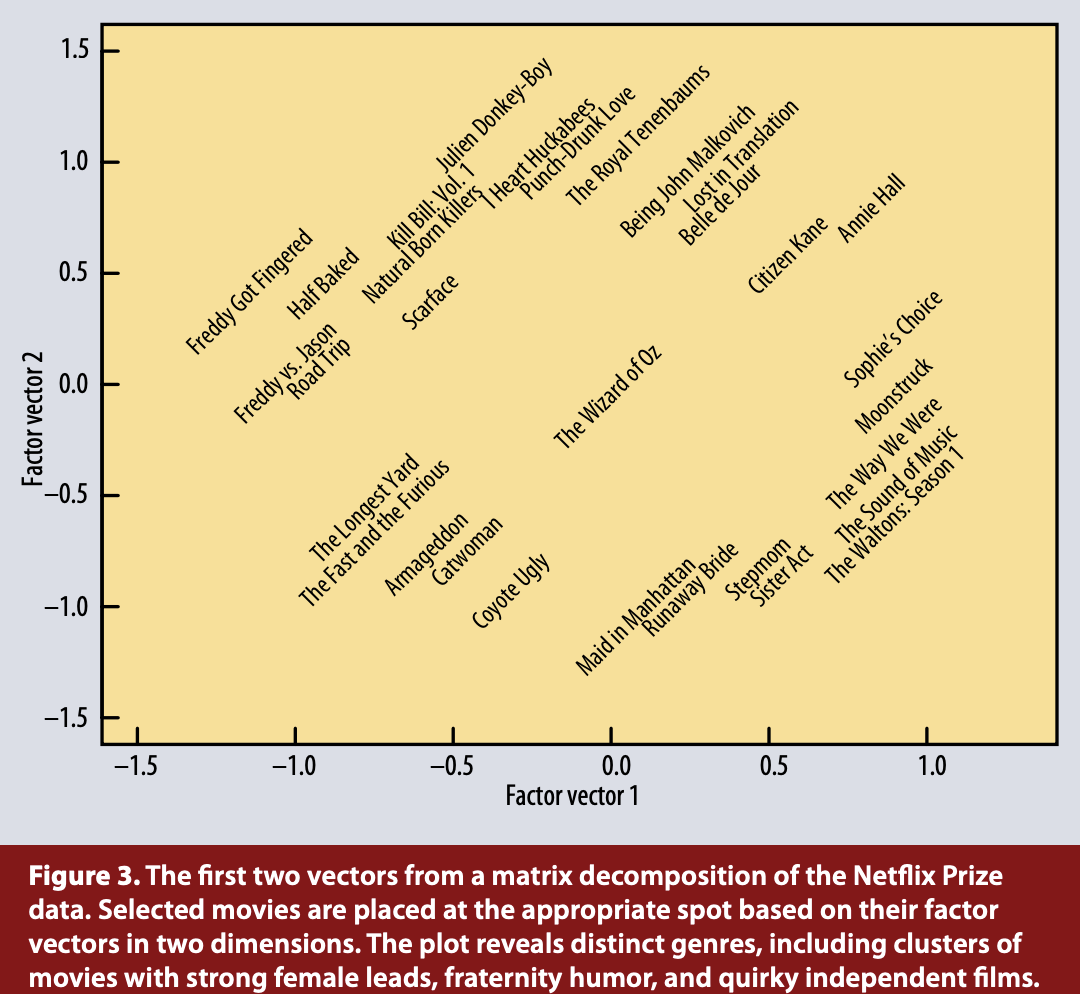
- 다음과 같이 우리 모델의 key factor vector가 굉장히 잘 분리해 주는 것을 볼 수 있음
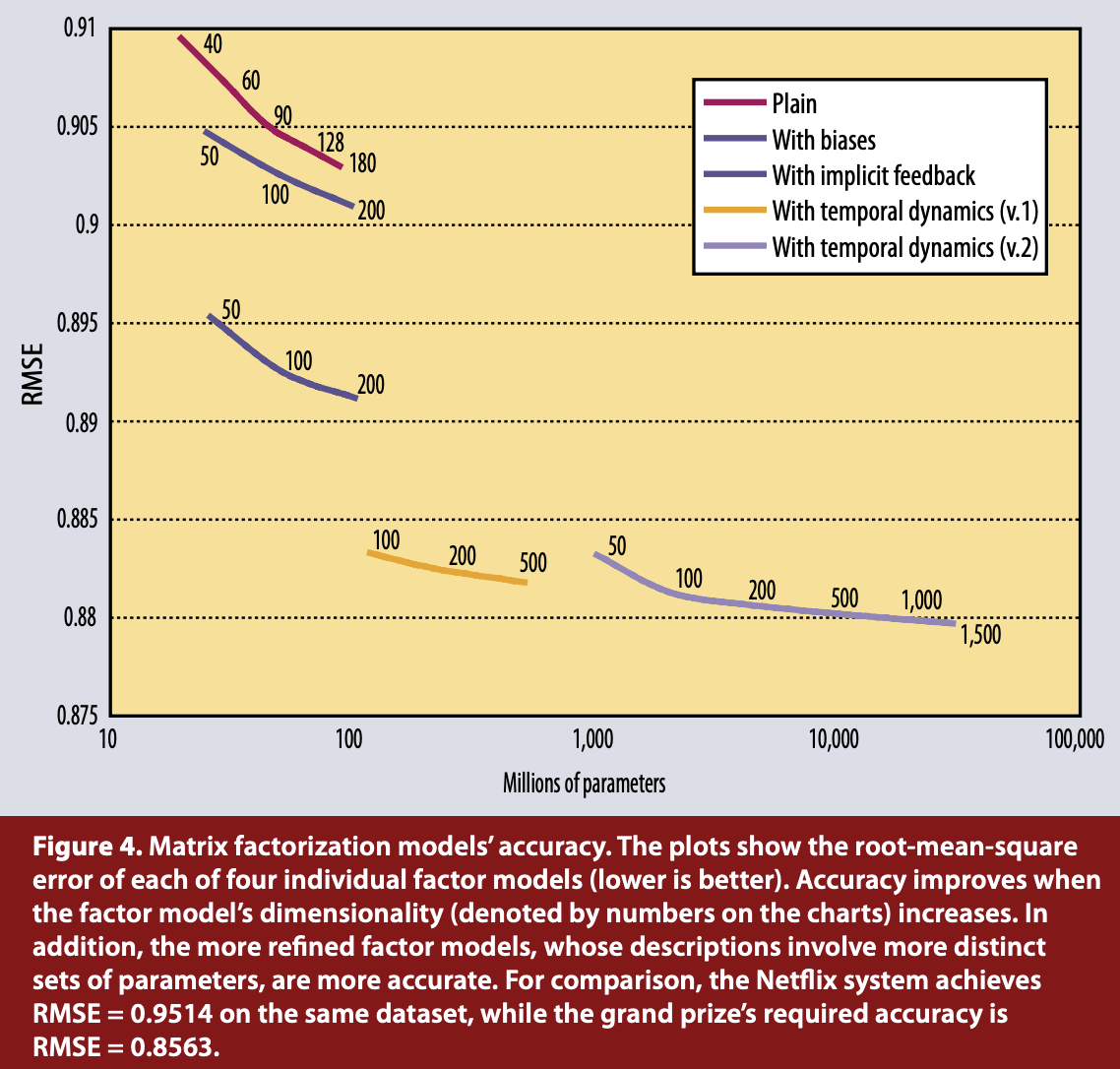
- 다음과 같이 모델의 성능 향상을 볼 수 있음
Conclusion
- CF의 지배적인 방법론 MF
- Netflix 등 여러 데이터 셋에서 MF가 NN을 능가하며, Compact한 메모리 효율성을 자랑
- 특히 모델의 확장 가능성은 무궁무진
- 다양한 형식의 feedback
- temporal dynamics
- confidence level 등 ..
